 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal Residual Perceptron Network for Audio-Video Emotion Recognition
Paper and Code
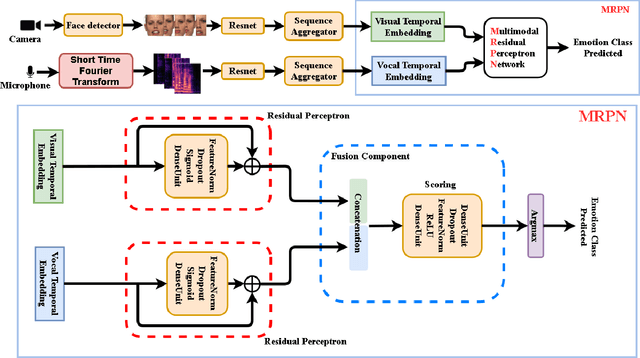
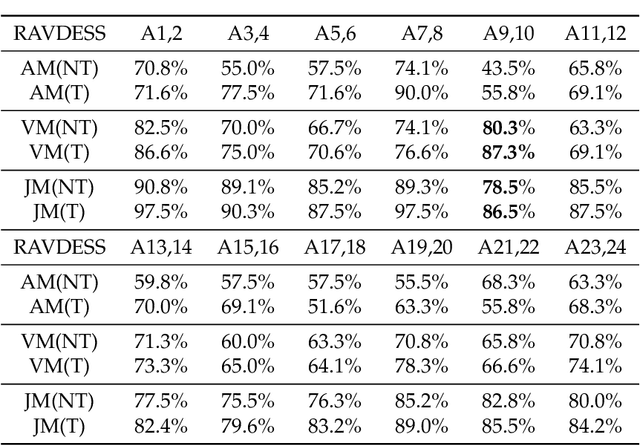

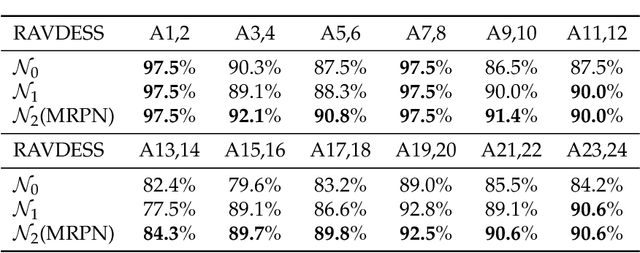
Audio-Video Emotion Recognition is now attacked with Deep Neural Network modeling tools. In published papers, as a rule, the authors show only cases of the superiority in multi-modality over audio-only or video-only modality. However, there are cases superiority in uni-modality can be found. In our research, we hypothesize that for fuzzy categories of emotional events, the within-modal and inter-modal noisy information represented indirectly in the parameters of the modeling neural network impedes better performance in the existing late fusion and end-to-end multi-modal network training strategies. To take advantage and overcome the deficiencies in both solutions, we define a Multi-modal Residual Perceptron Network which performs end-to-end learning from multi-modal network branches, generalizing better multi-modal feature representation. For the proposed Multi-modal Residual Perceptron Network and the novel time augmentation for streaming digital movies, the state-of-art average recognition rate was improved to 91.4% for The Ryerson Audio-Visual Database of Emotional Speech and Song dataset and to 83.15% for Crowd-sourced Emotional multi-modal Actors dataset. Moreover, the Multi-modal Residual Perceptron Network concept shows its potential for multi-modal applications dealing with signal sources not only of optical and acoustical types.