 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Last Query Transformer RNN for knowledge tracing
Feb 10, 2021
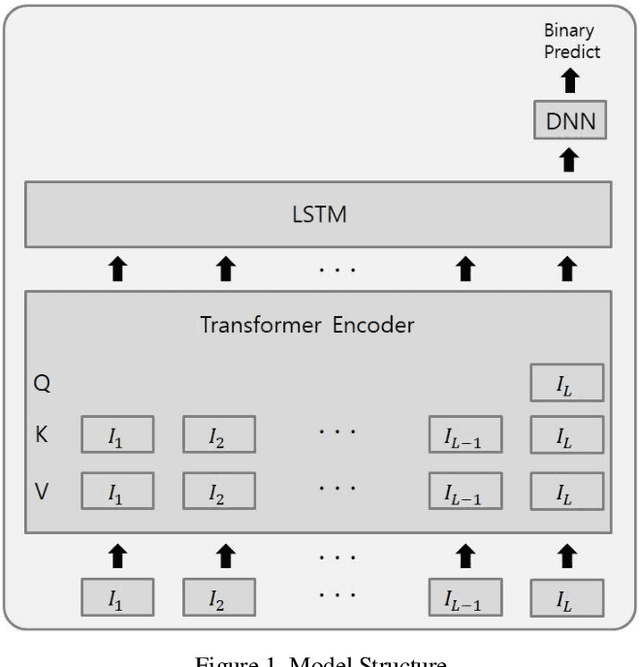
This paper presents an efficient model to predict a student's answer correctness given his past learning activities. Basically, I use both transformer encoder and RNN to deal with time series input. The novel point of the model is that it only uses the last input as query in transformer encoder, instead of all sequence, which makes QK matrix multiplication in transformer Encoder to have O(L) time complexity, instead of O(L^2). It allows the model to input longer sequence. Using this model I achieved the 1st place in the 'Riiid! Answer Correctness Prediction' competition hosted on kaggle.
Introducing "Neuromorphic Computing and Engineering"
May 30, 2021
The standard nature of computing is currently being challenged by a range of problems that start to hinder technological progress. One of the strategies being proposed to address some of these problems is to develop novel brain-inspired processing methods and technologies, and apply them to a wide range of application scenarios. This is an extremely challenging endeavor that requires researchers in multiple disciplines to combine their efforts and co-design at the same time the processing methods, the supporting computing architectures, and their underlying technologies. The journal ``Neuromorphic Computing and Engineering'' (NCE) has been launched to support this new community in this effort and provide a forum and repository for presenting and discussing its latest advances. Through close collaboration with our colleagues on the editorial team, the scope and characteristics of NCE have been designed to ensure it serves a growing transdisciplinary and dynamic community across academia and industry.
A Variational Time Series Feature Extractor for Action Prediction
Sep 26, 2018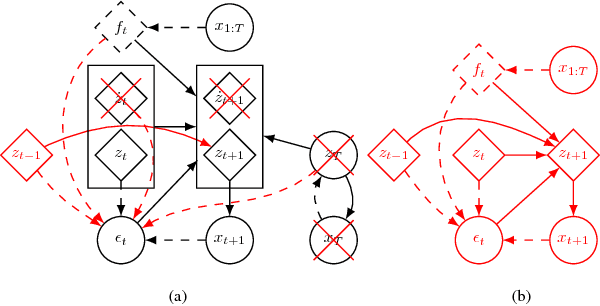

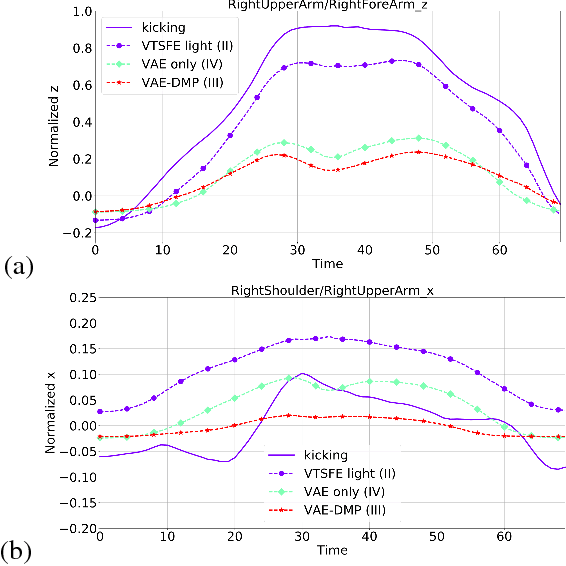
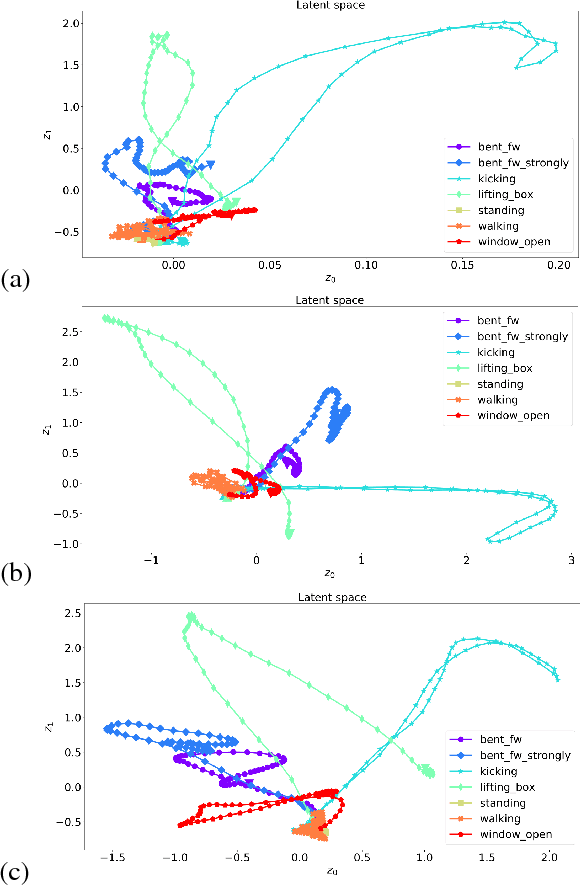
We propose a Variational Time Series Feature Extractor (VTSFE), inspired by the VAE-DMP model of Chen et al., to be used for action recognition and prediction. Our method is based on variational autoencoders. It improves VAE-DMP in that it has a better noise inference model, a simpler transition model constraining the acceleration in the trajectories of the latent space, and a tighter lower bound for the variational inference. We apply the method for classification and prediction of whole-body movements on a dataset with 7 tasks and 10 demonstrations per task, recorded with a wearable motion capture suit. The comparison with VAE and VAE-DMP suggests the better performance of our method for feature extraction. An open-source software implementation of each method with TensorFlow is also provided. In addition, a more detailed version of this work can be found in the indicated code repository. Although it was meant to, the VTSFE hasn't been tested for action prediction, due to a lack of time in the context of Maxime Chaveroche's Master thesis at INRIA.
Does Time-Delay Feedback Matter to Small Target Motion Detection Against Complex Dynamic Environments?
Dec 29, 2019
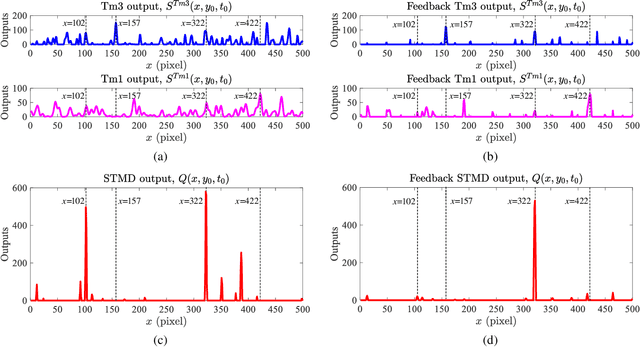
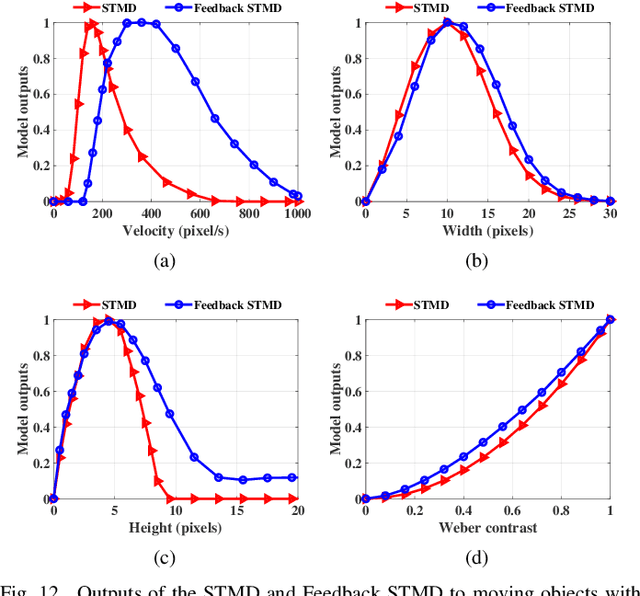
Discriminating small moving objects in complex visual environments is a significant challenge for autonomous micro robots that are generally limited in computational power. Relying on well-evolved visual systems, flying insects can effortlessly detect mates and track prey in rapid pursuits, despite target sizes as small as a few pixels in the visual field. Such exquisite sensitivity for small target motion is known to be supported by a class of specialized neurons named as small target motion detectors (STMDs). The existing STMD-based models normally consist of four sequentially arranged neural layers interconnected through feedforward loops to extract motion information about small targets from raw visual inputs. However, feedback loop, another important regulatory circuit for motion perception, has not been investigated in the STMD pathway and its functional roles for small target motion detection are not clear. In this paper, we assume the existence of the feedback and propose a STMD-based visual system with feedback connection (Feedback STMD), where the system output is temporally delayed, then fed back to lower layers to mediate neural responses. We compare the properties of the visual system with and without the time-delay feedback loop, and discuss its effect on small target motion detection. The experimental results suggest that the Feedback STMD prefers fast-moving small targets, while significantly suppresses those background features moving at lower velocities.
Diversifying Dialog Generation via Adaptive Label Smoothing
May 30, 2021
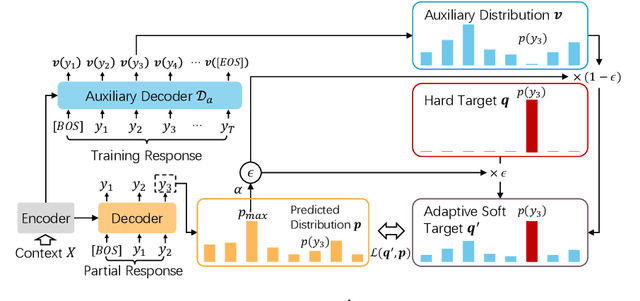
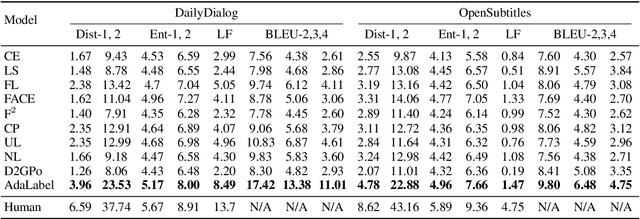
Neural dialogue generation models trained with the one-hot target distribution suffer from the over-confidence issue, which leads to poor generation diversity as widely reported in the literature. Although existing approaches such as label smoothing can alleviate this issue, they fail to adapt to diverse dialog contexts. In this paper, we propose an Adaptive Label Smoothing (AdaLabel) approach that can adaptively estimate a target label distribution at each time step for different contexts. The maximum probability in the predicted distribution is used to modify the soft target distribution produced by a novel light-weight bi-directional decoder module. The resulting target distribution is aware of both previous and future contexts and is adjusted to avoid over-training the dialogue model. Our model can be trained in an end-to-end manner. Extensive experiments on two benchmark datasets show that our approach outperforms various competitive baselines in producing diverse responses.
Causally-motivated Shortcut Removal Using Auxiliary Labels
Jun 03, 2021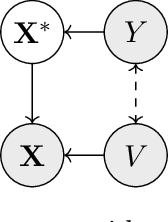

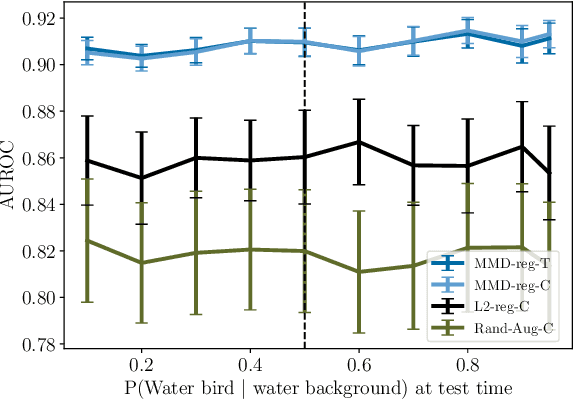
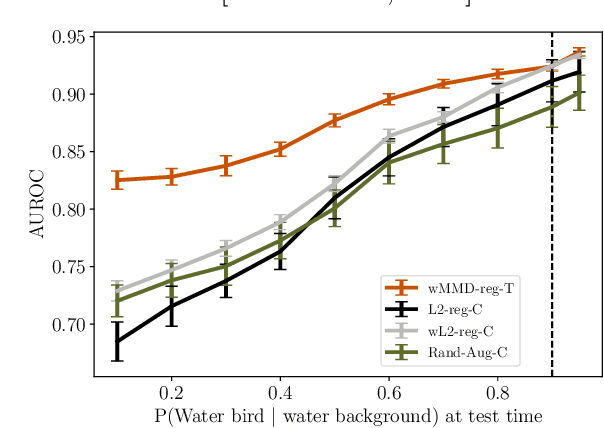
Robustness to certain forms of distribution shift is a key concern in many ML applications. Often, robustness can be formulated as enforcing invariances to particular interventions on the data generating process. Here, we study a flexible, causally-motivated approach to enforcing such invariances, paying special attention to shortcut learning, where a robust predictor can achieve optimal i.i.d generalization in principle, but instead it relies on spurious correlations or shortcuts in practice. Our approach uses auxiliary labels, typically available at training time, to enforce conditional independences between the latent factors that determine these labels. We show both theoretically and empirically that causally-motivated regularization schemes (a) lead to more robust estimators that generalize well under distribution shift, and (b) have better finite sample efficiency compared to usual regularization schemes, even in the absence of distribution shifts. Our analysis highlights important theoretical properties of training techniques commonly used in causal inference, fairness, and disentanglement literature.
Operator Autoencoders: Learning Physical Operations on Encoded Molecular Graphs
May 26, 2021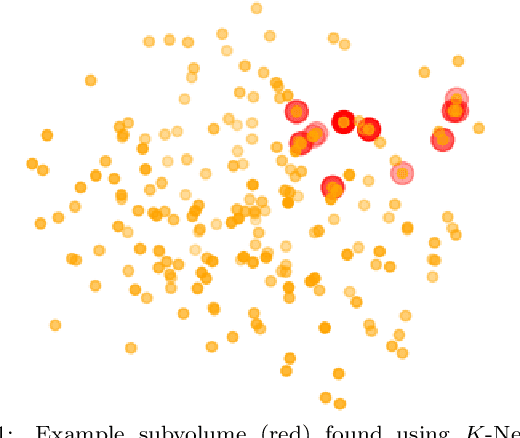
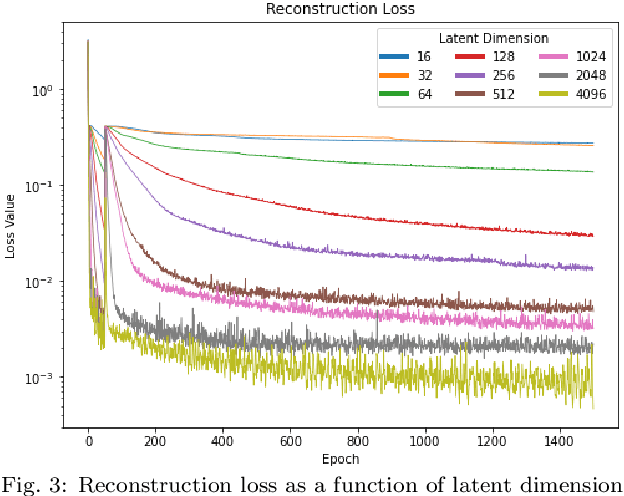
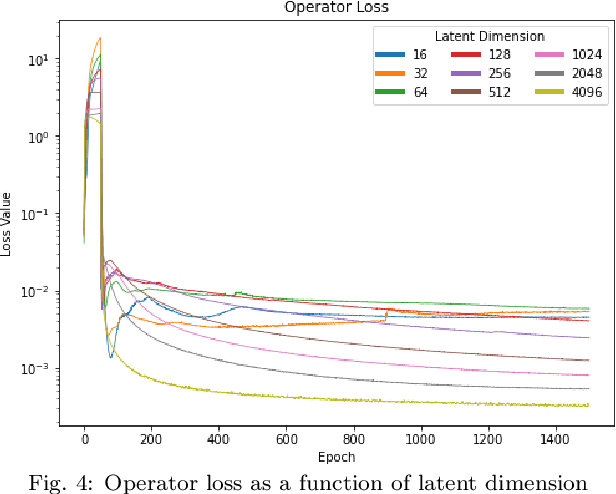
Molecular dynamics simulations produce data with complex nonlinear dynamics. If the timestep behavior of such a dynamic system can be represented by a linear operator, future states can be inferred directly without expensive simulations. The use of an autoencoder in combination with a physical timestep operator allows both the relevant structural characteristics of the molecular graphs and the underlying physics of the system to be isolated during the training process. In this work, we develop a pipeline for establishing graph-structured representations of time-series volumetric data from molecular dynamics simulations. We then train an autoencoder to find nonlinear mappings to a latent space where future timesteps can be predicted through application of a linear operator trained in tandem with the autoencoder. Increasing the dimensionality of the autoencoder output is shown to improve the accuracy of the physical timestep operator.
Sequential Estimation of Convex Divergences using Reverse Submartingales and Exchangeable Filtrations
Mar 16, 2021We present a unified technique for sequential estimation of convex divergences between distributions, including integral probability metrics like the kernel maximum mean discrepancy, $\varphi$-divergences like the Kullback-Leibler divergence, and optimal transport costs, such as powers of Wasserstein distances. The technical underpinnings of our approach lie in the observation that empirical convex divergences are (partially ordered) reverse submartingales with respect to the exchangeable filtration, coupled with maximal inequalities for such processes. These techniques appear to be powerful additions to the existing literature on both confidence sequences and convex divergences. We construct an offline-to-sequential device that converts a wide array of existing offline concentration inequalities into time-uniform confidence sequences that can be continuously monitored, providing valid inference at arbitrary stopping times. The resulting sequential bounds pay only an iterated logarithmic price over the corresponding fixed-time bounds, retaining the same dependence on problem parameters (like dimension or alphabet size if applicable).
Experimental Comparison of Visual and Single-Receiver GPS Odometry
Jun 03, 2021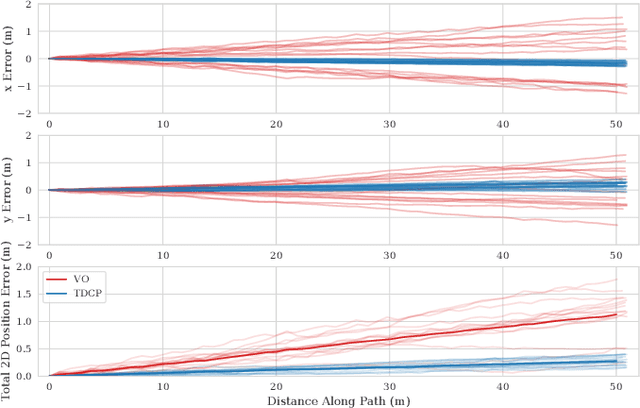
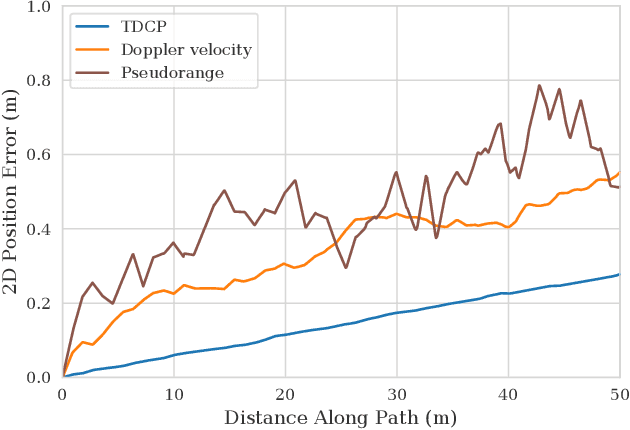
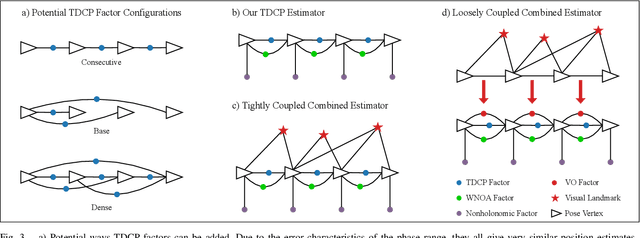
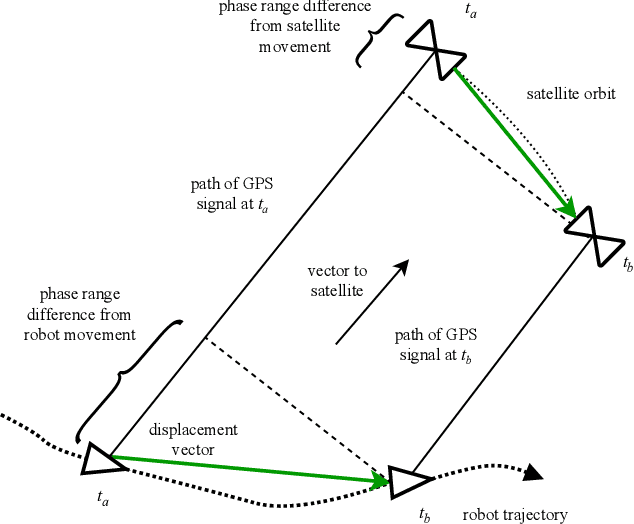
Mobile robots rely on odometry to navigate through areas where localization fails. Visual odometry (VO) is a common solution for obtaining robust and consistent relative motion estimates of the vehicle frame. Contrarily, Global Positioning System (GPS) measurements are typically used for absolute positioning and localization. However, when the constraint on absolute accuracy is relaxed, time-differenced carrier phase (TDCP) measurements can be used to find accurate relative position estimates with one single-frequency GPS receiver. This suggests practitioners may want to consider GPS odometry as an alternative or in combination with VO. We describe a robust method for single-receiver GPS odometry on an unmanned ground vehicle (UGV). We then present an experimental comparison of the two strategies on the same test trajectories. After 1.8km of testing, the results show our GPS odometry method has a 75% lower drift rate than a proven stereo VO method while maintaining a smooth error signal despite varying satellite availability.
Deep Generative Learning via Schrödinger Bridge
Jun 19, 2021
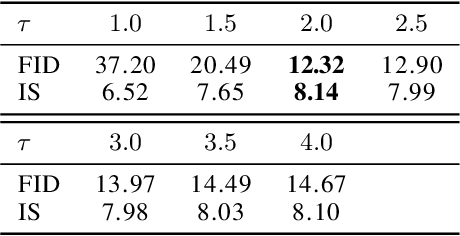

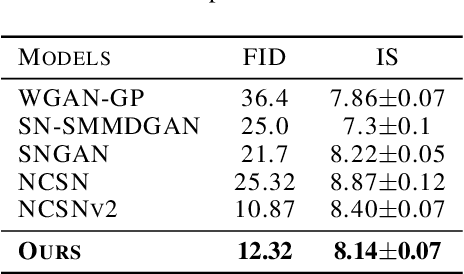
We propose to learn a generative model via entropy interpolation with a Schr\"{o}dinger Bridge. The generative learning task can be formulated as interpolating between a reference distribution and a target distribution based on the Kullback-Leibler divergence. At the population level, this entropy interpolation is characterized via an SDE on $[0,1]$ with a time-varying drift term. At the sample level, we derive our Schr\"{o}dinger Bridge algorithm by plugging the drift term estimated by a deep score estimator and a deep density ratio estimator into the Euler-Maruyama method. Under some mild smoothness assumptions of the target distribution, we prove the consistency of both the score estimator and the density ratio estimator, and then establish the consistency of the proposed Schr\"{o}dinger Bridge approach. Our theoretical results guarantee that the distribution learned by our approach converges to the target distribution. Experimental results on multimodal synthetic data and benchmark data support our theoretical findings and indicate that the generative model via Schr\"{o}dinger Bridge is comparable with state-of-the-art GANs, suggesting a new formulation of generative learning. We demonstrate its usefulness in image interpolation and image inpainting.