 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Finite-Horizon, Energy-Optimal Trajectories in Unsteady Flows
Mar 18, 2021
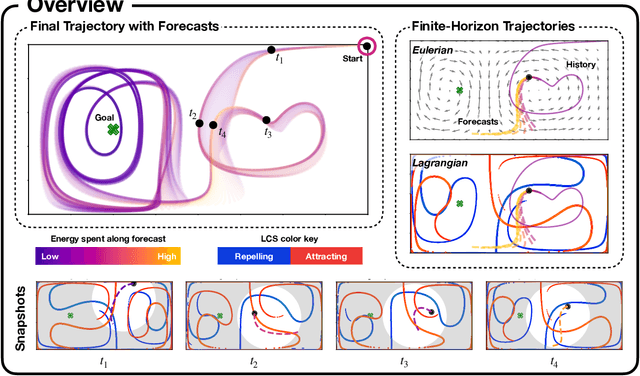
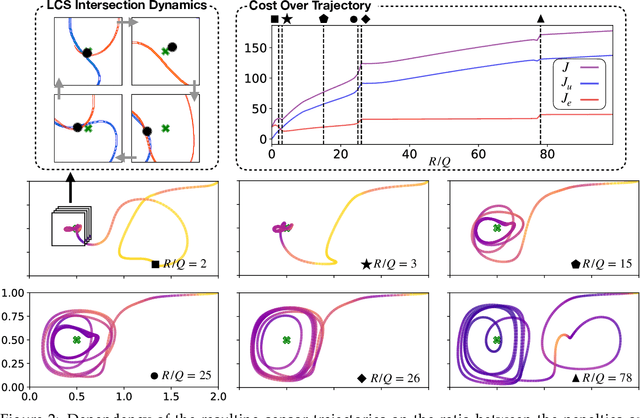
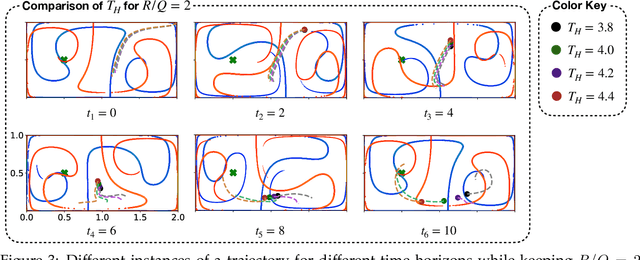
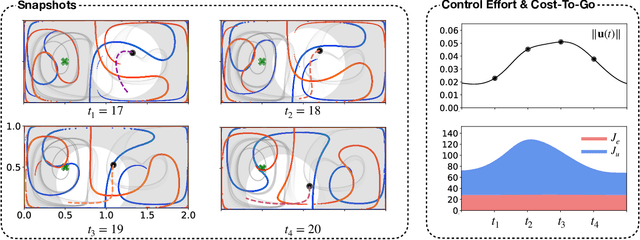
Intelligent mobile sensors, such as uninhabited aerial or underwater vehicles, are becoming prevalent in environmental sensing and monitoring applications. These active sensing platforms operate in unsteady fluid flows, including windy urban environments, hurricanes, and ocean currents. Often constrained in their actuation capabilities, the dynamics of these mobile sensors depend strongly on the background flow, making their deployment and control particularly challenging. Therefore, efficient trajectory planning with partial knowledge about the background flow is essential for teams of mobile sensors to adaptively sense and monitor their environments. In this work, we investigate the use of finite-horizon model predictive control (MPC) for the energy-efficient trajectory planning of an active mobile sensor in an unsteady fluid flow field. We uncover connections between the finite-time optimal trajectories and finite-time Lyapunov exponents (FTLE) of the background flow, confirming that energy-efficient trajectories exploit invariant coherent structures in the flow. We demonstrate our findings on the unsteady double gyre vector field, which is a canonical model for chaotic mixing in the ocean. We present an exhaustive search through critical MPC parameters including the prediction horizon, maximum sensor actuation, and relative penalty on the accumulated state error and actuation effort. We find that even relatively short prediction horizons can often yield nearly energy-optimal trajectories. These results are promising for the adaptive planning of energy-efficient trajectories for swarms of mobile sensors in distributed sensing and monitoring.
Enabling Long-Term Cooperation in Cross-Silo Federated Learning: A Repeated Game Perspective
Jun 22, 2021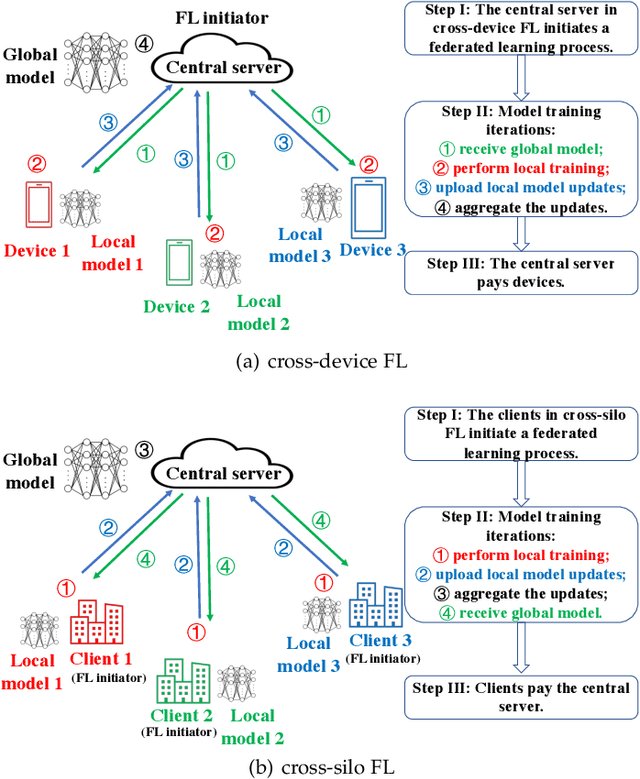
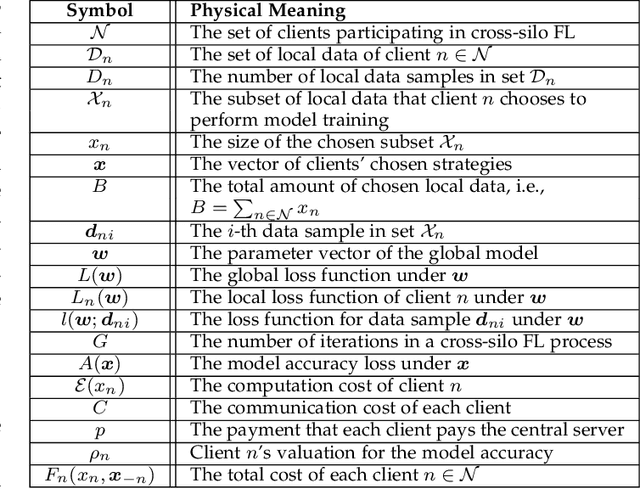
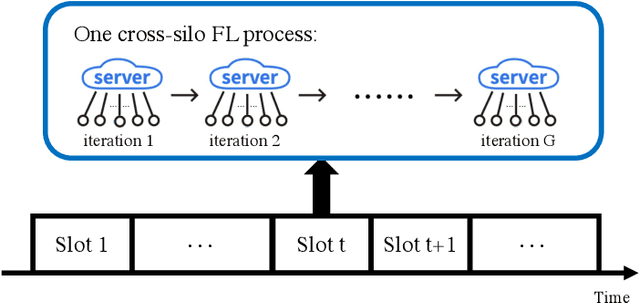
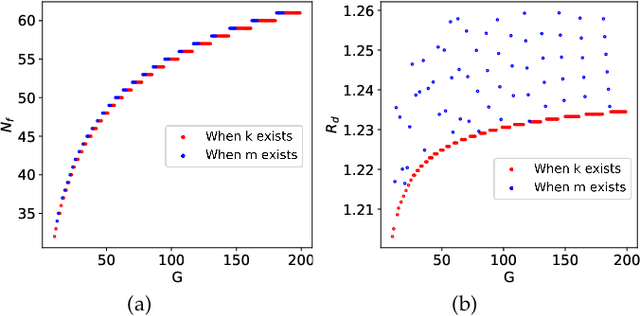
Cross-silo federated learning (FL) is a distributed learning approach where clients train a global model cooperatively while keeping their local data private. Different from cross-device FL, clients in cross-silo FL are usually organizations or companies which may execute multiple cross-silo FL processes repeatedly due to their time-varying local data sets, and aim to optimize their long-term benefits by selfishly choosing their participation levels. While there has been some work on incentivizing clients to join FL, the analysis of the long-term selfish participation behaviors of clients in cross-silo FL remains largely unexplored. In this paper, we analyze the selfish participation behaviors of heterogeneous clients in cross-silo FL. Specifically, we model the long-term selfish participation behaviors of clients as an infinitely repeated game, with the stage game being a selfish participation game in one cross-silo FL process (SPFL). For the stage game SPFL, we derive the unique Nash equilibrium (NE), and propose a distributed algorithm for each client to calculate its equilibrium participation strategy. For the long-term interactions among clients, we derive a cooperative strategy for clients which minimizes the number of free riders while increasing the amount of local data for model training. We show that enforced by a punishment strategy, such a cooperative strategy is a SPNE of the infinitely repeated game, under which some clients who are free riders at the NE of the stage game choose to be (partial) contributors. We further propose an algorithm to calculate the optimal SPNE which minimizes the number of free riders while maximizing the amount of local data for model training. Simulation results show that our proposed cooperative strategy at the optimal SPNE can effectively reduce the number of free riders and increase the amount of local data for model training.
Neural Granger Causality for Nonlinear Time Series
Feb 16, 2018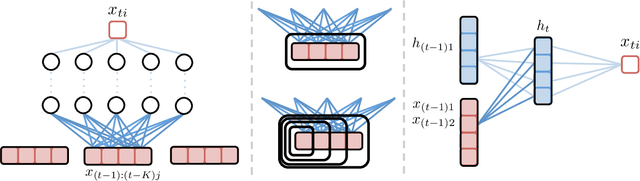
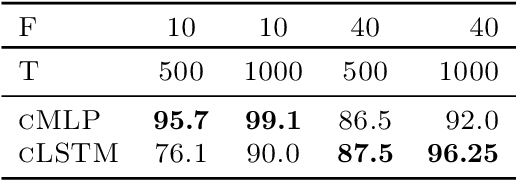
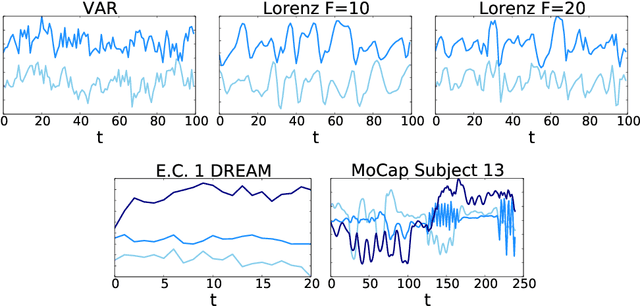

While most classical approaches to Granger causality detection assume linear dynamics, many interactions in applied domains, like neuroscience and genomics, are inherently nonlinear. In these cases, using linear models may lead to inconsistent estimation of Granger causal interactions. We propose a class of nonlinear methods by applying structured multilayer perceptrons (MLPs) or recurrent neural networks (RNNs) combined with sparsity-inducing penalties on the weights. By encouraging specific sets of weights to be zero---in particular through the use of convex group-lasso penalties---we can extract the Granger causal structure. To further contrast with traditional approaches, our framework naturally enables us to efficiently capture long-range dependencies between series either via our RNNs or through an automatic lag selection in the MLP. We show that our neural Granger causality methods outperform state-of-the-art nonlinear Granger causality methods on the DREAM3 challenge data. This data consists of nonlinear gene expression and regulation time courses with only a limited number of time points. The successes we show in this challenging dataset provide a powerful example of how deep learning can be useful in cases that go beyond prediction on large datasets. We likewise demonstrate our methods in detecting nonlinear interactions in a human motion capture dataset.
Environmental Hotspot Identification in Limited Time with a UAV Equipped with a Downward-Facing Camera
Sep 18, 2019
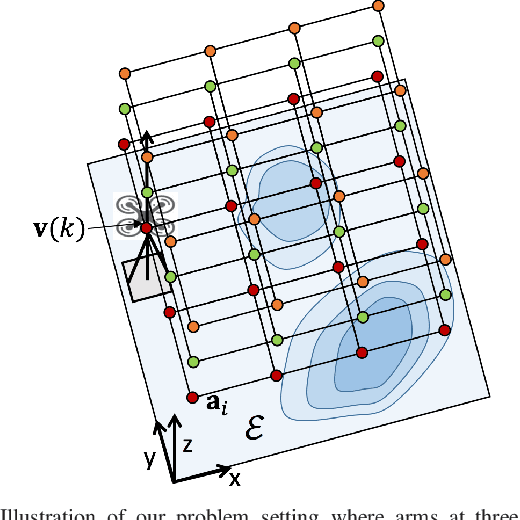
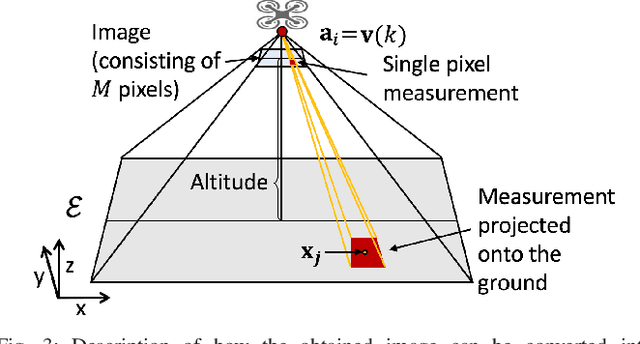
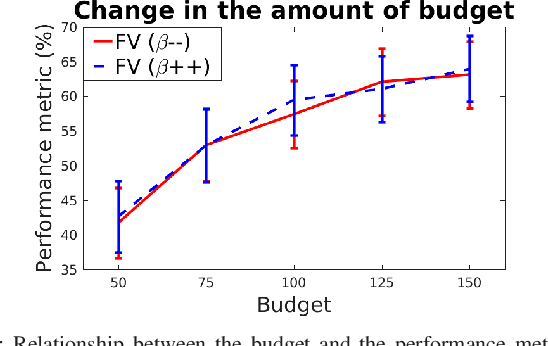
We are motivated by environmental monitoring tasks where finding the global maxima (i.e., hotspot) of a spatially varying field is crucial. We investigate the problem of identifying the hotspot for fields that can be sensed using an Unmanned Aerial Vehicle (UAV) equipped with a downward-facing camera. The UAV has a limited time budget which it must use for learning the unknown field and identifying the hotspot. Our first contribution is to show how this problem can be formulated as a novel variant of the Gaussian Process (GP) multi-armed bandit problem. The novelty is two-fold: (i) unlike standard multi-armed bandit settings, the arms ; and (ii) unlike standard GP regression, the measurements in our problem are image (i.e., vector measurements) whose quality depends on the altitude at which the UAV flies. We present a strategy for finding the sequence of UAV sensing locations and empirically compare it with a number of baselines. We also present experimental results using images gathered onboard a UAV.
Modeling Multi-Label Action Dependencies for Temporal Action Localization
Mar 04, 2021

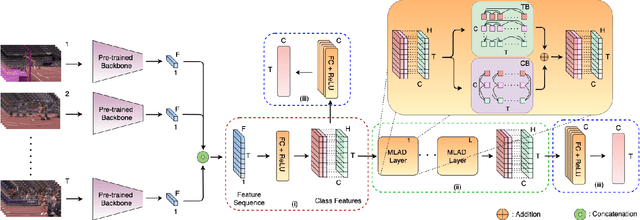
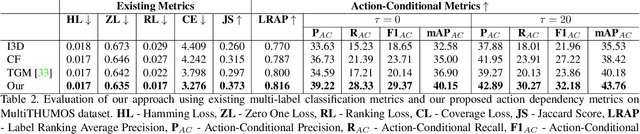
Real-world videos contain many complex actions with inherent relationships between action classes. In this work, we propose an attention-based architecture that models these action relationships for the task of temporal action localization in untrimmed videos. As opposed to previous works that leverage video-level co-occurrence of actions, we distinguish the relationships between actions that occur at the same time-step and actions that occur at different time-steps (i.e. those which precede or follow each other). We define these distinct relationships as action dependencies. We propose to improve action localization performance by modeling these action dependencies in a novel attention-based Multi-Label Action Dependency (MLAD)layer. The MLAD layer consists of two branches: a Co-occurrence Dependency Branch and a Temporal Dependency Branch to model co-occurrence action dependencies and temporal action dependencies, respectively. We observe that existing metrics used for multi-label classification do not explicitly measure how well action dependencies are modeled, therefore, we propose novel metrics that consider both co-occurrence and temporal dependencies between action classes. Through empirical evaluation and extensive analysis, we show improved performance over state-of-the-art methods on multi-label action localization benchmarks(MultiTHUMOS and Charades) in terms of f-mAP and our proposed metric.
A New Channel Estimation Strategy in Intelligent Reflecting Surface Assisted Networks
Jun 22, 2021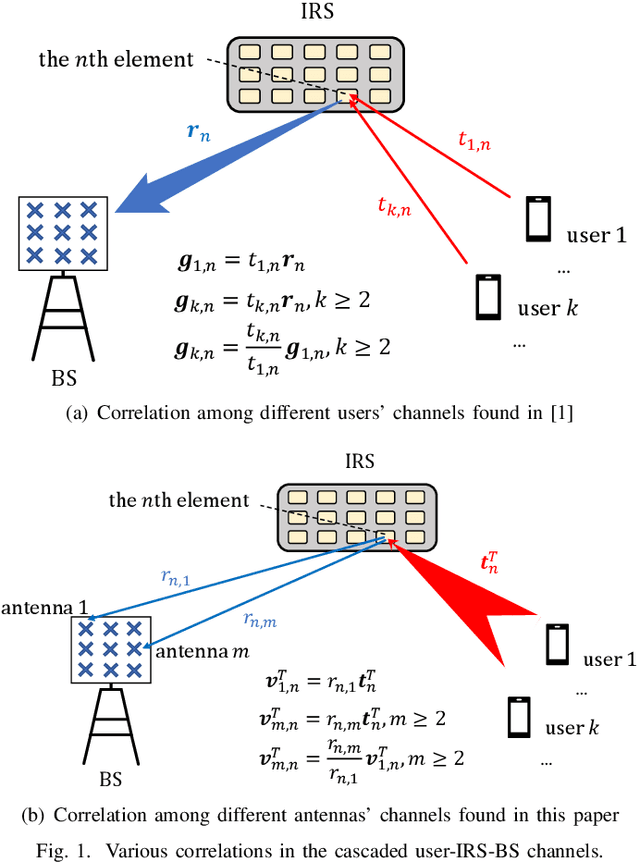
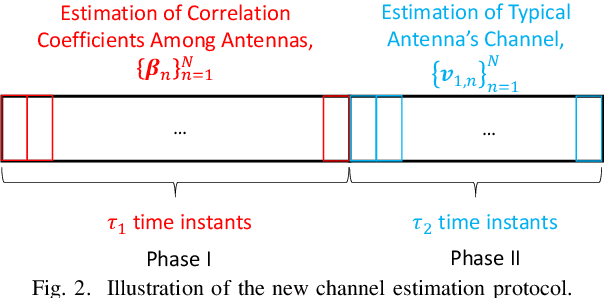
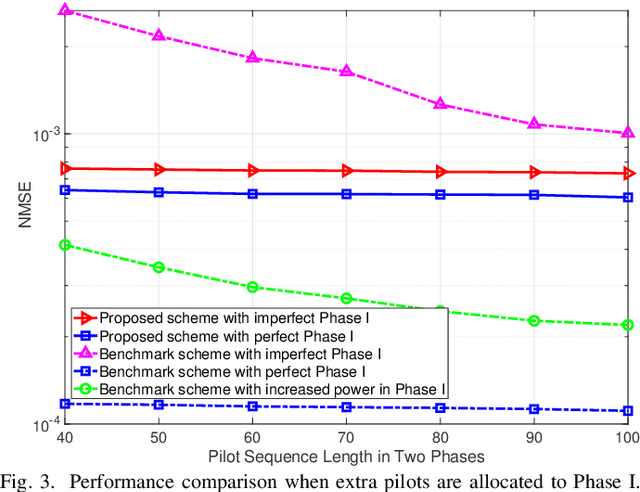
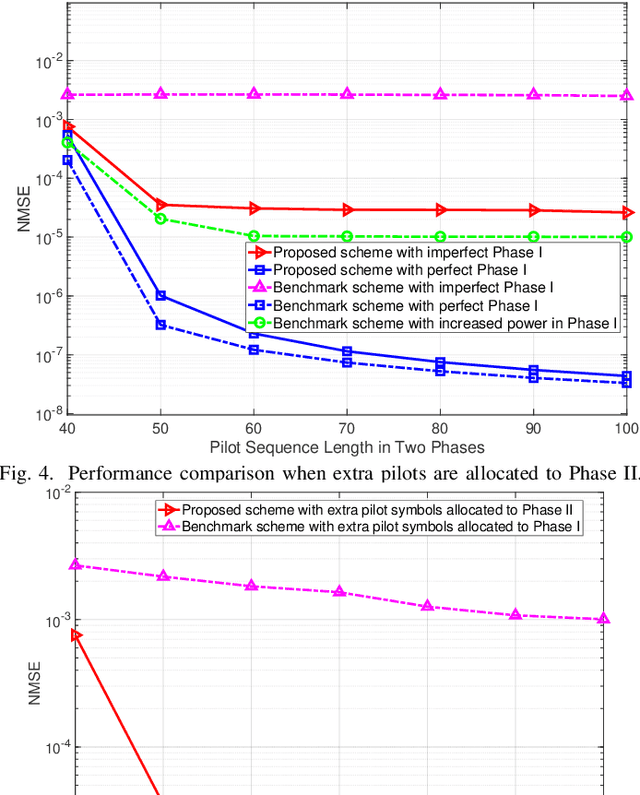
Channel estimation is the main hurdle to reaping the benefits promised by the intelligent reflecting surface (IRS), due to its absence of ability to transmit/receive pilot signals as well as the huge number of channel coefficients associated with its reflecting elements. Recently, a breakthrough was made in reducing the channel estimation overhead by revealing that the IRS-BS (base station) channels are common in the cascaded user-IRS-BS channels of all the users, and if the cascaded channel of one typical user is estimated, the other users' cascaded channels can be estimated very quickly based on their correlation with the typical user's channel \cite{b5}. One limitation of this strategy, however, is the waste of user energy, because many users need to keep silent when the typical user's channel is estimated. In this paper, we reveal another correlation hidden in the cascaded user-IRS-BS channels by observing that the user-IRS channel is common in all the cascaded channels from users to each BS antenna as well. Building upon this finding, we propose a novel two-phase channel estimation protocol in the uplink communication. Specifically, in Phase I, the correlation coefficients between the channels of a typical BS antenna and those of the other antennas are estimated; while in Phase II, the cascaded channel of the typical antenna is estimated. In particular, all the users can transmit throughput Phase I and Phase II. Under this strategy, it is theoretically shown that the minimum number of time instants required for perfect channel estimation is the same as that of the aforementioned strategy in the ideal case without BS noise. Then, in the case with BS noise, we show by simulation that the channel estimation error of our proposed scheme is significantly reduced thanks to the full exploitation of the user energy.
Modelling of LIDAR sensor disturbances by solid airborne particles
May 10, 2021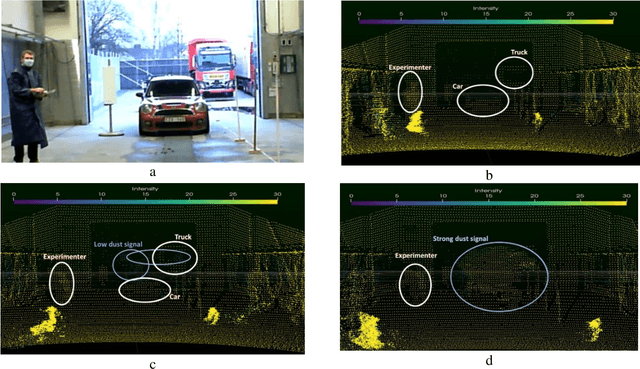
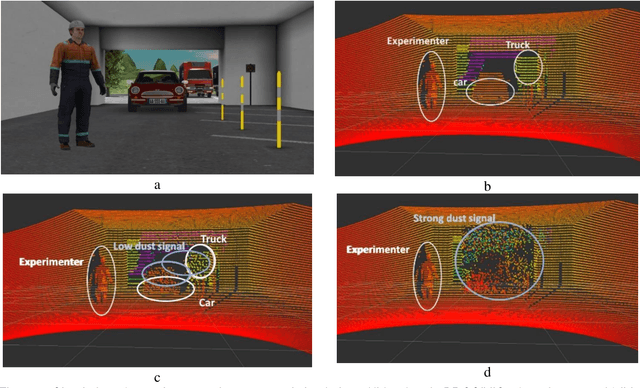
This paper aims to introduce a method for simulating with a real time performance the automotive LIDAR disturbance by dust clouds caused by natural phenomena, mechanical or man-made processes like a traveling vehicle. In this study, we are interested to study the interaction of an automotive LIDAR sensor with a dust cloud composed of solid particles. The main objective of this study is to provide a simulation model to industry and research laboratories that help to study LIDAR performance in a dust-sand environment with the capability to reproduce the encountered problems in degraded conditions and the ability to parameterize the degradation model. Based on industrial projects with a passenger's vehicles and truck manufacturers, we present LIDAR sensor and functionalities to perceive objects in a scene (pedestrian, car, truck, ...) in clear or extreme weather conditions. Simulated and experimental data are compared and analyzed in this article. The features presented are evaluated according to their quality for object detection. This study can be applied to sensors post-processing algorithms (object recognition, tracking, data fusion...) and even to the design of cleaning systems.
Approximately Solving Mean Field Games via Entropy-Regularized Deep Reinforcement Learning
Feb 02, 2021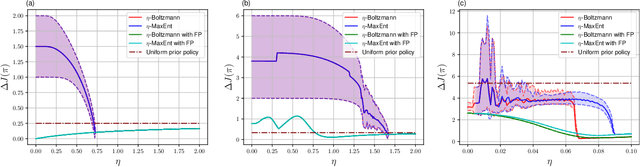

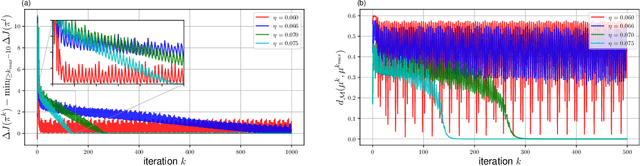
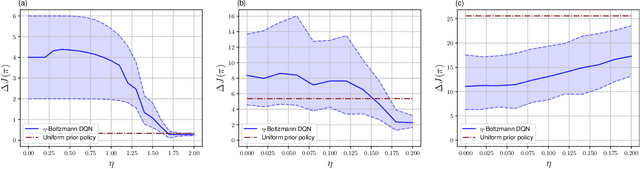
The recent mean field game (MFG) formalism facilitates otherwise intractable computation of approximate Nash equilibria in many-agent settings. In this paper, we consider discrete-time finite MFGs subject to finite-horizon objectives. We show that all discrete-time finite MFGs with non-constant fixed point operators fail to be contractive as typically assumed in existing MFG literature, barring convergence via fixed point iteration. Instead, we incorporate entropy-regularization and Boltzmann policies into the fixed point iteration. As a result, we obtain provable convergence to approximate fixed points where existing methods fail, and reach the original goal of approximate Nash equilibria. All proposed methods are evaluated with respect to their exploitability, on both instructive examples with tractable exact solutions and high-dimensional problems where exact methods become intractable. In high-dimensional scenarios, we apply established deep reinforcement learning methods and empirically combine fictitious play with our approximations.
Probabilistic Gradient Boosting Machines for Large-Scale Probabilistic Regression
Jun 06, 2021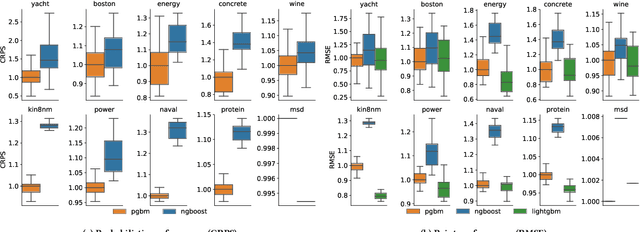
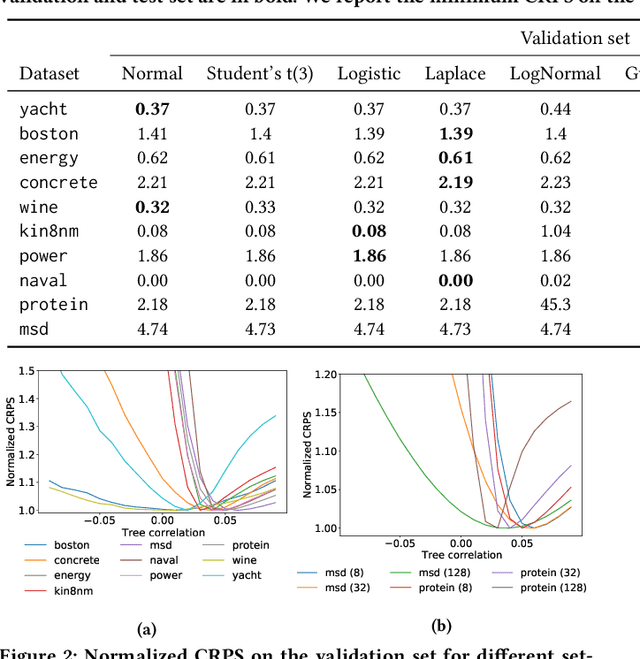
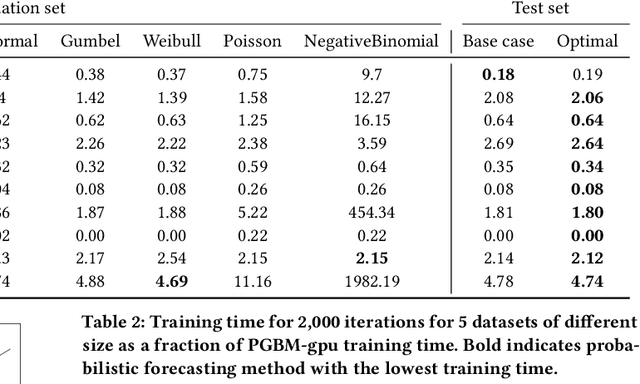
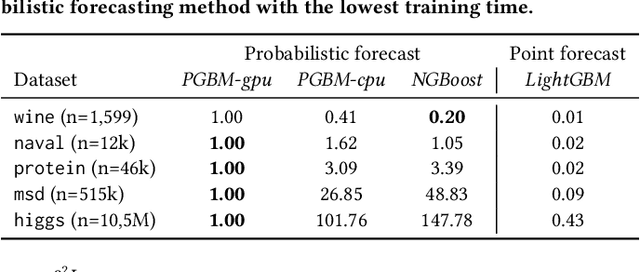
Gradient Boosting Machines (GBM) are hugely popular for solving tabular data problems. However, practitioners are not only interested in point predictions, but also in probabilistic predictions in order to quantify the uncertainty of the predictions. Creating such probabilistic predictions is difficult with existing GBM-based solutions: they either require training multiple models or they become too computationally expensive to be useful for large-scale settings. We propose Probabilistic Gradient Boosting Machines (PGBM), a method to create probabilistic predictions with a single ensemble of decision trees in a computationally efficient manner. PGBM approximates the leaf weights in a decision tree as a random variable, and approximates the mean and variance of each sample in a dataset via stochastic tree ensemble update equations. These learned moments allow us to subsequently sample from a specified distribution after training. We empirically demonstrate the advantages of PGBM compared to existing state-of-the-art methods: (i) PGBM enables probabilistic estimates without compromising on point performance in a single model, (ii) PGBM learns probabilistic estimates via a single model only (and without requiring multi-parameter boosting), and thereby offers a speedup of up to several orders of magnitude over existing state-of-the-art methods on large datasets, and (iii) PGBM achieves accurate probabilistic estimates in tasks with complex differentiable loss functions, such as hierarchical time series problems, where we observed up to 10% improvement in point forecasting performance and up to 300% improvement in probabilistic forecasting performance.
Parameter-free Gradient Temporal Difference Learning
May 10, 2021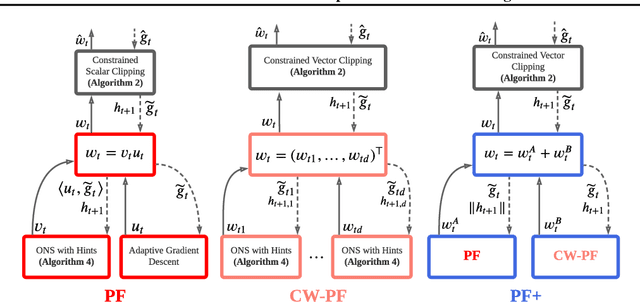
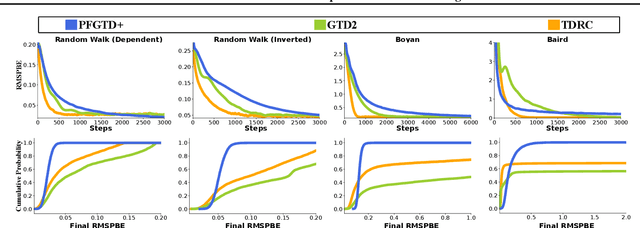
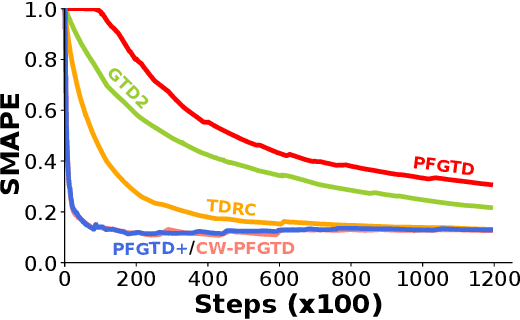
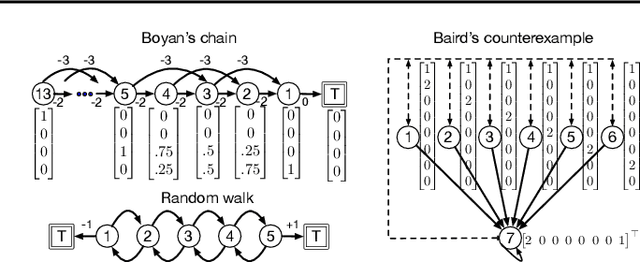
Reinforcement learning lies at the intersection of several challenges. Many applications of interest involve extremely large state spaces, requiring function approximation to enable tractable computation. In addition, the learner has only a single stream of experience with which to evaluate a large number of possible courses of action, necessitating algorithms which can learn off-policy. However, the combination of off-policy learning with function approximation leads to divergence of temporal difference methods. Recent work into gradient-based temporal difference methods has promised a path to stability, but at the cost of expensive hyperparameter tuning. In parallel, progress in online learning has provided parameter-free methods that achieve minimax optimal guarantees up to logarithmic terms, but their application in reinforcement learning has yet to be explored. In this work, we combine these two lines of attack, deriving parameter-free, gradient-based temporal difference algorithms. Our algorithms run in linear time and achieve high-probability convergence guarantees matching those of GTD2 up to $\log$ factors. Our experiments demonstrate that our methods maintain high prediction performance relative to fully-tuned baselines, with no tuning whatsoever.