 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
TIMEDIAL: Temporal Commonsense Reasoning in Dialog
Jun 08, 2021

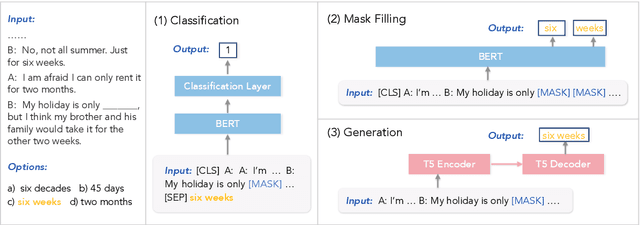

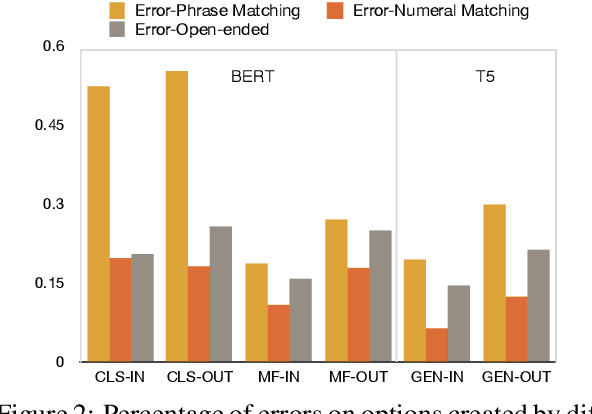
Everyday conversations require understanding everyday events, which in turn, requires understanding temporal commonsense concepts interwoven with those events. Despite recent progress with massive pre-trained language models (LMs) such as T5 and GPT-3, their capability of temporal reasoning in dialogs remains largely under-explored. In this paper, we present the first study to investigate pre-trained LMs for their temporal reasoning capabilities in dialogs by introducing a new task and a crowd-sourced English challenge set, TIMEDIAL. We formulate TIME-DIAL as a multiple-choice cloze task with over 1.1K carefully curated dialogs. Empirical results demonstrate that even the best performing models struggle on this task compared to humans, with 23 absolute points of gap in accuracy. Furthermore, our analysis reveals that the models fail to reason about dialog context correctly; instead, they rely on shallow cues based on existing temporal patterns in context, motivating future research for modeling temporal concepts in text and robust contextual reasoning about them. The dataset is publicly available at: https://github.com/google-research-datasets/timedial.
Localization-Based Tracking
Apr 12, 2021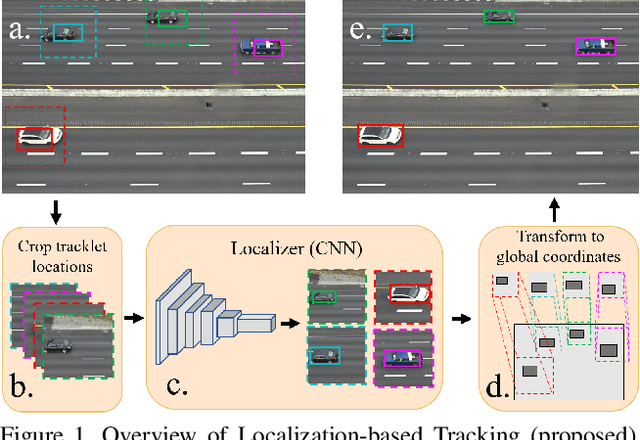
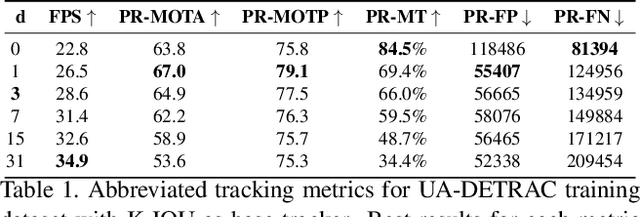
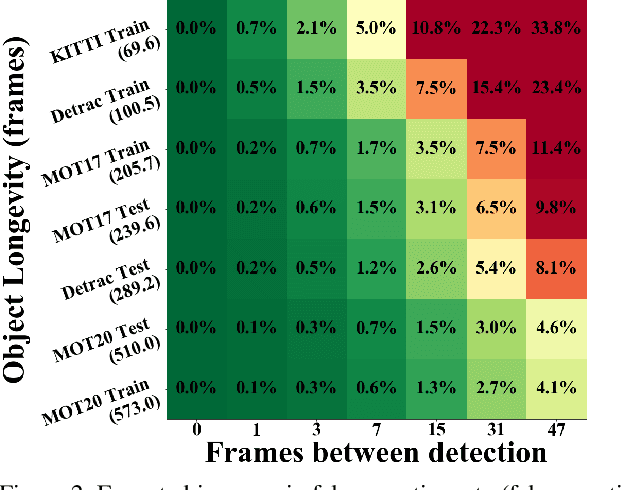
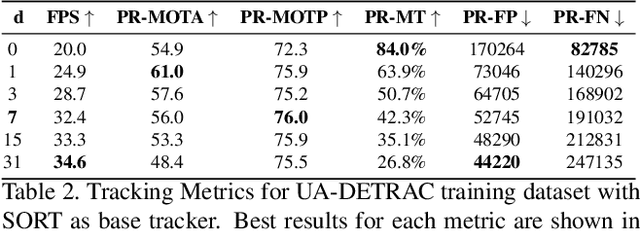
End-to-end production of object tracklets from high resolution video in real-time and with high accuracy remains a challenging problem due to the cost of object detection on each frame. In this work we present Localization-based Tracking (LBT), an extension to any tracker that follows the tracking by detection or joint detection and tracking paradigms. Localization-based Tracking focuses only on regions likely to contain objects to boost detection speed and avoid matching errors. We evaluate LBT as an extension to two example trackers (KIOU and SORT) on the UA-DETRAC and MOT20 datasets. LBT-extended trackers outperform all other reported algorithms in terms of PR-MOTA, PR-MOTP, and mostly tracked objects on the UA-DETRAC benchmark, establishing a new state-of-the art. relative to tracking by detection with KIOU, LBT-extended KIOU achieves a 25% higher frame-rate and is 1.1% more accurate in terms of PR-MOTA on the UA-DETRAC dataset. LBT-extended SORT achieves a 62% speedup and a 3.2% increase in PR-MOTA on the UA-DETRAC dataset. On MOT20, LBT-extended KIOU has a 50% higher frame-rate than tracking by detection and is 0.4% more accurate in terms of MOTA. As of submission time, our LBT-extended KIOU tracker places 10th overall on the MOT20 benchmark.
Factorising Meaning and Form for Intent-Preserving Paraphrasing
May 31, 2021
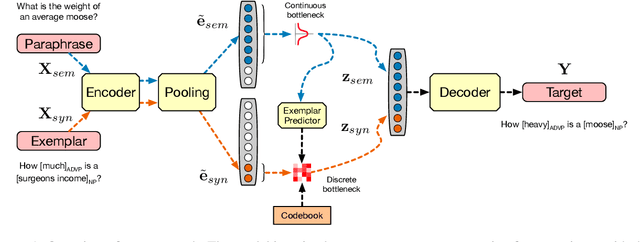

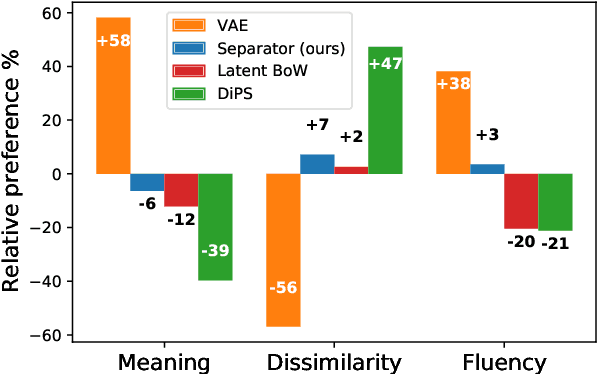
We propose a method for generating paraphrases of English questions that retain the original intent but use a different surface form. Our model combines a careful choice of training objective with a principled information bottleneck, to induce a latent encoding space that disentangles meaning and form. We train an encoder-decoder model to reconstruct a question from a paraphrase with the same meaning and an exemplar with the same surface form, leading to separated encoding spaces. We use a Vector-Quantized Variational Autoencoder to represent the surface form as a set of discrete latent variables, allowing us to use a classifier to select a different surface form at test time. Crucially, our method does not require access to an external source of target exemplars. Extensive experiments and a human evaluation show that we are able to generate paraphrases with a better tradeoff between semantic preservation and syntactic novelty compared to previous methods.
Sublinear Least-Squares Value Iteration via Locality Sensitive Hashing
Jun 08, 2021
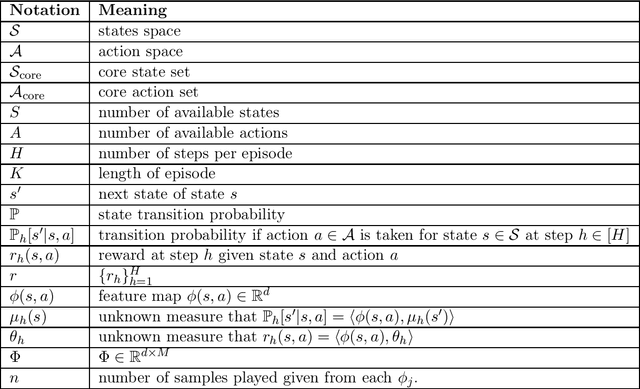
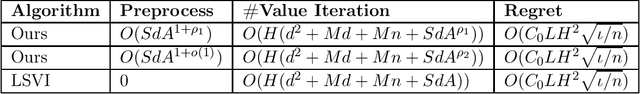

We present the first provable Least-Squares Value Iteration (LSVI) algorithms that have runtime complexity sublinear in the number of actions. We formulate the value function estimation procedure in value iteration as an approximate maximum inner product search problem and propose a locality sensitive hashing (LSH) [Indyk and Motwani STOC'98, Andoni and Razenshteyn STOC'15, Andoni, Laarhoven, Razenshteyn and Waingarten SODA'17] type data structure to solve this problem with sublinear time complexity. Moreover, we build the connections between the theory of approximate maximum inner product search and the regret analysis of reinforcement learning. We prove that, with our choice of approximation factor, our Sublinear LSVI algorithms maintain the same regret as the original LSVI algorithms while reducing the runtime complexity to sublinear in the number of actions. To the best of our knowledge, this is the first work that combines LSH with reinforcement learning resulting in provable improvements. We hope that our novel way of combining data-structures and iterative algorithm will open the door for further study into cost reduction in optimization.
MoCo-Flow: Neural Motion Consensus Flow for Dynamic Humans in Stationary Monocular Cameras
Jun 08, 2021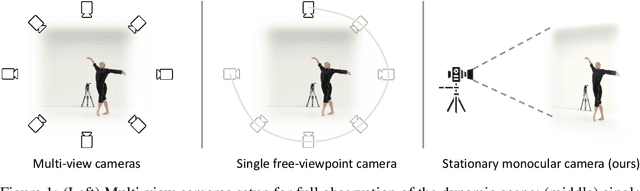

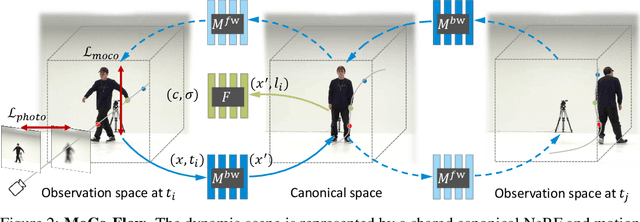

Synthesizing novel views of dynamic humans from stationary monocular cameras is a popular scenario. This is particularly attractive as it does not require static scenes, controlled environments, or specialized hardware. In contrast to techniques that exploit multi-view observations to constrain the modeling, given a single fixed viewpoint only, the problem of modeling the dynamic scene is significantly more under-constrained and ill-posed. In this paper, we introduce Neural Motion Consensus Flow (MoCo-Flow), a representation that models the dynamic scene using a 4D continuous time-variant function. The proposed representation is learned by an optimization which models a dynamic scene that minimizes the error of rendering all observation images. At the heart of our work lies a novel optimization formulation, which is constrained by a motion consensus regularization on the motion flow. We extensively evaluate MoCo-Flow on several datasets that contain human motions of varying complexity, and compare, both qualitatively and quantitatively, to several baseline methods and variants of our methods. Pretrained model, code, and data will be released for research purposes upon paper acceptance.
Choose a Transformer: Fourier or Galerkin
May 31, 2021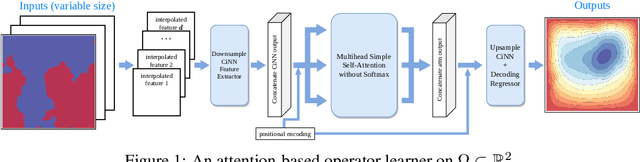

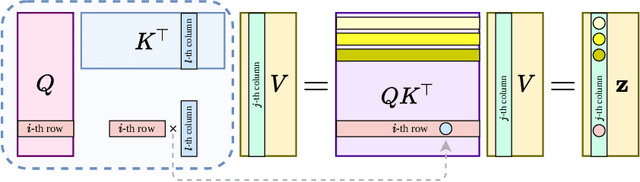

In this paper, we apply the self-attention from the state-of-art Transformer in Attention Is All You Need the first time to a data-driven operator learning problem related to partial differential equations. We put together an effort to explain the heuristics of, and improve the efficacy of the self-attention by demonstrating that the softmax normalization in the scaled dot-product attention is sufficient but not necessary, and have proved the approximation capacity of a linear variant as a Petrov-Galerkin projection. A new layer normalization scheme is proposed to allow a scaling to propagate through attention layers, which helps the model achieve remarkable accuracy in operator learning tasks with unnormalized data. Finally, we present three operator learning experiments, including the viscid Burgers' equation, an interface Darcy flow, and an inverse interface coefficient identification problem. All experiments validate the improvements of the newly proposed simple attention-based operator learner over their softmax-normalized counterparts.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
Apr 26, 2021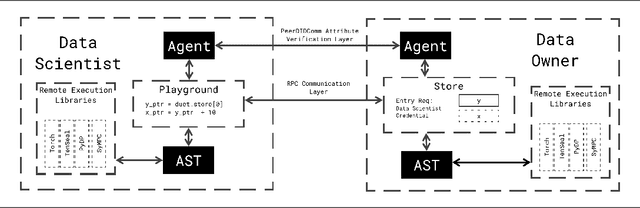
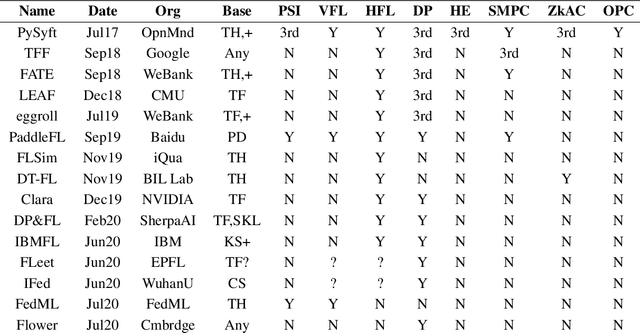
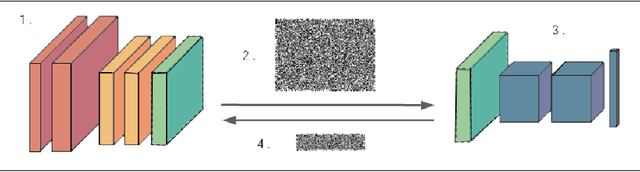
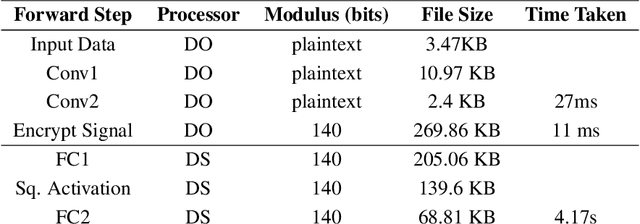
We present Syft, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems. This framework is demonstrated through the design and implementation of a novel privacy-preserving inference information flow where we pass homomorphically encrypted activation signals through a split neural network for inference. We show that splitting the model further up the computation chain significantly reduces the computation time of inference and the payload size of activation signals at the cost of model secrecy. We evaluate our proposed flow with respect to its provision of the core structural transparency principles.
Action Shuffle Alternating Learning for Unsupervised Action Segmentation
Apr 05, 2021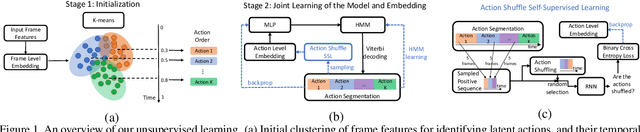
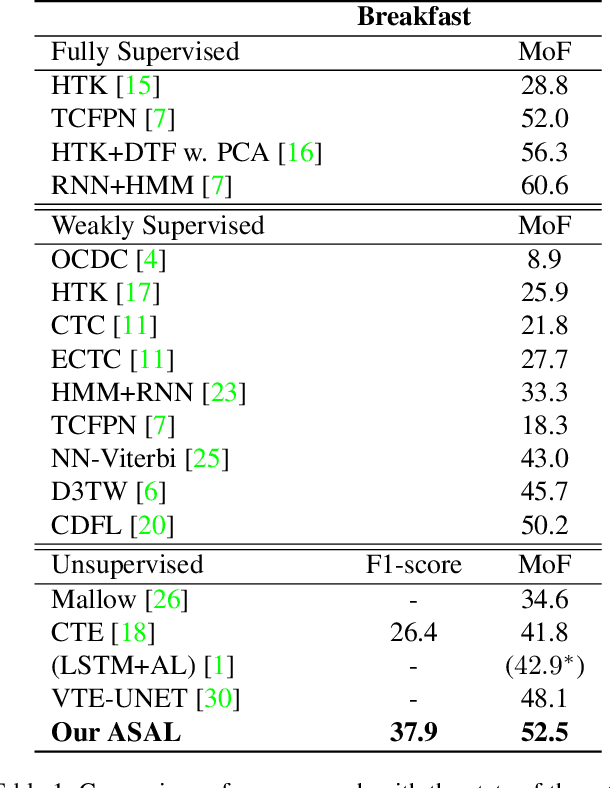
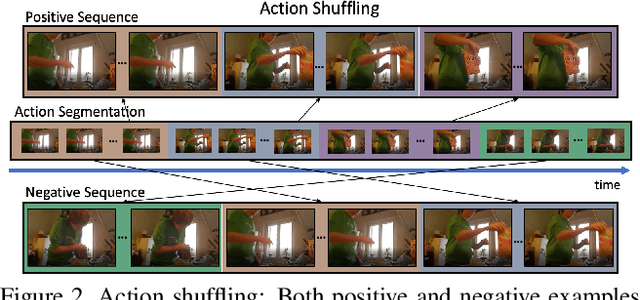
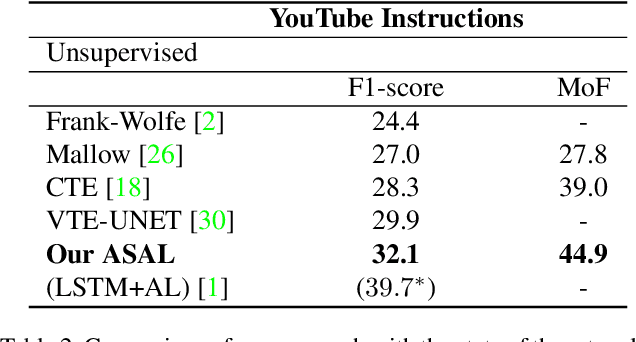
This paper addresses unsupervised action segmentation. Prior work captures the frame-level temporal structure of videos by a feature embedding that encodes time locations of frames in the video. We advance prior work with a new self-supervised learning (SSL) of a feature embedding that accounts for both frame- and action-level structure of videos. Our SSL trains an RNN to recognize positive and negative action sequences, and the RNN's hidden layer is taken as our new action-level feature embedding. The positive and negative sequences consist of action segments sampled from videos, where in the former the sampled action segments respect their time ordering in the video, and in the latter they are shuffled. As supervision of actions is not available and our SSL requires access to action segments, we specify an HMM that explicitly models action lengths, and infer a MAP action segmentation with the Viterbi algorithm. The resulting action segmentation is used as pseudo-ground truth for estimating our action-level feature embedding and updating the HMM. We alternate the above steps within the Generalized EM framework, which ensures convergence. Our evaluation on the Breakfast, YouTube Instructions, and 50Salads datasets gives superior results to those of the state of the art.
Online Bayesian inference for multiple changepoints and risk assessment
May 31, 2021The aim of the present study is to detect abrupt trend changes in the mean of a multidimensional sequential signal. Directly inspired by papers of Fernhead and Liu ([4] and [5]), this work describes the signal in a hierarchical manner : the change dates of a time segmentation process trigger the renewal of a piece-wise constant emission law. Bayesian posterior information on the change dates and emission parameters is obtained. These estimations can be revised online, i.e. as new data arrive. This paper proposes explicit formulations corresponding to various emission laws, as well as a generalization to the case where only partially observed data are available. Practical applications include the returns of partially observed multi-asset investment strategies, when only scant prior knowledge of the movers of the returns is at hand, limited to some statistical assumptions. This situation is different from the study of trend changes in the returns of individual assets, where fundamental exogenous information (news, earnings announcements, controversies, etc.) can be used.
YOLO5Face: Why Reinventing a Face Detector
May 27, 2021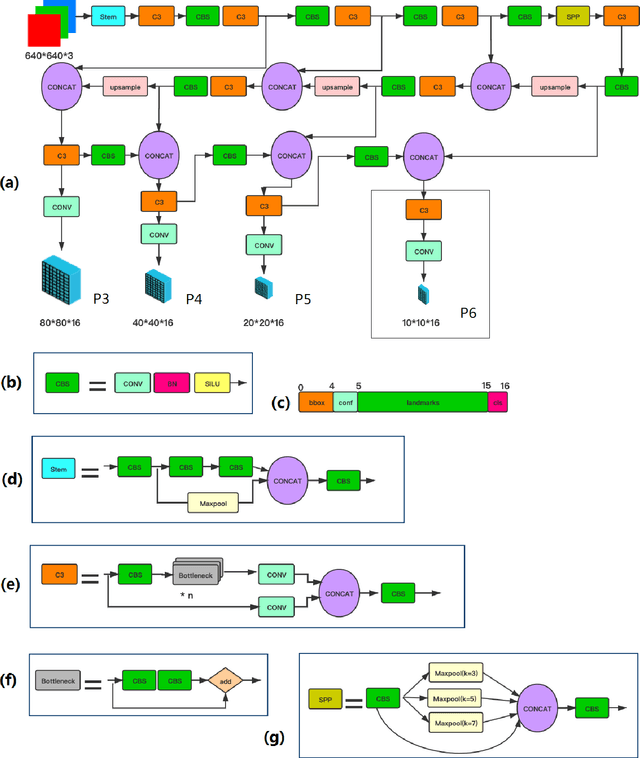
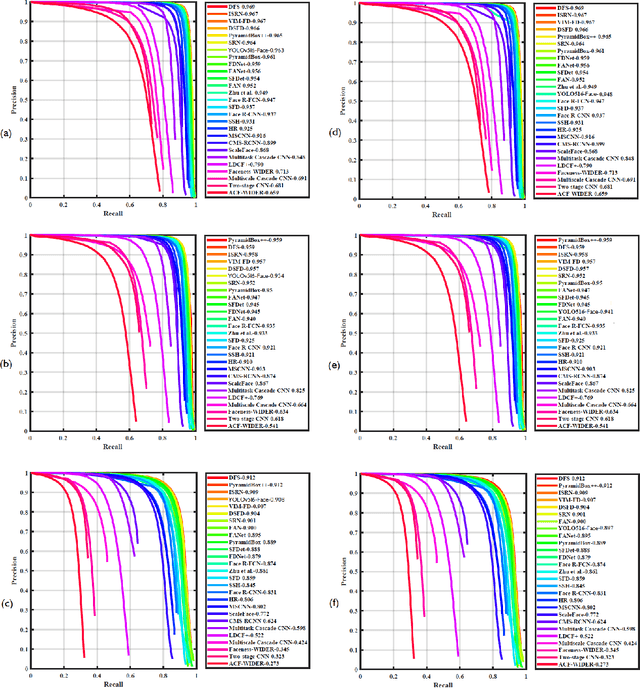
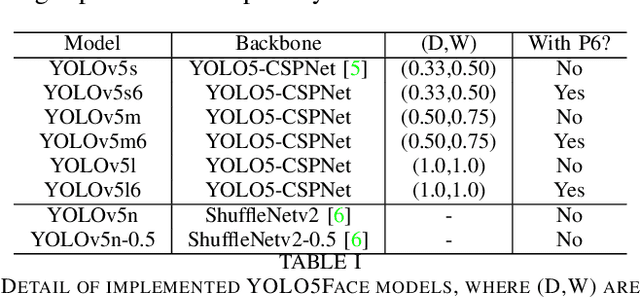
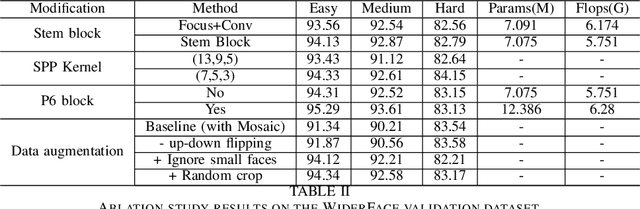
Tremendous progress has been made on face detection in recent years using convolutional neural networks. While many face detectors use designs designated for the detection of face, we treat face detection as a general object detection task. We implement a face detector based on YOLOv5 object detector and call it YOLO5Face. We add a five-point landmark regression head into it and use the Wing loss function. We design detectors with different model sizes, from a large model to achieve the best performance, to a super small model for real-time detection on an embedded or mobile device. Experiment results on the WiderFace dataset show that our face detectors can achieve state-of-the-art performance in almost all the Easy, Medium, and Hard subsets, exceeding the more complex designated face detectors. The code is available at \url{https://www.github.com/deepcam-cn/yolov5-face}.