 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Affinity Mixup for Weakly Supervised Sound Event Detection
Jun 21, 2021
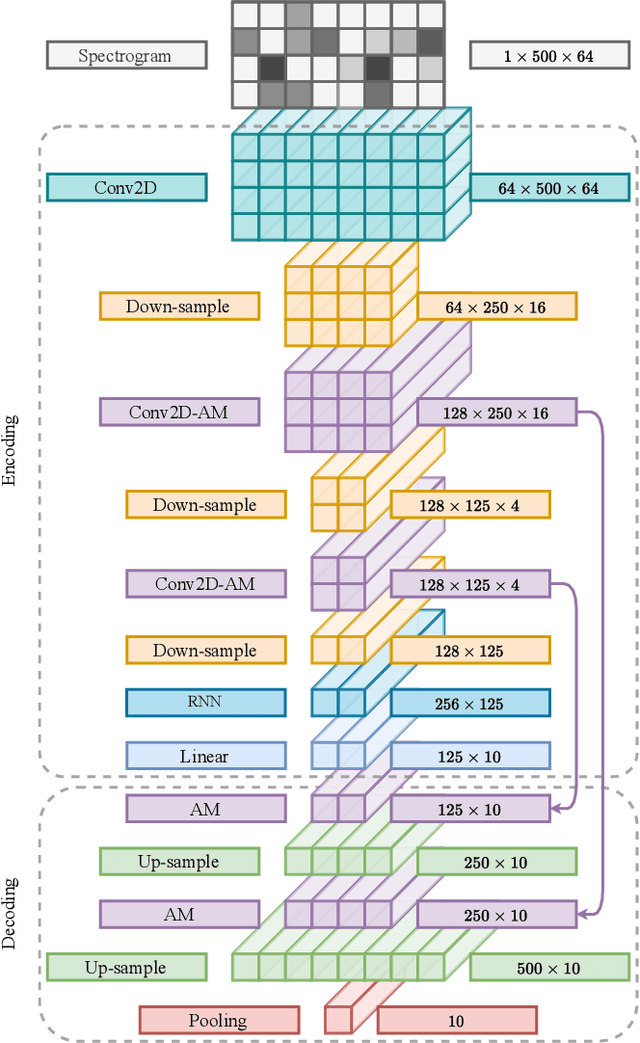
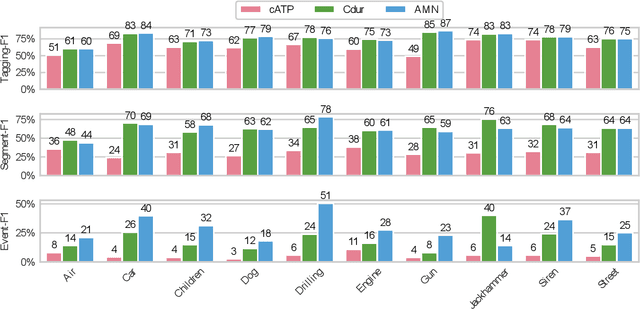
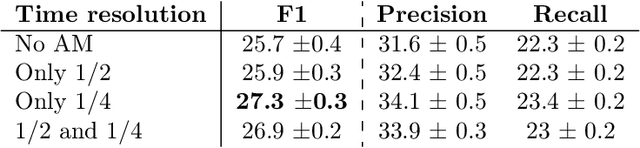
The weakly supervised sound event detection problem is the task of predicting the presence of sound events and their corresponding starting and ending points in a weakly labeled dataset. A weak dataset associates each training sample (a short recording) to one or more present sources. Networks that solely rely on convolutional and recurrent layers cannot directly relate multiple frames in a recording. Motivated by attention and graph neural networks, we introduce the concept of an affinity mixup to incorporate time-level similarities and make a connection between frames. This regularization technique mixes up features in different layers using an adaptive affinity matrix. Our proposed affinity mixup network improves over state-of-the-art techniques event-F1 scores by $8.2\%$.
Nonparametric posterior learning for emission tomography with multimodal data
Aug 03, 2021
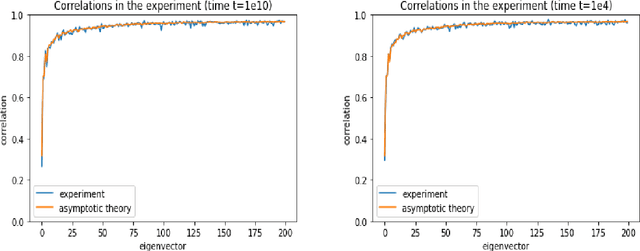
In this work we continue studies of the uncertainty quantification problem in emission tomographies such as PET or SPECT. In particular, we consider a scenario when additional multimodal data (e.g., anatomical MRI images) are available. To solve the aforementioned problem we adapt the recently proposed nonparametric posterior learning technique to the context of Poisson-type data in emission tomography. Using this approach we derive sampling algorithms which are trivially parallelizable, scalable and very easy to implement. In addition, we prove conditional consistency and tightness for the distribution of produced samples in the small noise limit (i.e., when the acquisition time tends to infinity) and derive new geometrical and necessary condition on how MRI images must be used. This condition arises naturally in the context of misspecified generalized Poisson models. We also contrast our approach with bayesian MCMC sampling based one one data augmentation scheme which is very popular in the context of EM-type algorithms for PET or SPECT. We show theoretically and also numerically that such data augmentation significantly increases mixing times for the Markov chain. In view of this, our algorithms seem to give a reasonable trade-off between design complexity, scalability, numerical load and asessement for the uncertainty quantification.
VolMap: A Real-time Model for Semantic Segmentation of a LiDAR surrounding view
Jun 12, 2019



This paper introduces VolMap, a real-time approach for the semantic segmentation of a 3D LiDAR surrounding view system in autonomous vehicles. We designed an optimized deep convolution neural network that can accurately segment the point cloud produced by a 360\degree{} LiDAR setup, where the input consists of a volumetric bird-eye view with LiDAR height layers used as input channels. We further investigated the usage of multi-LiDAR setup and its effect on the performance of the semantic segmentation task. Our evaluations are carried out on a large scale 3D object detection benchmark containing a LiDAR cocoon setup, along with KITTI dataset, where the per-point segmentation labels are derived from 3D bounding boxes. We show that VolMap achieved an excellent balance between high accuracy and real-time running on CPU.
Imitation and Mirror Systems in Robots through Deep Modality Blending Networks
Jun 15, 2021

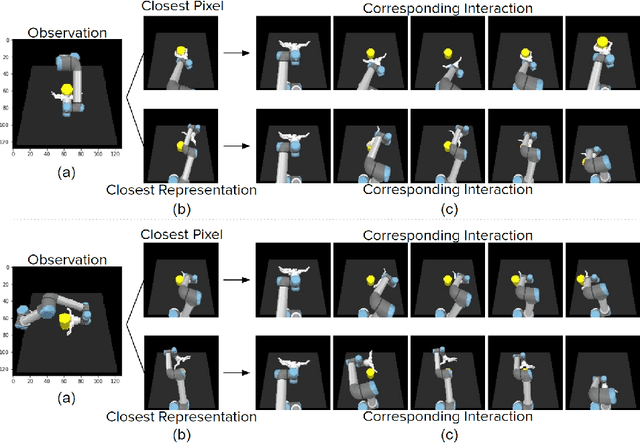

Learning to interact with the environment not only empowers the agent with manipulation capability but also generates information to facilitate building of action understanding and imitation capabilities. This seems to be a strategy adopted by biological systems, in particular primates, as evidenced by the existence of mirror neurons that seem to be involved in multi-modal action understanding. How to benefit from the interaction experience of the robots to enable understanding actions and goals of other agents is still a challenging question. In this study, we propose a novel method, deep modality blending networks (DMBN), that creates a common latent space from multi-modal experience of a robot by blending multi-modal signals with a stochastic weighting mechanism. We show for the first time that deep learning, when combined with a novel modality blending scheme, can facilitate action recognition and produce structures to sustain anatomical and effect-based imitation capabilities. Our proposed system, can be conditioned on any desired sensory/motor value at any time-step, and can generate a complete multi-modal trajectory consistent with the desired conditioning in parallel avoiding accumulation of prediction errors. We further showed that given desired images from different perspectives, i.e. images generated by the observation of other robots placed on different sides of the table, our system could generate image and joint angle sequences that correspond to either anatomical or effect based imitation behavior. Overall, the proposed DMBN architecture not only serves as a computational model for sustaining mirror neuron-like capabilities, but also stands as a powerful machine learning architecture for high-dimensional multi-modal temporal data with robust retrieval capabilities operating with partial information in one or multiple modalities.
Generalization in Multimodal Language Learning from Simulation
Aug 03, 2021


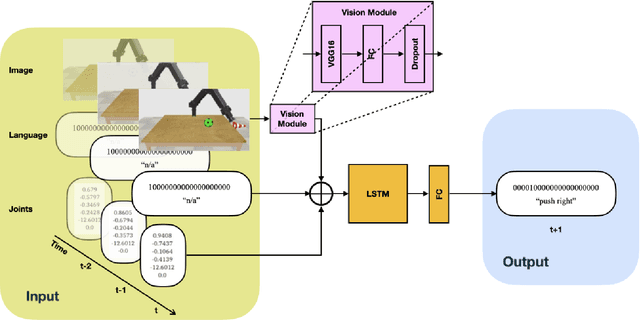
Neural networks can be powerful function approximators, which are able to model high-dimensional feature distributions from a subset of examples drawn from the target distribution. Naturally, they perform well at generalizing within the limits of their target function, but they often fail to generalize outside of the explicitly learned feature space. It is therefore an open research topic whether and how neural network-based architectures can be deployed for systematic reasoning. Many studies have shown evidence for poor generalization, but they often work with abstract data or are limited to single-channel input. Humans, however, learn and interact through a combination of multiple sensory modalities, and rarely rely on just one. To investigate compositional generalization in a multimodal setting, we generate an extensible dataset with multimodal input sequences from simulation. We investigate the influence of the underlying training data distribution on compostional generalization in a minimal LSTM-based network trained in a supervised, time continuous setting. We find compositional generalization to fail in simple setups while improving with the number of objects, actions, and particularly with a lot of color overlaps between objects. Furthermore, multimodality strongly improves compositional generalization in settings where a pure vision model struggles to generalize.
Random Warping Series: A Random Features Method for Time-Series Embedding
Sep 14, 2018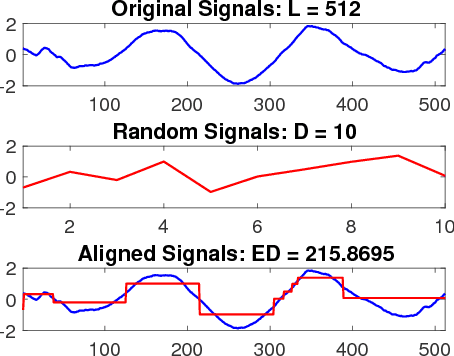
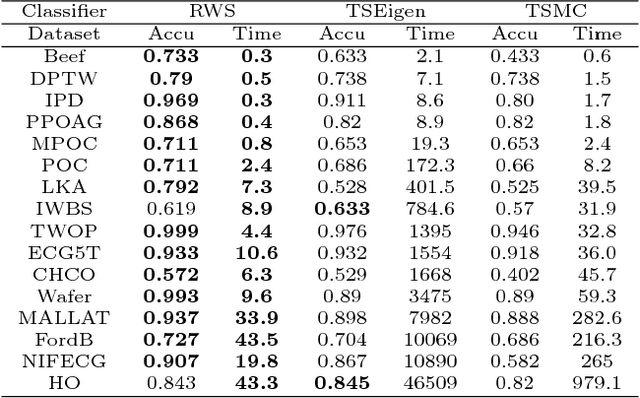
Time series data analytics has been a problem of substantial interests for decades, and Dynamic Time Warping (DTW) has been the most widely adopted technique to measure dissimilarity between time series. A number of global-alignment kernels have since been proposed in the spirit of DTW to extend its use to kernel-based estimation method such as support vector machine. However, those kernels suffer from diagonal dominance of the Gram matrix and a quadratic complexity w.r.t. the sample size. In this work, we study a family of alignment-aware positive definite (p.d.) kernels, with its feature embedding given by a distribution of \emph{Random Warping Series (RWS)}. The proposed kernel does not suffer from the issue of diagonal dominance while naturally enjoys a \emph{Random Features} (RF) approximation, which reduces the computational complexity of existing DTW-based techniques from quadratic to linear in terms of both the number and the length of time-series. We also study the convergence of the RF approximation for the domain of time series of unbounded length. Our extensive experiments on 16 benchmark datasets demonstrate that RWS outperforms or matches state-of-the-art classification and clustering methods in both accuracy and computational time. Our code and data is available at { \url{https://github.com/IBM/RandomWarpingSeries}}.
Lifelong Computing
Aug 19, 2021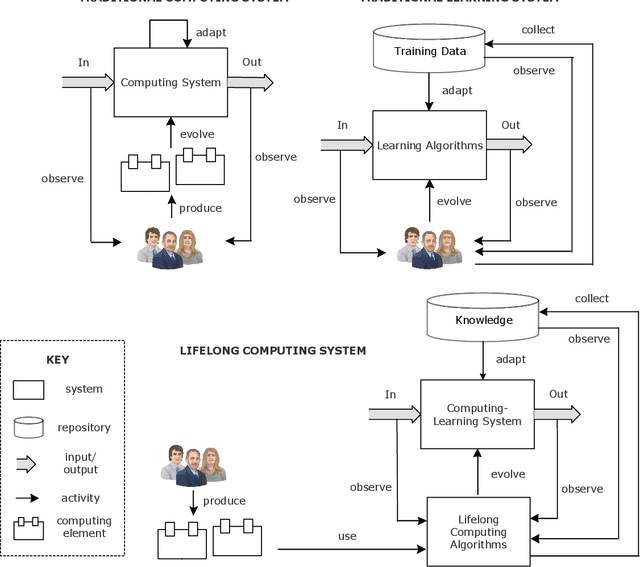
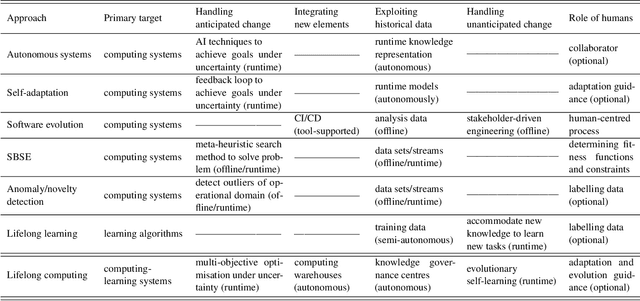
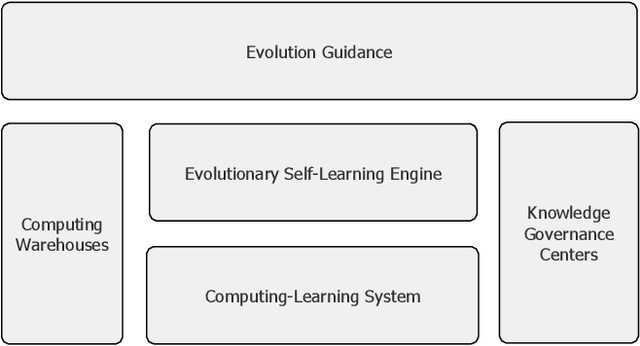
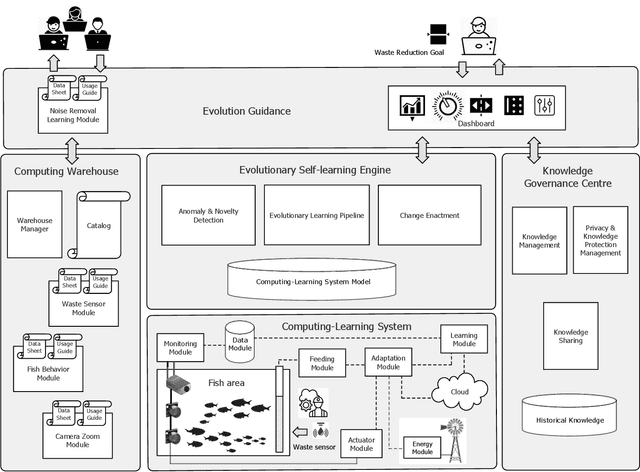
Computing systems form the backbone of many aspects of our life, hence they are becoming as vital as water, electricity, and road infrastructures for our society. Yet, engineering long running computing systems that achieve their goals in ever-changing environments pose significant challenges. Currently, we can build computing systems that adjust or learn over time to match changes that were anticipated. However, dealing with unanticipated changes, such as anomalies, novelties, new goals or constraints, requires system evolution, which remains in essence a human-driven activity. Given the growing complexity of computing systems and the vast amount of highly complex data to process, this approach will eventually become unmanageable. To break through the status quo, we put forward a new paradigm for the design and operation of computing systems that we coin "lifelong computing." The paradigm starts from computing-learning systems that integrate computing/service modules and learning modules. Computing warehouses offer such computing elements together with data sheets and usage guides. When detecting anomalies, novelties, new goals or constraints, a lifelong computing system activates an evolutionary self-learning engine that runs online experiments to determine how the computing-learning system needs to evolve to deal with the changes, thereby changing its architecture and integrating new computing elements from computing warehouses as needed. Depending on the domain at hand, some activities of lifelong computing systems can be supported by humans. We motivate the need for lifelong computing with a future fish farming scenario, outline a blueprint architecture for lifelong computing systems, and highlight key research challenges to realise the vision of lifelong computing.
A Point Cloud Generative Model via Tree-Structured Graph Convolutions for 3D Brain Shape Reconstruction
Jul 21, 2021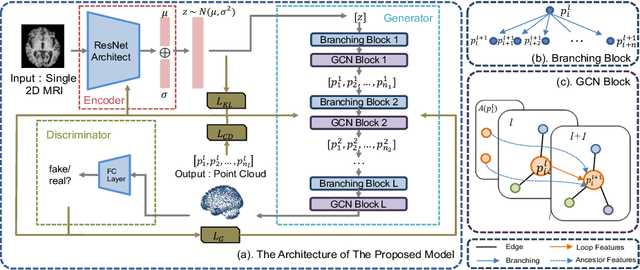

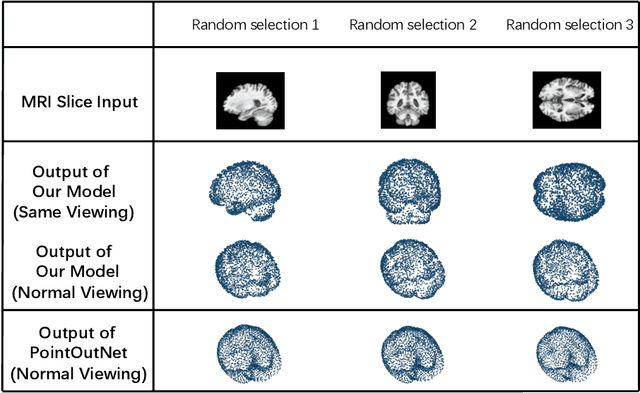

Fusing medical images and the corresponding 3D shape representation can provide complementary information and microstructure details to improve the operational performance and accuracy in brain surgery. However, compared to the substantial image data, it is almost impossible to obtain the intraoperative 3D shape information by using physical methods such as sensor scanning, especially in minimally invasive surgery and robot-guided surgery. In this paper, a general generative adversarial network (GAN) architecture based on graph convolutional networks is proposed to reconstruct the 3D point clouds (PCs) of brains by using one single 2D image, thus relieving the limitation of acquiring 3D shape data during surgery. Specifically, a tree-structured generative mechanism is constructed to use the latent vector effectively and transfer features between hidden layers accurately. With the proposed generative model, a spontaneous image-to-PC conversion is finished in real-time. Competitive qualitative and quantitative experimental results have been achieved on our model. In multiple evaluation methods, the proposed model outperforms another common point cloud generative model PointOutNet.
Drift in a Popular Metal Oxide Sensor Dataset Reveals Limitations for Gas Classification Benchmarks
Aug 19, 2021



Metal oxide (MOx) electro-chemical gas sensors are a sensible choice for many applications, due to their tunable sensitivity, their space-efficiency and their low price. Publicly available sensor datasets streamline the development and evaluation of novel algorithm and circuit designs, making them particularly valuable for the Artificial Olfaction / Mobile Robot Olfaction community. In 2013, Vergara et al. published a dataset comprising 16 months of recordings from a large MOx gas sensor array in a wind tunnel, which has since become a standard benchmark in the field. Here we report a previously undetected property of the dataset that limits its suitability for gas classification studies. The analysis of individual measurement timestamps reveals that gases were recorded in temporally clustered batches. The consequential correlation between the sensor response before gas exposure and the time of recording is often sufficient to predict the gas used in a given trial. Even if compensated by zero-offset-subtraction, residual short-term drift contains enough information for gas classification. We have identified a minimally drift-affected subset of the data, which is suitable for gas classification benchmarking after zero-offset-subtraction, although gas classification performance was substantially lower than for the full dataset. We conclude that previous studies conducted with this dataset very likely overestimate the accuracy of gas classification results. For the 17 potentially affected publications, we urge the authors to re-evaluate the results in light of our findings. Our observations emphasize the need to thoroughly document gas sensing datasets, and proper validation before using them for the development of algorithms.
Conditional Neural Relational Inference for Interacting Systems
Jun 21, 2021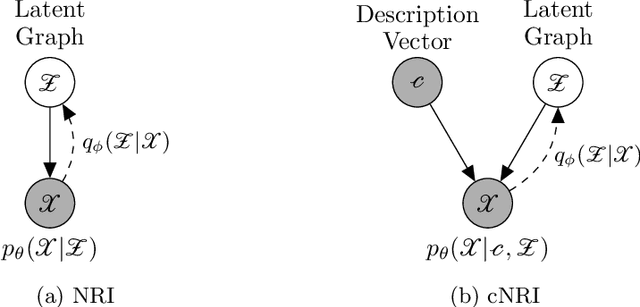
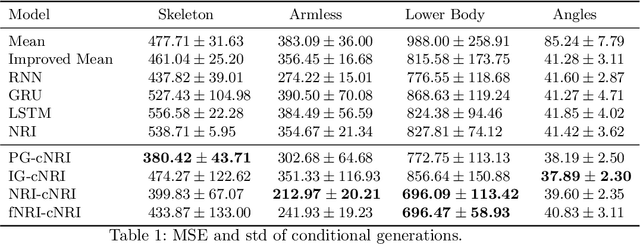
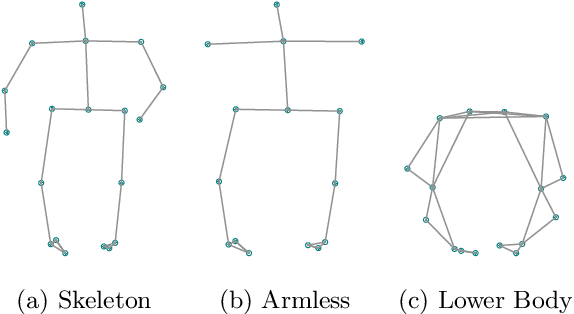
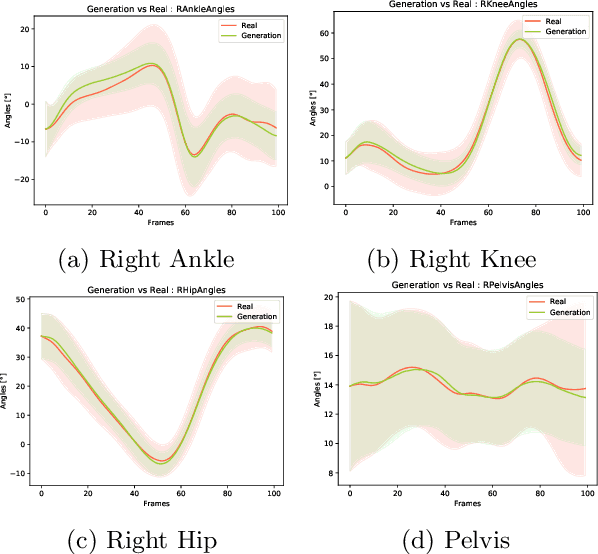
In this work, we want to learn to model the dynamics of similar yet distinct groups of interacting objects. These groups follow some common physical laws that exhibit specificities that are captured through some vectorial description. We develop a model that allows us to do conditional generation from any such group given its vectorial description. Unlike previous work on learning dynamical systems that can only do trajectory completion and require a part of the trajectory dynamics to be provided as input in generation time, we do generation using only the conditioning vector with no access to generation time's trajectories. We evaluate our model in the setting of modeling human gait and, in particular pathological human gait.