 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparing Popular Simulation Environments in the Scope of Robotics and Reinforcement Learning
Mar 08, 2021

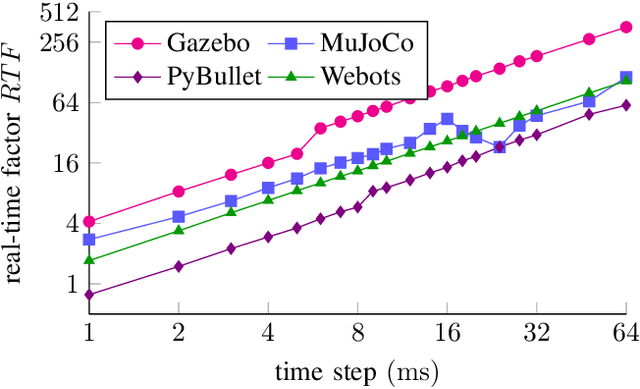
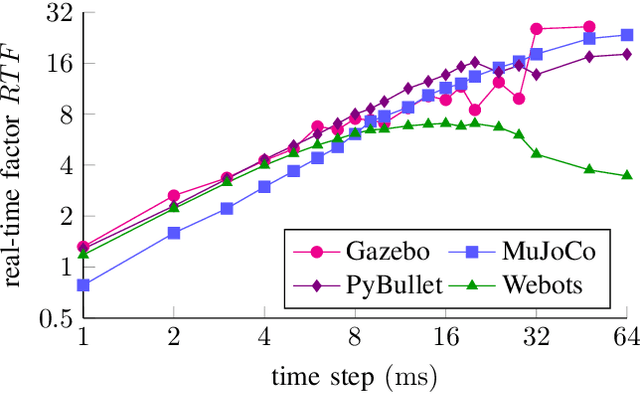
This letter compares the performance of four different, popular simulation environments for robotics and reinforcement learning (RL) through a series of benchmarks. The benchmarked scenarios are designed carefully with current industrial applications in mind. Given the need to run simulations as fast as possible to reduce the real-world training time of the RL agents, the comparison includes not only different simulation environments but also different hardware configurations, ranging from an entry-level notebook up to a dual CPU high performance server. We show that the chosen simulation environments benefit the most from single core performance. Yet, using a multi core system, multiple simulations could be run in parallel to increase the performance.
Obstacle avoidance-driven controller for safety-critical aerial robots
Nov 19, 2020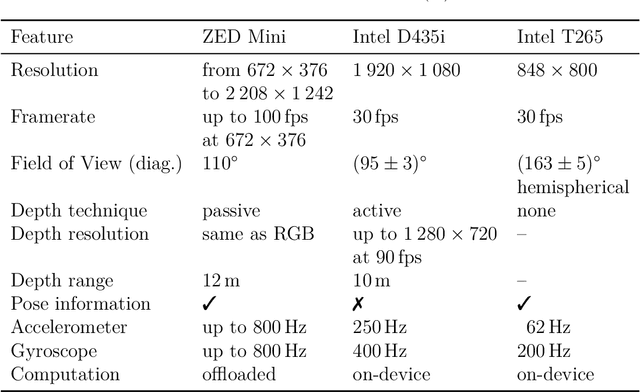
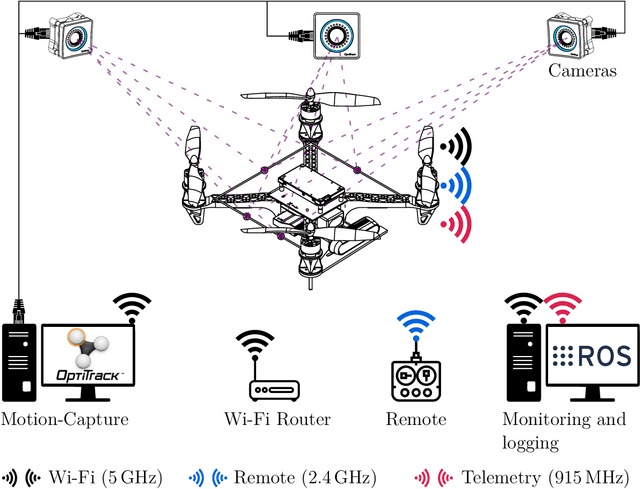
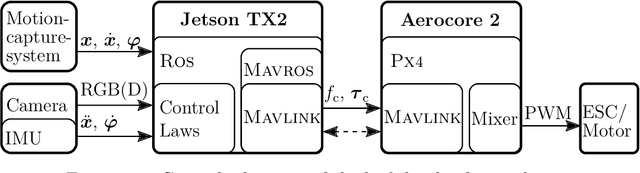
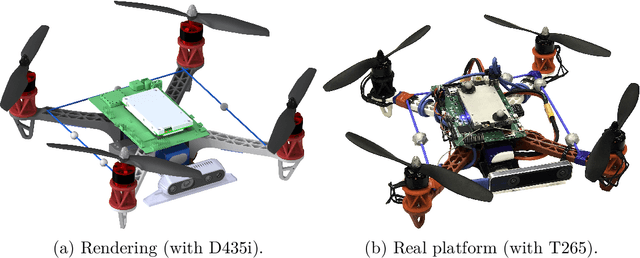
The goal of this thesis is to propose the combination of Control-Barrier-Functions (CBF) with Model-Predictive-Control (MPC) resulting in the novel Model-Predictive-Control-Barrier-Function (MPCBF). It can be shown, that the performance of the MPCBF surpasses the performance of the CBF due to the increased time horizon of the MPC. Moreover, the MPCBF was applied to a quadrotor, a system strongly in need of fast and predictive control. Using the MPCBF, the quadrotor was able to avoid obstacles, which the CBF failed to avoid due to the relative speed of the obstacle. The results of this work are experimentally validated.