 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Location Trace Privacy Under Conditional Priors
Feb 23, 2021
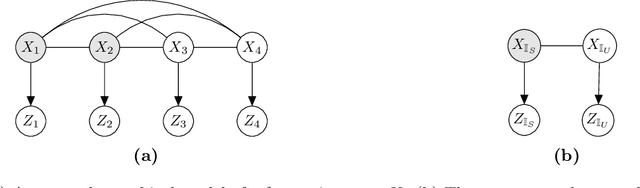
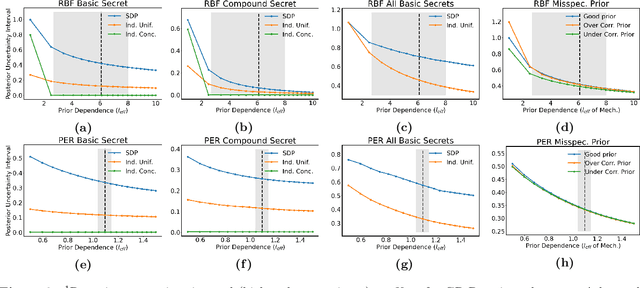
Providing meaningful privacy to users of location based services is particularly challenging when multiple locations are revealed in a short period of time. This is primarily due to the tremendous degree of dependence that can be anticipated between points. We propose a R\'enyi divergence based privacy framework for bounding expected privacy loss for conditionally dependent data. Additionally, we demonstrate an algorithm for achieving this privacy under Gaussian process conditional priors. This framework both exemplifies why conditionally dependent data is so challenging to protect and offers a strategy for preserving privacy to within a fixed radius for sensitive locations in a user's trace.
Comparing Popular Simulation Environments in the Scope of Robotics and Reinforcement Learning
Mar 08, 2021

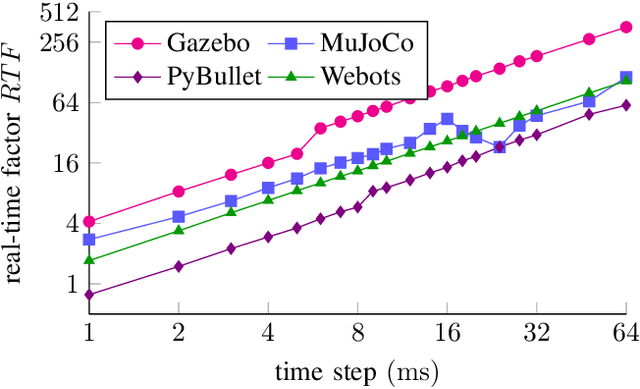
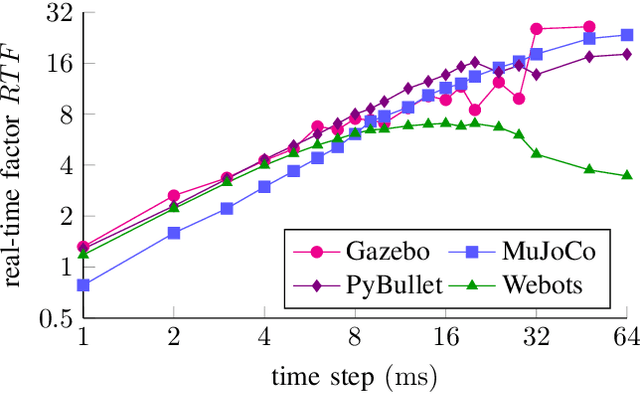
This letter compares the performance of four different, popular simulation environments for robotics and reinforcement learning (RL) through a series of benchmarks. The benchmarked scenarios are designed carefully with current industrial applications in mind. Given the need to run simulations as fast as possible to reduce the real-world training time of the RL agents, the comparison includes not only different simulation environments but also different hardware configurations, ranging from an entry-level notebook up to a dual CPU high performance server. We show that the chosen simulation environments benefit the most from single core performance. Yet, using a multi core system, multiple simulations could be run in parallel to increase the performance.
Sampling Training Data for Continual Learning Between Robots and the Cloud
Dec 12, 2020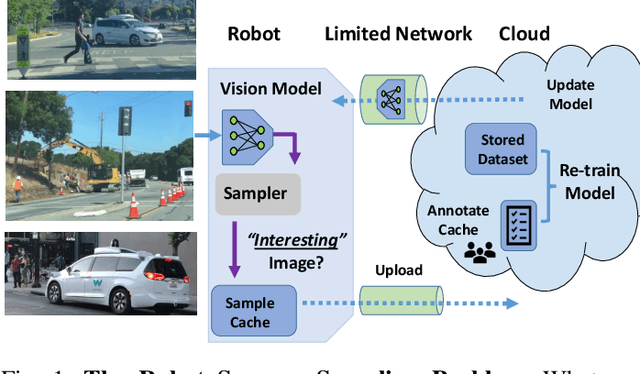
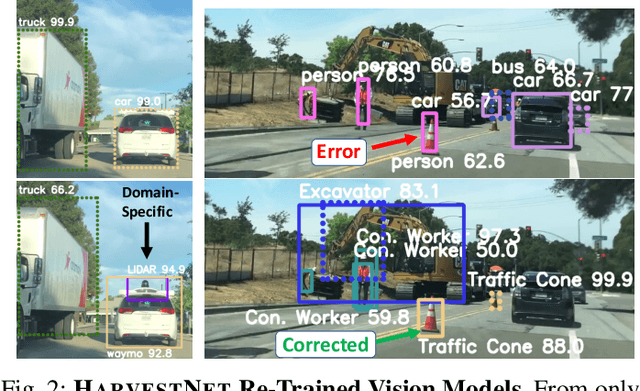
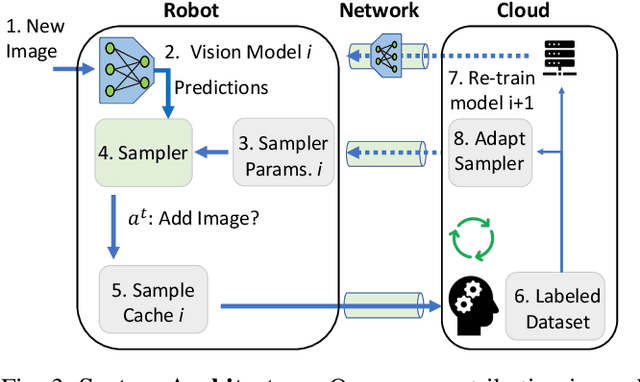
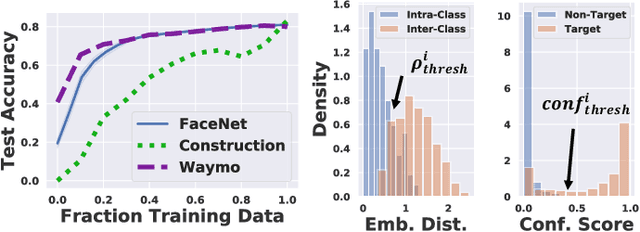
Today's robotic fleets are increasingly measuring high-volume video and LIDAR sensory streams, which can be mined for valuable training data, such as rare scenes of road construction sites, to steadily improve robotic perception models. However, re-training perception models on growing volumes of rich sensory data in central compute servers (or the "cloud") places an enormous time and cost burden on network transfer, cloud storage, human annotation, and cloud computing resources. Hence, we introduce HarvestNet, an intelligent sampling algorithm that resides on-board a robot and reduces system bottlenecks by only storing rare, useful events to steadily improve perception models re-trained in the cloud. HarvestNet significantly improves the accuracy of machine-learning models on our novel dataset of road construction sites, field testing of self-driving cars, and streaming face recognition, while reducing cloud storage, dataset annotation time, and cloud compute time by between 65.7-81.3%. Further, it is between 1.05-2.58x more accurate than baseline algorithms and scalably runs on embedded deep learning hardware. We provide a suite of compute-efficient perception models for the Google Edge Tensor Processing Unit (TPU), an extended technical report, and a novel video dataset to the research community at https://sites.google.com/view/harvestnet.
Neural Camera Simulators
Apr 12, 2021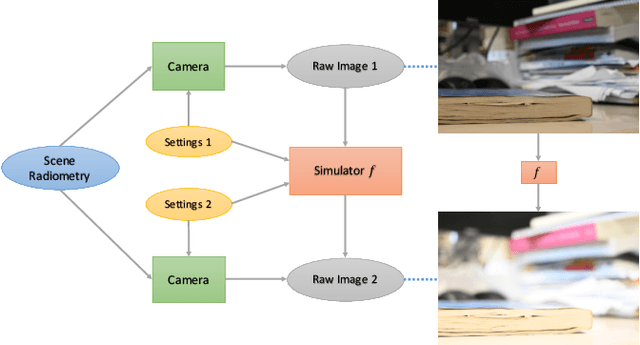

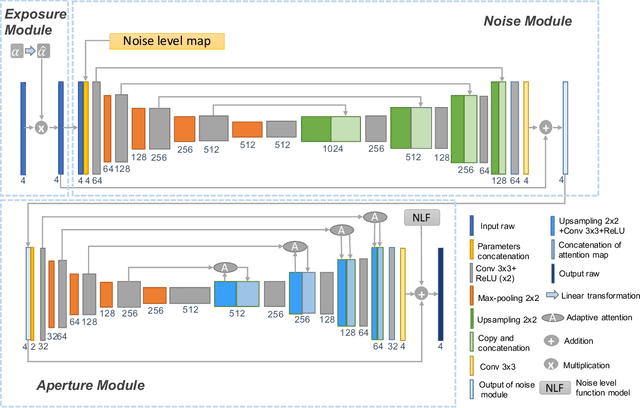
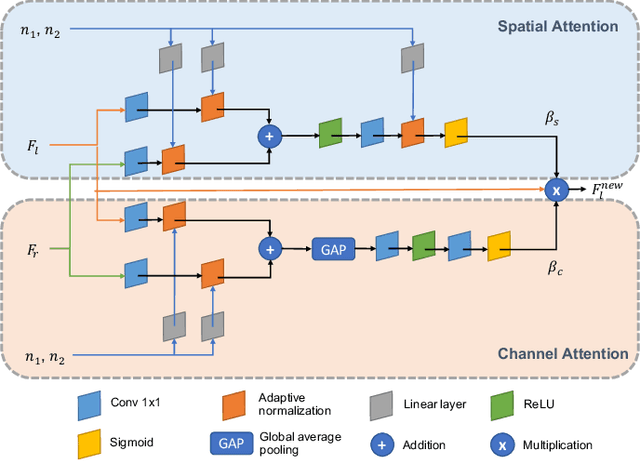
We present a controllable camera simulator based on deep neural networks to synthesize raw image data under different camera settings, including exposure time, ISO, and aperture. The proposed simulator includes an exposure module that utilizes the principle of modern lens designs for correcting the luminance level. It also contains a noise module using the noise level function and an aperture module with adaptive attention to simulate the side effects on noise and defocus blur. To facilitate the learning of a simulator model, we collect a dataset of the 10,000 raw images of 450 scenes with different exposure settings. Quantitative experiments and qualitative comparisons show that our approach outperforms relevant baselines in raw data synthesize on multiple cameras. Furthermore, the camera simulator enables various applications, including large-aperture enhancement, HDR, auto exposure, and data augmentation for training local feature detectors. Our work represents the first attempt to simulate a camera sensor's behavior leveraging both the advantage of traditional raw sensor features and the power of data-driven deep learning.
RANSIC: Fast and Highly Robust Estimation for Rotation Search and Point Cloud Registration using Invariant Compatibility
Apr 20, 2021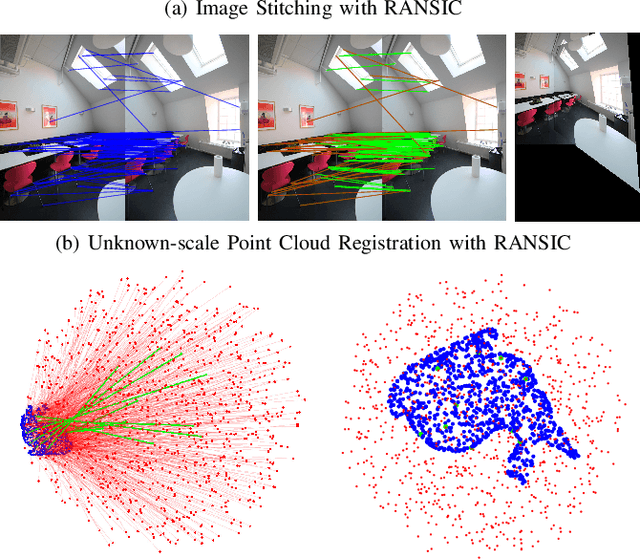
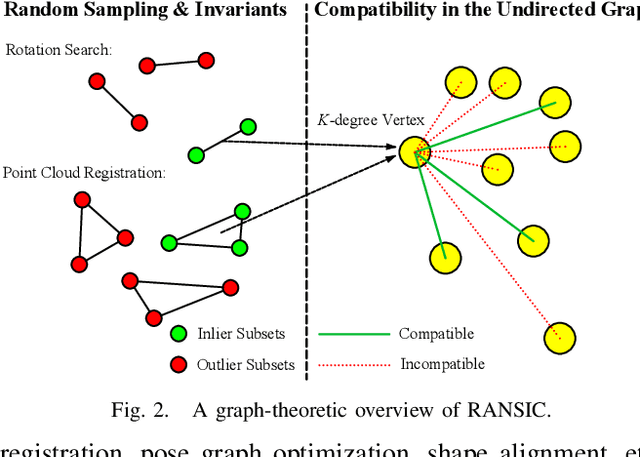
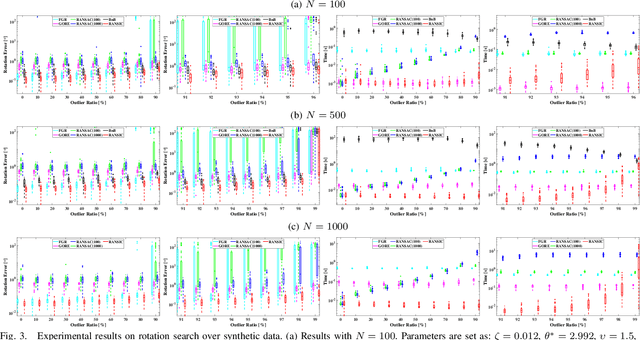
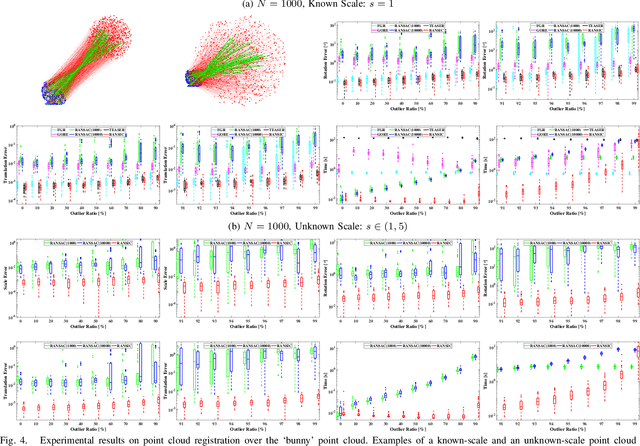
Correspondence-based rotation search and point cloud registration are two fundamental problems in robotics and computer vision. However, the presence of outliers, sometimes even occupying the great majority of the putative correspondences, can make many existing algorithms either fail or have very high computational cost. In this paper, we present RANSIC (RANdom Sampling with Invariant Compatibility), a fast and highly robust method applicable to both problems based on a new paradigm combining random sampling with invariance and compatibility. Generally, RANSIC starts with randomly selecting small subsets from the correspondence set, then seeks potential inliers as graph vertices from the random subsets through the compatibility tests of invariants established in each problem, and eventually returns the eligible inliers when there exists at least one K-degree vertex (K is automatically updated depending on the problem) and the residual errors satisfy a certain termination condition at the same time. In multiple synthetic and real experiments, we demonstrate that RANSIC is fast for use, robust against over 95% outliers, and also able to recall approximately 100% inliers, outperforming other state-of-the-art solvers for both the rotation search and the point cloud registration problems.
Recurrent Neural Filters: Learning Independent Bayesian Filtering Steps for Time Series Prediction
Jan 23, 2019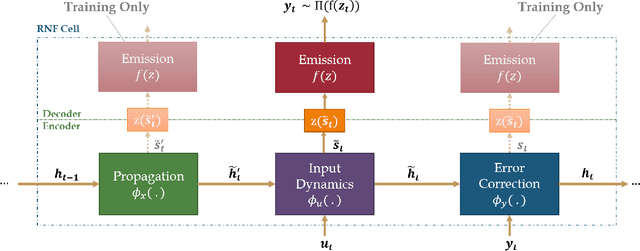
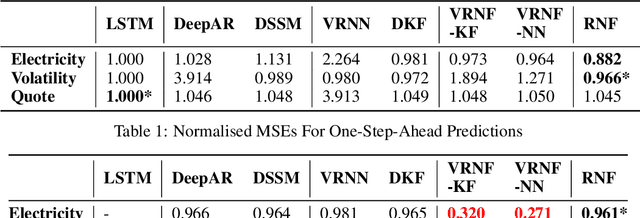
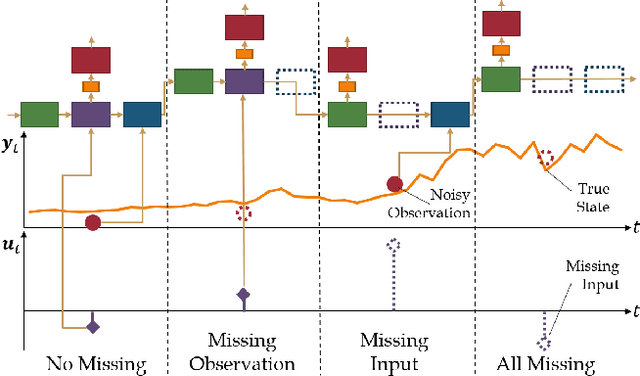
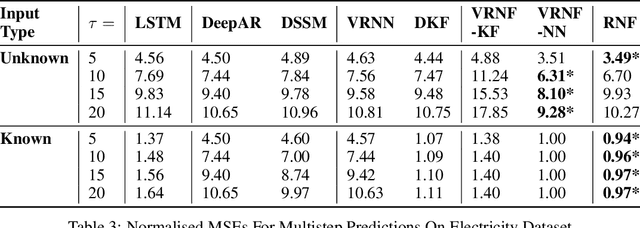
Despite the recent popularity of deep generative state space models, few comparisons have been made between network architectures and the inference steps of the Bayesian filtering framework -- with most models simultaneously approximating both state transition and update steps with a single recurrent neural network (RNN). In this paper, we introduce the Recurrent Neural Filter (RNF), a novel recurrent variational autoencoder architecture that learns distinct representations for each Bayesian filtering step, captured by a series of encoders and decoders. Testing this on three real-world time series datasets, we demonstrate that decoupling representations not only improves the accuracy of one-step-ahead forecasts while providing realistic uncertainty estimates, but also facilitates multistep prediction through the separation of encoder stages.
Convex Aggregation for Opinion Summarization
Apr 03, 2021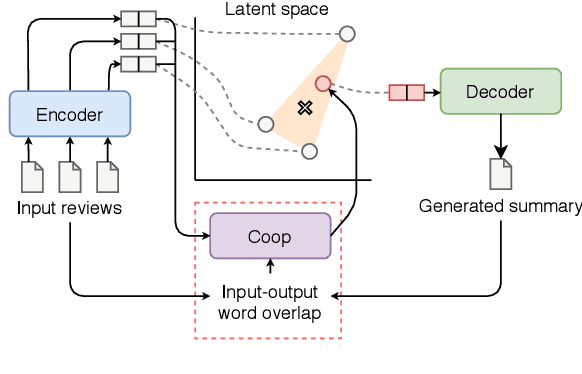
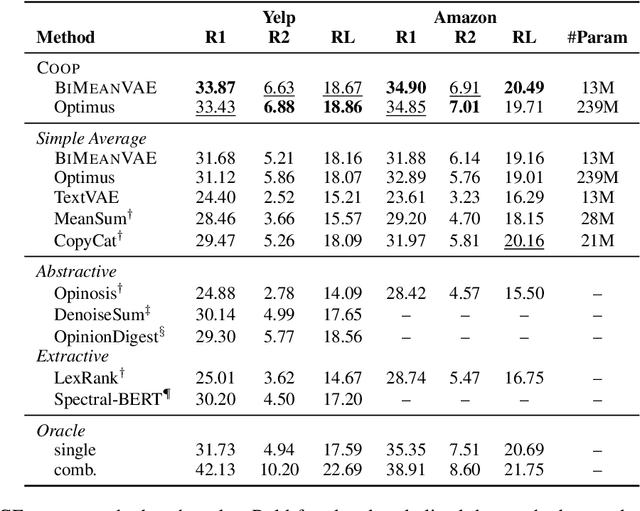
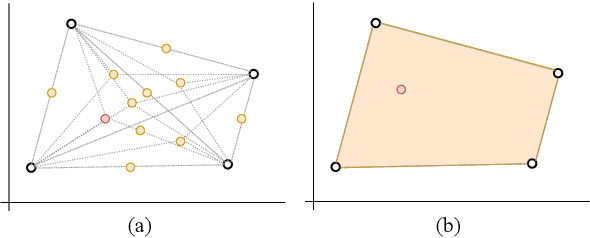
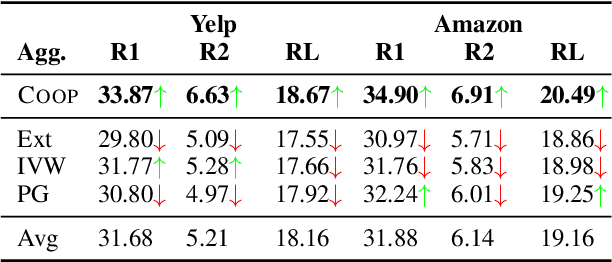
Recent approaches for unsupervised opinion summarization have predominantly used the review reconstruction training paradigm. An encoder-decoder model is trained to reconstruct single reviews and learns a latent review encoding space. At summarization time, the unweighted average of latent review vectors is decoded into a summary. In this paper, we challenge the convention of simply averaging the latent vector set, and claim that this simplistic approach fails to consider variations in the quality of input reviews or the idiosyncrasies of the decoder. We propose Coop, a convex vector aggregation framework for opinion summarization, that searches for better combinations of input reviews. Coop requires no further supervision and uses a simple word overlap objective to help the model generate summaries that are more consistent with input reviews. Experimental results show that extending opinion summarizers with Coop results in state-of-the-art performance, with ROUGE-1 improvements of 3.7% and 2.9% on the Yelp and Amazon benchmark datasets, respectively.
BeamLearning: an end-to-end Deep Learning approach for the angular localization of sound sources using raw multichannel acoustic pressure data
Apr 27, 2021Sound sources localization using multichannel signal processing has been a subject of active research for decades. In recent years, the use of deep learning in audio signal processing has allowed to drastically improve performances for machine hearing. This has motivated the scientific community to also develop machine learning strategies for source localization applications. In this paper, we present BeamLearning, a multi-resolution deep learning approach that allows to encode relevant information contained in unprocessed time domain acoustic signals captured by microphone arrays. The use of raw data aims at avoiding simplifying hypothesis that most traditional model-based localization methods rely on. Benefits of its use are shown for realtime sound source 2D-localization tasks in reverberating and noisy environments. Since supervised machine learning approaches require large-sized, physically realistic, precisely labelled datasets, we also developed a fast GPU-based computation of room impulse responses using fractional delays for image source models. A thorough analysis of the network representation and extensive performance tests are carried out using the BeamLearning network with synthetic and experimental datasets. Obtained results demonstrate that the BeamLearning approach significantly outperforms the wideband MUSIC and SRP-PHAT methods in terms of localization accuracy and computational efficiency in presence of heavy measurement noise and reverberation.
Identifying Helpful Sentences in Product Reviews
Apr 20, 2021
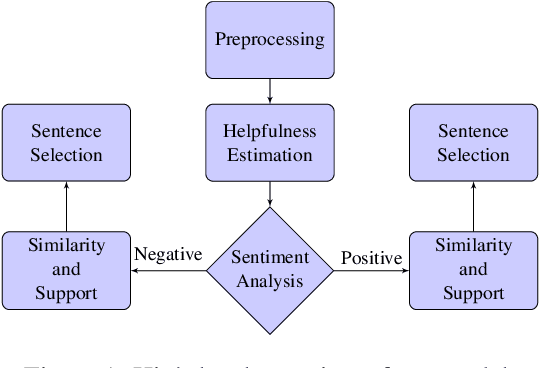

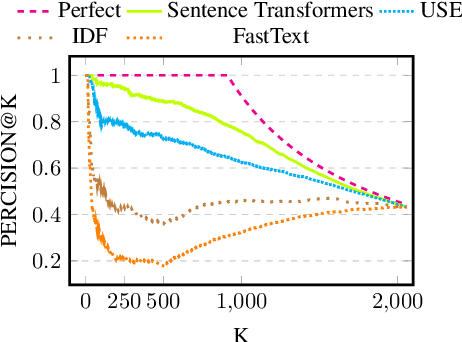
In recent years online shopping has gained momentum and became an important venue for customers wishing to save time and simplify their shopping process. A key advantage of shopping online is the ability to read what other customers are saying about products of interest. In this work, we aim to maintain this advantage in situations where extreme brevity is needed, for example, when shopping by voice. We suggest a novel task of extracting a single representative helpful sentence from a set of reviews for a given product. The selected sentence should meet two conditions: first, it should be helpful for a purchase decision and second, the opinion it expresses should be supported by multiple reviewers. This task is closely related to the task of Multi Document Summarization in the product reviews domain but differs in its objective and its level of conciseness. We collect a dataset in English of sentence helpfulness scores via crowd-sourcing and demonstrate its reliability despite the inherent subjectivity involved. Next, we describe a complete model that extracts representative helpful sentences with positive and negative sentiment towards the product and demonstrate that it outperforms several baselines.
Does enhanced shape bias improve neural network robustness to common corruptions?
Apr 20, 2021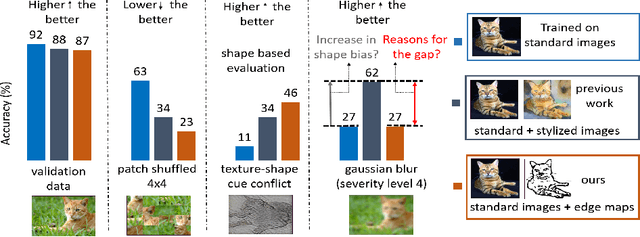
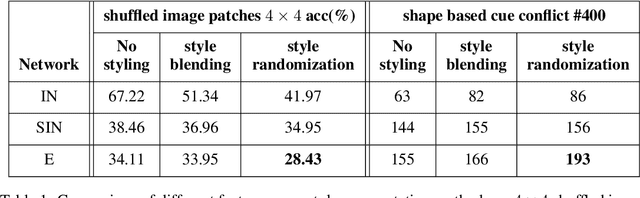

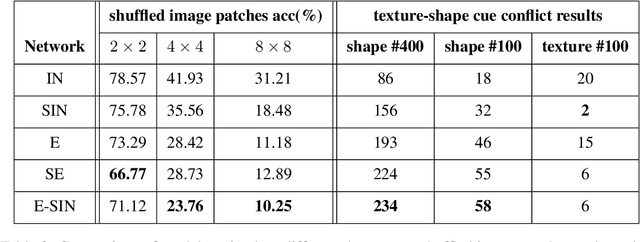
Convolutional neural networks (CNNs) learn to extract representations of complex features, such as object shapes and textures to solve image recognition tasks. Recent work indicates that CNNs trained on ImageNet are biased towards features that encode textures and that these alone are sufficient to generalize to unseen test data from the same distribution as the training data but often fail to generalize to out-of-distribution data. It has been shown that augmenting the training data with different image styles decreases this texture bias in favor of increased shape bias while at the same time improving robustness to common corruptions, such as noise and blur. Commonly, this is interpreted as shape bias increasing corruption robustness. However, this relationship is only hypothesized. We perform a systematic study of different ways of composing inputs based on natural images, explicit edge information, and stylization. While stylization is essential for achieving high corruption robustness, we do not find a clear correlation between shape bias and robustness. We conclude that the data augmentation caused by style-variation accounts for the improved corruption robustness and increased shape bias is only a byproduct.