 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Surveillance of COVID-19 Pandemic using Social Media: A Reddit Study in North Carolina
Jun 09, 2021
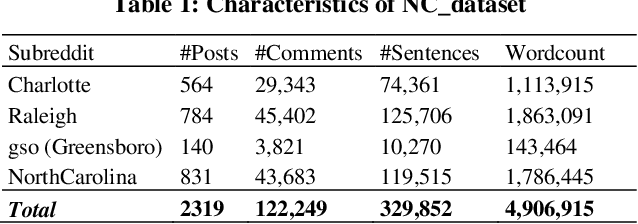
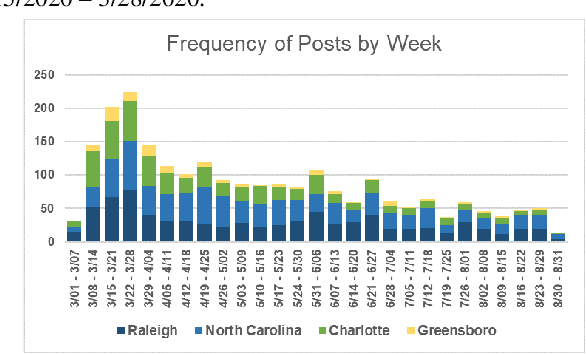
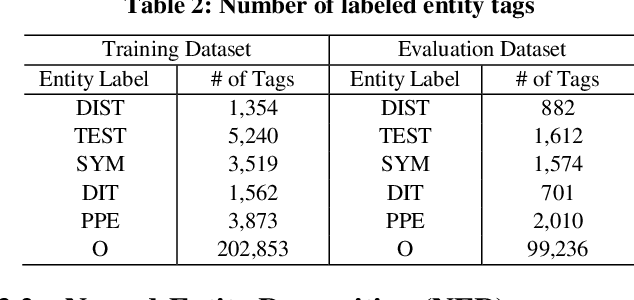
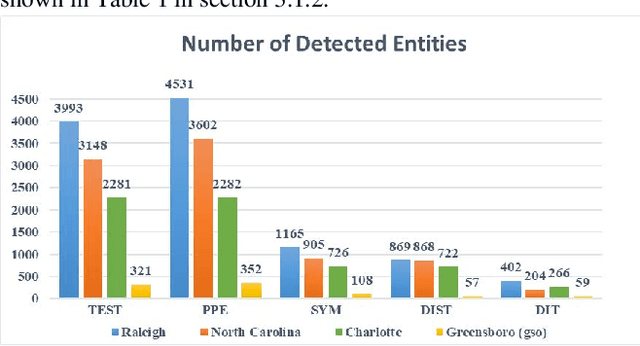
Coronavirus disease (COVID-19) pandemic has changed various aspects of people's lives and behaviors. At this stage, there are no other ways to control the natural progression of the disease than adopting mitigation strategies such as wearing masks, watching distance, and washing hands. Moreover, at this time of social distancing, social media plays a key role in connecting people and providing a platform for expressing their feelings. In this study, we tap into social media to surveil the uptake of mitigation and detection strategies, and capture issues and concerns about the pandemic. In particular, we explore the research question, "how much can be learned regarding the public uptake of mitigation strategies and concerns about COVID-19 pandemic by using natural language processing on Reddit posts?" After extracting COVID-related posts from the four largest subreddit communities of North Carolina over six months, we performed NLP-based preprocessing to clean the noisy data. We employed a custom Named-entity Recognition (NER) system and a Latent Dirichlet Allocation (LDA) method for topic modeling on a Reddit corpus. We observed that 'mask', 'flu', and 'testing' are the most prevalent named-entities for "Personal Protective Equipment", "symptoms", and "testing" categories, respectively. We also observed that the most discussed topics are related to testing, masks, and employment. The mitigation measures are the most prevalent theme of discussion across all subreddits.
MILP, pseudo-boolean, and OMT solvers for optimal fault-tolerant placements of relay nodes in mission critical wireless networks
Jun 20, 2021
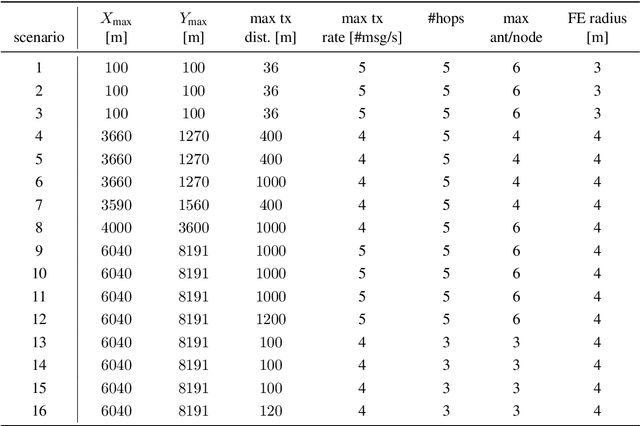
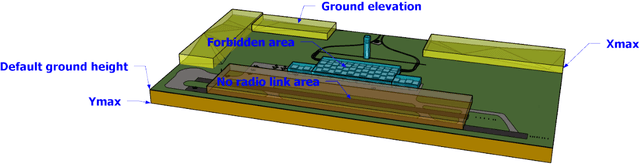
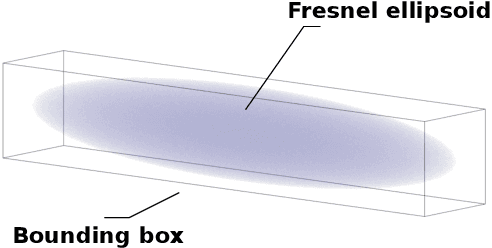
In critical infrastructures like airports, much care has to be devoted in protecting radio communication networks from external electromagnetic interference. Protection of such mission-critical radio communication networks is usually tackled by exploiting radiogoniometers: at least three suitably deployed radiogoniometers, and a gateway gathering information from them, permit to monitor and localise sources of electromagnetic emissions that are not supposed to be present in the monitored area. Typically, radiogoniometers are connected to the gateway through relay nodes. As a result, some degree of fault-tolerance for the network of relay nodes is essential in order to offer a reliable monitoring. On the other hand, deployment of relay nodes is typically quite expensive. As a result, we have two conflicting requirements: minimise costs while guaranteeing a given fault-tolerance. In this paper, we address the problem of computing a deployment for relay nodes that minimises the relay node network cost while at the same time guaranteeing proper working of the network even when some of the relay nodes (up to a given maximum number) become faulty (fault-tolerance). We show that, by means of a computation-intensive pre-processing on a HPC infrastructure, the above optimisation problem can be encoded as a 0/1 Linear Program, becoming suitable to be approached with standard Artificial Intelligence reasoners like MILP, PB-SAT, and SMT/OMT solvers. Our problem formulation enables us to present experimental results comparing the performance of these three solving technologies on a real case study of a relay node network deployment in areas of the Leonardo da Vinci Airport in Rome, Italy.
* 33 pages, 11 figures
Multi-agent Path Finding with Continuous Time Viewed Through Satisfiability Modulo Theories (SMT)
Mar 23, 2019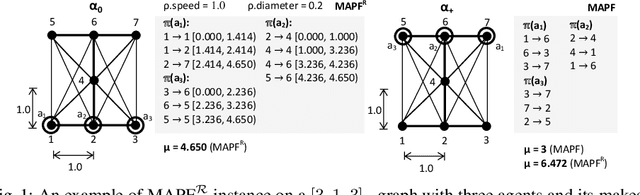
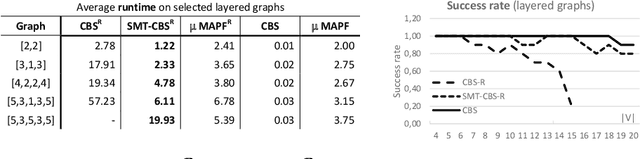
This paper addresses a variant of multi-agent path finding (MAPF) in continuous space and time. We present a new solving approach based on satisfiability modulo theories (SMT) to obtain makespan optimal solutions. The standard MAPF is a task of navigating agents in an undirected graph from given starting vertices to given goal vertices so that agents do not collide with each other in vertices of the graph. In the continuous version (MAPF$^\mathcal{R}$) agents move in an $n$-dimensional Euclidean space along straight lines that interconnect predefined positions. For simplicity, we work with circular omni-directional agents having constant velocities in the 2D plane. As agents can have different sizes and move smoothly along lines, a non-colliding movement along certain lines with small agents can result in a collision if the same movement is performed with larger agents. Our SMT-based approach for MAPF$^\mathcal{R}$ called SMT-CBS$^\mathcal{R}$ reformulates the Conflict-based Search (CBS) algorithm in terms of SMT concepts. We suggest lazy generation of decision variables and constraints. Each time a new conflict is discovered, the underlying encoding is extended with new variables and constraints to eliminate the conflict. We compared SMT-CBS$^\mathcal{R}$ and adaptations of CBS for the continuous variant of MAPF experimentally.
Fully General Online Imitation Learning
Feb 17, 2021

In imitation learning, imitators and demonstrators are policies for picking actions given past interactions with the environment. If we run an imitator, we probably want events to unfold similarly to the way they would have if the demonstrator had been acting the whole time. No existing work provides formal guidance in how this might be accomplished, instead restricting focus to environments that restart, making learning unusually easy, and conveniently limiting the significance of any mistake. We address a fully general setting, in which the (stochastic) environment and demonstrator never reset, not even for training purposes. Our new conservative Bayesian imitation learner underestimates the probabilities of each available action, and queries for more data with the remaining probability. Our main result: if an event would have been unlikely had the demonstrator acted the whole time, that event's likelihood can be bounded above when running the (initially totally ignorant) imitator instead. Meanwhile, queries to the demonstrator rapidly diminish in frequency.
Detection, Tracking, and Counting Meets Drones in Crowds: A Benchmark
May 06, 2021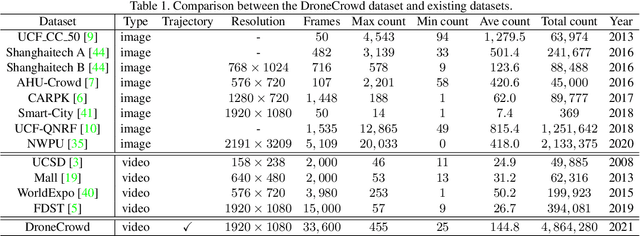

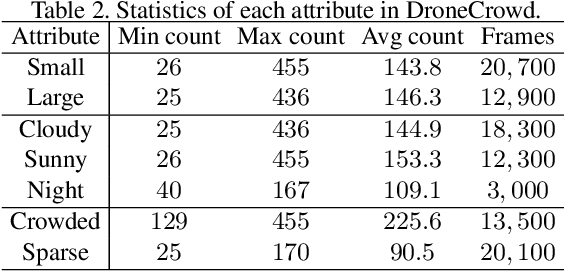
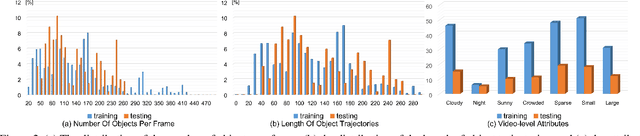
To promote the developments of object detection, tracking and counting algorithms in drone-captured videos, we construct a benchmark with a new drone-captured largescale dataset, named as DroneCrowd, formed by 112 video clips with 33,600 HD frames in various scenarios. Notably, we annotate 20,800 people trajectories with 4.8 million heads and several video-level attributes. Meanwhile, we design the Space-Time Neighbor-Aware Network (STNNet) as a strong baseline to solve object detection, tracking and counting jointly in dense crowds. STNNet is formed by the feature extraction module, followed by the density map estimation heads, and localization and association subnets. To exploit the context information of neighboring objects, we design the neighboring context loss to guide the association subnet training, which enforces consistent relative position of nearby objects in temporal domain. Extensive experiments on our DroneCrowd dataset demonstrate that STNNet performs favorably against the state-of-the-arts.
RETRIEVE: Coreset Selection for Efficient and Robust Semi-Supervised Learning
Jun 14, 2021
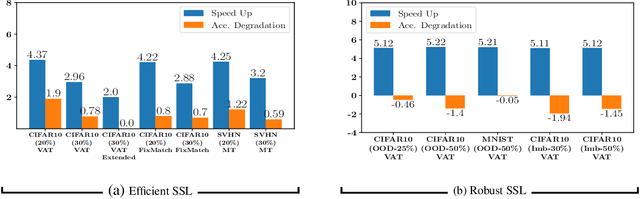


Semi-supervised learning (SSL) algorithms have had great success in recent years in limited labeled data regimes. However, the current state-of-the-art SSL algorithms are computationally expensive and entail significant compute time and energy requirements. This can prove to be a huge limitation for many smaller companies and academic groups. Our main insight is that training on a subset of unlabeled data instead of entire unlabeled data enables the current SSL algorithms to converge faster, thereby reducing the computational costs significantly. In this work, we propose RETRIEVE, a coreset selection framework for efficient and robust semi-supervised learning. RETRIEVE selects the coreset by solving a mixed discrete-continuous bi-level optimization problem such that the selected coreset minimizes the labeled set loss. We use a one-step gradient approximation and show that the discrete optimization problem is approximately submodular, thereby enabling simple greedy algorithms to obtain the coreset. We empirically demonstrate on several real-world datasets that existing SSL algorithms like VAT, Mean-Teacher, FixMatch, when used with RETRIEVE, achieve a) faster training times, b) better performance when unlabeled data consists of Out-of-Distribution(OOD) data and imbalance. More specifically, we show that with minimal accuracy degradation, RETRIEVE achieves a speedup of around 3X in the traditional SSL setting and achieves a speedup of 5X compared to state-of-the-art (SOTA) robust SSL algorithms in the case of imbalance and OOD data.
A Contraction Theory Approach to Optimization Algorithms from Acceleration Flows
May 18, 2021Much recent interest has focused on the design of optimization algorithms from the discretization of an associated optimization flow, i.e., a system of differential equations (ODEs) whose trajectories solve an associated optimization problem. Such a design approach poses an important problem: how to find a principled methodology to design and discretize appropriate ODEs. This paper aims to provide a solution to this problem through the use of contraction theory. We first introduce general mathematical results that explain how contraction theory guarantees the stability of the implicit and explicit Euler integration methods. Then, we propose a novel system of ODEs, namely the Accelerated-Contracting-Nesterov flow, and use contraction theory to establish it is an optimization flow with exponential convergence rate, from which the linear convergence rate of its associated optimization algorithm is immediately established. Remarkably, a simple explicit Euler discretization of this flow corresponds to the Nesterov acceleration method. Finally, we present how our approach leads to performance guarantees in the design of optimization algorithms for time-varying optimization problems.
Robust Kalman filter-based dynamic state estimation of natural gas pipeline networks
Feb 26, 2021
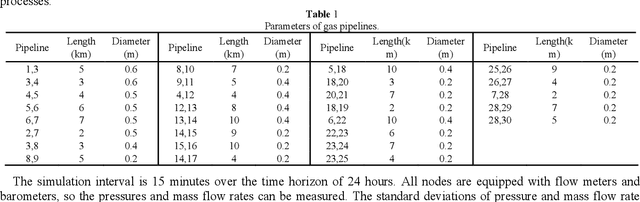
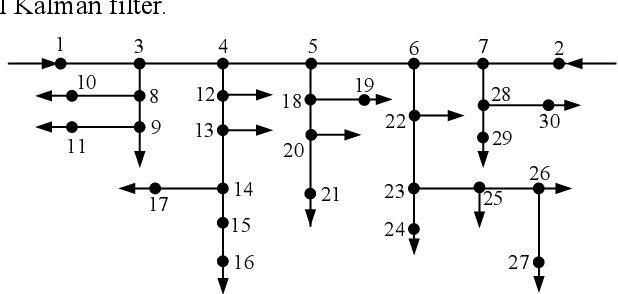
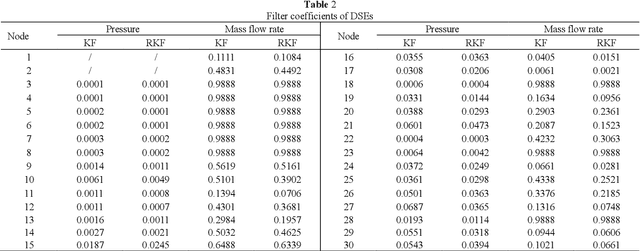
To obtain the accurate transient states of the big scale natural gas pipeline networks under the bad data and non-zero mean noises conditions, a robust Kalman filter-based dynamic state estimation method is proposed using the linearized gas pipeline transient flow equations in this paper. Firstly, the dynamic state estimation model is built. Since the gas pipeline transient flow equations are less than the states, the boundary conditions are used as supplementary constraints to predict the transient states. To increase the measurement redundancy, the zero mass flow rate constraints at the sink nodes are taken as virtual measurements. Secondly, to ensure the stability under bad data condition, the robust Kalman filter algorithm is proposed by introducing a time-varying scalar matrix to regulate the measurement error variances correctly according to the innovation vector at every time step. At last, the proposed method is applied to a 30-node gas pipeline networks in several kinds of measurement conditions. The simulation shows that the proposed robust dynamic state estimation can decrease the effects of bad data and achieve better estimating results.
Dynamic Instance-Wise Classification in Correlated Feature Spaces
Jun 08, 2021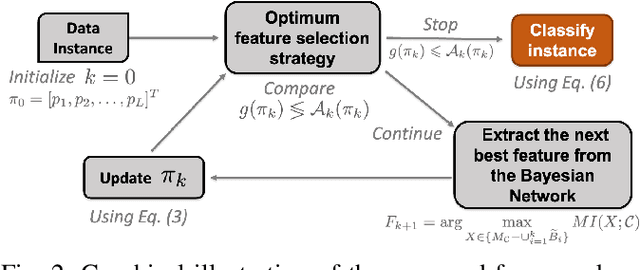
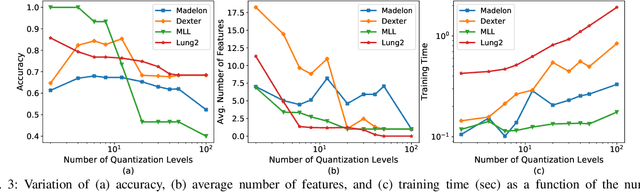
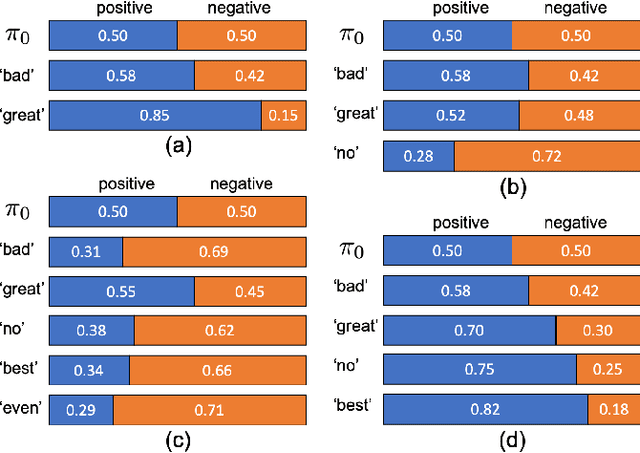
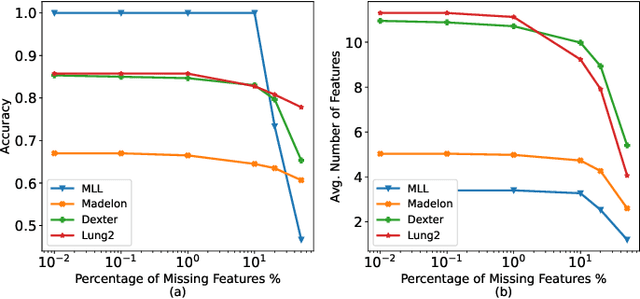
In a typical supervised machine learning setting, the predictions on all test instances are based on a common subset of features discovered during model training. However, using a different subset of features that is most informative for each test instance individually may not only improve prediction accuracy, but also the overall interpretability of the model. At the same time, feature selection methods for classification have been known to be the most effective when many features are irrelevant and/or uncorrelated. In fact, feature selection ignoring correlations between features can lead to poor classification performance. In this work, a Bayesian network is utilized to model feature dependencies. Using the dependency network, a new method is proposed that sequentially selects the best feature to evaluate for each test instance individually, and stops the selection process to make a prediction once it determines that no further improvement can be achieved with respect to classification accuracy. The optimum number of features to acquire and the optimum classification strategy are derived for each test instance. The theoretical properties of the optimum solution are analyzed, and a new algorithm is proposed that takes advantage of these properties to implement a robust and scalable solution for high dimensional settings. The effectiveness, generalizability, and scalability of the proposed method is illustrated on a variety of real-world datasets from diverse application domains.
Automatic 2D-3D Registration without Contrast Agent during Neurovascular Interventions
Jun 08, 2021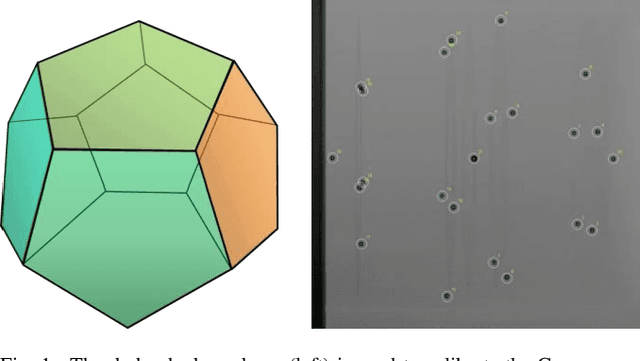
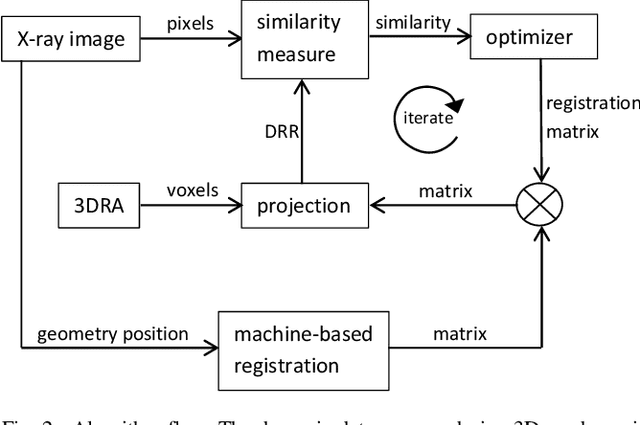
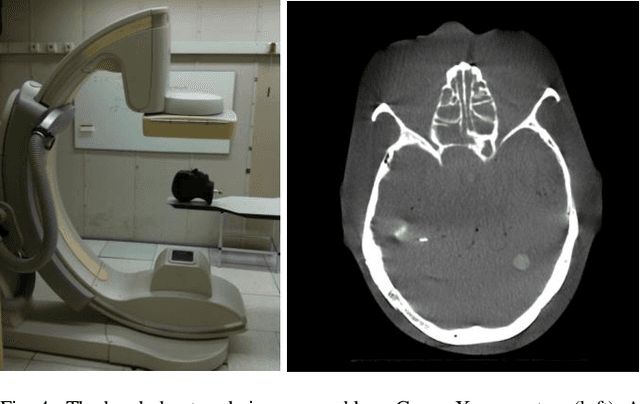
Fusing live fluoroscopy images with a 3D rotational reconstruction of the vasculature allows to navigate endovascular devices in minimally invasive neuro-vascular treatment, while reducing the usage of harmful iodine contrast medium. The alignment of the fluoroscopy images and the 3D reconstruction is initialized using the sensor information of the X-ray C-arm geometry. Patient motion is then corrected by an image-based registration algorithm, based on a gradient difference similarity measure using digital reconstructed radiographs of the 3D reconstruction. This algorithm does not require the vessels in the fluoroscopy image to be filled with iodine contrast agent, but rather relies on gradients in the image (bone structures, sinuses) as landmark features. This paper investigates the accuracy, robustness and computation time aspects of the image-based registration algorithm. Using phantom experiments 97% of the registration attempts passed the success criterion of a residual registration error of less than 1 mm translation and 3{\deg} rotation. The paper establishes a new method for validation of 2D-3D registration without requiring changes to the clinical workflow, such as attaching fiducial markers. As a consequence, this method can be retrospectively applied to pre-existing clinical data. For clinical data experiments, 87% of the registration attempts passed the criterion of a residual translational error of < 1 mm, and 84% possessed a rotational error of < 3{\deg}.