 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estimating Respiratory Rate From Breath Audio Obtained Through Wearable Microphones
Jul 28, 2021
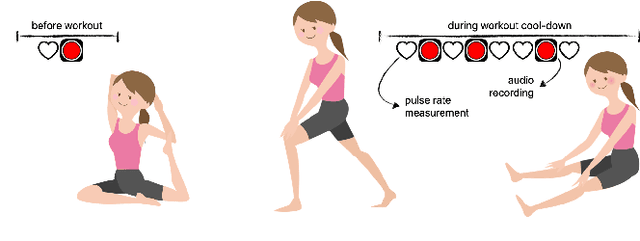
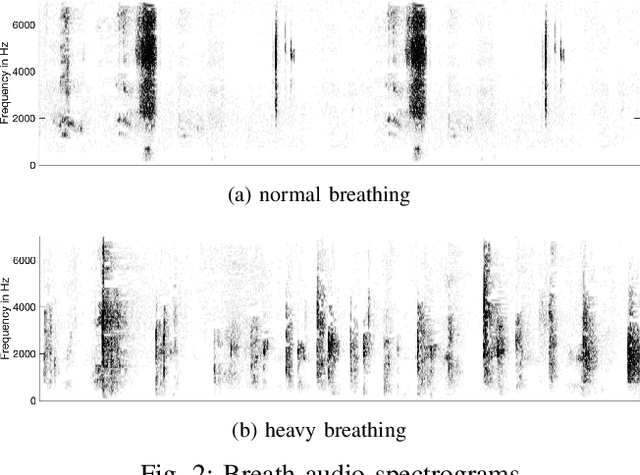
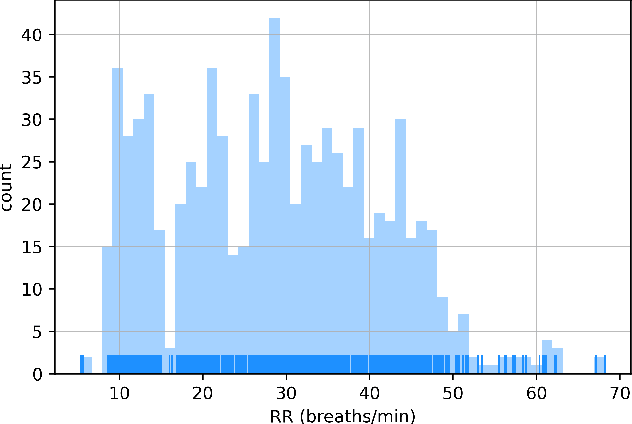
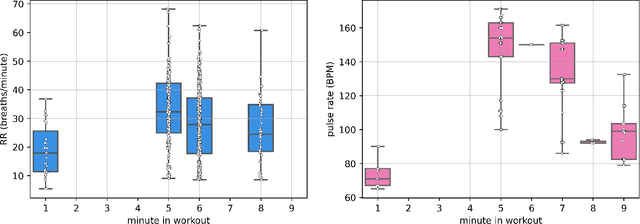
Respiratory rate (RR) is a clinical metric used to assess overall health and physical fitness. An individual's RR can change from their baseline due to chronic illness symptoms (e.g., asthma, congestive heart failure), acute illness (e.g., breathlessness due to infection), and over the course of the day due to physical exhaustion during heightened exertion. Remote estimation of RR can offer a cost-effective method to track disease progression and cardio-respiratory fitness over time. This work investigates a model-driven approach to estimate RR from short audio segments obtained after physical exertion in healthy adults. Data was collected from 21 individuals using microphone-enabled, near-field headphones before, during, and after strenuous exercise. RR was manually annotated by counting perceived inhalations and exhalations. A multi-task Long-Short Term Memory (LSTM) network with convolutional layers was implemented to process mel-filterbank energies, estimate RR in varying background noise conditions, and predict heavy breathing, indicated by an RR of more than 25 breaths per minute. The multi-task model performs both classification and regression tasks and leverages a mixture of loss functions. It was observed that RR can be estimated with a concordance correlation coefficient (CCC) of 0.76 and a mean squared error (MSE) of 0.2, demonstrating that audio can be a viable signal for approximating RR.
Deep Temporal-Recurrent-Replicated-Softmax for Topical Trends over Time
May 01, 2018

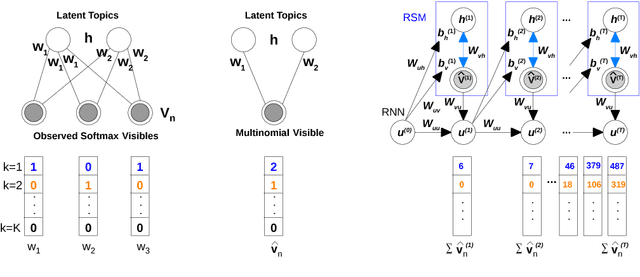
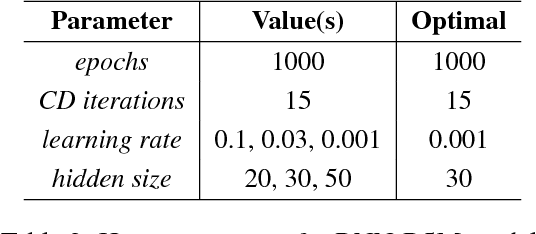
Dynamic topic modeling facilitates the identification of topical trends over time in temporal collections of unstructured documents. We introduce a novel unsupervised neural dynamic topic model named as Recurrent Neural Network-Replicated Softmax Model (RNNRSM), where the discovered topics at each time influence the topic discovery in the subsequent time steps. We account for the temporal ordering of documents by explicitly modeling a joint distribution of latent topical dependencies over time, using distributional estimators with temporal recurrent connections. Applying RNN-RSM to 19 years of articles on NLP research, we demonstrate that compared to state-of-the art topic models, RNNRSM shows better generalization, topic interpretation, evolution and trends. We also introduce a metric (named as SPAN) to quantify the capability of dynamic topic model to capture word evolution in topics over time.
TopicTracker: A Platform for Topic Trajectory Identification and Visualisation
Mar 02, 2021
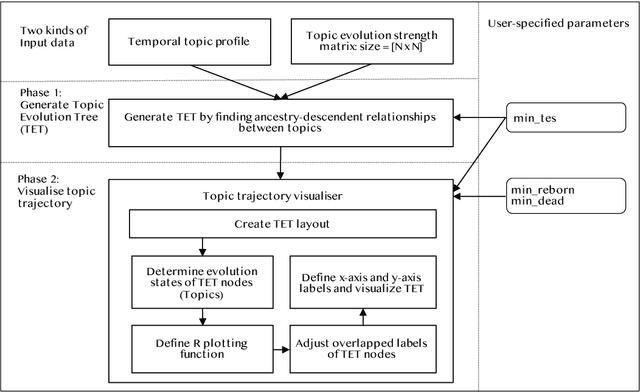
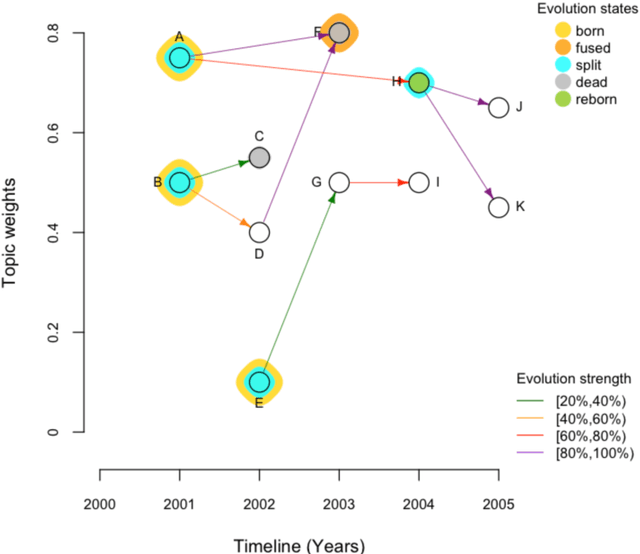
Topic trajectory information provides crucial insight into the dynamics of topics and their evolutionary relationships over a given time. Also, this information can help to improve our understanding on how new topics have emerged or formed through a sequential or interrelated events of emergence, modification and integration of prior topics. Nevertheless, the implementation of the existing methods for topic trajectory identification is rarely available as usable software. In this paper, we present TopicTracker, a platform for topic trajectory identification and visualisation. The key of Topic Tracker is that it can represent the three facets of information together, given two kinds of input: a time-stamped topic profile consisting of the set of the underlying topics over time, and the evolution strength matrix among them: evolutionary pathways of dynamic topics, evolution states of the topics, and topic importance. TopicTracker is a publicly available software implemented using the R software.
SCSS-Net: Superpoint Constrained Semi-supervised Segmentation Network for 3D Indoor Scenes
Jul 09, 2021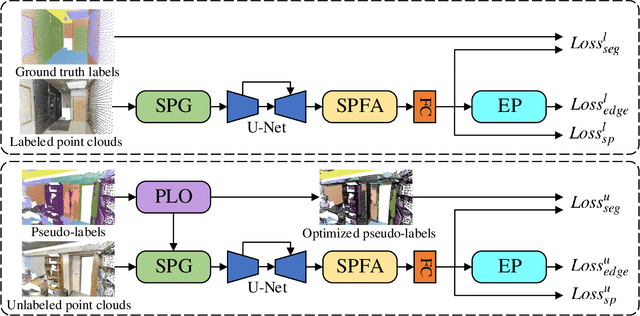

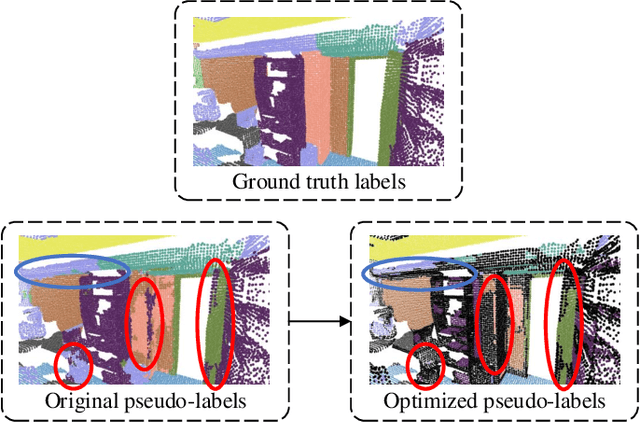

Many existing deep neural networks (DNNs) for 3D point cloud semantic segmentation require a large amount of fully labeled training data. However, manually assigning point-level labels on the complex scenes is time-consuming. While unlabeled point clouds can be easily obtained from sensors or reconstruction, we propose a superpoint constrained semi-supervised segmentation network for 3D point clouds, named as SCSS-Net. Specifically, we use the pseudo labels predicted from unlabeled point clouds for self-training, and the superpoints produced by geometry-based and color-based Region Growing algorithms are combined to modify and delete pseudo labels with low confidence. Additionally, we propose an edge prediction module to constrain the features from edge points of geometry and color. A superpoint feature aggregation module and superpoint feature consistency loss functions are introduced to smooth the point features in each superpoint. Extensive experimental results on two 3D public indoor datasets demonstrate that our method can achieve better performance than some state-of-the-art point cloud segmentation networks and some popular semi-supervised segmentation methods with few labeled scenes.
Goal-Conditioned Reinforcement Learning with Imagined Subgoals
Jul 01, 2021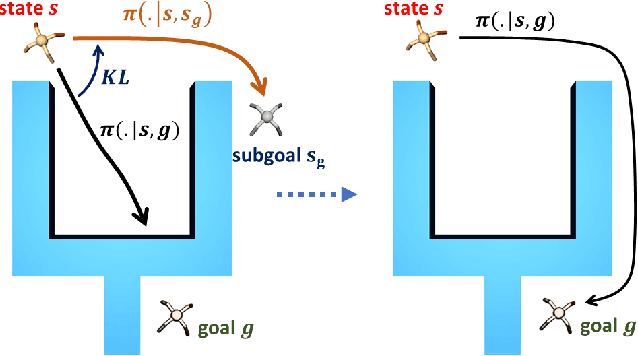
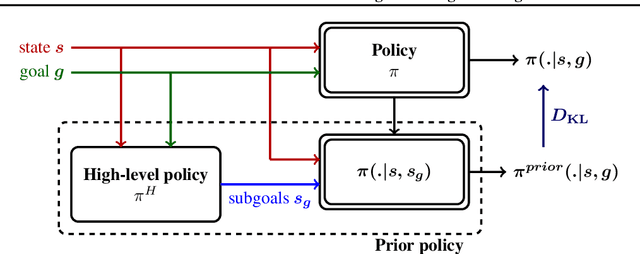

Goal-conditioned reinforcement learning endows an agent with a large variety of skills, but it often struggles to solve tasks that require more temporally extended reasoning. In this work, we propose to incorporate imagined subgoals into policy learning to facilitate learning of complex tasks. Imagined subgoals are predicted by a separate high-level policy, which is trained simultaneously with the policy and its critic. This high-level policy predicts intermediate states halfway to the goal using the value function as a reachability metric. We don't require the policy to reach these subgoals explicitly. Instead, we use them to define a prior policy, and incorporate this prior into a KL-constrained policy iteration scheme to speed up and regularize learning. Imagined subgoals are used during policy learning, but not during test time, where we only apply the learned policy. We evaluate our approach on complex robotic navigation and manipulation tasks and show that it outperforms existing methods by a large margin.
Waveform Design for Joint Sensing and Communications in the Terahertz Band
Jun 03, 2021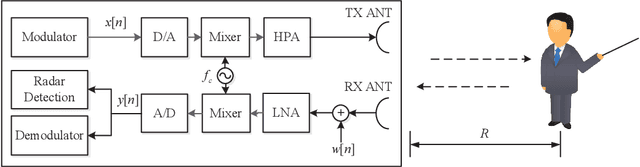
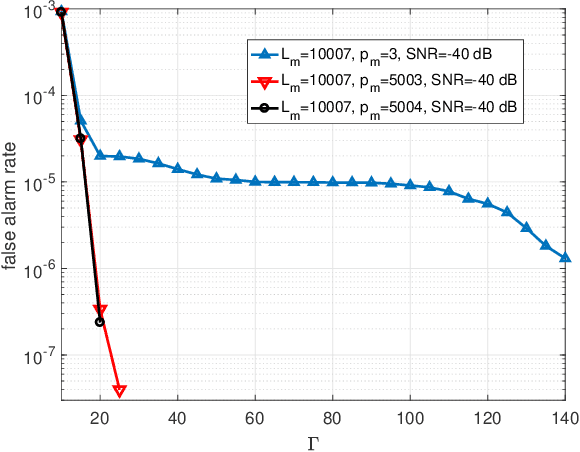
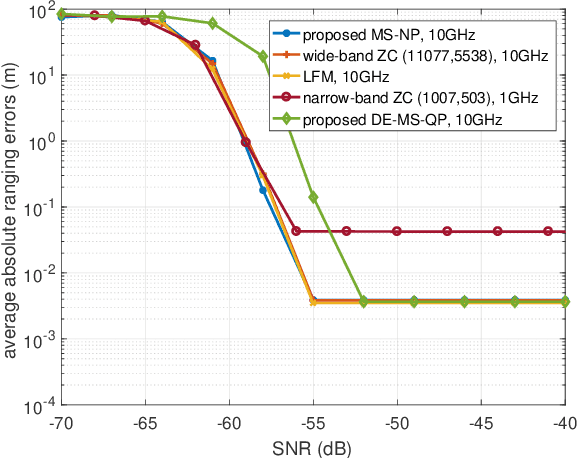
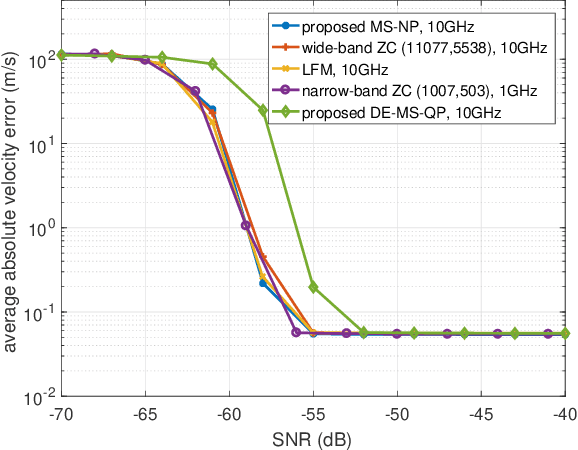
The convergence of radar sensing and communication applications in the terahertz (THz) band has been envisioned as a promising technology, since it incorporates terabit-per-second (Tbps) data transmission and mm-level radar sensing in a spectrum- and cost-efficient manner, by sharing both the frequency and hardware resources. However, the joint THz radar and communication (JRC) system faces considerable challenges, due to the peculiarities of the THz channel and front ends. To this end, the waveform design for THz-JRC systems with ultra-broad bandwidth is investigated in this paper. Firstly, by considering THz-JRC systems based on the co-existence concept, where both functions operate in a time-domain duplex (TDD) manner, a novel multi-subband quasi-perfect (MS-QP) sequence, composed of multiple Zadoff-Chu (ZC) perfect subsequences on different subbands, is proposed for target sensing, which achieves accurate target ranging and velocity estimation, whilst only requiring cost-efficient low-rate analog-to-digital converters (A/Ds) for sequence detection. Furthermore, the root index of each ZC subsequence of the MS-QP sequence is designed to eliminate the influence of doppler shift on the THz radar sensing. Finally, a data-embedded MS-QP (DE-MS-QP) waveform is constructed through time-domain extension of the MS-QP sequence, generating null frequency points on each subband for data transmission. Unlike the THz-JRC system in TDD manner, the proposed DE-MS-QP waveform enables simultaneous interference-free sensing and communication, whilst inheriting all the merits from MS-QP sequences. Numerical results validate the superiority of the proposed waveforms in terms of sensing performance, hardware cost and flexible resource allocation over their conventional counterparts.
PDL Impact on Linearly Coded Digital Phase Conjugation Techniques in CO-OFDM Systems
Jun 27, 2021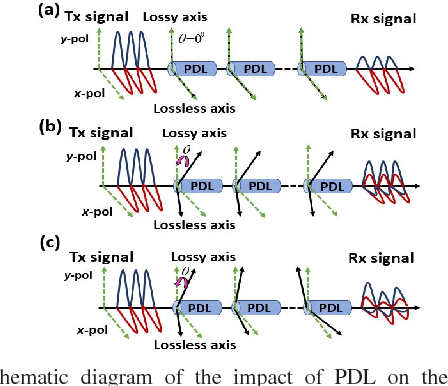
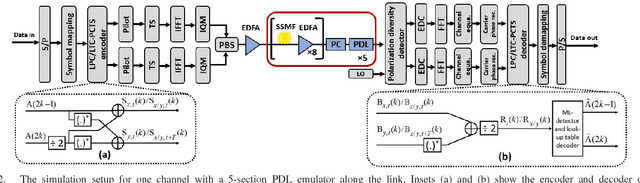
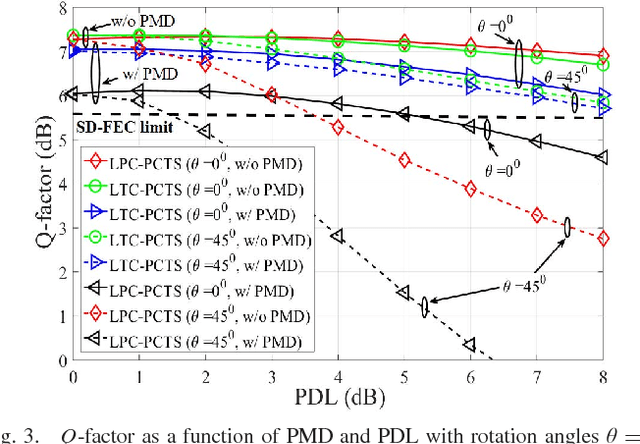
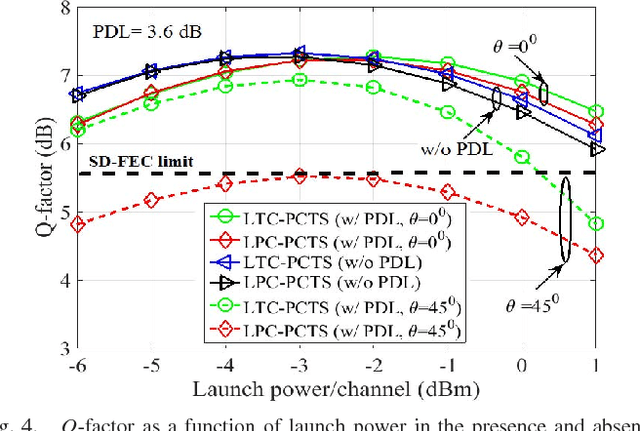
We investigate the impact of polarization-dependent loss (PDL) on the linearly coded digital phase conjugation (DPC) techniques in coherent optical orthogonal frequency division multiplexing (CO-OFDM) superchannel systems. We consider two DPC approaches: one uses orthogonal polarizations to transmit the linearly coded signal and its phase conjugate, while the other uses two orthogonal time slots of the same polarization. We compare the performances of these DPC approaches by considering both aligned- and statistical-PDL models. The investigation with aligned-PDL model indicates that the latter approach is more tolerant to PDL-induced distortions when compared to the former. Furthermore, the study using statistical-PDL model shows that the outage probability of the latter approach tends to zero at a root mean square PDL value of 3.6 dB. On the other hand, the former shows an outage probability of 0.63 for the same PDL value.
Predictive and Prescriptive Performance of Bike-Sharing Demand Forecasts for Inventory Management
Jul 28, 2021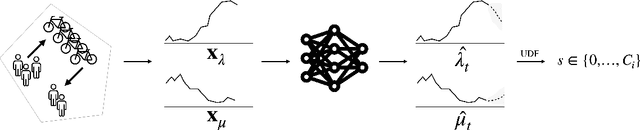
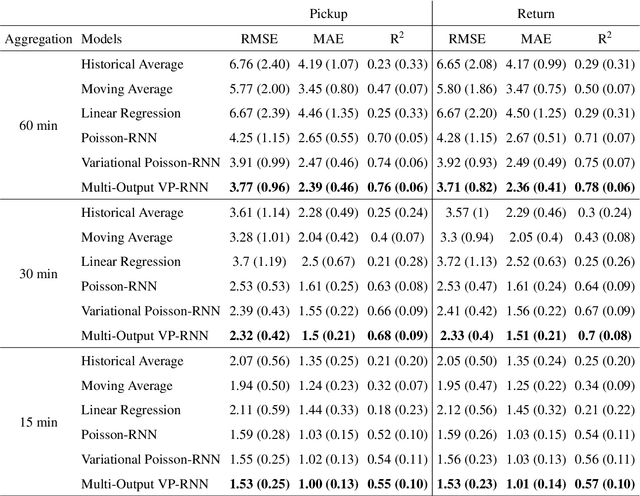
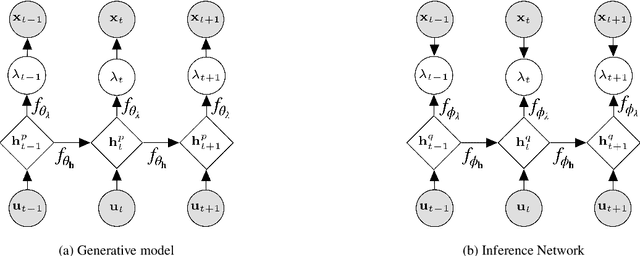

Bike-sharing systems are a rapidly developing mode of transportation and provide an efficient alternative to passive, motorized personal mobility. The asymmetric nature of bike demand causes the need for rebalancing bike stations, which is typically done during night time. To determine the optimal starting inventory level of a station for a given day, a User Dissatisfaction Function (UDF) models user pickups and returns as non-homogeneous Poisson processes with piece-wise linear rates. In this paper, we devise a deep generative model directly applicable in the UDF by introducing a variational Poisson recurrent neural network model (VP-RNN) to forecast future pickup and return rates. We empirically evaluate our approach against both traditional and learning-based forecasting methods on real trip travel data from the city of New York, USA, and show how our model outperforms benchmarks in terms of system efficiency and demand satisfaction. By explicitly focusing on the combination of decision-making algorithms with learning-based forecasting methods, we highlight a number of shortcomings in literature. Crucially, we show how more accurate predictions do not necessarily translate into better inventory decisions. By providing insights into the interplay between forecasts, model assumptions, and decisions, we point out that forecasts and decision models should be carefully evaluated and harmonized to optimally control shared mobility systems.
Leveraging Language to Learn Program Abstractions and Search Heuristics
Jun 18, 2021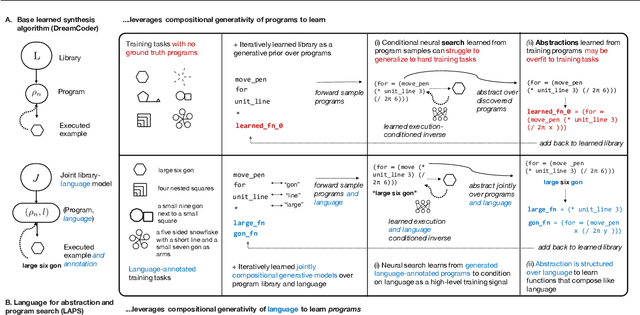
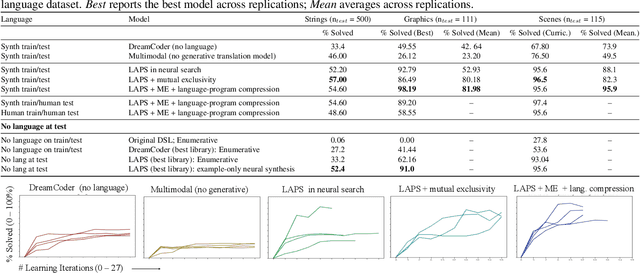


Inductive program synthesis, or inferring programs from examples of desired behavior, offers a general paradigm for building interpretable, robust, and generalizable machine learning systems. Effective program synthesis depends on two key ingredients: a strong library of functions from which to build programs, and an efficient search strategy for finding programs that solve a given task. We introduce LAPS (Language for Abstraction and Program Search), a technique for using natural language annotations to guide joint learning of libraries and neurally-guided search models for synthesis. When integrated into a state-of-the-art library learning system (DreamCoder), LAPS produces higher-quality libraries and improves search efficiency and generalization on three domains -- string editing, image composition, and abstract reasoning about scenes -- even when no natural language hints are available at test time.
A Physiologically-Adapted Gold Standard for Arousal during Stress
Jul 28, 2021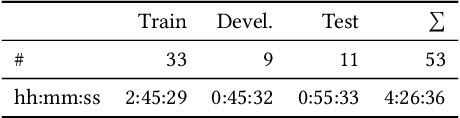
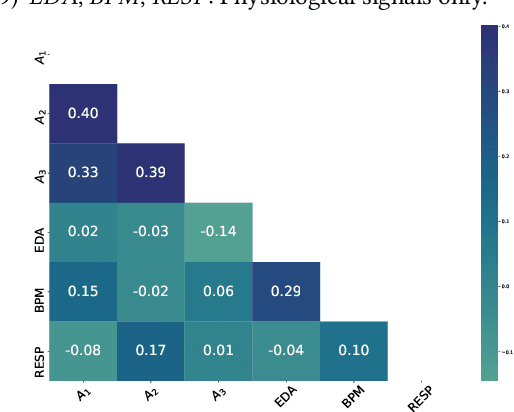
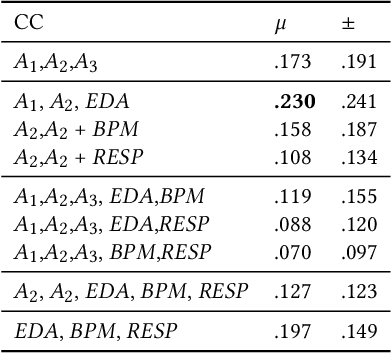
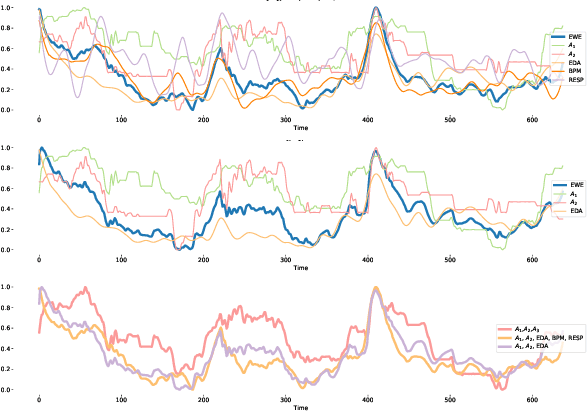
Emotion is an inherently subjective psychophysiological human-state and to produce an agreed-upon representation (gold standard) for continuous emotion requires a time-consuming and costly training procedure of multiple human annotators. There is strong evidence in the literature that physiological signals are sufficient objective markers for states of emotion, particularly arousal. In this contribution, we utilise a dataset which includes continuous emotion and physiological signals - Heartbeats per Minute (BPM), Electrodermal Activity (EDA), and Respiration-rate - captured during a stress inducing scenario (Trier Social Stress Test). We utilise a Long Short-Term Memory, Recurrent Neural Network to explore the benefit of fusing these physiological signals with arousal as the target, learning from various audio, video, and textual based features. We utilise the state-of-the-art MuSe-Toolbox to consider both annotation delay and inter-rater agreement weighting when fusing the target signals. An improvement in Concordance Correlation Coefficient (CCC) is seen across features sets when fusing EDA with arousal, compared to the arousal only gold standard results. Additionally, BERT-based textual features' results improved for arousal plus all physiological signals, obtaining up to .3344 CCC compared to .2118 CCC for arousal only. Multimodal fusion also improves overall CCC with audio plus video features obtaining up to .6157 CCC to recognize arousal plus EDA and BPM.