 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking down-scaled (not so large) pre-trained language models
May 11, 2021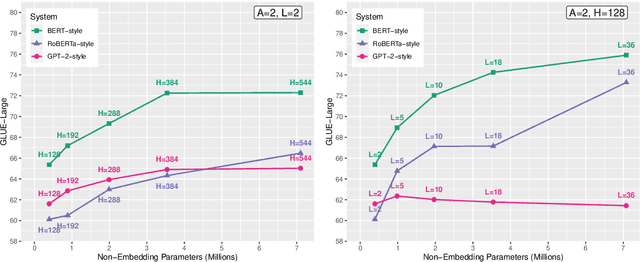
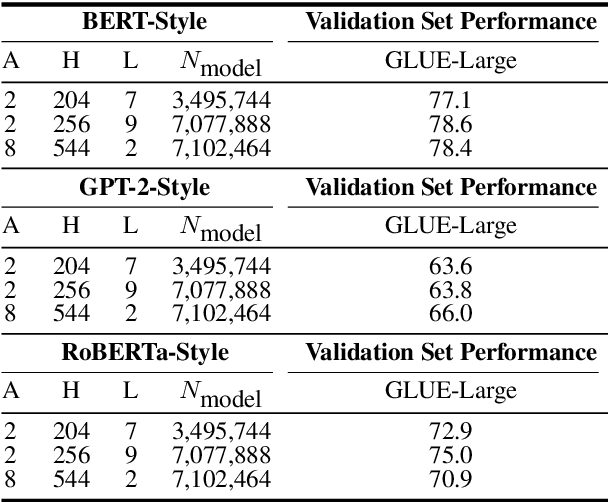
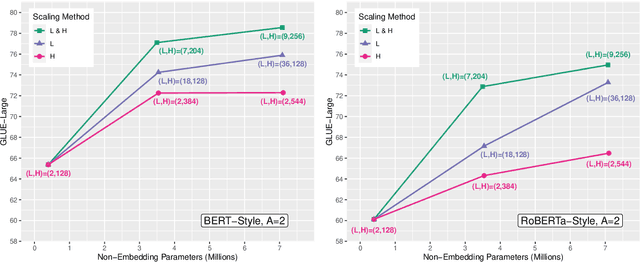
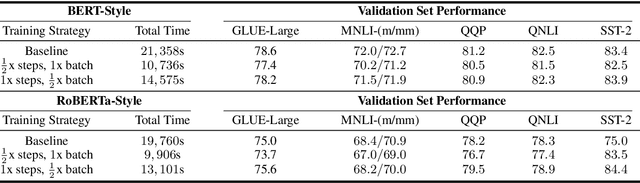
Large Transformer-based language models are pre-trained on corpora of varying sizes, for a different number of steps and with different batch sizes. At the same time, more fundamental components, such as the pre-training objective or architectural hyperparameters, are modified. In total, it is therefore difficult to ascribe changes in performance to specific factors. Since searching the hyperparameter space over the full systems is too costly, we pre-train down-scaled versions of several popular Transformer-based architectures on a common pre-training corpus and benchmark them on a subset of the GLUE tasks (Wang et al., 2018). Specifically, we systematically compare three pre-training objectives for different shape parameters and model sizes, while also varying the number of pre-training steps and the batch size. In our experiments MLM + NSP (BERT-style) consistently outperforms MLM (RoBERTa-style) as well as the standard LM objective. Furthermore, we find that additional compute should be mainly allocated to an increased model size, while training for more steps is inefficient. Based on these observations, as a final step we attempt to scale up several systems using compound scaling (Tan and Le, 2019) adapted to Transformer-based language models.
Exploring Topic-Metadata Relationships with the STM: A Bayesian Approach
Apr 06, 2021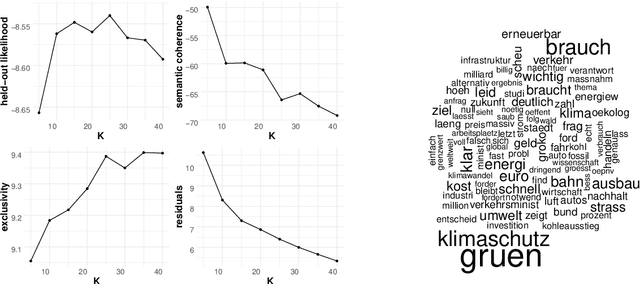
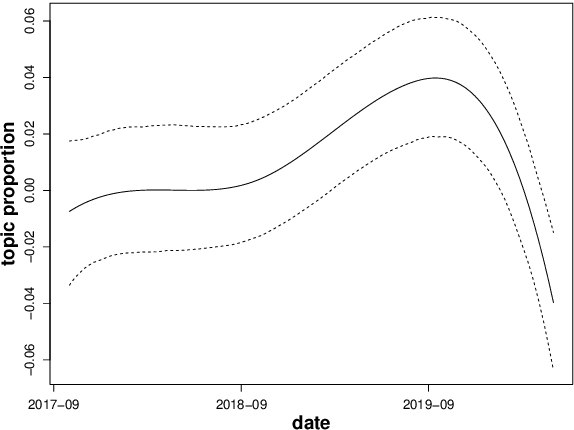
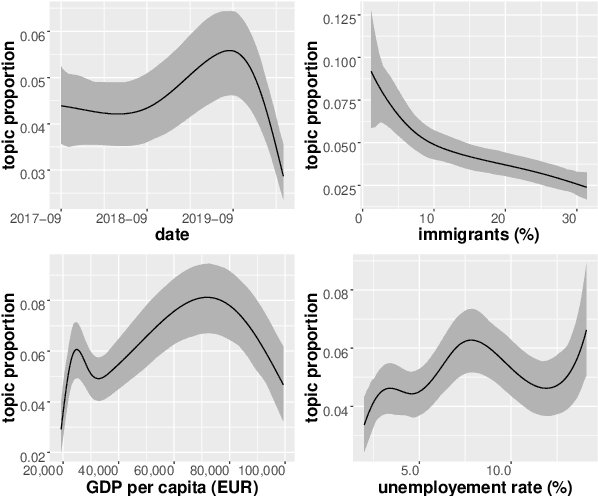
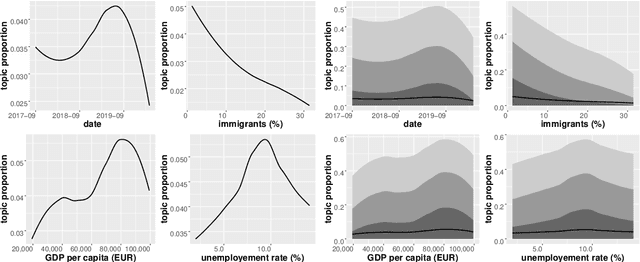
Topic models such as the Structural Topic Model (STM) estimate latent topical clusters within text. An important step in many topic modeling applications is to explore relationships between the discovered topical structure and metadata associated with the text documents. Methods used to estimate such relationships must take into account that the topical structure is not directly observed, but instead being estimated itself. The authors of the STM, for instance, perform repeated OLS regressions of sampled topic proportions on metadata covariates by using a Monte Carlo sampling technique known as the method of composition. In this paper, we propose two improvements: first, we replace OLS with more appropriate Beta regression. Second, we suggest a fully Bayesian approach instead of the current blending of frequentist and Bayesian methods. We demonstrate our improved methodology by exploring relationships between Twitter posts by German members of parliament (MPs) and different metadata covariates.
Re-Evaluating GermEval17 Using German Pre-Trained Language Models
Feb 24, 2021
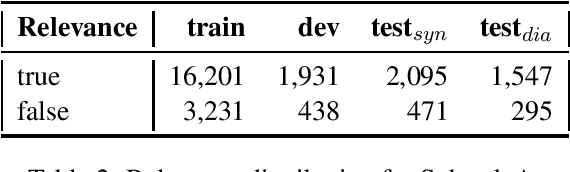
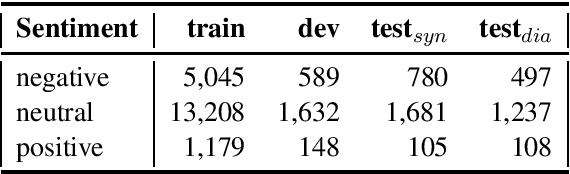
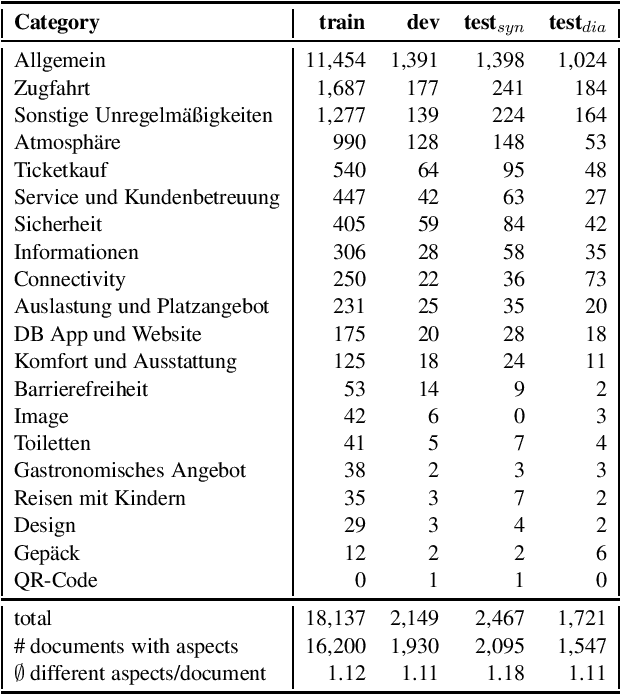
The lack of a commonly used benchmark data set (collection) such as (Super-)GLUE (Wang et al., 2018, 2019) for the evaluation of non-English pre-trained language models is a severe shortcoming of current English-centric NLP-research. It concentrates a large part of the research on English, neglecting the uncertainty when transferring conclusions found for the English language to other languages. We evaluate the performance of the German and multilingual BERT-based models currently available via the huggingface transformers library on the four tasks of the GermEval17 workshop. We compare them to pre-BERT architectures (Wojatzki et al., 2017; Schmitt et al., 2018; Attia et al., 2018) as well as to an ELMo-based architecture (Biesialska et al., 2020) and a BERT-based approach (Guhr et al., 2020). The observed improvements are put in relation to those for similar tasks and similar models (pre-BERT vs. BERT-based) for the English language in order to draw tentative conclusions about whether the observed improvements are transferable to German or potentially other related languages.
Pre-trained language models as knowledge bases for Automotive Complaint Analysis
Dec 04, 2020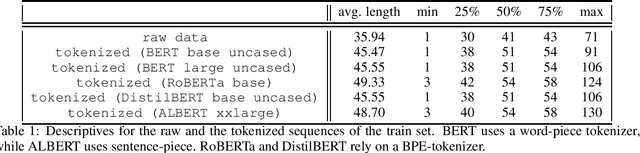

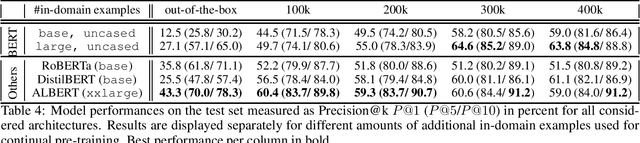
Recently it has been shown that large pre-trained language models like BERT (Devlin et al., 2018) are able to store commonsense factual knowledge captured in its pre-training corpus (Petroni et al., 2019). In our work we further evaluate this ability with respect to an application from industry creating a set of probes specifically designed to reveal technical quality issues captured as described incidents out of unstructured customer feedback in the automotive industry. After probing the out-of-the-box versions of the pre-trained models with fill-in-the-mask tasks we dynamically provide it with more knowledge via continual pre-training on the Office of Defects Investigation (ODI) Complaints data set. In our experiments the models exhibit performance regarding queries on domain-specific topics compared to when queried on factual knowledge itself, as Petroni et al. (2019) have done. For most of the evaluated architectures the correct token is predicted with a $Precision@1$ ($P@1$) of above 60\%, while for $P@5$ and $P@10$ even values of well above 80\% and up to 90\% respectively are reached. These results show the potential of using language models as a knowledge base for structured analysis of customer feedback.