 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Parallel Tacotron 2: A Non-Autoregressive Neural TTS Model with Differentiable Duration Modeling
Apr 06, 2021
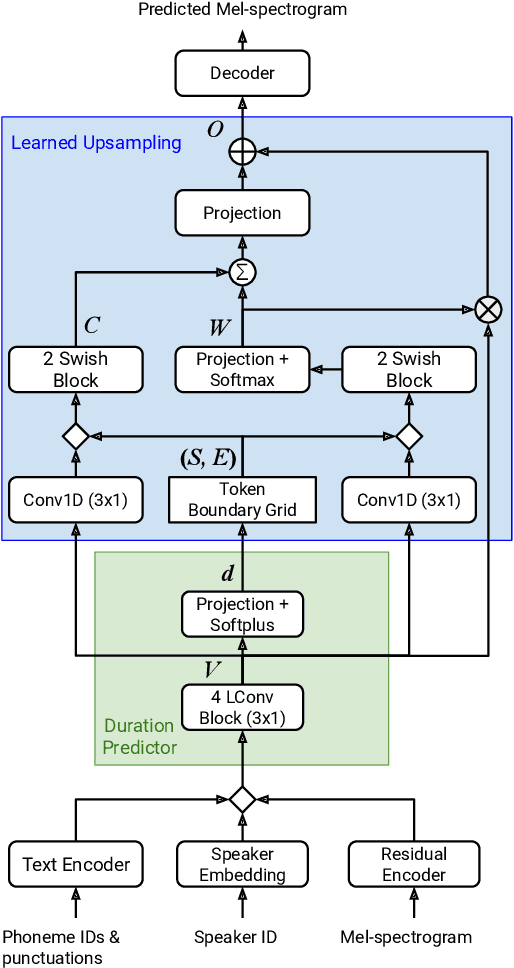
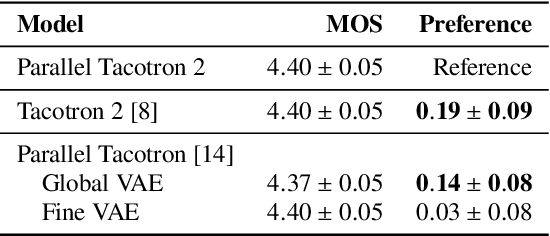
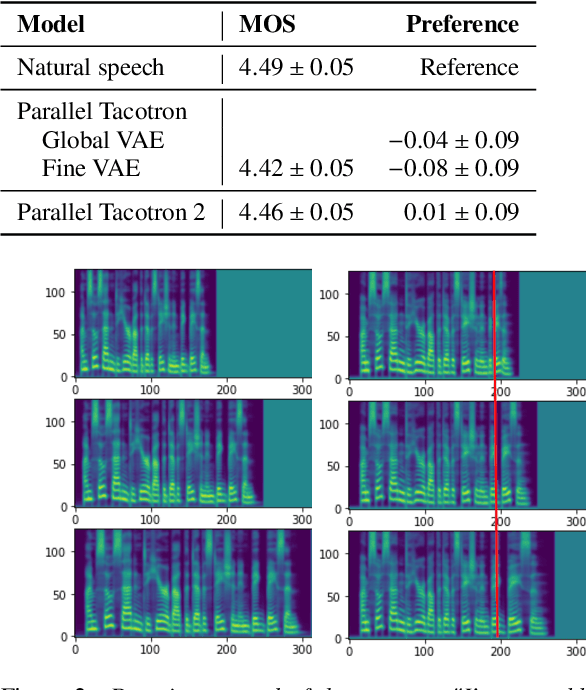

This paper introduces Parallel Tacotron 2, a non-autoregressive neural text-to-speech model with a fully differentiable duration model which does not require supervised duration signals. The duration model is based on a novel attention mechanism and an iterative reconstruction loss based on Soft Dynamic Time Warping, this model can learn token-frame alignments as well as token durations automatically. Experimental results show that Parallel Tacotron 2 outperforms baselines in subjective naturalness in several diverse multi speaker evaluations. Its duration control capability is also demonstrated.
A Benchmarking on Cloud based Speech-To-Text Services for French Speech and Background Noise Effect
May 07, 2021
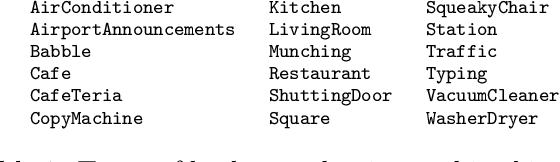
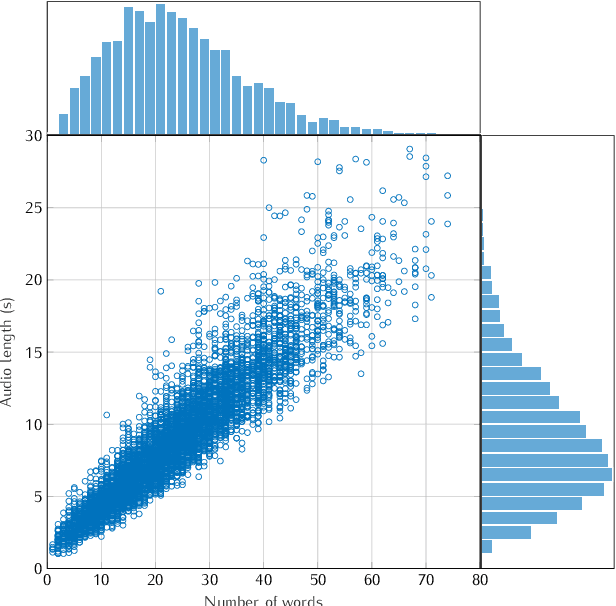
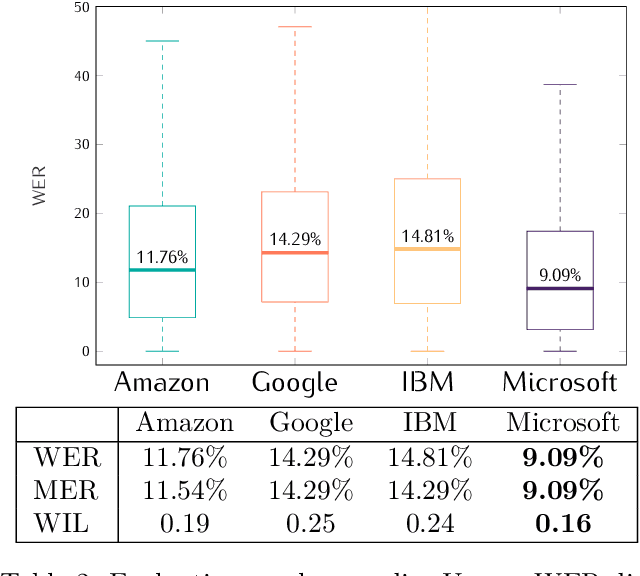
This study presents a large scale benchmarking on cloud based Speech-To-Text systems: {Google Cloud Speech-To-Text}, {Microsoft Azure Cognitive Services}, {Amazon Transcribe}, {IBM Watson Speech to Text}. For each systems, 40158 clean and noisy speech files about 101 hours are tested. Effect of background noise on STT quality is also evaluated with 5 different Signal-to-noise ratios from 40dB to 0dB. Results showed that {Microsoft Azure} provided lowest transcription error rate $9.09\%$ on clean speech, with high robustness to noisy environment. {Google Cloud} and {Amazon Transcribe} gave similar performance, but the latter is very limited for time-constraint usage. Though {IBM Watson} could work correctly in quiet conditions, it is highly sensible to noisy speech which could strongly limit its application in real life situations.
Optimal Estimator Design and Properties Analysis for Interconnected Systems with Asymmetric Information Structure
May 21, 2021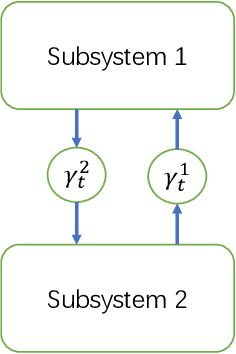
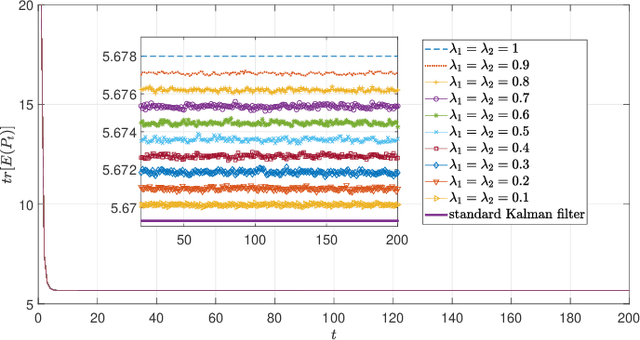
This paper studies the optimal state estimation problem for interconnected systems. Each subsystem can obtain its own measurement in real time, while, the measurements transmitted between the subsystems suffer from random delay. The optimal estimator is analytically designed for minimizing the conditional error covariance. Due to the random delay, the error covariance of the estimation is random. The boundedness of the expected error covariance (EEC) is analyzed. In particular, a new condition that is easy to verify is established for the boundedness of EEC. Further, the properties about EEC with respect to the delay probability is studied. We found that there exists a critical probability such that the EEC is bounded if the delay probability is below the critical probability. Also, a lower and upper bound of the critical probability is effectively computed. Finally, the proposed results are applied to a power system, and the effectiveness of the designed methods is illustrated by simulations.
Towards Causal Models for Adversary Distractions
Apr 21, 2021
Automated adversary emulation is becoming an indispensable tool of network security operators in testing and evaluating their cyber defenses. At the same time, it has exposed how quickly adversaries can propagate through the network. While research has greatly progressed on quality decoy generation to fool human adversaries, we may need different strategies to slow computer agents. In this paper, we show that decoy generation can slow an automated agent's decision process, but that the degree to which it is inhibited is greatly dependent on the types of objects used. This points to the need to explicitly evaluate decoy generation and placement strategies against fast moving, automated adversaries.
Principled Exploration via Optimistic Bootstrapping and Backward Induction
May 17, 2021

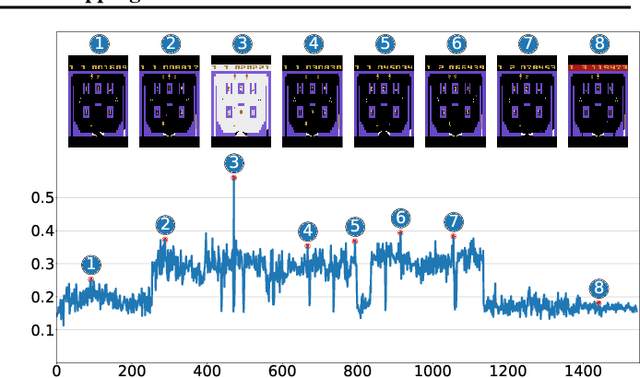
One principled approach for provably efficient exploration is incorporating the upper confidence bound (UCB) into the value function as a bonus. However, UCB is specified to deal with linear and tabular settings and is incompatible with Deep Reinforcement Learning (DRL). In this paper, we propose a principled exploration method for DRL through Optimistic Bootstrapping and Backward Induction (OB2I). OB2I constructs a general-purpose UCB-bonus through non-parametric bootstrap in DRL. The UCB-bonus estimates the epistemic uncertainty of state-action pairs for optimistic exploration. We build theoretical connections between the proposed UCB-bonus and the LSVI-UCB in a linear setting. We propagate future uncertainty in a time-consistent manner through episodic backward update, which exploits the theoretical advantage and empirically improves the sample-efficiency. Our experiments in the MNIST maze and Atari suite suggest that OB2I outperforms several state-of-the-art exploration approaches.
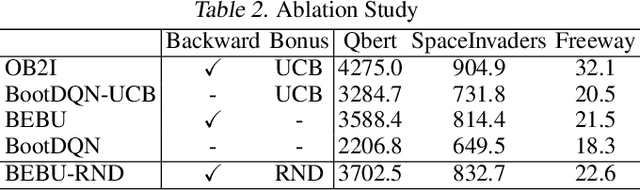
Two Novel Performance Improvements for Evolving CNN Topologies
Feb 10, 2021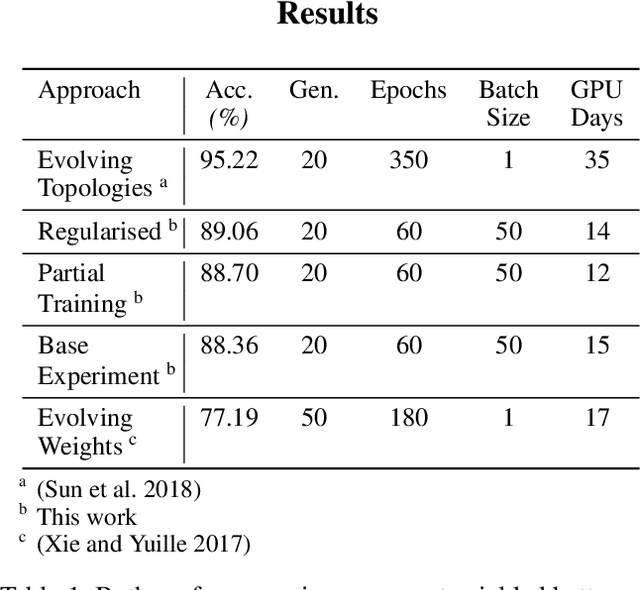
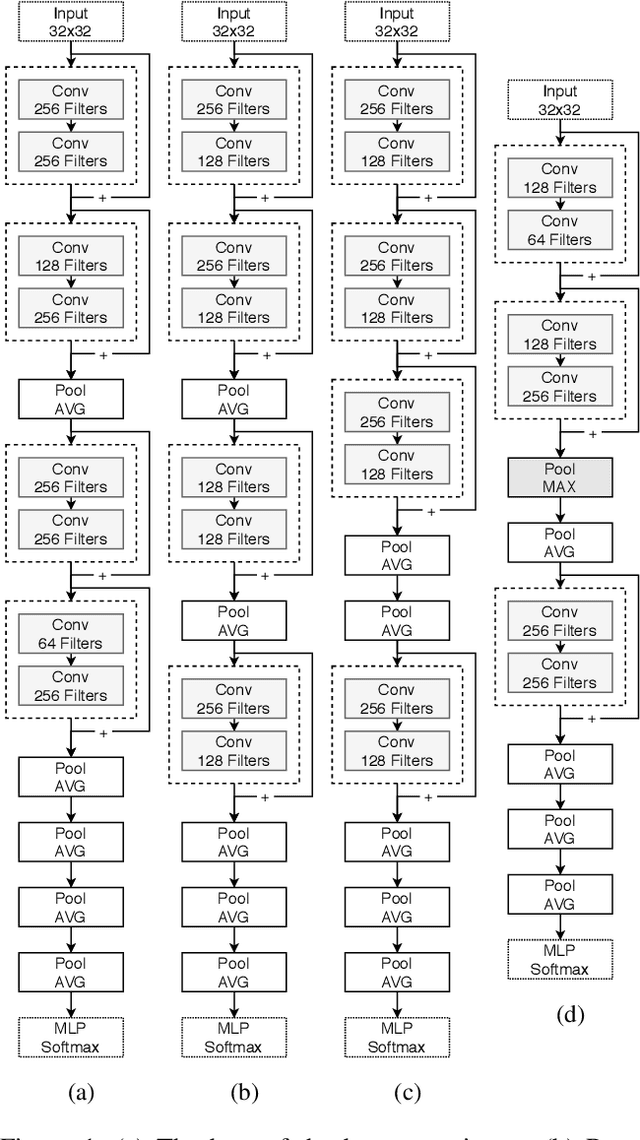
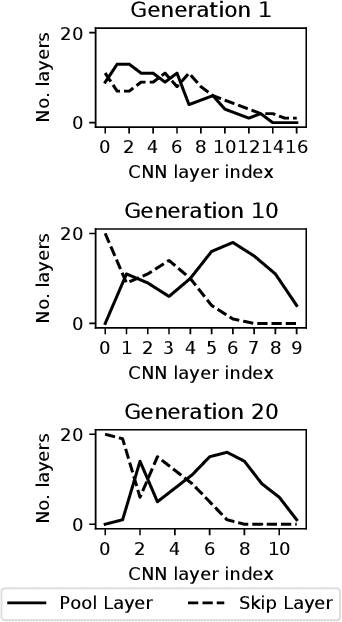
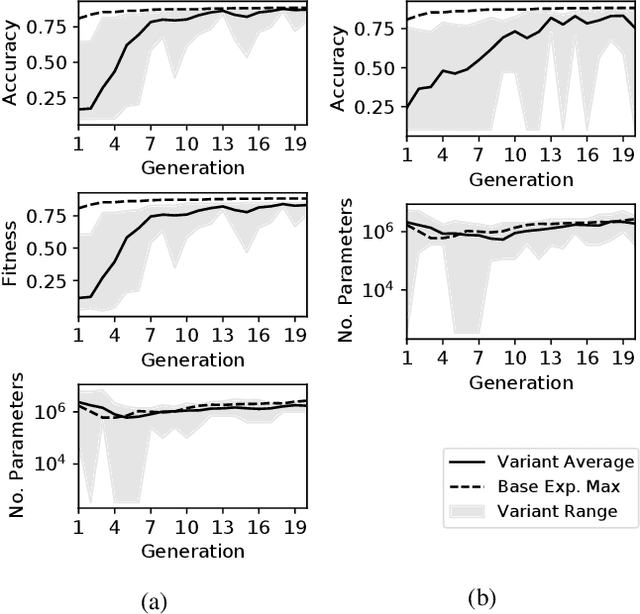
Convolutional Neural Networks (CNNs) are the state-of-the-art algorithms for the processing of images. However the configuration and training of these networks is a complex task requiring deep domain knowledge, experience and much trial and error. Using genetic algorithms, competitive CNN topologies for image recognition can be produced for any specific purpose, however in previous work this has come at high computational cost. In this work two novel approaches are presented to the utilisation of these algorithms, effective in reducing complexity and training time by nearly 20%. This is accomplished via regularisation directly on training time, and the use of partial training to enable early ranking of individual architectures. Both approaches are validated on the benchmark CIFAR10 data set, and maintain accuracy.
Time Series Compression Based on Adaptive Piecewise Recurrent Autoencoder
Aug 16, 2017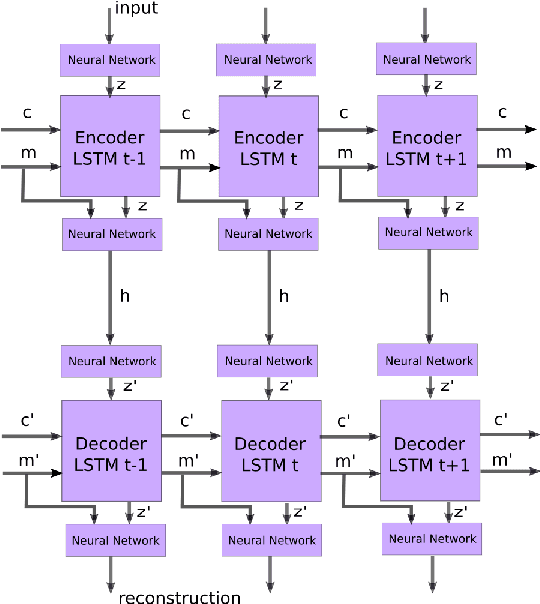
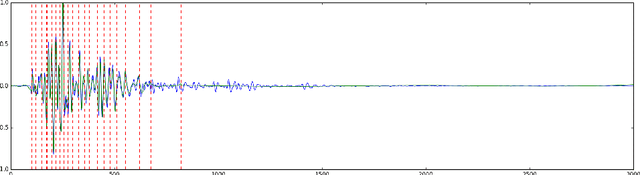
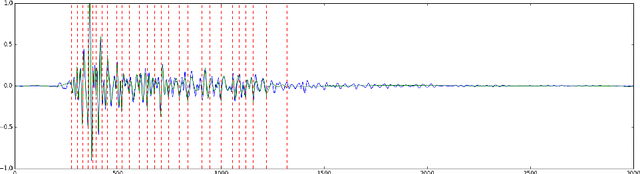
Time series account for a large proportion of the data stored in financial, medical and scientific databases. The efficient storage of time series is important in practical applications. In this paper, we propose a novel compression scheme for time series. The encoder and decoder are both composed by recurrent neural networks (RNN) such as long short-term memory (LSTM). There is an autoencoder between encoder and decoder, which encodes the hidden state and input together and decodes them at the decoder side. Moreover, we pre-process the original time series by partitioning it into segments with various lengths which have similar total variation. The experimental study shows that the proposed algorithm can achieve competitive compression ratio on real-world time series.
Concept Drift Detection from Multi-Class Imbalanced Data Streams
Apr 20, 2021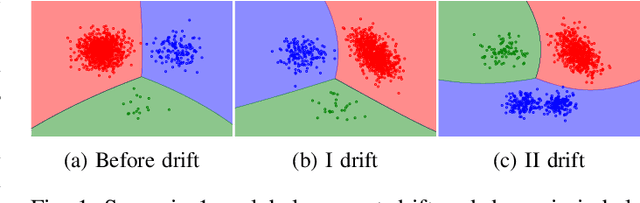

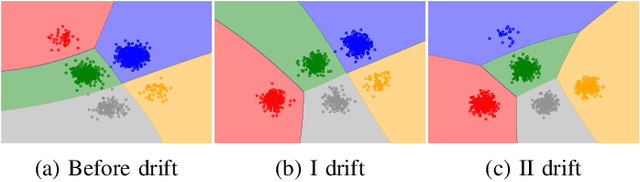
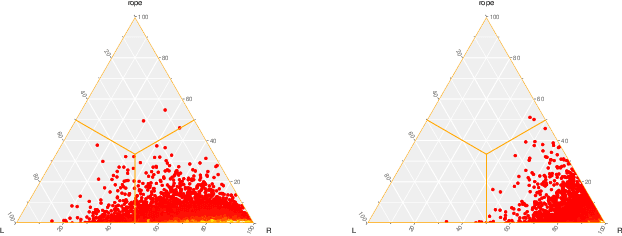
Continual learning from data streams is among the most important topics in contemporary machine learning. One of the biggest challenges in this domain lies in creating algorithms that can continuously adapt to arriving data. However, previously learned knowledge may become outdated, as streams evolve over time. This phenomenon is known as concept drift and must be detected to facilitate efficient adaptation of the learning model. While there exists a plethora of drift detectors, all of them assume that we are dealing with roughly balanced classes. In the case of imbalanced data streams, those detectors will be biased towards the majority classes, ignoring changes happening in the minority ones. Furthermore, class imbalance may evolve over time and classes may change their roles (majority becoming minority and vice versa). This is especially challenging in the multi-class setting, where relationships among classes become complex. In this paper, we propose a detailed taxonomy of challenges posed by concept drift in multi-class imbalanced data streams, as well as a novel trainable concept drift detector based on Restricted Boltzmann Machine. It is capable of monitoring multiple classes at once and using reconstruction error to detect changes in each of them independently. Our detector utilizes a skew-insensitive loss function that allows it to handle multiple imbalanced distributions. Due to its trainable nature, it is capable of following changes in a stream and evolving class roles, as well as it can deal with local concept drift occurring in minority classes. Extensive experimental study on multi-class drifting data streams, enriched with a detailed analysis of the impact of local drifts and changing imbalance ratios, confirms the high efficacy of our approach.
Improving weakly supervised sound event detection with self-supervised auxiliary tasks
Jun 12, 2021

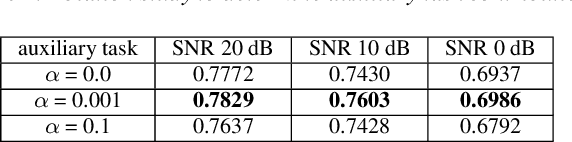
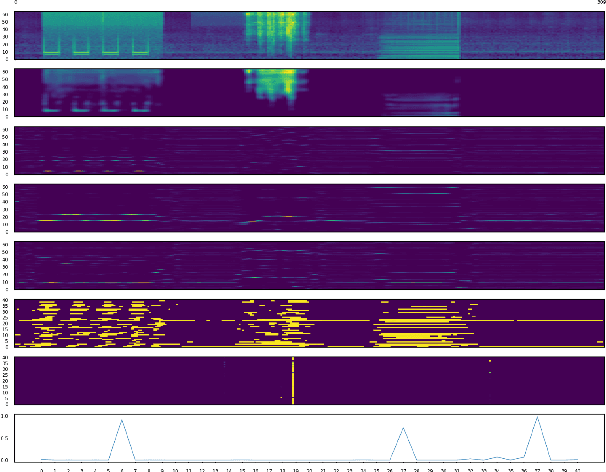
While multitask and transfer learning has shown to improve the performance of neural networks in limited data settings, they require pretraining of the model on large datasets beforehand. In this paper, we focus on improving the performance of weakly supervised sound event detection in low data and noisy settings simultaneously without requiring any pretraining task. To that extent, we propose a shared encoder architecture with sound event detection as a primary task and an additional secondary decoder for a self-supervised auxiliary task. We empirically evaluate the proposed framework for weakly supervised sound event detection on a remix dataset of the DCASE 2019 task 1 acoustic scene data with DCASE 2018 Task 2 sounds event data under 0, 10 and 20 dB SNR. To ensure we retain the localisation information of multiple sound events, we propose a two-step attention pooling mechanism that provides a time-frequency localisation of multiple audio events in the clip. The proposed framework with two-step attention outperforms existing benchmark models by 22.3%, 12.8%, 5.9% on 0, 10 and 20 dB SNR respectively. We carry out an ablation study to determine the contribution of the auxiliary task and two-step attention pooling to the SED performance improvement.
Optimal Resource Allocation for Full-Duplex IoT Systems Underlaying Cellular Networks with Mutual SIC NOMA
Apr 08, 2021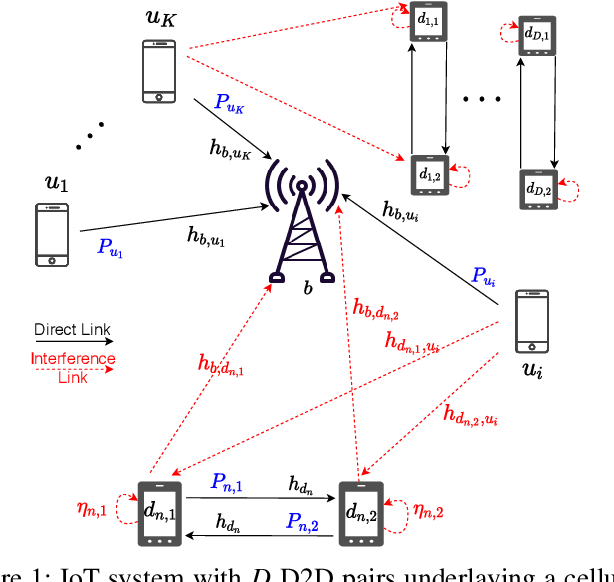
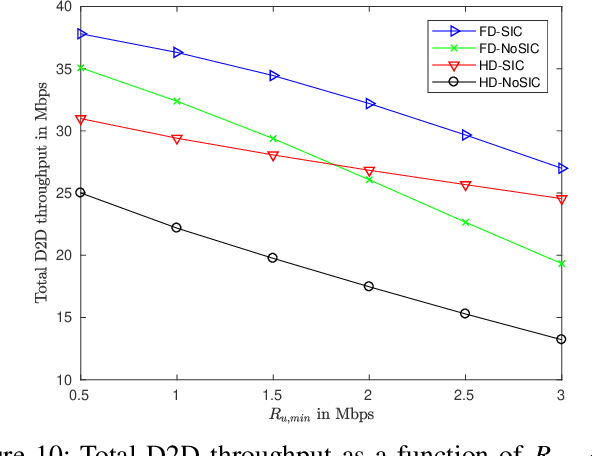
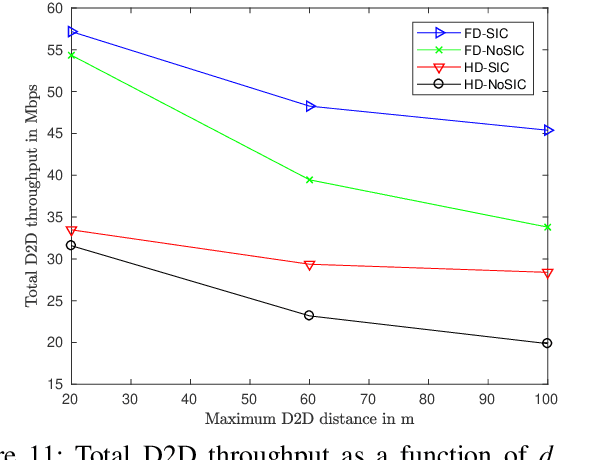
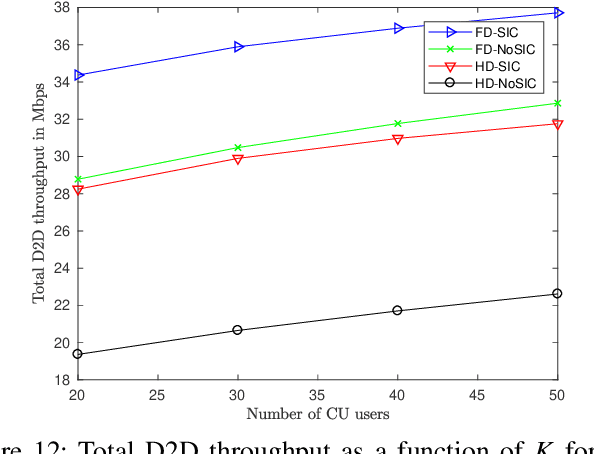
Device-to-device (D2D) and non-orthogonal multiple access (NOMA) are promising technologies to meet the challenges of the next generations of mobile communications in terms of network density and diversity for internet of things (IoT) services. This paper tackles the problem of maximizing the D2D sum-throughput in an IoT system underlaying a cellular network, through optimal channel and power allocation. NOMA is used to manage the interference between cellular users and full-duplex (FD) IoT devices. To this aim, mutual successive interference cancellation (SIC) conditions are identified to allow simultaneously the removal of the D2D devices interference at the level of the base station and the removal of the cellular users (CU) interference at the level of D2D devices. To optimally solve the joint channel and power allocation (PA) problem, a time-efficient solution of the PA problem in the FD context is elaborated. By means of graphical representation, the complex non-convex PA problem is efficiently solved in constant time complexity. This enables the global optimal resolution by successively solving the separate PA and channel assignment problems. The performance of the proposed strategy is compared against the classical state-of-the-art FD and HD scenarios, where SIC is not applied between CUs and IoT devices. The results show that important gains can be achieved by applying mutual SIC NOMA in the IoT-cellular context, in either HD or FD scenarios.