 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Safe Model-based Off-policy Reinforcement Learning for Eco-Driving in Connected and Automated Hybrid Electric Vehicles
May 25, 2021
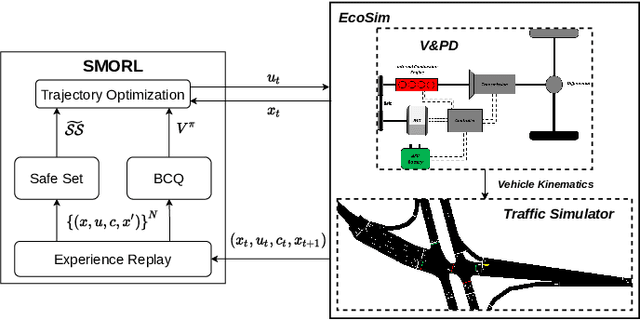
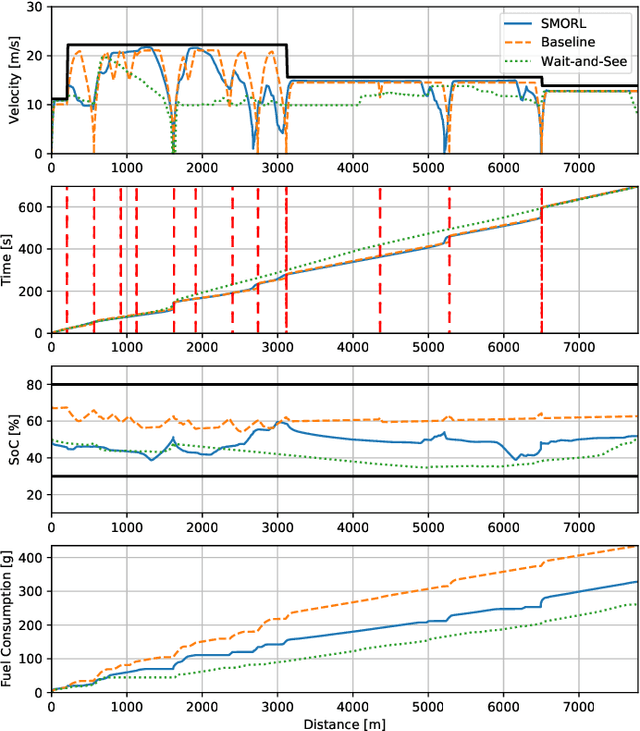
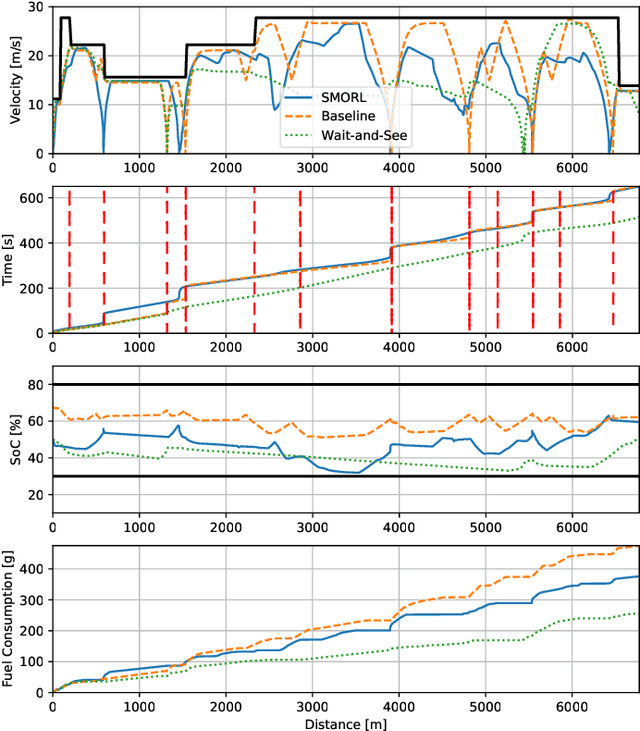
Connected and Automated Hybrid Electric Vehicles have the potential to reduce fuel consumption and travel time in real-world driving conditions. The eco-driving problem seeks to design optimal speed and power usage profiles based upon look-ahead information from connectivity and advanced mapping features. Recently, Deep Reinforcement Learning (DRL) has been applied to the eco-driving problem. While the previous studies synthesize simulators and model-free DRL to reduce online computation, this work proposes a Safe Off-policy Model-Based Reinforcement Learning algorithm for the eco-driving problem. The advantages over the existing literature are three-fold. First, the combination of off-policy learning and the use of a physics-based model improves the sample efficiency. Second, the training does not require any extrinsic rewarding mechanism for constraint satisfaction. Third, the feasibility of trajectory is guaranteed by using a safe set approximated by deep generative models. The performance of the proposed method is benchmarked against a baseline controller representing human drivers, a previously designed model-free DRL strategy, and the wait-and-see optimal solution. In simulation, the proposed algorithm leads to a policy with a higher average speed and a better fuel economy compared to the model-free agent. Compared to the baseline controller, the learned strategy reduces the fuel consumption by more than 21\% while keeping the average speed comparable.
Benchmarking down-scaled (not so large) pre-trained language models
May 11, 2021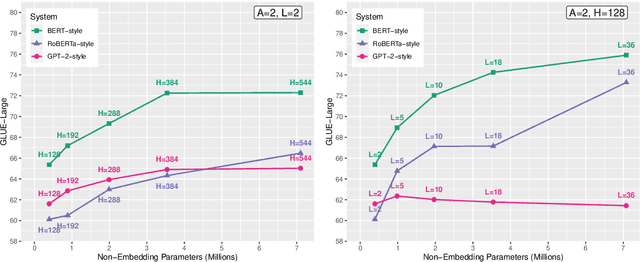
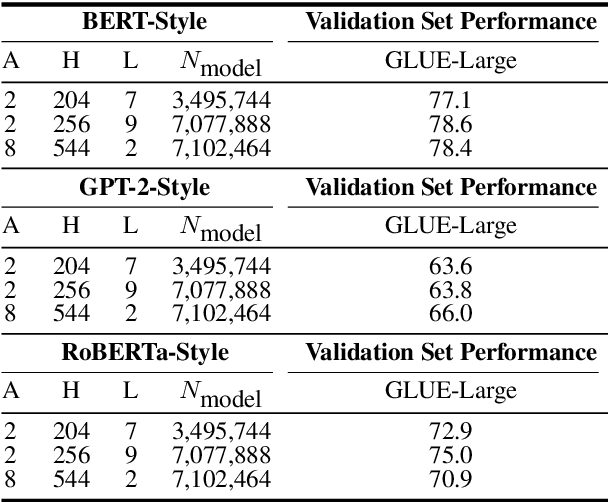
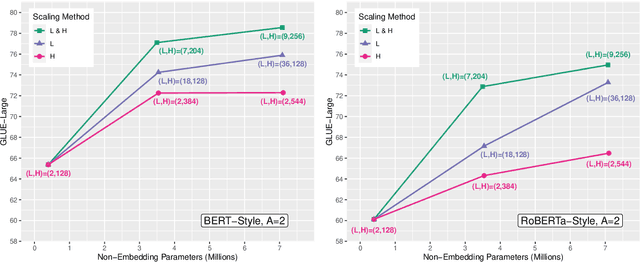
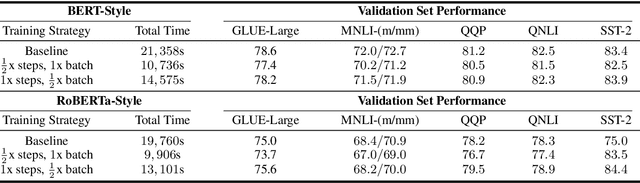
Large Transformer-based language models are pre-trained on corpora of varying sizes, for a different number of steps and with different batch sizes. At the same time, more fundamental components, such as the pre-training objective or architectural hyperparameters, are modified. In total, it is therefore difficult to ascribe changes in performance to specific factors. Since searching the hyperparameter space over the full systems is too costly, we pre-train down-scaled versions of several popular Transformer-based architectures on a common pre-training corpus and benchmark them on a subset of the GLUE tasks (Wang et al., 2018). Specifically, we systematically compare three pre-training objectives for different shape parameters and model sizes, while also varying the number of pre-training steps and the batch size. In our experiments MLM + NSP (BERT-style) consistently outperforms MLM (RoBERTa-style) as well as the standard LM objective. Furthermore, we find that additional compute should be mainly allocated to an increased model size, while training for more steps is inefficient. Based on these observations, as a final step we attempt to scale up several systems using compound scaling (Tan and Le, 2019) adapted to Transformer-based language models.
Estimation and Quantization of Expected Persistence Diagrams
May 11, 2021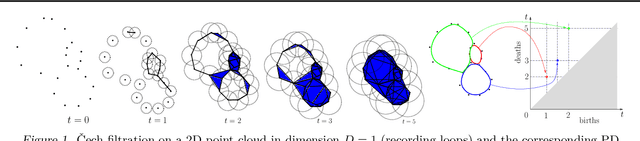
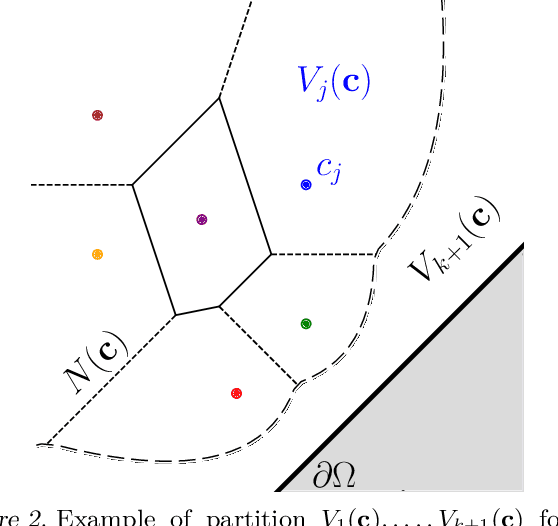
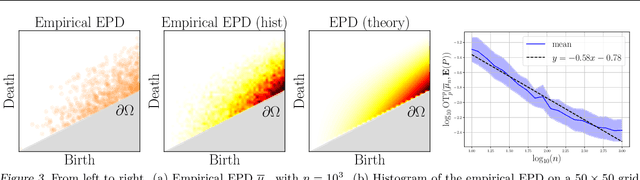
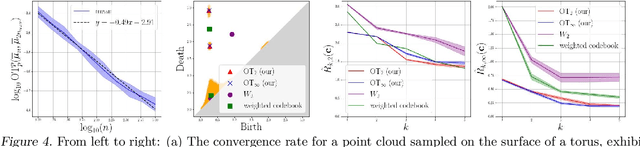
Persistence diagrams (PDs) are the most common descriptors used to encode the topology of structured data appearing in challenging learning tasks; think e.g. of graphs, time series or point clouds sampled close to a manifold. Given random objects and the corresponding distribution of PDs, one may want to build a statistical summary-such as a mean-of these random PDs, which is however not a trivial task as the natural geometry of the space of PDs is not linear. In this article, we study two such summaries, the Expected Persistence Diagram (EPD), and its quantization. The EPD is a measure supported on R 2 , which may be approximated by its empirical counterpart. We prove that this estimator is optimal from a minimax standpoint on a large class of models with a parametric rate of convergence. The empirical EPD is simple and efficient to compute, but possibly has a very large support, hindering its use in practice. To overcome this issue, we propose an algorithm to compute a quantization of the empirical EPD, a measure with small support which is shown to approximate with near-optimal rates a quantization of the theoretical EPD.
FDMA-CDMA Mode CAOS Camera Demonstration using UV to NIR Full Spectrum
Jan 06, 2021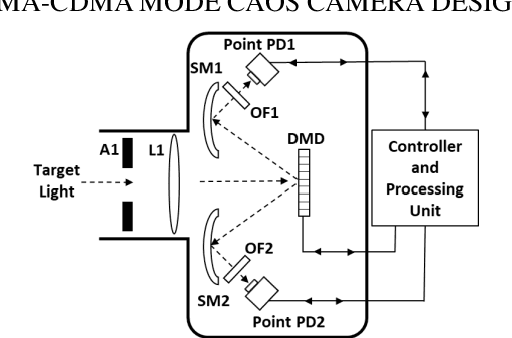
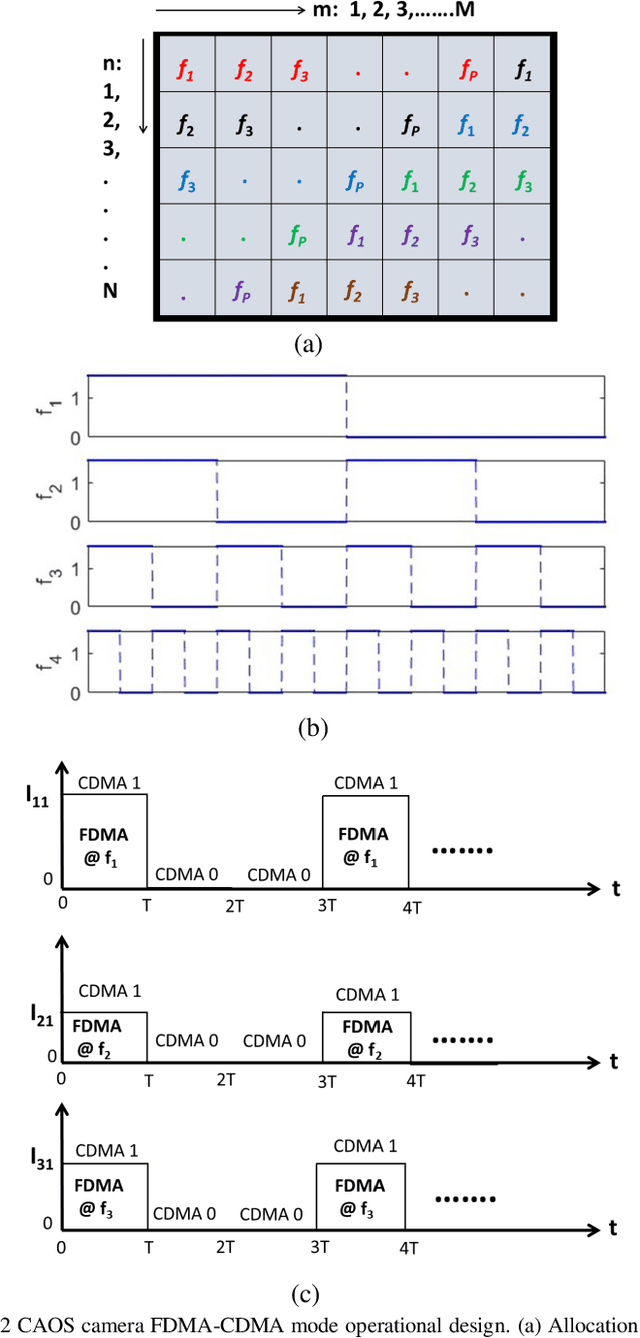
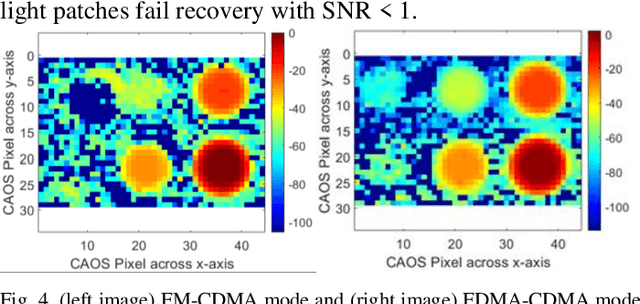
For the first time, the hybrid Frequency Division Multiple Access (FDMA) Code Division Multiple Access (CDMA) mode of the CAOS (i.e., Coded Access Optical Sensor) camera is demonstrated. The FDMA CDMA mode is a time frequency double signal encoding design for robust and faster linear High Dynamic Range (HDR) image irradiance extraction. Specifically, it simultaneously combines the strength of the FDMA-mode linear HDR Fast Fourier Transform (FFT) Digital Signal Processing (DSP) based spectrum analysis with the CDMA mode provided many simultaneous CAOS pixels high Signal to Noise Ratio (SNR) photo-detection. The FDMA CDMA mode with P FDMA channels provides a faster camera operation versus the linear HDR Frequency Modulation (FM) CDMA mode. Visible band imaging experiments using a Digital Micromirror Device (DMD) based CAOS camera demonstrate a P equal to 4 channels FDMA CDMA mode high quality image recovery of a calibrated 64 dB 6 patches HDR target versus the CDMA and FM CDMA CAOS modes that limit dynamic range and speed, respectively. Simultaneous dual image capture capability of the FDMA-CDMA mode is also demonstrated for the first time in Ultraviolet (UV) to Near Infrared (NIR) 350 to 1800 nm full spectrum using Silicon (Si) and Germanium (Ge) point photo-detectors.
Globally-Robust Neural Networks
Feb 16, 2021
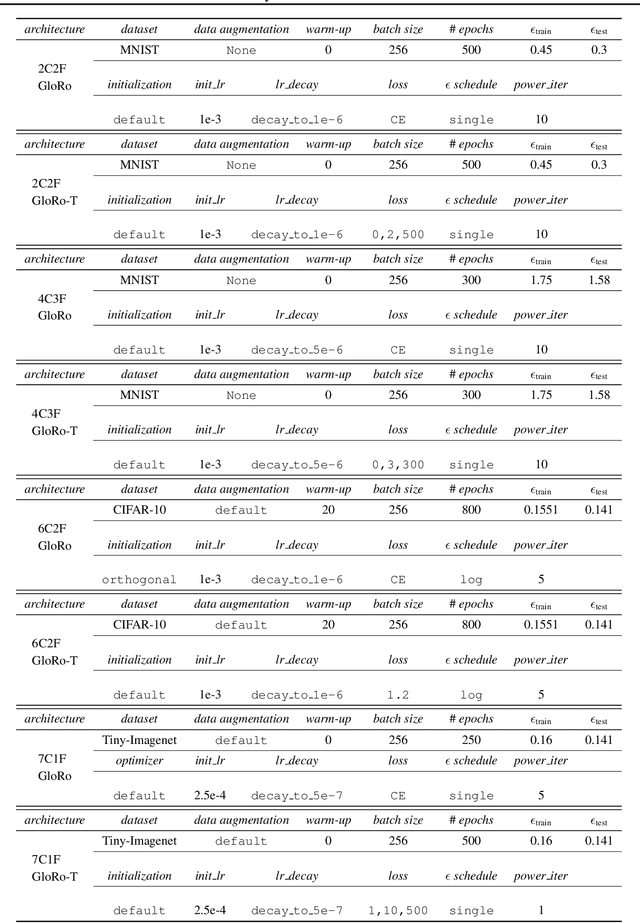
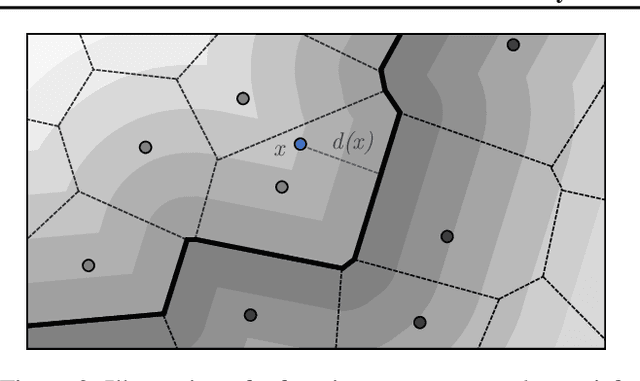
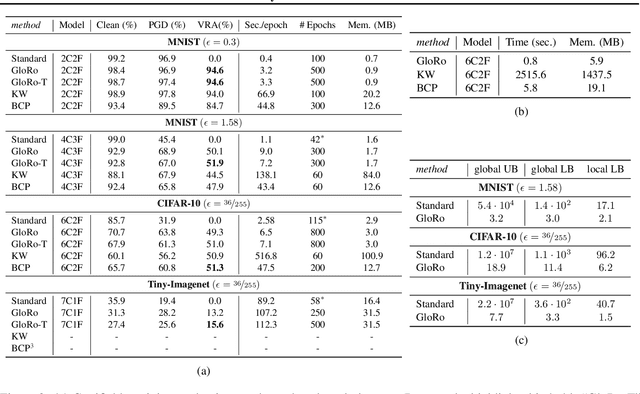
The threat of adversarial examples has motivated work on training certifiably robust neural networks, to facilitate efficient verification of local robustness at inference time. We formalize a notion of global robustness, which captures the operational properties of on-line local robustness certification while yielding a natural learning objective for robust training. We show that widely-used architectures can be easily adapted to this objective by incorporating efficient global Lipschitz bounds into the network, yielding certifiably-robust models by construction that achieve state-of-the-art verifiable and clean accuracy. Notably, this approach requires significantly less time and memory than recent certifiable training methods, and leads to negligible costs when certifying points on-line; for example, our evaluation shows that it is possible to train a large tiny-imagenet model in a matter of hours. We posit that this is possible using inexpensive global bounds -- despite prior suggestions that tighter local bounds are needed for good performance -- because these models are trained to achieve tighter global bounds. Namely, we prove that the maximum achievable verifiable accuracy for a given dataset is not improved by using a local bound.
Learning What To Do by Simulating the Past
May 03, 2021
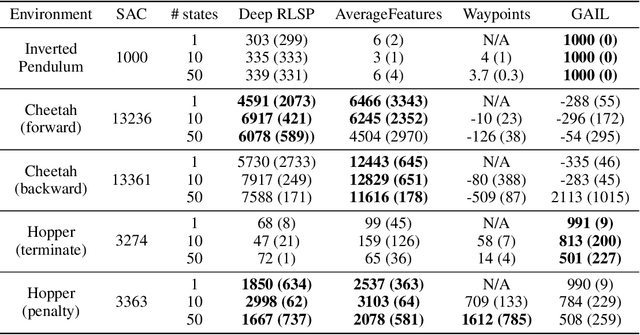

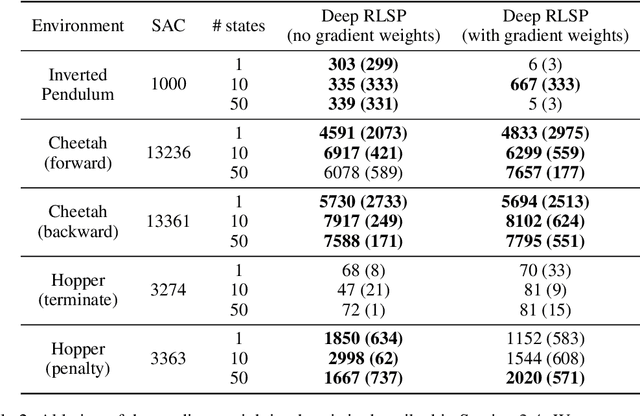
Since reward functions are hard to specify, recent work has focused on learning policies from human feedback. However, such approaches are impeded by the expense of acquiring such feedback. Recent work proposed that agents have access to a source of information that is effectively free: in any environment that humans have acted in, the state will already be optimized for human preferences, and thus an agent can extract information about what humans want from the state. Such learning is possible in principle, but requires simulating all possible past trajectories that could have led to the observed state. This is feasible in gridworlds, but how do we scale it to complex tasks? In this work, we show that by combining a learned feature encoder with learned inverse models, we can enable agents to simulate human actions backwards in time to infer what they must have done. The resulting algorithm is able to reproduce a specific skill in MuJoCo environments given a single state sampled from the optimal policy for that skill.
Generalized Linear Tree Space Nearest Neighbor
Mar 30, 2021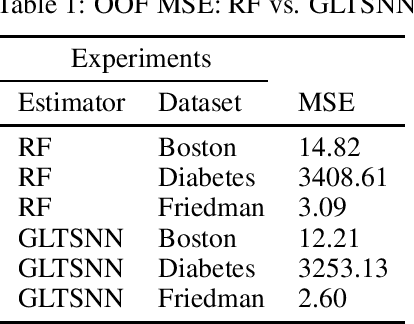
We present a novel method of stacking decision trees by projection into an ordered time split out-of-fold (OOF) one nearest neighbor (1NN) space. The predictions of these one nearest neighbors are combined through a linear model. This process is repeated many times and averaged to reduce variance. Generalized Linear Tree Space Nearest Neighbor (GLTSNN) is competitive with respect to Mean Squared Error (MSE) compared to Random Forest (RF) on several publicly available datasets. Some of the theoretical and applied advantages of GLTSNN are discussed. We conjecture a classifier based upon the GLTSNN would have an error that is asymptotically bounded by twice the Bayes error rate like k = 1 Nearest Neighbor.
Same State, Different Task: Continual Reinforcement Learning without Interference
Jun 05, 2021



Continual Learning (CL) considers the problem of training an agent sequentially on a set of tasks while seeking to retain performance on all previous tasks. A key challenge in CL is catastrophic forgetting, which arises when performance on a previously mastered task is reduced when learning a new task. While a variety of methods exist to combat forgetting, in some cases tasks are fundamentally incompatible with each other and thus cannot be learnt by a single policy. This can occur, in reinforcement learning (RL) when an agent may be rewarded for achieving different goals from the same observation. In this paper we formalize this ``interference'' as distinct from the problem of forgetting. We show that existing CL methods based on single neural network predictors with shared replay buffers fail in the presence of interference. Instead, we propose a simple method, OWL, to address this challenge. OWL learns a factorized policy, using shared feature extraction layers, but separate heads, each specializing on a new task. The separate heads in OWL are used to prevent interference. At test time, we formulate policy selection as a multi-armed bandit problem, and show it is possible to select the best policy for an unknown task using feedback from the environment. The use of bandit algorithms allows the OWL agent to constructively re-use different continually learnt policies at different times during an episode. We show in multiple RL environments that existing replay based CL methods fail, while OWL is able to achieve close to optimal performance when training sequentially.
Availability-Based Production Predicts Speakers' Real-time Choices of Mandarin Classifiers
May 17, 2019
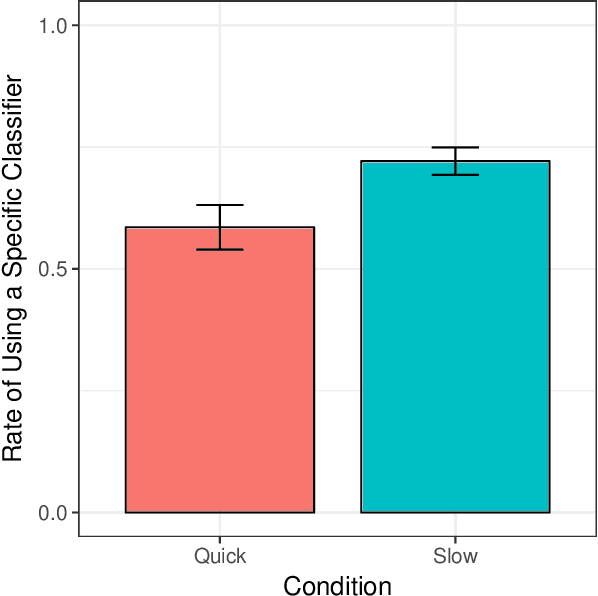
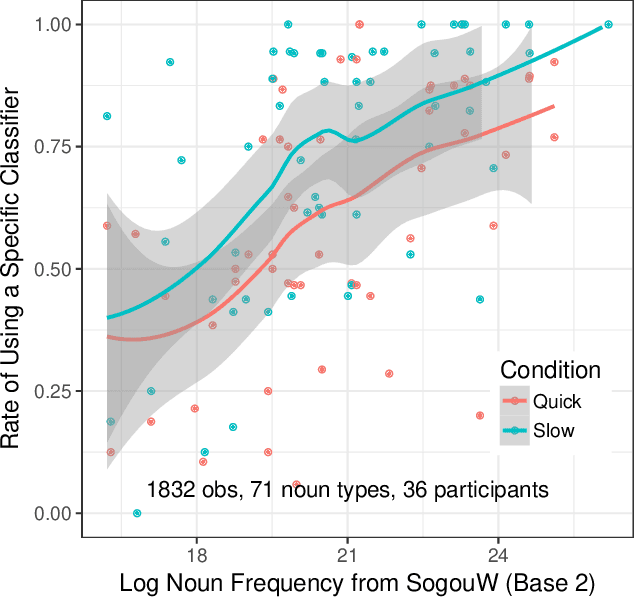
Speakers often face choices as to how to structure their intended message into an utterance. Here we investigate the influence of contextual predictability on the encoding of linguistic content manifested by speaker choice in a classifier language. In English, a numeral modifies a noun directly (e.g., three computers). In classifier languages such as Mandarin Chinese, it is obligatory to use a classifier (CL) with the numeral and the noun (e.g., three CL.machinery computer, three CL.general computer). While different nouns are compatible with different specific classifiers, there is a general classifier "ge" (CL.general) that can be used with most nouns. When the upcoming noun is less predictable, the use of a more specific classifier would reduce surprisal at the noun thus potentially facilitate comprehension (predicted by Uniform Information Density, Levy & Jaeger, 2007), but the use of that more specific classifier may be dispreferred from a production standpoint if accessing the general classifier is always available (predicted by Availability-Based Production; Bock, 1987; Ferreira & Dell, 2000). Here we use a picture-naming experiment showing that Availability-Based Production predicts speakers' real-time choices of Mandarin classifiers.
Width Transfer: On the (In)variance of Width Optimization
Apr 24, 2021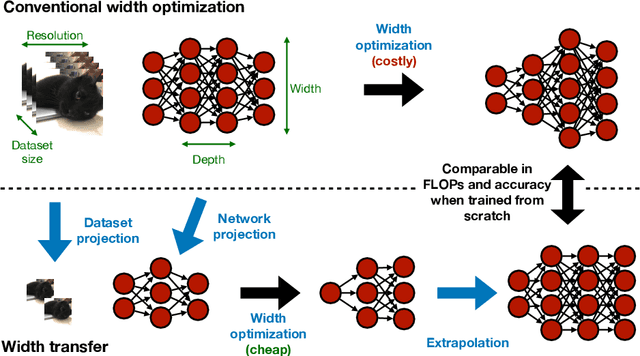

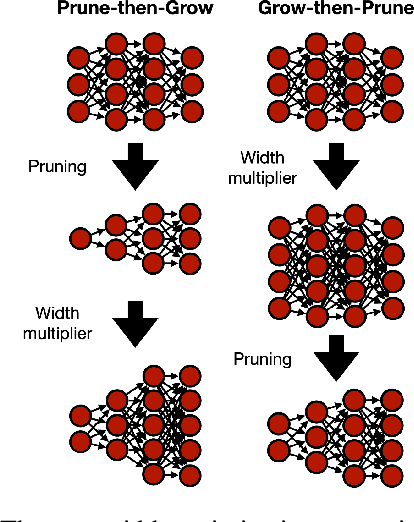
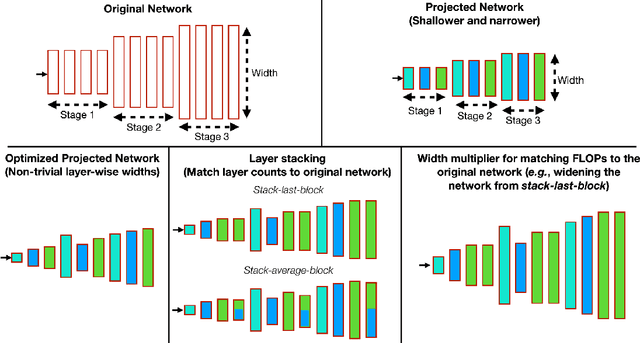
Optimizing the channel counts for different layers of a CNN has shown great promise in improving the efficiency of CNNs at test-time. However, these methods often introduce large computational overhead (e.g., an additional 2x FLOPs of standard training). Minimizing this overhead could therefore significantly speed up training. In this work, we propose width transfer, a technique that harnesses the assumptions that the optimized widths (or channel counts) are regular across sizes and depths. We show that width transfer works well across various width optimization algorithms and networks. Specifically, we can achieve up to 320x reduction in width optimization overhead without compromising the top-1 accuracy on ImageNet, making the additional cost of width optimization negligible relative to initial training. Our findings not only suggest an efficient way to conduct width optimization but also highlight that the widths that lead to better accuracy are invariant to various aspects of network architectures and training data.