 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contrastive Learning for Sports Video: Unsupervised Player Classification
Apr 15, 2021

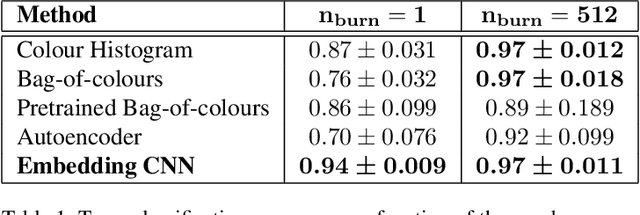

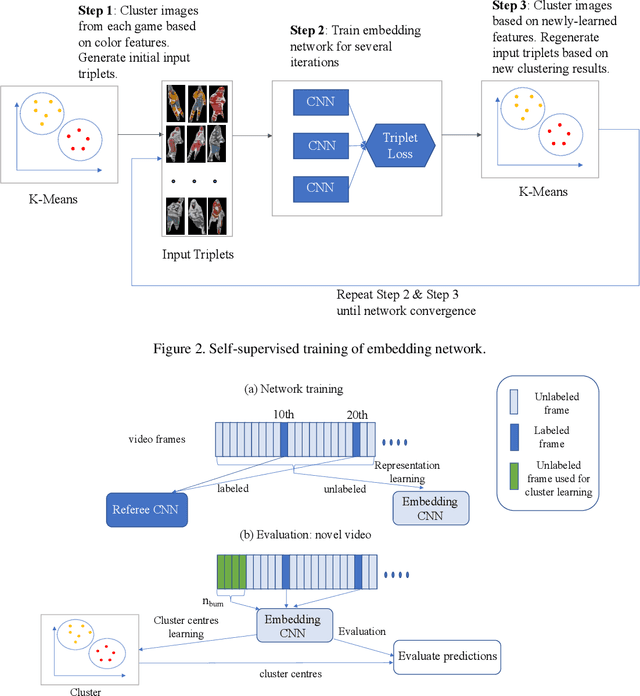
We address the problem of unsupervised classification of players in a team sport according to their team affiliation, when jersey colours and design are not known a priori. We adopt a contrastive learning approach in which an embedding network learns to maximize the distance between representations of players on different teams relative to players on the same team, in a purely unsupervised fashion, without any labelled data. We evaluate the approach using a new hockey dataset and find that it outperforms prior unsupervised approaches by a substantial margin, particularly for real-time application when only a small number of frames are available for unsupervised learning before team assignments must be made. Remarkably, we show that our contrastive method achieves 94% accuracy after unsupervised training on only a single frame, with accuracy rising to 97% within 500 frames (17 seconds of game time). We further demonstrate how accurate team classification allows accurate team-conditional heat maps of player positioning to be computed.
From Single to Multiple: Leveraging Multi-level Prediction Spaces for Video Forecasting
Jul 21, 2021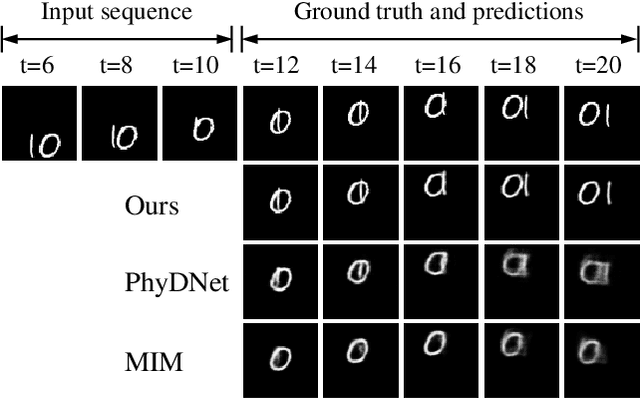
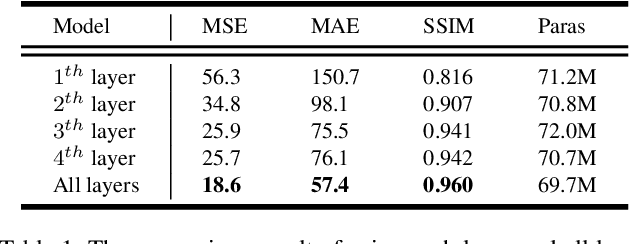
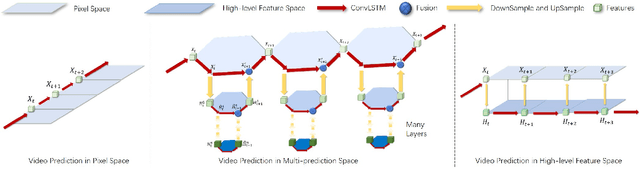
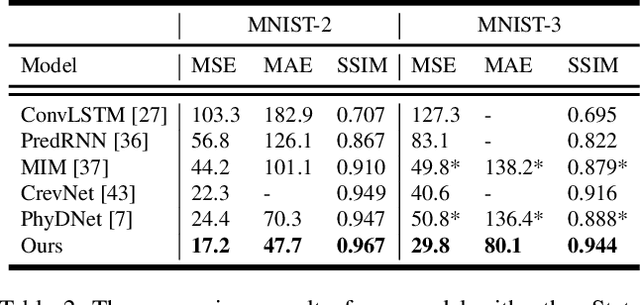
Despite video forecasting has been a widely explored topic in recent years, the mainstream of the existing work still limits their models with a single prediction space but completely neglects the way to leverage their model with multi-prediction spaces. This work fills this gap. For the first time, we deeply study numerous strategies to perform video forecasting in multi-prediction spaces and fuse their results together to boost performance. The prediction in the pixel space usually lacks the ability to preserve the semantic and structure content of the video however the prediction in the high-level feature space is prone to generate errors in the reduction and recovering process. Therefore, we build a recurrent connection between different feature spaces and incorporate their generations in the upsampling process. Rather surprisingly, this simple idea yields a much more significant performance boost than PhyDNet (performance improved by 32.1% MAE on MNIST-2 dataset, and 21.4% MAE on KTH dataset). Both qualitative and quantitative evaluations on four datasets demonstrate the generalization ability and effectiveness of our approach. We show that our model significantly reduces the troublesome distortions and blurry artifacts and brings remarkable improvements to the accuracy in long term video prediction. The code will be released soon.
Multi-modal Residual Perceptron Network for Audio-Video Emotion Recognition
Jul 21, 2021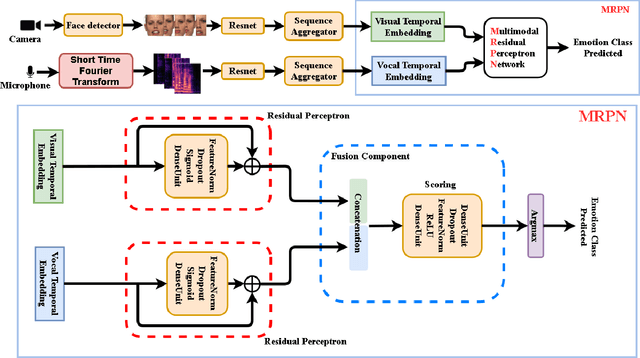
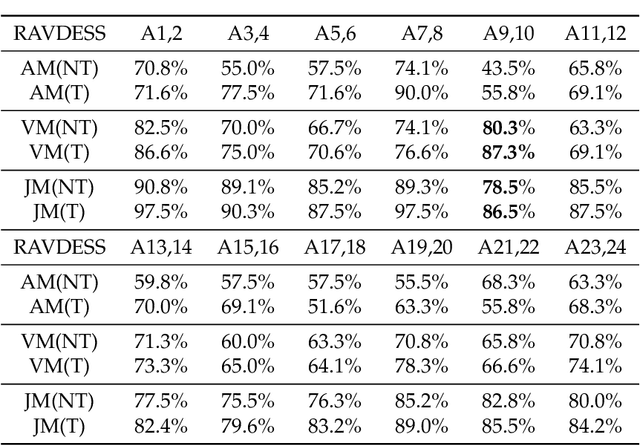

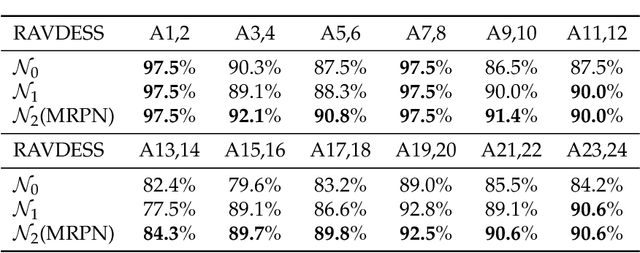
Emotion recognition is an important research field for Human-Computer Interaction(HCI). Audio-Video Emotion Recognition (AVER) is now attacked with Deep Neural Network (DNN) modeling tools. In published papers, as a rule, the authors show only cases of the superiority of multi modalities over audio-only or video-only modalities. However, there are cases superiority in single modality can be found. In our research, we hypothesize that for fuzzy categories of emotional events, the higher noise of one modality can amplify the lower noise of the second modality represented indirectly in the parameters of the modeling neural network. To avoid such cross-modal information interference we define a multi-modal Residual Perceptron Network (MRPN) which learns from multi-modal network branches creating deep feature representation with reduced noise. For the proposed MRPN model and the novel time augmentation for streamed digital movies, the state-of-art average recognition rate was improved to 91.4% for The Ryerson Audio-Visual Database of Emotional Speech and Song(RAVDESS) dataset and to 83.15% for Crowd-sourced Emotional multi-modal Actors Dataset(Crema-d). Moreover, the MRPN concept shows its potential for multi-modal classifiers dealing with signal sources not only of optical and acoustical type.
Informed Machine Learning for Improved Similarity Assessment in Process-Oriented Case-Based Reasoning
Jun 30, 2021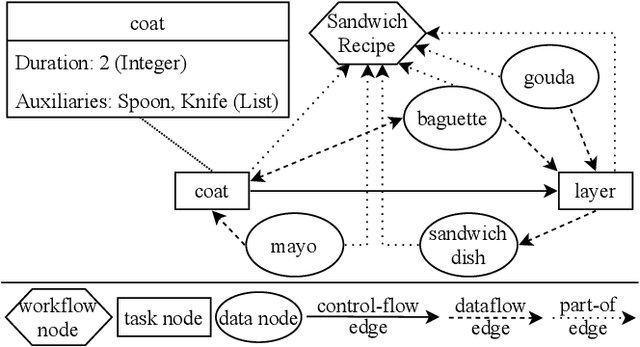

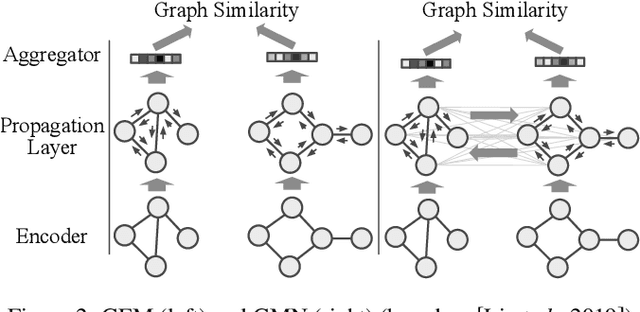
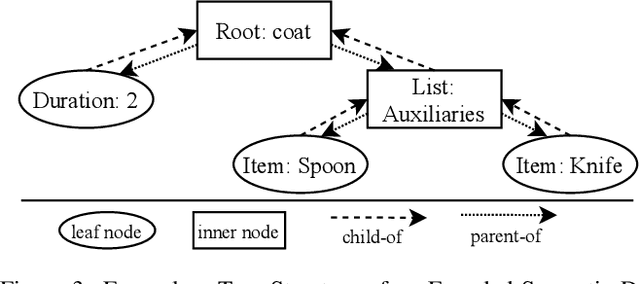
Currently, Deep Learning (DL) components within a Case-Based Reasoning (CBR) application often lack the comprehensive integration of available domain knowledge. The trend within machine learning towards so-called Informed machine learning can help to overcome this limitation. In this paper, we therefore investigate the potential of integrating domain knowledge into Graph Neural Networks (GNNs) that are used for similarity assessment between semantic graphs within process-oriented CBR applications. We integrate knowledge in two ways: First, a special data representation and processing method is used that encodes structural knowledge about the semantic annotations of each graph node and edge. Second, the message-passing component of the GNNs is constrained by knowledge on legal node mappings. The evaluation examines the quality and training time of the extended GNNs, compared to the stock models. The results show that both extensions are capable of providing better quality, shorter training times, or in some configurations both advantages at once.
Wavelet-Packet Powered Deepfake Image Detection
Jun 17, 2021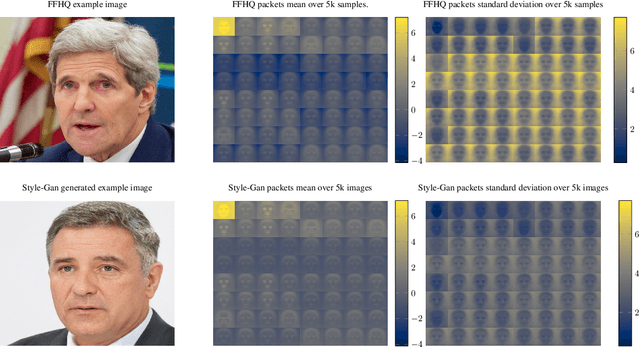
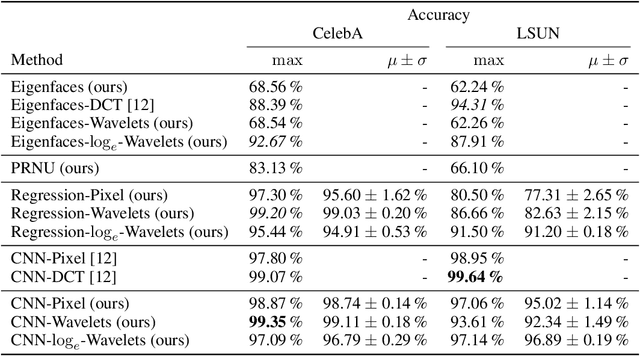
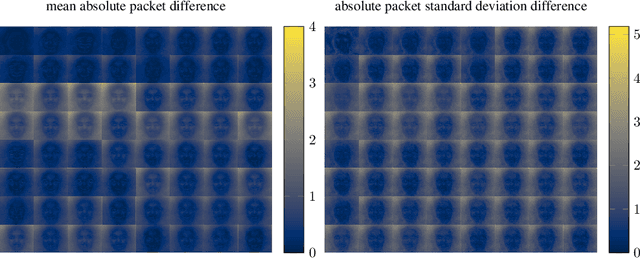
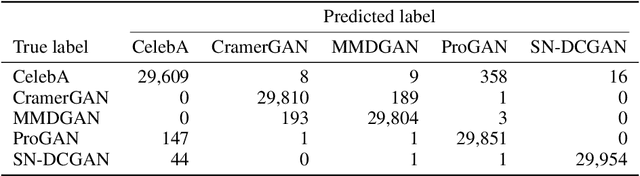
As neural networks become more able to generate realistic artificial images, they have the potential to improve movies, music, video games and make the internet an even more creative and inspiring place. Yet, at the same time, the latest technology potentially enables new digital ways to lie. In response, the need for a diverse and reliable toolbox arises to identify artificial images and other content. Previous work primarily relies on pixel-space CNN or the Fourier transform. To the best of our knowledge, wavelet-based gan analysis and detection methods have been absent thus far. This paper aims to fill this gap and describes a wavelet-based approach to gan-generated image analysis and detection. We evaluate our method on FFHQ, CelebA, and LSUN source identification problems and find improved or competitive performance.
RepVGG: Making VGG-style ConvNets Great Again
Jan 11, 2021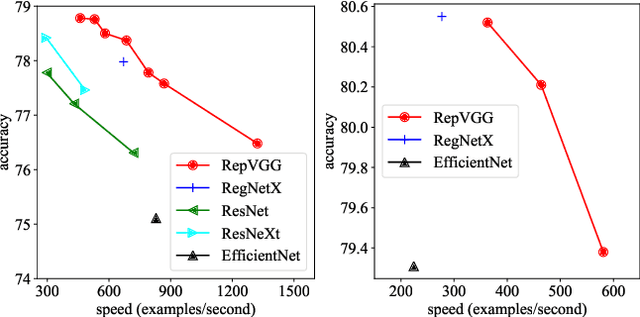
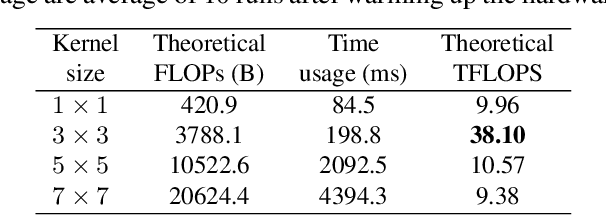
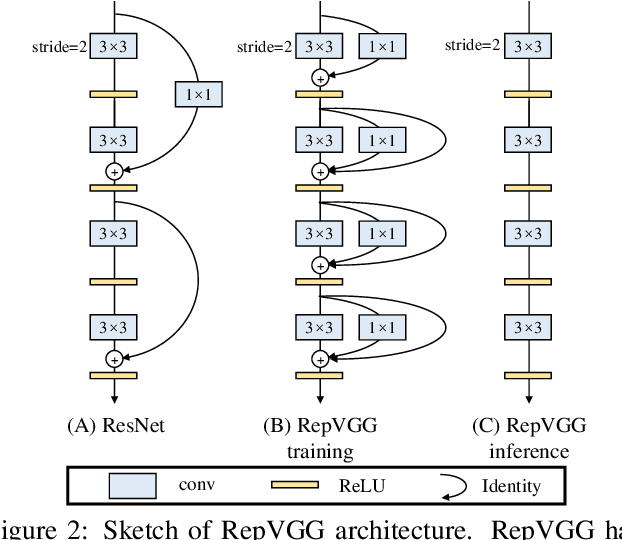

We present a simple but powerful architecture of convolutional neural network, which has a VGG-like inference-time body composed of nothing but a stack of 3x3 convolution and ReLU, while the training-time model has a multi-branch topology. Such decoupling of the training-time and inference-time architecture is realized by a structural re-parameterization technique so that the model is named RepVGG. On ImageNet, RepVGG reaches over 80\% top-1 accuracy, which is the first time for a plain model, to the best of our knowledge. On NVIDIA 1080Ti GPU, RepVGG models run 83% faster than ResNet-50 or 101% faster than ResNet-101 with higher accuracy and show favorable accuracy-speed trade-off compared to the state-of-the-art models like EfficientNet and RegNet. The code and trained models are available at https://github.com/megvii-model/RepVGG.
Learn Like The Pro: Norms from Theory to Size Neural Computation
Jun 21, 2021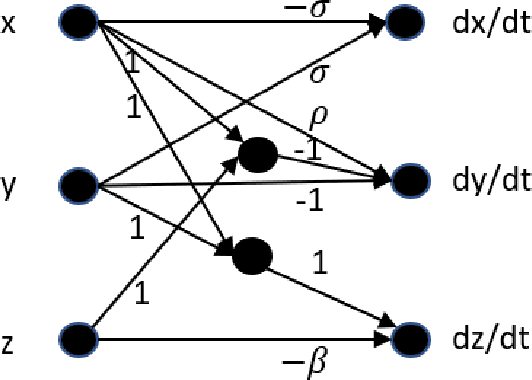
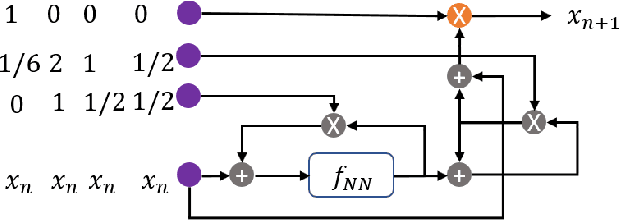
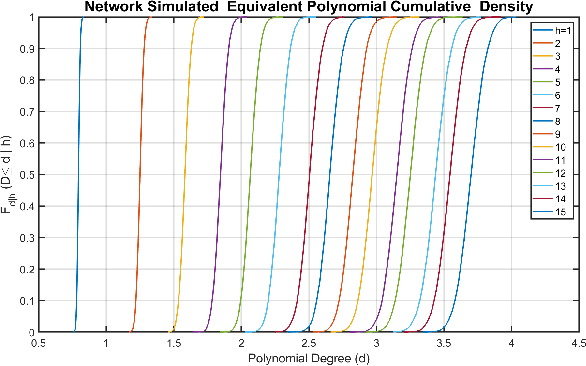
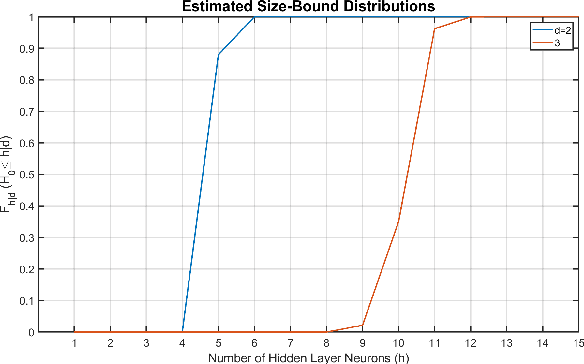
The optimal design of neural networks is a critical problem in many applications. Here, we investigate how dynamical systems with polynomial nonlinearities can inform the design of neural systems that seek to emulate them. We propose a Learnability metric and its associated features to quantify the near-equilibrium behavior of learning dynamics. Equating the Learnability of neural systems with equivalent parameter estimation metric of the reference system establishes bounds on network structure. In this way, norms from theory provide a good first guess for neural structure, which may then further adapt with data. The proposed approach neither requires training nor training data. It reveals exact sizing for a class of neural networks with multiplicative nodes that mimic continuous- or discrete-time polynomial dynamics. It also provides relatively tight lower size bounds for classical feed-forward networks that is consistent with simulated assessments.
Generating Cyber Threat Intelligence to Discover Potential Security Threats Using Classification and Topic Modeling
Aug 16, 2021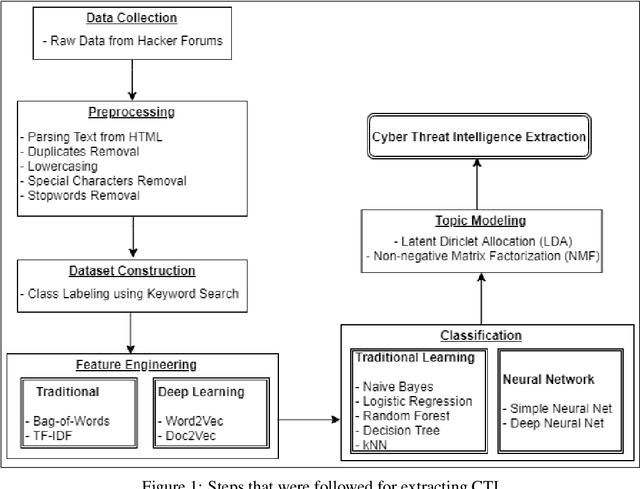

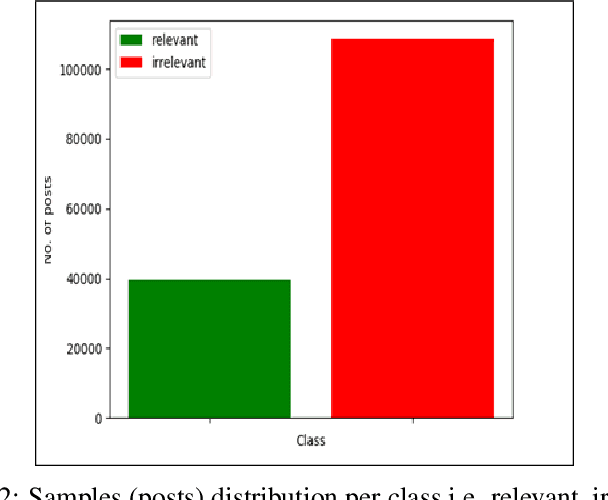

Due to the variety of cyber-attacks or threats, the cybersecurity community has been enhancing the traditional security control mechanisms to an advanced level so that automated tools can encounter potential security threats. Very recently a term, Cyber Threat Intelligence (CTI) has been represented as one of the proactive and robust mechanisms because of its automated cybersecurity threat prediction based on data. In general, CTI collects and analyses data from various sources e.g. online security forums, social media where cyber enthusiasts, analysts, even cybercriminals discuss cyber or computer security related topics and discovers potential threats based on the analysis. As the manual analysis of every such discussion i.e. posts on online platforms is time-consuming, inefficient, and susceptible to errors, CTI as an automated tool can perform uniquely to detect cyber threats. In this paper, our goal is to identify and explore relevant CTI from hacker forums by using different supervised and unsupervised learning techniques. To this end, we collect data from a real hacker forum and constructed two datasets: a binary dataset and a multi-class dataset. Our binary dataset contains two classes one containing cybersecurity-relevant posts and another one containing posts that are not related to security. This dataset is constructed using simple keyword search technique. Using a similar approach, we further categorize posts from security-relevant posts into five different threat categories. We then applied several machine learning classifiers along with deep neural network-based classifiers and use them on the datasets to compare their performances. We also tested the classifiers on a leaked dataset with labels named nulled.io as our ground truth. We further explore the datasets using unsupervised techniques i.e. Latent Dirichlet Allocation (LDA) and Non-negative Matrix Factorization (NMF).
Model-free Reinforcement Learning for Branching Markov Decision Processes
Jun 12, 2021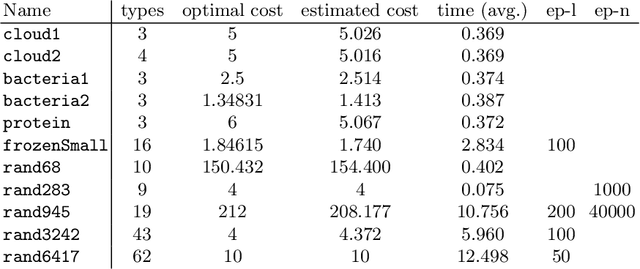
We study reinforcement learning for the optimal control of Branching Markov Decision Processes (BMDPs), a natural extension of (multitype) Branching Markov Chains (BMCs). The state of a (discrete-time) BMCs is a collection of entities of various types that, while spawning other entities, generate a payoff. In comparison with BMCs, where the evolution of a each entity of the same type follows the same probabilistic pattern, BMDPs allow an external controller to pick from a range of options. This permits us to study the best/worst behaviour of the system. We generalise model-free reinforcement learning techniques to compute an optimal control strategy of an unknown BMDP in the limit. We present results of an implementation that demonstrate the practicality of the approach.
Field trial on Ocean Estimation for Multi-Vessel Multi-Float-based Active perception
Jun 17, 2021
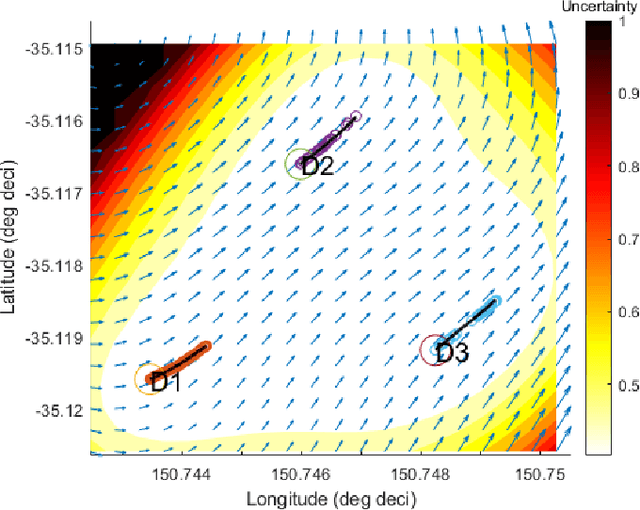
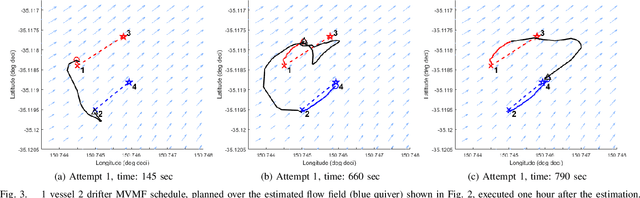
Marine vehicles have been used for various scientific missions where information over features of interest is collected. In order to maximise efficiency in collecting information over a large search space, we should be able to deploy a large number of autonomous vehicles that make a decision based on the latest understanding of the target feature in the environment. In our previous work, we have presented a hierarchical framework for the multi-vessel multi-float (MVMF) problem where surface vessels drop and pick up underactuated floats in a time-minimal way. In this paper, we present the field trial results using the framework with a number of drifters and floats. We discovered a number of important aspects that need to be considered in the proposed framework, and present the potential approaches to address the challenges.