 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Variation Regret Bounds for Unconstrained Online Learning
Apr 13, 2026We develop parameter-free algorithms for unconstrained online learning with regret guarantees that scale with the gradient variation $V_T(u) = \sum_{t=2}^T \|\nabla f_t(u)-\nabla f_{t-1}(u)\|^2$. For $L$-smooth convex loss, we provide fully-adaptive algorithms achieving regret of order $\widetilde{O}(\|u\|\sqrt{V_T(u)} + L\|u\|^2+G^4)$ without requiring prior knowledge of comparator norm $\|u\|$, Lipschitz constant $G$, or smoothness $L$. The update in each round can be computed efficiently via a closed-form expression. Our results extend to dynamic regret and find immediate implications to the stochastically-extended adversarial (SEA) model, which significantly improves upon the previous best-known result [Wang et al., 2025].
A Perturbation Approach to Unconstrained Linear Bandits
Mar 30, 2026We revisit the standard perturbation-based approach of Abernethy et al. (2008) in the context of unconstrained Bandit Linear Optimization (uBLO). We show the surprising result that in the unconstrained setting, this approach effectively reduces Bandit Linear Optimization (BLO) to a standard Online Linear Optimization (OLO) problem. Our framework improves on prior work in several ways. First, we derive expected-regret guarantees when our perturbation scheme is combined with comparator-adaptive OLO algorithms, leading to new insights about the impact of different adversarial models on the resulting comparator-adaptive rates. We also extend our analysis to dynamic regret, obtaining the optimal $\sqrt{P_T}$ path-length dependencies without prior knowledge of $P_T$. We then develop the first high-probability guarantees for both static and dynamic regret in uBLO. Finally, we discuss lower bounds on the static regret, and prove the folklore $Ω(\sqrt{dT})$ rate for adversarial linear bandits on the unit Euclidean ball, which is of independent interest.
Parameter-Free Dynamic Regret for Unconstrained Linear Bandits
Mar 26, 2026We study dynamic regret minimization in unconstrained adversarial linear bandit problems. In this setting, a learner must minimize the cumulative loss relative to an arbitrary sequence of comparators $\boldsymbol{u}_1,\ldots,\boldsymbol{u}_T$ in $\mathbb{R}^d$, but receives only point-evaluation feedback on each round. We provide a simple approach to combining the guarantees of several bandit algorithms, allowing us to optimally adapt to the number of switches $S_T = \sum_t\mathbb{I}\{\boldsymbol{u}_t \neq \boldsymbol{u}_{t-1}\}$ of an arbitrary comparator sequence. In particular, we provide the first algorithm for linear bandits achieving the optimal regret guarantee of order $\mathcal{O}\big(\sqrt{d(1+S_T) T}\big)$ up to poly-logarithmic terms without prior knowledge of $S_T$, thus resolving a long-standing open problem.
Parameter-free Dynamic Regret: Time-varying Movement Costs, Delayed Feedback, and Memory
Feb 06, 2026In this paper, we study dynamic regret in unconstrained online convex optimization (OCO) with movement costs. Specifically, we generalize the standard setting by allowing the movement cost coefficients $λ_t$ to vary arbitrarily over time. Our main contribution is a novel algorithm that establishes the first comparator-adaptive dynamic regret bound for this setting, guaranteeing $\widetilde{\mathcal{O}}(\sqrt{(1+P_T)(T+\sum_t λ_t)})$ regret, where $P_T$ is the path length of the comparator sequence over $T$ rounds. This recovers the optimal guarantees for both static and dynamic regret in standard OCO as a special case where $λ_t=0$ for all rounds. To demonstrate the versatility of our results, we consider two applications: OCO with delayed feedback and OCO with time-varying memory. We show that both problems can be translated into time-varying movement costs, establishing a novel reduction specifically for the delayed feedback setting that is of independent interest. A crucial observation is that the first-order dependence on movement costs in our regret bound plays a key role in enabling optimal comparator-adaptive dynamic regret guarantees in both settings.
An Equivalence Between Static and Dynamic Regret Minimization
Jun 03, 2024We study the problem of dynamic regret minimization in online convex optimization, in which the objective is to minimize the difference between the cumulative loss of an algorithm and that of an arbitrary sequence of comparators. While the literature on this topic is very rich, a unifying framework for the analysis and design of these algorithms is still missing. In this paper, \emph{we show that dynamic regret minimization is equivalent to static regret minimization in an extended decision space}. Using this simple observation, we show that there is a frontier of lower bounds trading off penalties due to the variance of the losses and penalties due to variability of the comparator sequence, and provide a framework for achieving any of the guarantees along this frontier. As a result, we prove for the first time that adapting to the squared path-length of an arbitrary sequence of comparators to achieve regret $R_{T}(u_{1},\dots,u_{T})\le O(\sqrt{T\sum_{t} \|u_{t}-u_{t+1}\|^{2}})$ is impossible. However, we prove that it is possible to adapt to a new notion of variability based on the locally-smoothed squared path-length of the comparator sequence, and provide an algorithm guaranteeing dynamic regret of the form $R_{T}(u_{1},\dots,u_{T})\le \tilde O(\sqrt{T\sum_{i}\|\bar u_{i}-\bar u_{i+1}\|^{2}})$. Up to polylogarithmic terms, the new notion of variability is never worse than the classic one involving the path-length.
Online Linear Regression in Dynamic Environments via Discounting
May 29, 2024We develop algorithms for online linear regression which achieve optimal static and dynamic regret guarantees \emph{even in the complete absence of prior knowledge}. We present a novel analysis showing that a discounted variant of the Vovk-Azoury-Warmuth forecaster achieves dynamic regret of the form $R_{T}(\vec{u})\le O\left(d\log(T)\vee \sqrt{dP_{T}^{\gamma}(\vec{u})T}\right)$, where $P_{T}^{\gamma}(\vec{u})$ is a measure of variability of the comparator sequence, and show that the discount factor achieving this result can be learned on-the-fly. We show that this result is optimal by providing a matching lower bound. We also extend our results to \emph{strongly-adaptive} guarantees which hold over every sub-interval $[a,b]\subseteq[1,T]$ simultaneously.
Unconstrained Online Learning with Unbounded Losses
Jun 08, 2023Algorithms for online learning typically require one or more boundedness assumptions: that the domain is bounded, that the losses are Lipschitz, or both. In this paper, we develop a new setting for online learning with unbounded domains and non-Lipschitz losses. For this setting we provide an algorithm which guarantees $R_{T}(u)\le \tilde O(G\|u\|\sqrt{T}+L\|u\|^{2}\sqrt{T})$ regret on any problem where the subgradients satisfy $\|g_{t}\|\le G+L\|w_{t}\|$, and show that this bound is unimprovable without further assumptions. We leverage this algorithm to develop new saddle-point optimization algorithms that converge in duality gap in unbounded domains, even in the absence of meaningful curvature. Finally, we provide the first algorithm achieving non-trivial dynamic regret in an unbounded domain for non-Lipschitz losses, as well as a matching lower bound. The regret of our dynamic regret algorithm automatically improves to a novel $L^{*}$ bound when the losses are smooth.
Parameter-free Mirror Descent
Apr 02, 2022We develop a modified online mirror descent framework that is suitable for building adaptive and parameter-free algorithms in unbounded domains. We leverage this technique to develop the first unconstrained online linear optimization algorithm achieving an optimal dynamic regret bound, and we further demonstrate that natural strategies based on Follow-the-Regularized-Leader are unable to achieve similar results. We also apply our mirror descent framework to build new parameter-free implicit updates, as well as a simplified and improved unconstrained scale-free algorithm.
Continual Auxiliary Task Learning
Feb 22, 2022
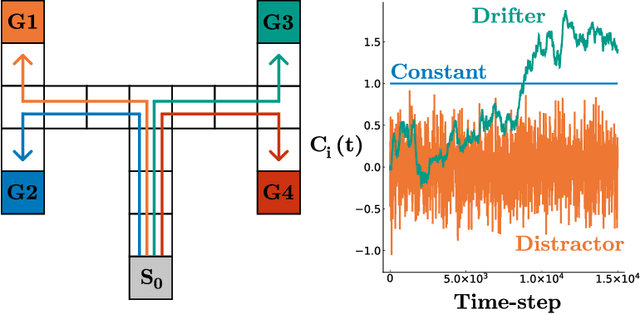
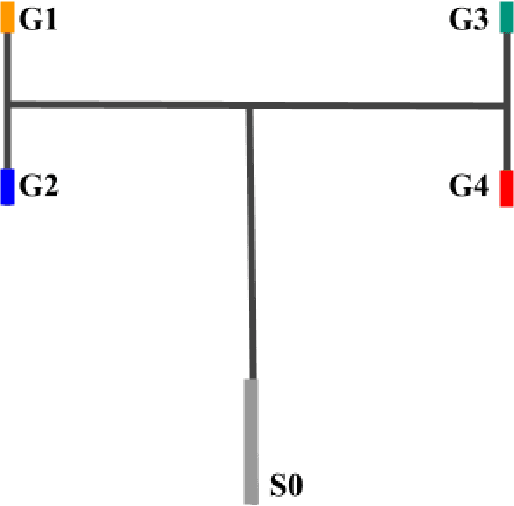
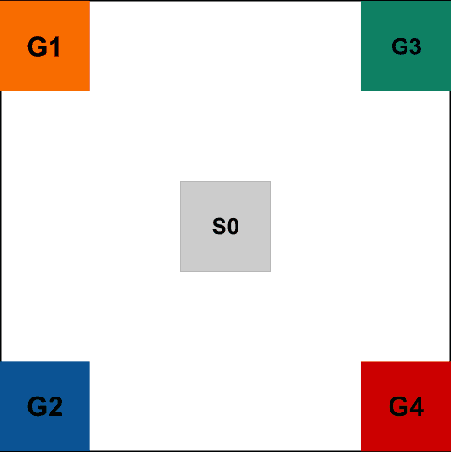
Learning auxiliary tasks, such as multiple predictions about the world, can provide many benefits to reinforcement learning systems. A variety of off-policy learning algorithms have been developed to learn such predictions, but as yet there is little work on how to adapt the behavior to gather useful data for those off-policy predictions. In this work, we investigate a reinforcement learning system designed to learn a collection of auxiliary tasks, with a behavior policy learning to take actions to improve those auxiliary predictions. We highlight the inherent non-stationarity in this continual auxiliary task learning problem, for both prediction learners and the behavior learner. We develop an algorithm based on successor features that facilitates tracking under non-stationary rewards, and prove the separation into learning successor features and rewards provides convergence rate improvements. We conduct an in-depth study into the resulting multi-prediction learning system.
Parameter-free Gradient Temporal Difference Learning
May 10, 2021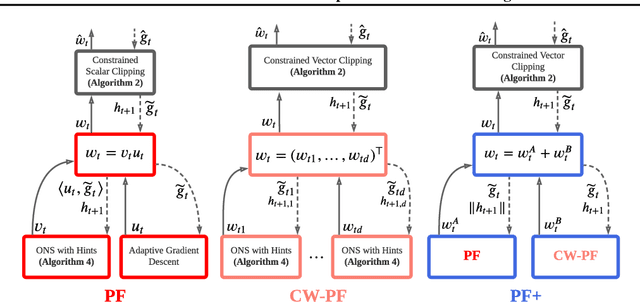
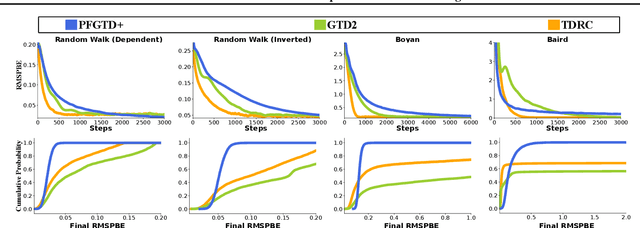
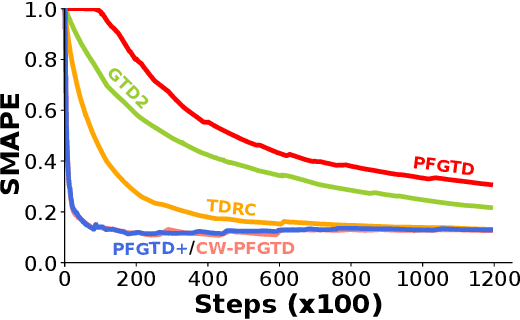
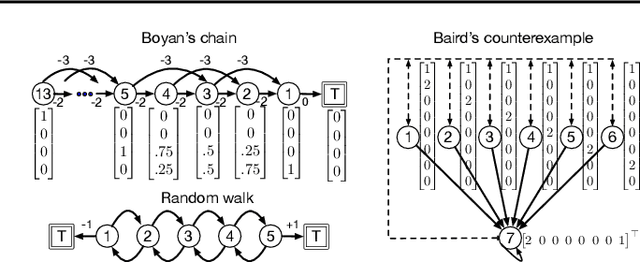
Reinforcement learning lies at the intersection of several challenges. Many applications of interest involve extremely large state spaces, requiring function approximation to enable tractable computation. In addition, the learner has only a single stream of experience with which to evaluate a large number of possible courses of action, necessitating algorithms which can learn off-policy. However, the combination of off-policy learning with function approximation leads to divergence of temporal difference methods. Recent work into gradient-based temporal difference methods has promised a path to stability, but at the cost of expensive hyperparameter tuning. In parallel, progress in online learning has provided parameter-free methods that achieve minimax optimal guarantees up to logarithmic terms, but their application in reinforcement learning has yet to be explored. In this work, we combine these two lines of attack, deriving parameter-free, gradient-based temporal difference algorithms. Our algorithms run in linear time and achieve high-probability convergence guarantees matching those of GTD2 up to $\log$ factors. Our experiments demonstrate that our methods maintain high prediction performance relative to fully-tuned baselines, with no tuning whatsoever.