 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAngle of Arrival Estimation with Transformer: A Sparse and Gridless Method with Zero-Shot Capability
Aug 18, 2024Automotive Multiple-Input Multiple-Output (MIMO) radars have gained significant traction in Advanced Driver Assistance Systems (ADAS) and Autonomous Vehicles (AV) due to their cost-effectiveness, resilience to challenging operating conditions, and extended detection range. To fully leverage the advantages of MIMO radars, it is crucial to develop an Angle of Arrival (AOA) algorithm that delivers high performance with reasonable computational workload. This work introduces AAETR (Angle of Arrival Estimation with TRansformer) for high performance gridless AOA estimation. Comprehensive evaluations across various signal-to-noise ratios (SNRs) and multi-target scenarios demonstrate AAETR's superior performance compared to super resolution AOA algorithms such as Iterative Adaptive Approach (IAA). The proposed architecture features efficient, scalable, sparse and gridless angle-finding capability, overcoming the issues of high computational cost and straddling loss in SNR associated with grid-based IAA. AAETR requires fewer tunable hyper-parameters and is end-to-end trainable in a deep learning radar perception pipeline. When trained on large-scale simulated datasets then evaluated on real dataset, AAETR exhibits remarkable zero-shot sim-to-real transferability and emergent sidelobe suppression capability. This highlights the effectiveness of the proposed approach and its potential as a drop-in module in practical systems.
Eco-Driving Control of Connected and Automated Vehicles using Neural Network based Rollout
Oct 16, 2023Connected and autonomous vehicles have the potential to minimize energy consumption by optimizing the vehicle velocity and powertrain dynamics with Vehicle-to-Everything info en route. Existing deterministic and stochastic methods created to solve the eco-driving problem generally suffer from high computational and memory requirements, which makes online implementation challenging. This work proposes a hierarchical multi-horizon optimization framework implemented via a neural network. The neural network learns a full-route value function to account for the variability in route information and is then used to approximate the terminal cost in a receding horizon optimization. Simulations over real-world routes demonstrate that the proposed approach achieves comparable performance to a stochastic optimization solution obtained via reinforcement learning, while requiring no sophisticated training paradigm and negligible on-board memory.
Safe Model-based Off-policy Reinforcement Learning for Eco-Driving in Connected and Automated Hybrid Electric Vehicles
May 25, 2021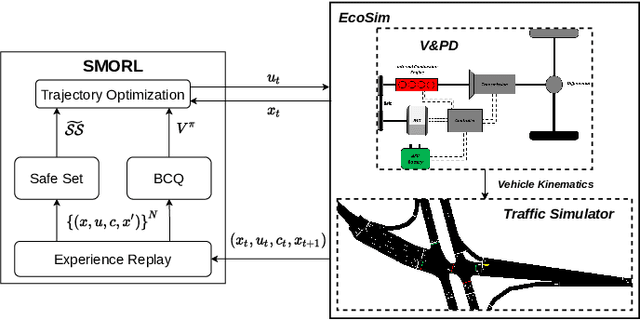
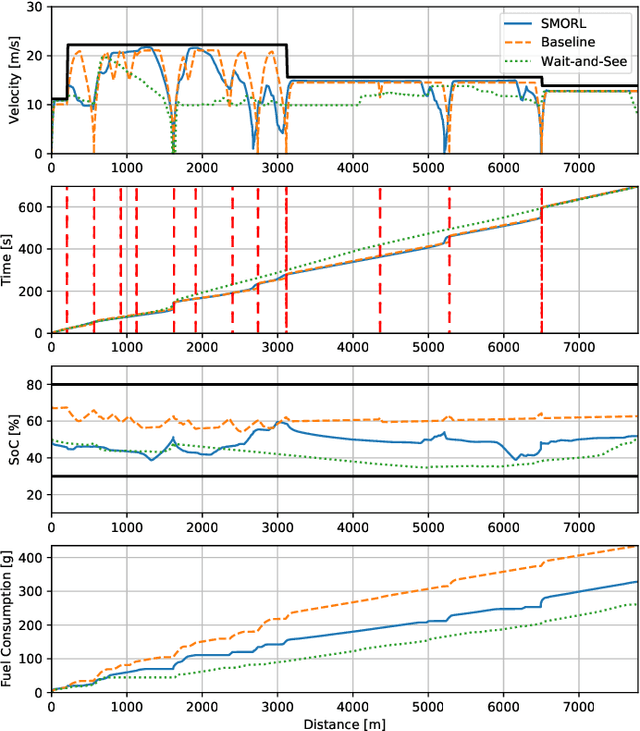
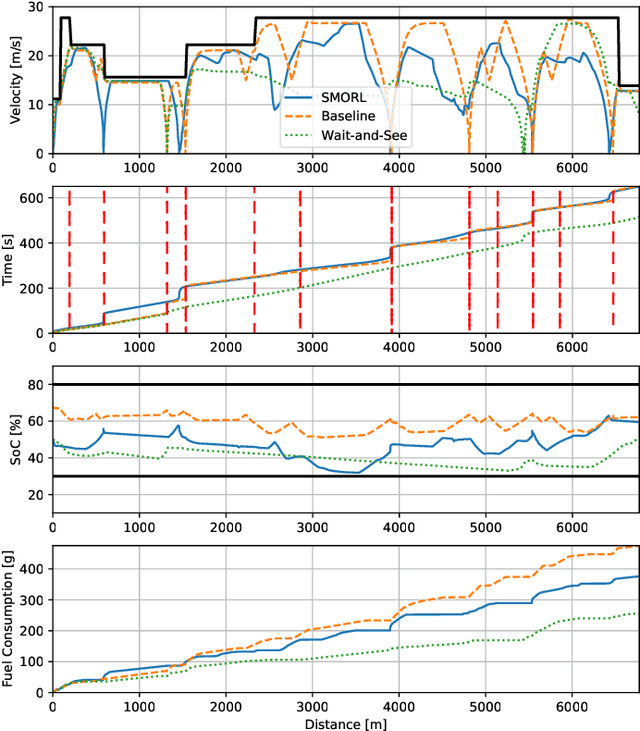
Connected and Automated Hybrid Electric Vehicles have the potential to reduce fuel consumption and travel time in real-world driving conditions. The eco-driving problem seeks to design optimal speed and power usage profiles based upon look-ahead information from connectivity and advanced mapping features. Recently, Deep Reinforcement Learning (DRL) has been applied to the eco-driving problem. While the previous studies synthesize simulators and model-free DRL to reduce online computation, this work proposes a Safe Off-policy Model-Based Reinforcement Learning algorithm for the eco-driving problem. The advantages over the existing literature are three-fold. First, the combination of off-policy learning and the use of a physics-based model improves the sample efficiency. Second, the training does not require any extrinsic rewarding mechanism for constraint satisfaction. Third, the feasibility of trajectory is guaranteed by using a safe set approximated by deep generative models. The performance of the proposed method is benchmarked against a baseline controller representing human drivers, a previously designed model-free DRL strategy, and the wait-and-see optimal solution. In simulation, the proposed algorithm leads to a policy with a higher average speed and a better fuel economy compared to the model-free agent. Compared to the baseline controller, the learned strategy reduces the fuel consumption by more than 21\% while keeping the average speed comparable.