 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-free Gradient Temporal Difference Learning
Paper and Code
May 10, 2021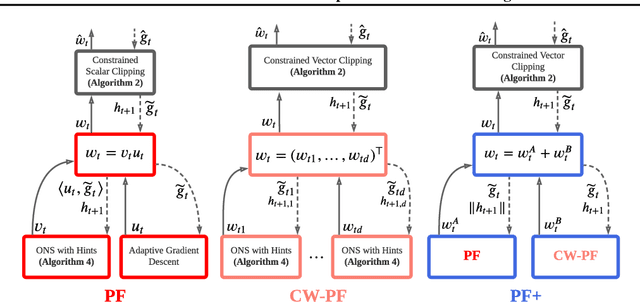
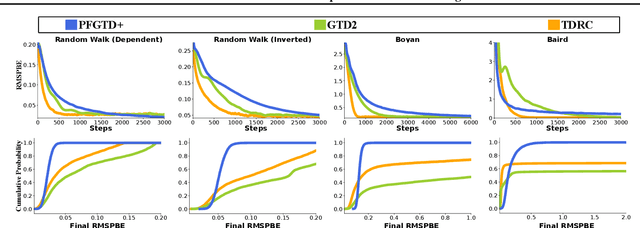
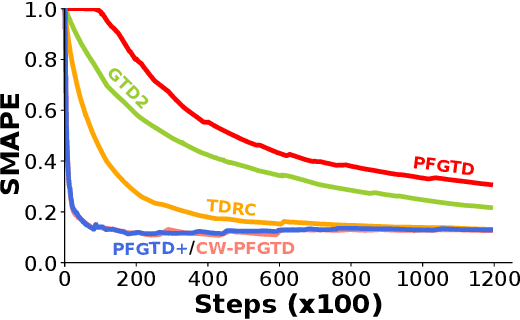
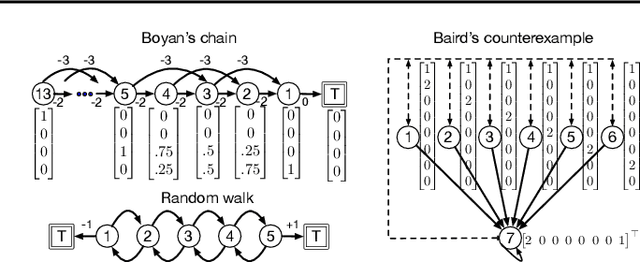
Reinforcement learning lies at the intersection of several challenges. Many applications of interest involve extremely large state spaces, requiring function approximation to enable tractable computation. In addition, the learner has only a single stream of experience with which to evaluate a large number of possible courses of action, necessitating algorithms which can learn off-policy. However, the combination of off-policy learning with function approximation leads to divergence of temporal difference methods. Recent work into gradient-based temporal difference methods has promised a path to stability, but at the cost of expensive hyperparameter tuning. In parallel, progress in online learning has provided parameter-free methods that achieve minimax optimal guarantees up to logarithmic terms, but their application in reinforcement learning has yet to be explored. In this work, we combine these two lines of attack, deriving parameter-free, gradient-based temporal difference algorithms. Our algorithms run in linear time and achieve high-probability convergence guarantees matching those of GTD2 up to $\log$ factors. Our experiments demonstrate that our methods maintain high prediction performance relative to fully-tuned baselines, with no tuning whatsoever.