 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResBM: Residual Bottleneck Models for Low-Bandwidth Pipeline Parallelism
Apr 13, 2026Unlocking large-scale low-bandwidth decentralized training has the potential to utilize otherwise untapped compute resources. In centralized settings, large-scale multi-node training is primarily enabled by data and pipeline parallelism, two techniques that require ultra-high-bandwidth communication. While efficient methods now exist for decentralized data parallelism, pipeline parallelism remains the primary challenge. Recent efforts, such as Subspace Models (SM), have claimed up to 100x activation compression but rely on complex constrained optimization and diverge from true end-to-end training. In this paper, we propose a different approach, based on an architecture designed from the ground up to be native to low-bandwidth communication environments while still applicable to any standard transformer-based architecture. We call this architecture the Residual Bottleneck Model or ResBM, it introduces a residual encoder-decoder bottleneck module across pipeline boundaries that can be trained end-to-end as part of the model's parameters while preserving an explicit low-rank identity path. We show that ResBMs achieve state-of-the-art 128x activation compression without significant loss in convergence rates and without significant memory or compute overhead.
Syft 0.5: A Platform for Universally Deployable Structured Transparency
Apr 27, 2021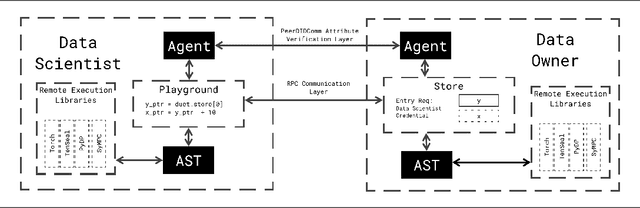
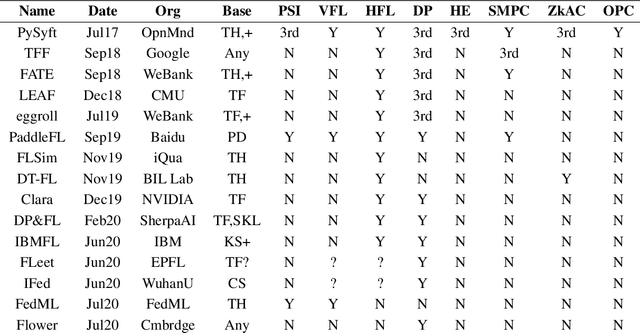
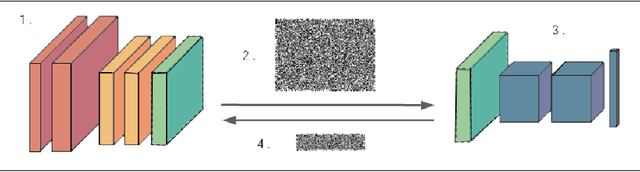
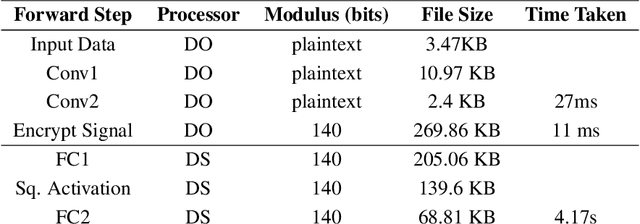
We present Syft 0.5, a general-purpose framework that combines a core group of privacy-enhancing technologies that facilitate a universal set of structured transparency systems. This framework is demonstrated through the design and implementation of a novel privacy-preserving inference information flow where we pass homomorphically encrypted activation signals through a split neural network for inference. We show that splitting the model further up the computation chain significantly reduces the computation time of inference and the payload size of activation signals at the cost of model secrecy. We evaluate our proposed flow with respect to its provision of the core structural transparency principles.