 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Feedback Control of Small Target Motion Detection Visual System
Nov 18, 2022



Feedback is crucial to motion perception in animals' visual systems where its spatial and temporal dynamics are often shaped by movement patterns of surrounding environments. However, such spatio-temporal feedback has not been deeply explored in designing neural networks to detect small moving targets that cover only one or a few pixels in image while presenting extremely limited visual features. In this paper, we address small target motion detection problem by developing a visual system with spatio-temporal feedback loop, and further reveal its important roles in suppressing false positive background movement while enhancing network responses to small targets. Specifically, the proposed visual system is composed of two complementary subnetworks. The first subnetwork is designed to extract spatial and temporal motion patterns of cluttered backgrounds by neuronal ensemble coding. The second subnetwork is developed to capture small target motion information and integrate the spatio-temporal feedback signal from the first subnetwork to inhibit background false positives. Experimental results demonstrate that the proposed spatio-temporal feedback visual system is more competitive than existing methods in discriminating small moving targets from complex dynamic environment.
Attention and Prediction Guided Motion Detection for Low-Contrast Small Moving Targets
May 08, 2021



Small target motion detection within complex natural environments is an extremely challenging task for autonomous robots. Surprisingly, the visual systems of insects have evolved to be highly efficient in detecting mates and tracking prey, even though targets are as small as a few pixels in their visual fields. The excellent sensitivity to small target motion relies on a class of specialized neurons called small target motion detectors (STMDs). However, existing STMD-based models are heavily dependent on visual contrast and perform poorly in complex natural environments where small targets generally exhibit extremely low contrast against neighbouring backgrounds. In this paper, we develop an attention and prediction guided visual system to overcome this limitation. The developed visual system comprises three main subsystems, namely, an attention module, an STMD-based neural network, and a prediction module. The attention module searches for potential small targets in the predicted areas of the input image and enhances their contrast against complex background. The STMD-based neural network receives the contrast-enhanced image and discriminates small moving targets from background false positives. The prediction module foresees future positions of the detected targets and generates a prediction map for the attention module. The three subsystems are connected in a recurrent architecture allowing information to be processed sequentially to activate specific areas for small target detection. Extensive experiments on synthetic and real-world datasets demonstrate the effectiveness and superiority of the proposed visual system for detecting small, low-contrast moving targets against complex natural environments.
Enhancing LGMD's Looming Selectivity for UAVs with Spatial-temporal Distributed Presynaptic Connection
May 19, 2020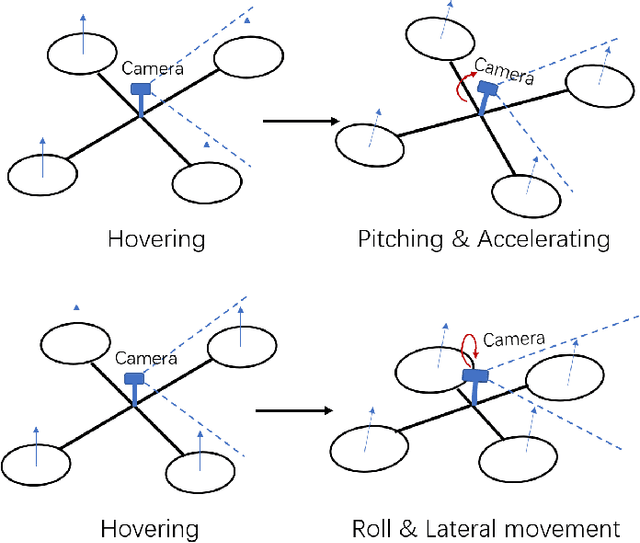
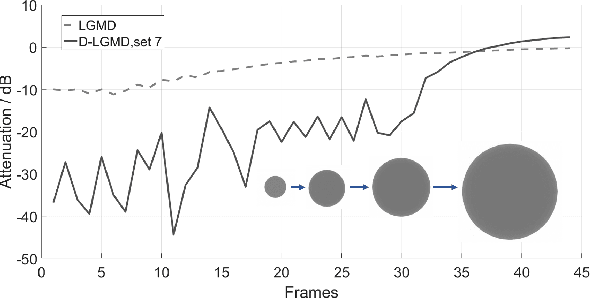
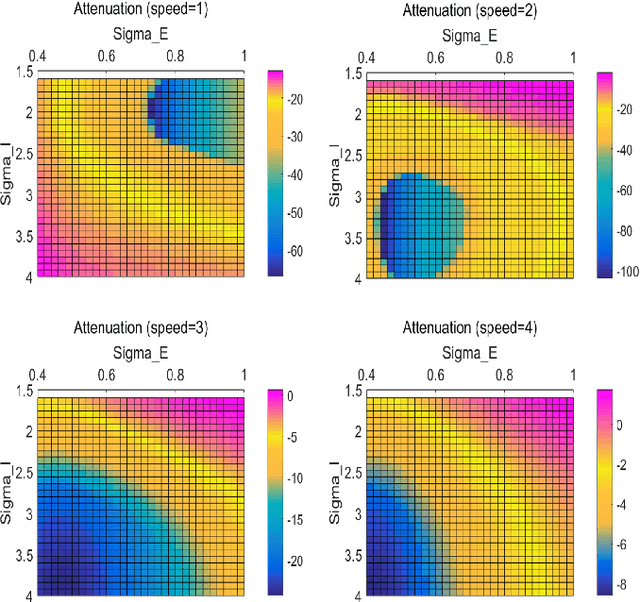
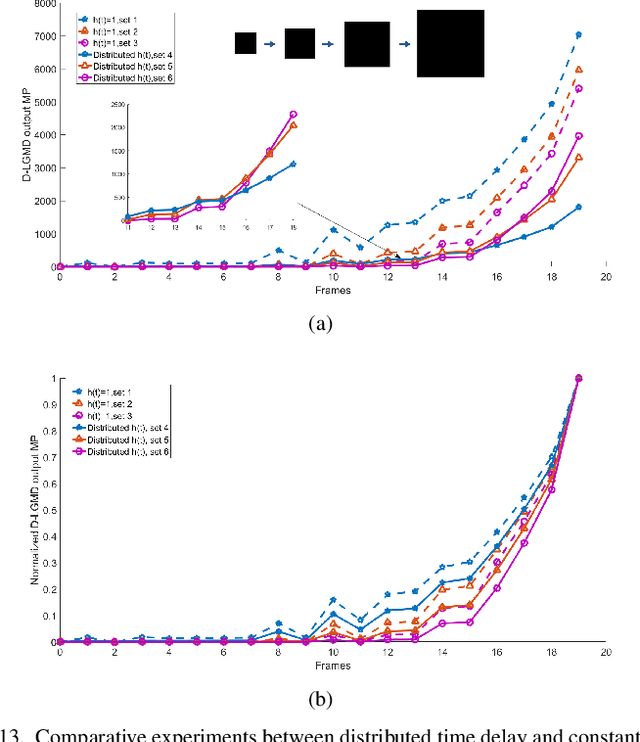
Collision detection is one of the most challenging tasks for Unmanned Aerial Vehicles (UAVs), especially for small or micro UAVs with limited computational power. In nature, fly insects with compact and simple visual systems demonstrate the amazing ability to navigating and avoid collision in a complex environment. A good example of this is locusts. Locusts avoid collision in a dense swarm relying on an identified vision neuron called Lobula Giant Movement Detector (LGMD) which has been modelled and applied on ground robots and vehicles. LGMD as a fly insect's visual neuron, is an ideal model for UAV collision detection. However, the existing models are inadequate in coping with complex visual challenges unique for UAVs. In this paper, we proposed a new LGMD model for flying robots considering distributed spatial-temporal computing for both excitation and inhibition to enhance the looming selectivity in flying scenes. The proposed model integrated recent discovered presynaptic connection types in biological LGMD neuron into a spatial-temporal filter with linear distributed interconnection. Systematic experiments containing quadcopter's first person view (FPV) flight videos demonstrated that the proposed distributed presynaptic structure can dramatically enhance LGMD's looming selectivity especially in complex flying UAV applications.
Does Time-Delay Feedback Matter to Small Target Motion Detection Against Complex Dynamic Environments?
Dec 29, 2019
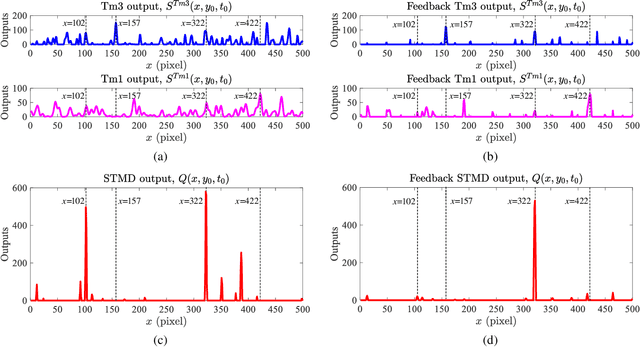
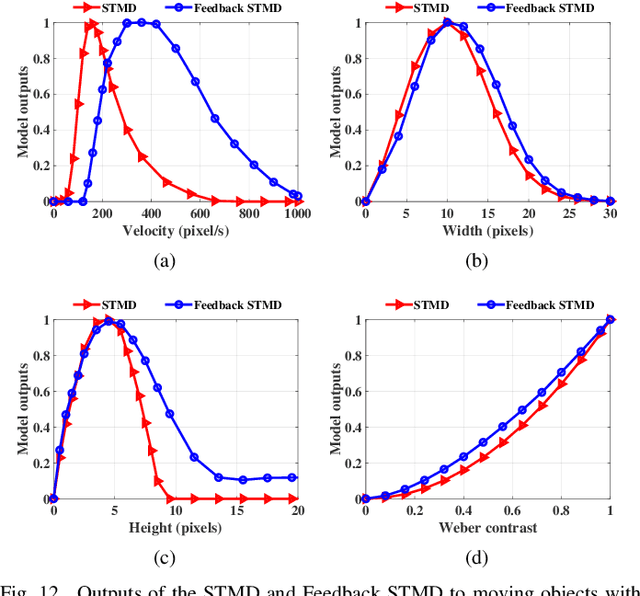
Discriminating small moving objects in complex visual environments is a significant challenge for autonomous micro robots that are generally limited in computational power. Relying on well-evolved visual systems, flying insects can effortlessly detect mates and track prey in rapid pursuits, despite target sizes as small as a few pixels in the visual field. Such exquisite sensitivity for small target motion is known to be supported by a class of specialized neurons named as small target motion detectors (STMDs). The existing STMD-based models normally consist of four sequentially arranged neural layers interconnected through feedforward loops to extract motion information about small targets from raw visual inputs. However, feedback loop, another important regulatory circuit for motion perception, has not been investigated in the STMD pathway and its functional roles for small target motion detection are not clear. In this paper, we assume the existence of the feedback and propose a STMD-based visual system with feedback connection (Feedback STMD), where the system output is temporally delayed, then fed back to lower layers to mediate neural responses. We compare the properties of the visual system with and without the time-delay feedback loop, and discuss its effect on small target motion detection. The experimental results suggest that the Feedback STMD prefers fast-moving small targets, while significantly suppresses those background features moving at lower velocities.
A Robust Visual System for Small Target Motion Detection Against Cluttered Moving Backgrounds
Apr 08, 2019
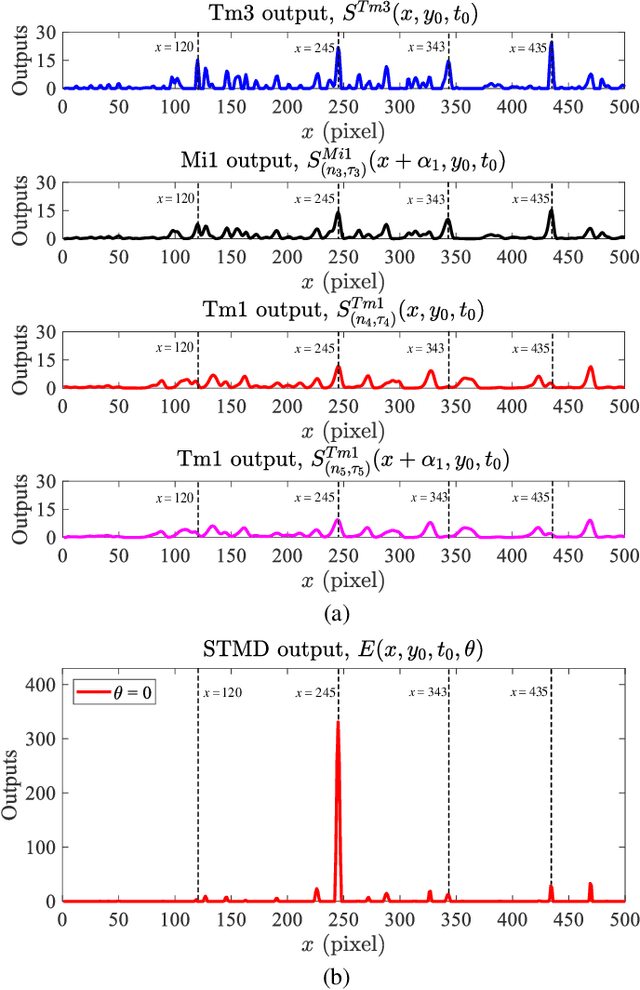
Monitoring small objects against cluttered moving backgrounds is a huge challenge to future robotic vision systems. As a source of inspiration, insects are quite apt at searching for mates and tracking prey -- which always appear as small dim speckles in the visual field. The exquisite sensitivity of insects for small target motion, as revealed recently, is coming from a class of specific neurons called small target motion detectors (STMDs). Although a few STMD-based models have been proposed, these existing models only use motion information for small target detection and cannot discriminate small targets from small-target-like background features (named as fake features). To address this problem, this paper proposes a novel visual system model (STMD+) for small target motion detection, which is composed of four subsystems -- ommatidia, motion pathway, contrast pathway and mushroom body. Compared to existing STMD-based models, the additional contrast pathway extracts directional contrast from luminance signals to eliminate false positive background motion. The directional contrast and the extracted motion information by the motion pathway are integrated in the mushroom body for small target discrimination. Extensive experiments showed the significant and consistent improvements of the proposed visual system model over existing STMD-based models against fake features.
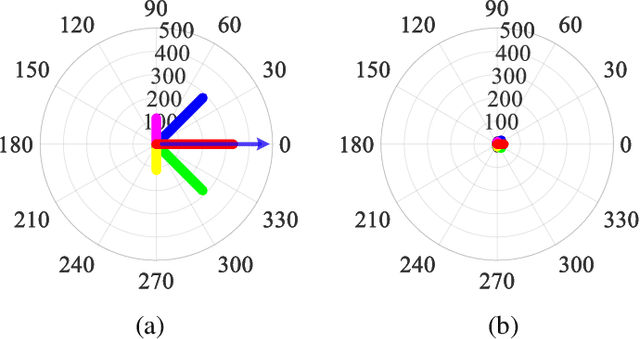
Constant Angular Velocity Regulation for Visually Guided Terrain Following
Apr 04, 2019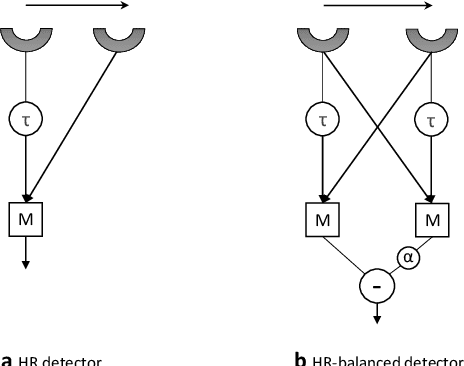

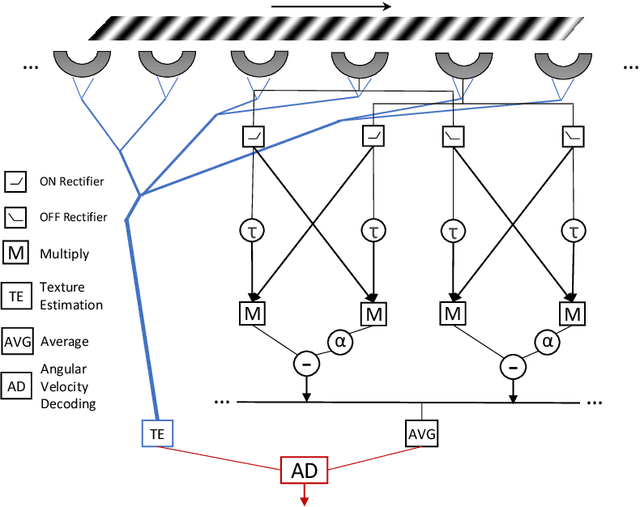
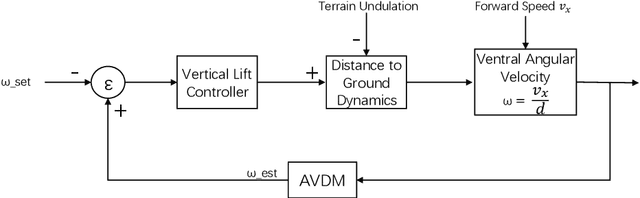
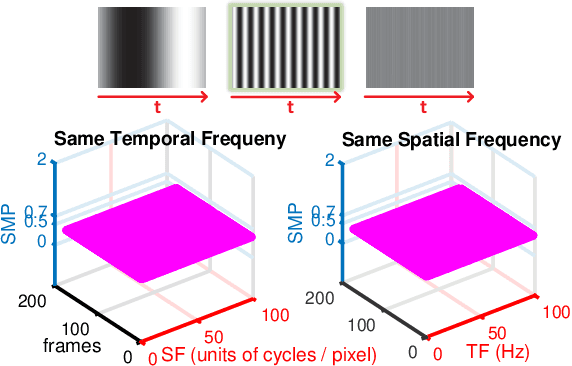
Insects use visual cues to control their flight behaviours. By estimating the angular velocity of the visual stimuli and regulating it to a constant value, honeybees can perform a terrain following task which keeps the certain height above the undulated ground. For mimicking this behaviour in a bio-plausible computation structure, this paper presents a new angular velocity decoding model based on the honeybee's behavioural experiments. The model consists of three parts, the texture estimation layer for spatial information extraction, the motion detection layer for temporal information extraction and the decoding layer combining information from pervious layers to estimate the angular velocity. Compared to previous methods on this field, the proposed model produces responses largely independent of the spatial frequency and contrast in grating experiments. The angular velocity based control scheme is proposed to implement the model into a bee simulated by the game engine Unity. The perfect terrain following above patterned ground and successfully flying over irregular textured terrain show its potential for micro unmanned aerial vehicles' terrain following.
A Visual Neural Network for Robust Collision Perception in Vehicle Driving Scenarios
Apr 03, 2019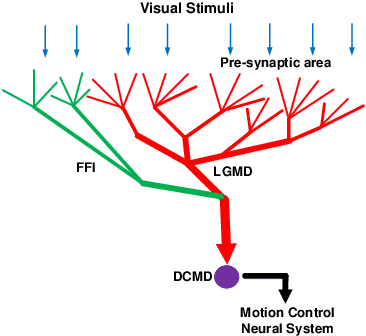
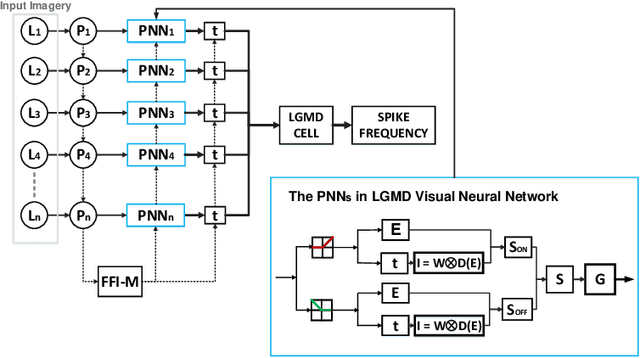
This research addresses the challenging problem of visual collision detection in very complex and dynamic real physical scenes, specifically, the vehicle driving scenarios. This research takes inspiration from a large-field looming sensitive neuron, i.e., the lobula giant movement detector (LGMD) in the locust's visual pathways, which represents high spike frequency to rapid approaching objects. Building upon our previous models, in this paper we propose a novel inhibition mechanism that is capable of adapting to different levels of background complexity. This adaptive mechanism works effectively to mediate the local inhibition strength and tune the temporal latency of local excitation reaching the LGMD neuron. As a result, the proposed model is effective to extract colliding cues from complex dynamic visual scenes. We tested the proposed method using a range of stimuli including simulated movements in grating backgrounds and shifting of a natural panoramic scene, as well as vehicle crash video sequences. The experimental results demonstrate the proposed method is feasible for fast collision perception in real-world situations with potential applications in future autonomous vehicles.
Towards Computational Models and Applications of Insect Visual Systems for Motion Perception: A Review
Apr 03, 2019Motion perception is a critical capability determining a variety of aspects of insects' life, including avoiding predators, foraging and so forth. A good number of motion detectors have been identified in the insects' visual pathways. Computational modelling of these motion detectors has not only been providing effective solutions to artificial intelligence, but also benefiting the understanding of complicated biological visual systems. These biological mechanisms through millions of years of evolutionary development will have formed solid modules for constructing dynamic vision systems for future intelligent machines. This article reviews the computational motion perception models originating from biological research of insects' visual systems in the literature. These motion perception models or neural networks comprise the looming sensitive neuronal models of lobula giant movement detectors (LGMDs) in locusts, the translation sensitive neural systems of direction selective neurons (DSNs) in fruit flies, bees and locusts, as well as the small target motion detectors (STMDs) in dragonflies and hover flies. We also review the applications of these models to robots and vehicles. Through these modelling studies, we summarise the methodologies that generate different direction and size selectivity in motion perception. At last, we discuss about multiple systems integration and hardware realisation of these bio-inspired motion perception models.
Visual Cue Integration for Small Target Motion Detection in Natural Cluttered Backgrounds
Mar 18, 2019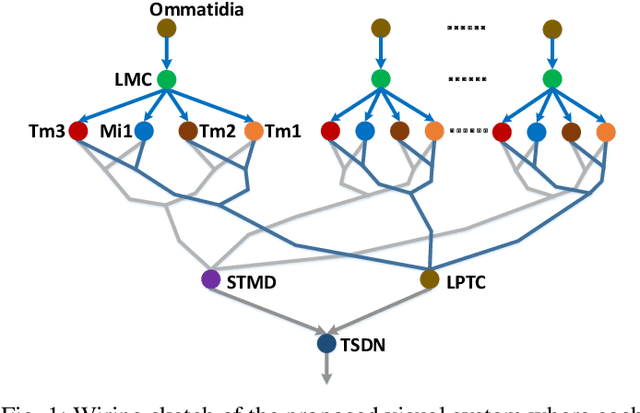
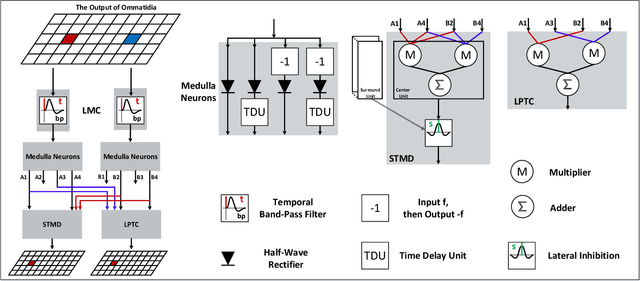
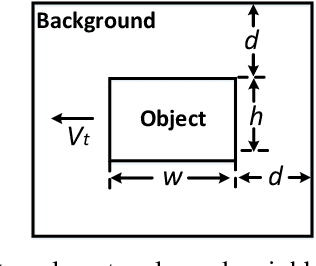
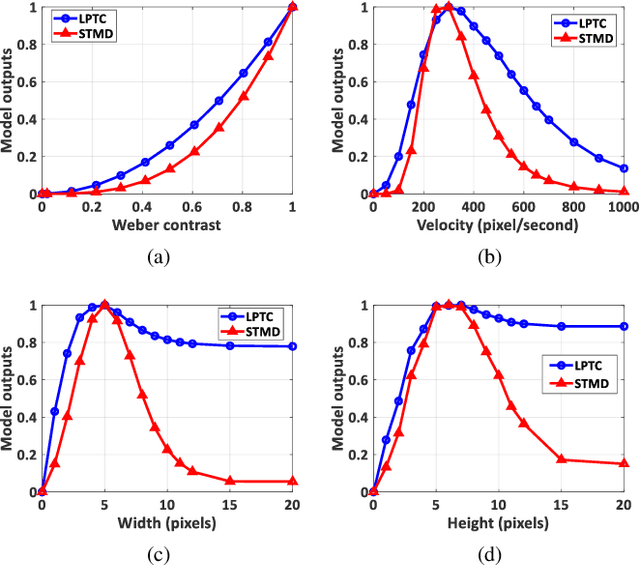
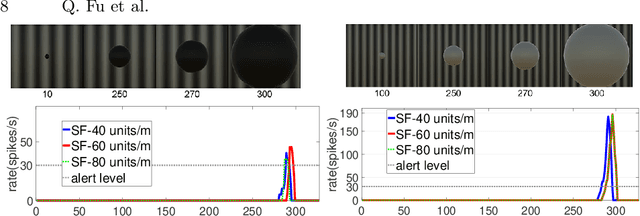
The robust detection of small targets against cluttered background is important for future artificial visual systems in searching and tracking applications. The insects' visual systems have demonstrated excellent ability to avoid predators, find prey or identify conspecifics - which always appear as small dim speckles in the visual field. Build a computational model of the insects' visual pathways could provide effective solutions to detect small moving targets. Although a few visual system models have been proposed, they only make use of small-field visual features for motion detection and their detection results often contain a number of false positives. To address this issue, we develop a new visual system model for small target motion detection against cluttered moving backgrounds. Compared to the existing models, the small-field and wide-field visual features are separately extracted by two motion-sensitive neurons to detect small target motion and background motion. These two types of motion information are further integrated to filter out false positives. Extensive experiments showed that the proposed model can outperform the existing models in terms of detection rates.
A Directionally Selective Small Target Motion Detecting Visual Neural Network in Cluttered Backgrounds
Sep 29, 2018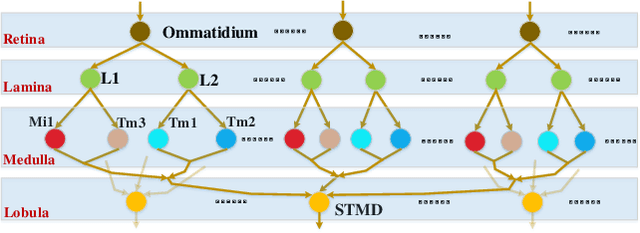
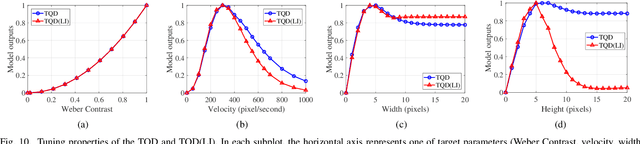
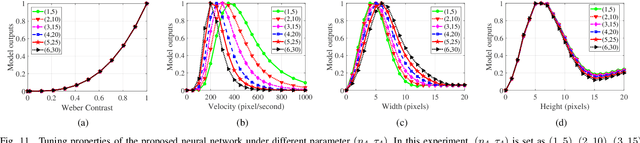
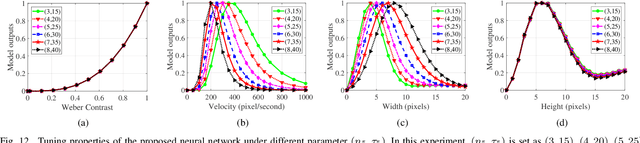
Discriminating targets moving against a cluttered background is a huge challenge, let alone detecting a target as small as one or a few pixels and tracking it in flight. In the fly's visual system, a class of specific neurons, called small target motion detectors (STMDs), have been identified as showing exquisite selectivity for small target motion. Some of the STMDs have also demonstrated directional selectivity which means these STMDs respond strongly only to their preferred motion direction. Directional selectivity is an important property of these STMD neurons which could contribute to tracking small targets such as mates in flight. However, little has been done on systematically modeling these directional selective STMD neurons. In this paper, we propose a directional selective STMD-based neural network (DSTMD) for small target detection in a cluttered background. In the proposed neural network, a new correlation mechanism is introduced for direction selectivity via correlating signals relayed from two pixels. Then, a lateral inhibition mechanism is implemented on the spatial field for size selectivity of STMD neurons. Extensive experiments showed that the proposed neural network not only is in accord with current biological findings, i.e. showing directional preferences, but also worked reliably in detecting small targets against cluttered backgrounds.