 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards long-term player tracking with graph hierarchies and domain-specific features
Feb 28, 2025In team sports analytics, long-term player tracking remains a challenging task due to player appearance similarity, occlusion, and dynamic motion patterns. Accurately re-identifying players and reconnecting tracklets after extended absences from the field of view or prolonged occlusions is crucial for robust analysis. We introduce SportsSUSHI, a hierarchical graph-based approach that leverages domain-specific features, including jersey numbers, team IDs, and field coordinates, to enhance tracking accuracy. SportsSUSHI achieves high performance on the SoccerNet dataset and a newly proposed hockey tracking dataset. Our hockey dataset, recorded using a stationary camera capturing the entire playing surface, contains long sequences and annotations for team IDs and jersey numbers, making it well-suited for evaluating long-term tracking capabilities. The inclusion of domain-specific features in our approach significantly improves association accuracy, as demonstrated in our experiments. The dataset and code are available at https://github.com/mkoshkina/sports-SUSHI.
A General Framework for Jersey Number Recognition in Sports Video
May 22, 2024



Jersey number recognition is an important task in sports video analysis, partly due to its importance for long-term player tracking. It can be viewed as a variant of scene text recognition. However, there is a lack of published attempts to apply scene text recognition models on jersey number data. Here we introduce a novel public jersey number recognition dataset for hockey and study how scene text recognition methods can be adapted to this problem. We address issues of occlusions and assess the degree to which training on one sport (hockey) can be generalized to another (soccer). For the latter, we also consider how jersey number recognition at the single-image level can be aggregated across frames to yield tracklet-level jersey number labels. We demonstrate high performance on image- and tracklet-level tasks, achieving 91.4% accuracy for hockey images and 87.4% for soccer tracklets. Code, models, and data are available at https://github.com/mkoshkina/jersey-number-pipeline.
The Third Monocular Depth Estimation Challenge
Apr 27, 2024



This paper discusses the results of the third edition of the Monocular Depth Estimation Challenge (MDEC). The challenge focuses on zero-shot generalization to the challenging SYNS-Patches dataset, featuring complex scenes in natural and indoor settings. As with the previous edition, methods can use any form of supervision, i.e. supervised or self-supervised. The challenge received a total of 19 submissions outperforming the baseline on the test set: 10 among them submitted a report describing their approach, highlighting a diffused use of foundational models such as Depth Anything at the core of their method. The challenge winners drastically improved 3D F-Score performance, from 17.51% to 23.72%.
A Reliable Online Method for Joint Estimation of Focal Length and Camera Rotation
Jul 26, 2022
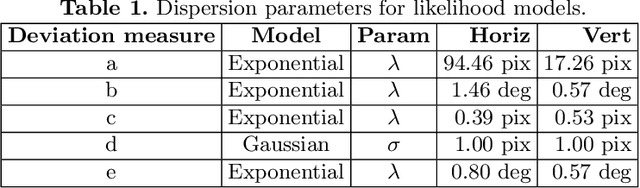

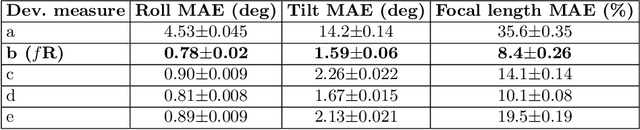
Linear perspectivecues deriving from regularities of the built environment can be used to recalibrate both intrinsic and extrinsic camera parameters online, but these estimates can be unreliable due to irregularities in the scene, uncertainties in line segment estimation and background clutter. Here we address this challenge through four initiatives. First, we use the PanoContext panoramic image dataset [27] to curate a novel and realistic dataset of planar projections over a broad range of scenes, focal lengths and camera poses. Second, we use this novel dataset and the YorkUrbanDB [4] to systematically evaluate the linear perspective deviation measures frequently found in the literature and show that the choice of deviation measure and likelihood model has a huge impact on reliability. Third, we use these findings to create a novel system for online camera calibration we call fR, and show that it outperforms the prior state of the art, substantially reducing error in estimated camera rotation and focal length. Our fourth contribution is a novel and efficient approach to estimating uncertainty that can dramatically improve online reliability for performance-critical applications by strategically selecting which frames to use for recalibration.
Contrastive Learning for Sports Video: Unsupervised Player Classification
May 03, 2021
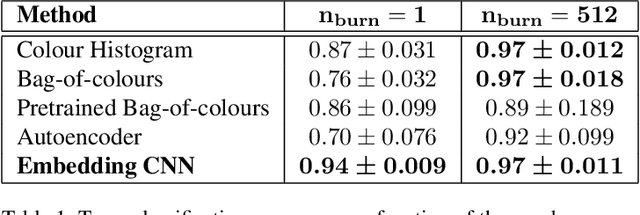

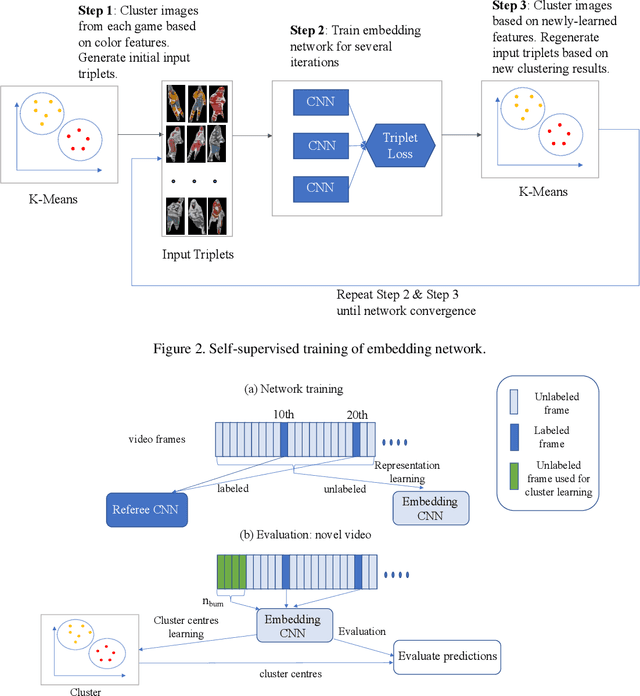
We address the problem of unsupervised classification of players in a team sport according to their team affiliation, when jersey colours and design are not known a priori. We adopt a contrastive learning approach in which an embedding network learns to maximize the distance between representations of players on different teams relative to players on the same team, in a purely unsupervised fashion, without any labelled data. We evaluate the approach using a new hockey dataset and find that it outperforms prior unsupervised approaches by a substantial margin, particularly for real-time application when only a small number of frames are available for unsupervised learning before team assignments must be made. Remarkably, we show that our contrastive method achieves 94% accuracy after unsupervised training on only a single frame, with accuracy rising to 97% within 500 frames (17 seconds of game time). We further demonstrate how accurate team classification allows accurate team-conditional heat maps of player positioning to be computed.
MCMLSD: A Probabilistic Algorithm and Evaluation Framework for Line Segment Detection
Jan 06, 2020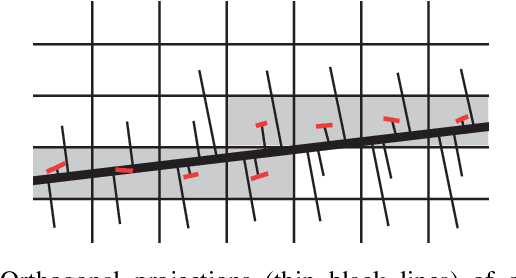
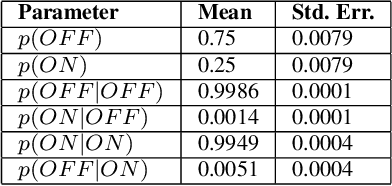
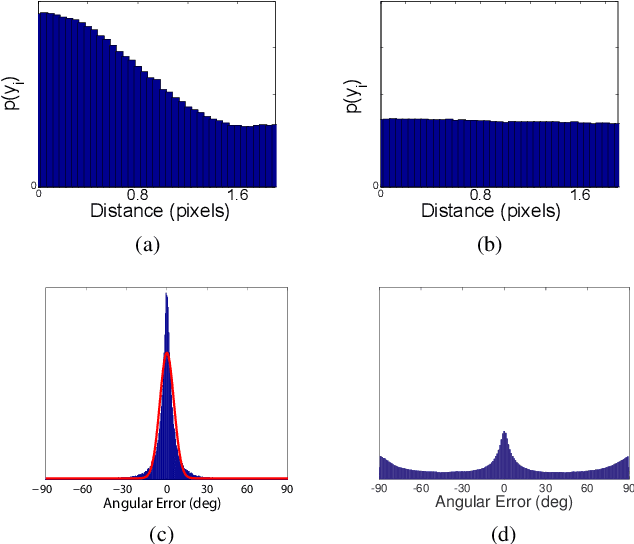
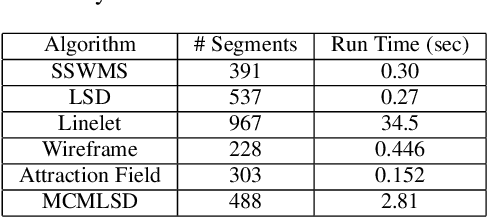
Traditional approaches to line segment detection typically involve perceptual grouping in the image domain and/or global accumulation in the Hough domain. Here we propose a probabilistic algorithm that merges the advantages of both approaches. In a first stage lines are detected using a global probabilistic Hough approach. In the second stage each detected line is analyzed in the image domain to localize the line segments that generated the peak in the Hough map. By limiting search to a line, the distribution of segments over the sequence of points on the line can be modeled as a Markov chain, and a probabilistically optimal labelling can be computed exactly using a standard dynamic programming algorithm, in linear time. The Markov assumption also leads to an intuitive ranking method that uses the local marginal posterior probabilities to estimate the expected number of correctly labelled points on a segment. To assess the resulting Markov Chain Marginal Line Segment Detector (MCMLSD) we develop and apply a novel quantitative evaluation methodology that controls for under- and over-segmentation. Evaluation on the YorkUrbanDB and Wireframe datasets shows that the proposed MCMLSD method outperforms prior traditional approaches, as well as more recent deep learning methods.
Class-Conditional Domain Adaptation on Semantic Segmentation
Nov 28, 2019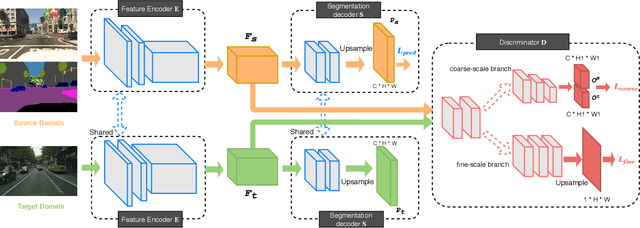
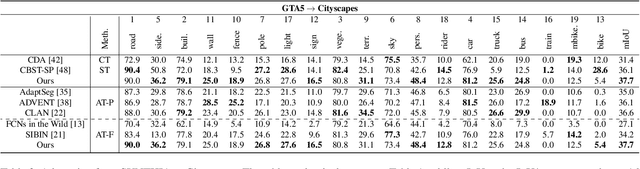
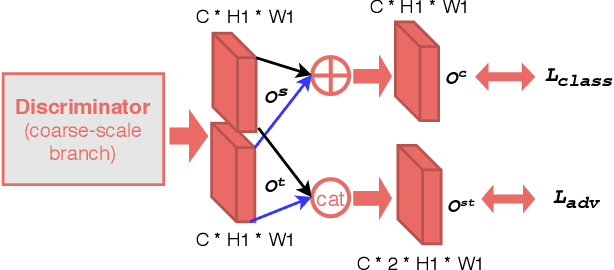
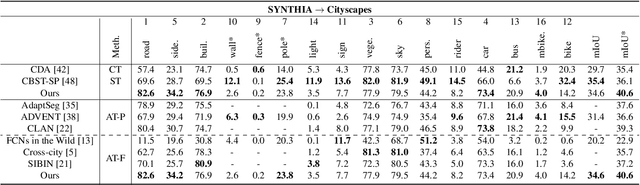
Semantic segmentation is an important sub-task for many applications, but pixel-level ground truth labeling is costly and there is a tendency to overfit the training data, limiting generalization. Unsupervised domain adaptation can potentially address these problems, allowing systems trained on labelled datasets from one or more source domains (including less expensive synthetic domains) to be adapted to novel target domains. The conventional approach is to automatically align the representational distributions of source and target domains. One limitation of this approach is that it tends to disadvantage lower probability classes. We address this problem by introducing a Class-Conditional Domain Adaptation method (CCDA). It includes a class-conditional multi-scale discriminator and the class-conditional loss. This novel CCDA method encourages the network to shift the domain in a class-conditional manner, and it equalizes loss over classes. We evaluate our CCDA method on two transfer tasks and demonstrate performance comparable to state-of-the-art methods.