 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
How to Train Your Flare Prediction Model: Revisiting Robust Sampling of Rare Events
Mar 12, 2021
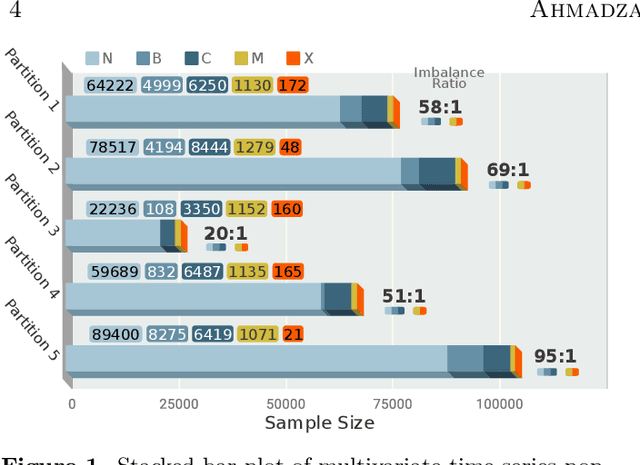
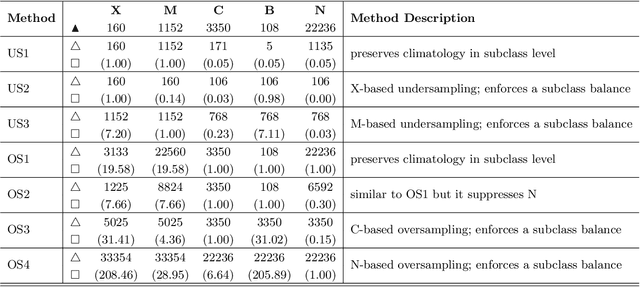
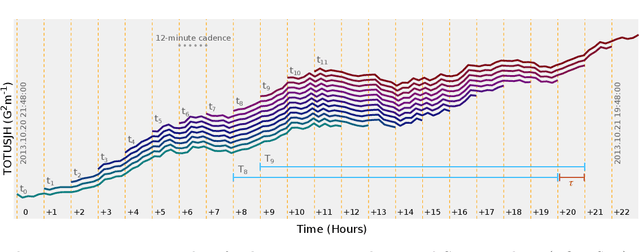
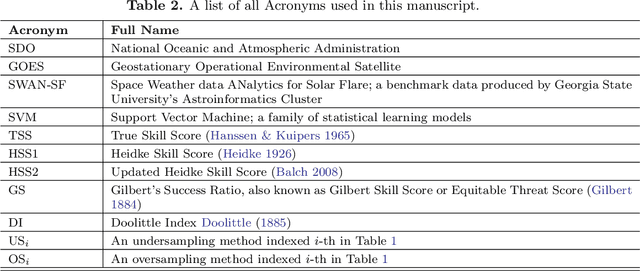
We present a case study of solar flare forecasting by means of metadata feature time series, by treating it as a prominent class-imbalance and temporally coherent problem. Taking full advantage of pre-flare time series in solar active regions is made possible via the Space Weather Analytics for Solar Flares (SWAN-SF) benchmark dataset; a partitioned collection of multivariate time series of active region properties comprising 4075 regions and spanning over 9 years of the Solar Dynamics Observatory (SDO) period of operations. We showcase the general concept of temporal coherence triggered by the demand of continuity in time series forecasting and show that lack of proper understanding of this effect may spuriously enhance models' performance. We further address another well-known challenge in rare event prediction, namely, the class-imbalance issue. The SWAN-SF is an appropriate dataset for this, with a 60:1 imbalance ratio for GOES M- and X-class flares and a 800:1 for X-class flares against flare-quiet instances. We revisit the main remedies for these challenges and present several experiments to illustrate the exact impact that each of these remedies may have on performance. Moreover, we acknowledge that some basic data manipulation tasks such as data normalization and cross validation may also impact the performance -- we discuss these problems as well. In this framework we also review the primary advantages and disadvantages of using true skill statistic and Heidke skill score, as two widely used performance verification metrics for the flare forecasting task. In conclusion, we show and advocate for the benefits of time series vs. point-in-time forecasting, provided that the above challenges are measurably and quantitatively addressed.
Scheduling Aerial Vehicles in an Urban Air Mobility Scheme
Aug 03, 2021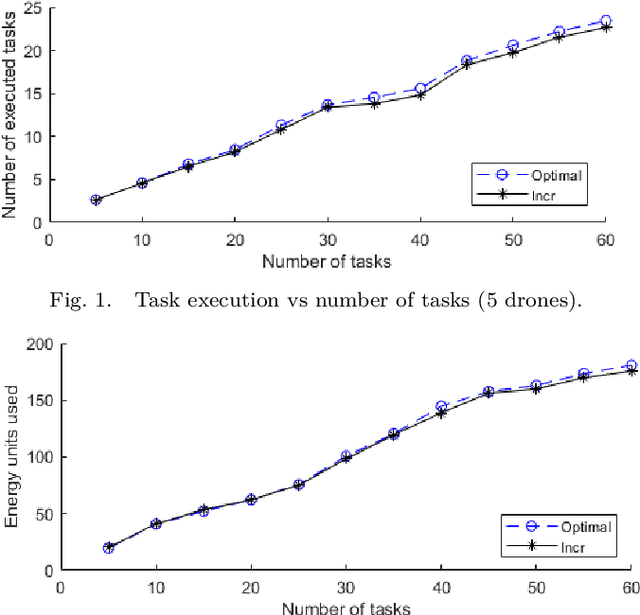
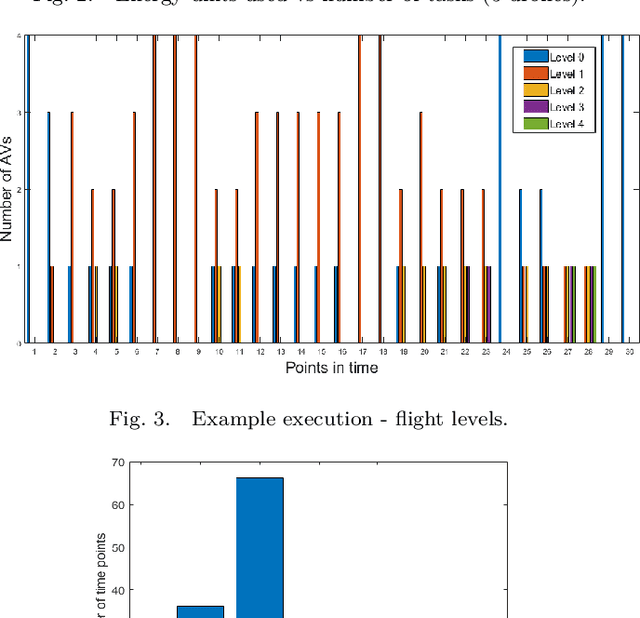
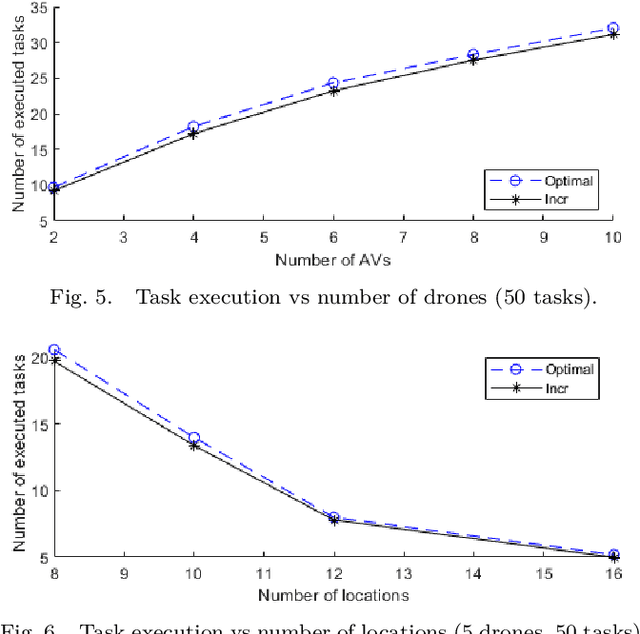
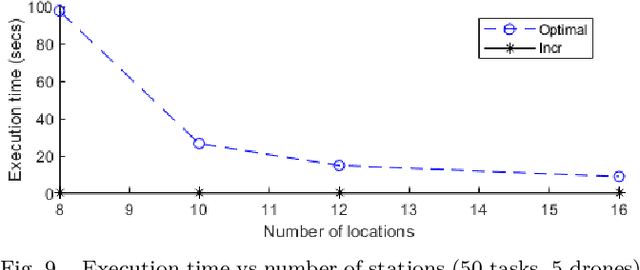
Highly populated cities face several challenges, one of them being the intense traffic congestion. In recent years, the concept of Urban Air Mobility has been put forward by large companies and organizations as a way to address this problem, and this approach has been rapidly gaining ground. This disruptive technology involves aerial vehicles (AVs) for hire than can be utilized by customers to travel between locations within large cities. This concept has the potential to drastically decrease traffic congestion and reduce air pollution, since these vehicles typically use electric motors powered by batteries. This work studies the problem of scheduling the assignment of AVs to customers, having as a goal to maximize the serviced customers and minimize the energy consumption of the AVs by forcing them to fly at the lowest possible altitude. Initially, an Integer Linear Program (ILP) formulation is presented, that is solved offline and optimally, followed by a near-optimal algorithm, that solves the problem incrementally, one AV at a time, to address scalability issues, allowing scheduling in problems involving large numbers of locations, AVs, and customer requests.
Fast Rule-Based Clutter Detection in Automotive Radar Data
Aug 27, 2021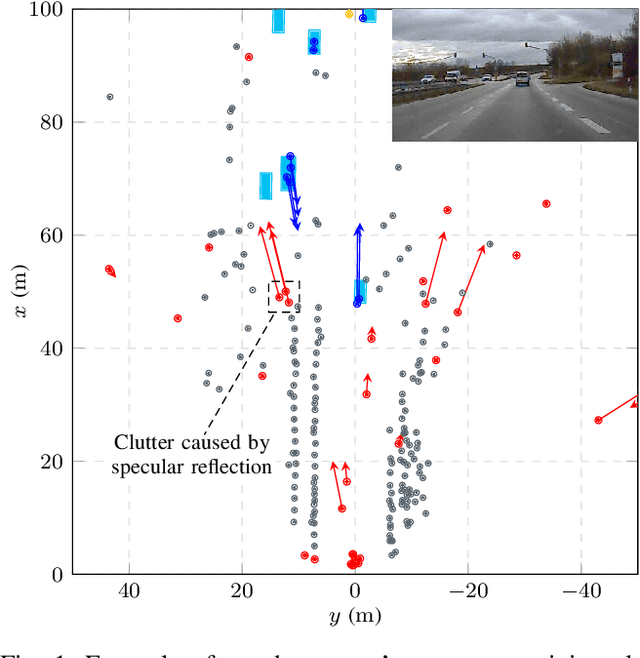
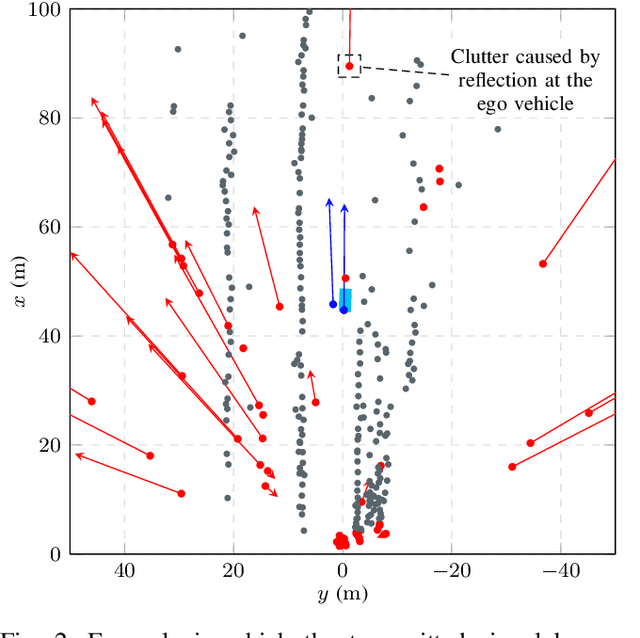
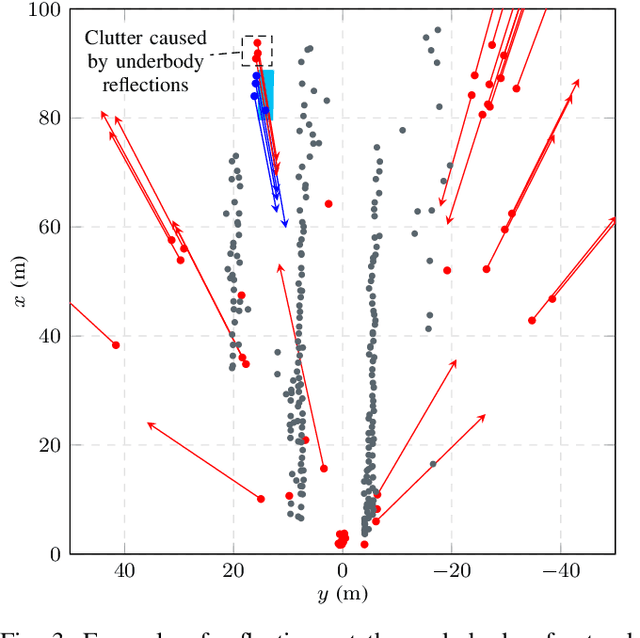
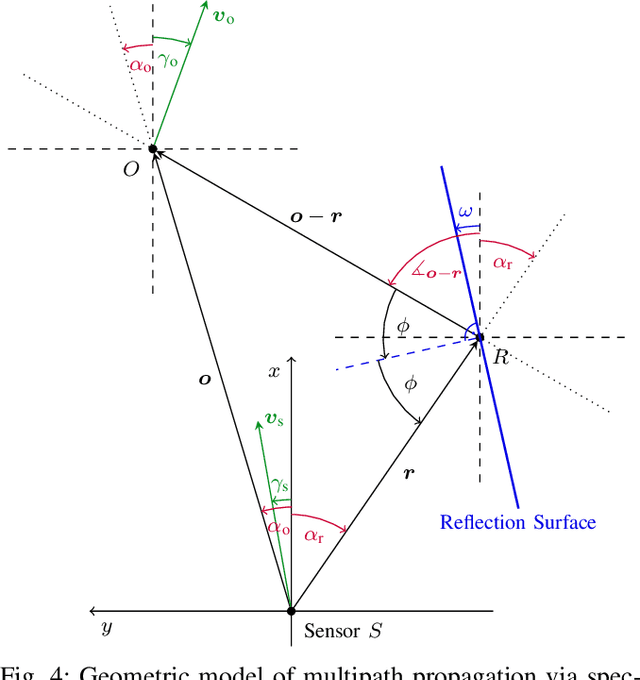
Automotive radar sensors output a lot of unwanted clutter or ghost detections, whose position and velocity do not correspond to any real object in the sensor's field of view. This poses a substantial challenge for environment perception methods like object detection or tracking. Especially problematic are clutter detections that occur in groups or at similar locations in multiple consecutive measurements. In this paper, a new algorithm for identifying such erroneous detections is presented. It is mainly based on the modeling of specific commonly occurring wave propagation paths that lead to clutter. In particular, the three effects explicitly covered are reflections at the underbody of a car or truck, signals traveling back and forth between the vehicle on which the sensor is mounted and another object, and multipath propagation via specular reflection. The latter often occurs near guardrails, concrete walls or similar reflective surfaces. Each of these effects is described both theoretically and regarding a method for identifying the corresponding clutter detections. Identification is done by analyzing detections generated from a single sensor measurement only. The final algorithm is evaluated on recordings of real extra-urban traffic. For labeling, a semi-automatic process is employed. The results are promising, both in terms of performance and regarding the very low execution time. Typically, a large part of clutter is found, while only a small ratio of detections corresponding to real objects are falsely classified by the algorithm.
Avaya Conversational Intelligence: A Real-Time System for Spoken Language Understanding in Human-Human Call Center Conversations
Sep 02, 2019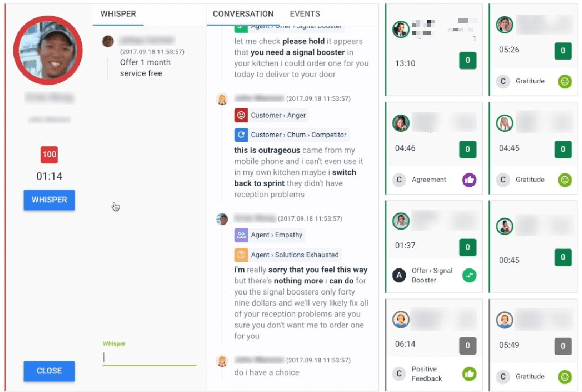
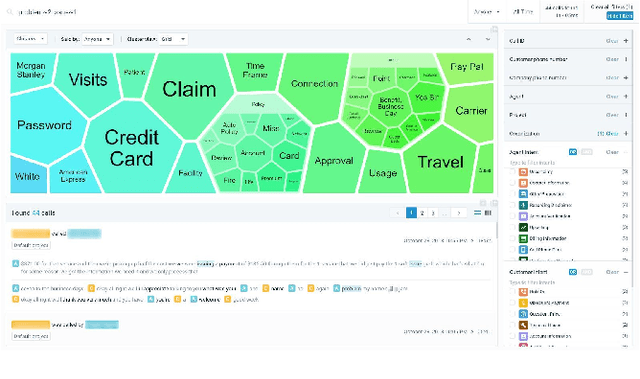
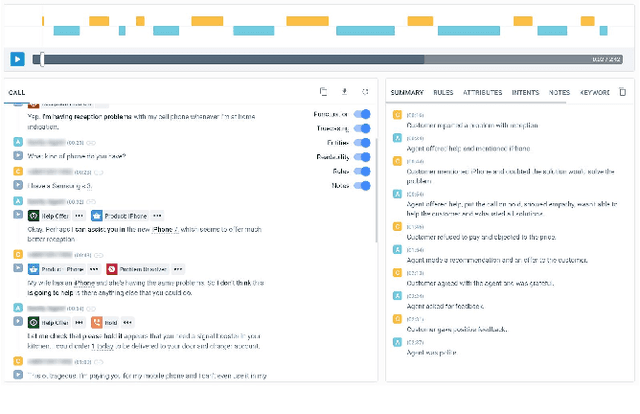
Avaya Conversational Intelligence(ACI) is an end-to-end, cloud-based solution for real-time Spoken Language Understanding for call centers. It combines large vocabulary, real-time speech recognition, transcript refinement, and entity and intent recognition in order to convert live audio into a rich, actionable stream of structured events. These events can be further leveraged with a business rules engine, thus serving as a foundation for real-time supervision and assistance applications. After the ingestion, calls are enriched with unsupervised keyword extraction, abstractive summarization, and business-defined attributes, enabling offline use cases, such as business intelligence, topic mining, full-text search, quality assurance, and agent training. ACI comes with a pretrained, configurable library of hundreds of intents and a robust intent training environment that allows for efficient, cost-effective creation and customization of customer-specific intents.
Real-Time Well Log Prediction From Drilling Data Using Deep Learning
Jan 28, 2020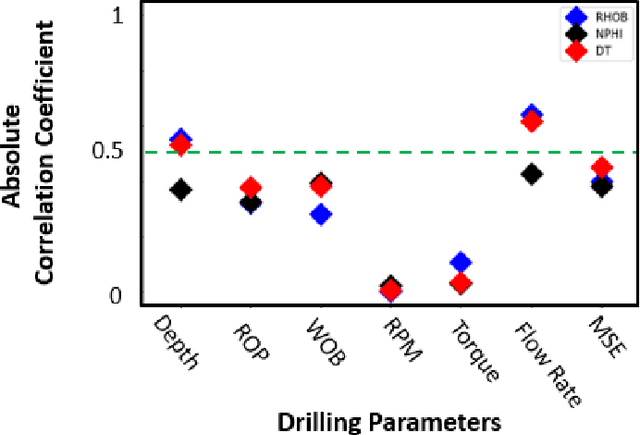
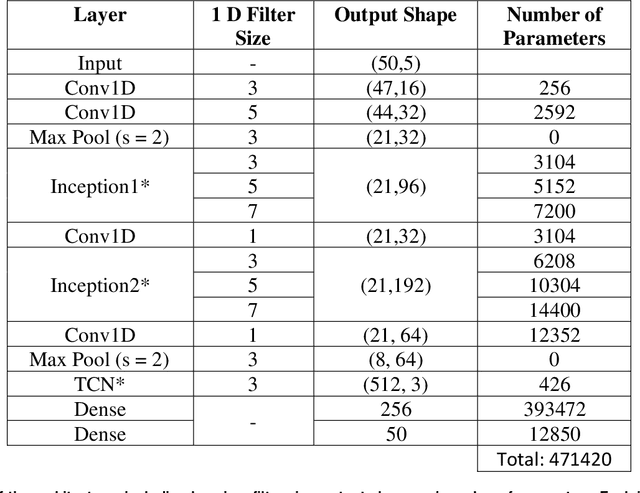
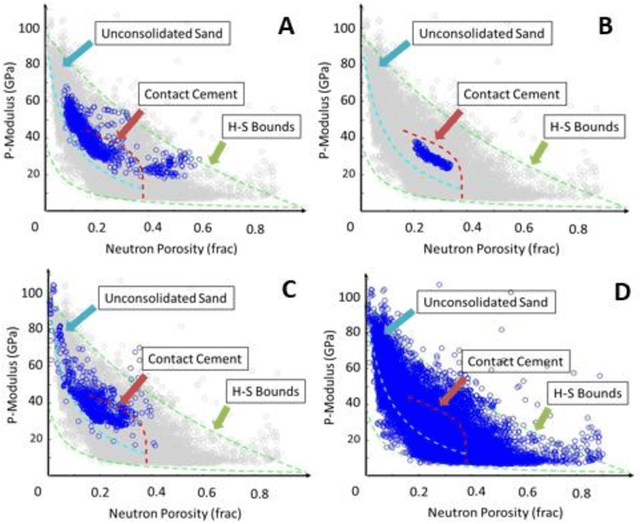
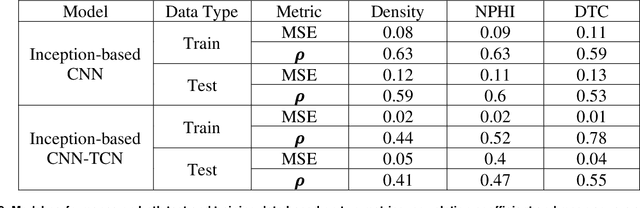
The objective is to study the feasibility of predicting subsurface rock properties in wells from real-time drilling data. Geophysical logs, namely, density, porosity and sonic logs are of paramount importance for subsurface resource estimation and exploitation. These wireline petro-physical measurements are selectively deployed as they are expensive to acquire; meanwhile, drilling information is recorded in every drilled well. Hence a predictive tool for wireline log prediction from drilling data can help management make decisions about data acquisition, especially for delineation and production wells. This problem is non-linear with strong ineractions between drilling parameters; hence the potential for deep learning to address this problem is explored. We present a workflow for data augmentation and feature engineering using Distance-based Global Sensitivity Analysis. We propose an Inception-based Convolutional Neural Network combined with a Temporal Convolutional Network as the deep learning model. The model is designed to learn both low and high frequency content of the data. 12 wells from the Equinor dataset for the Volve field in the North Sea are used for learning. The model predictions not only capture trends but are also physically consistent across density, porosity, and sonic logs. On the test data, the mean square error reaches a low value of 0.04 but the correlation coefficient plateaus around 0.6. The model is able however to differentiate between different types of rocks such as cemented sandstone, unconsolidated sands, and shale.
Joint Active User Detection and Channel Estimation for Grant-Free NOMA-OTFS in LEO Constellation Internet-of-Things
Aug 03, 2021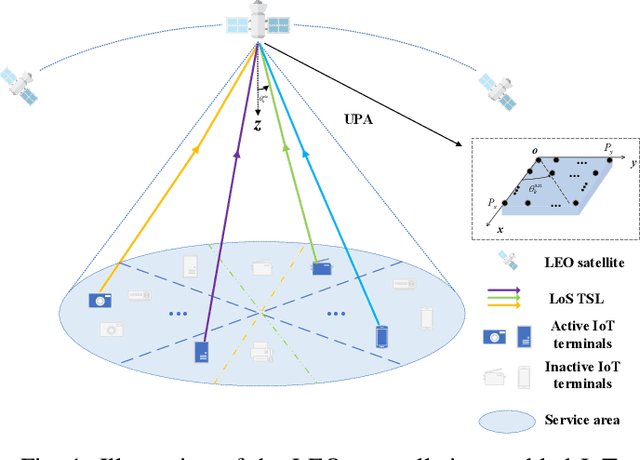
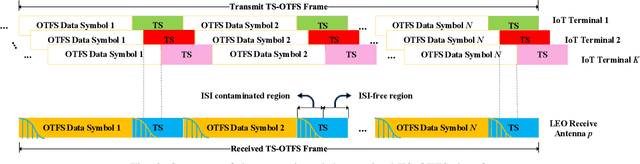
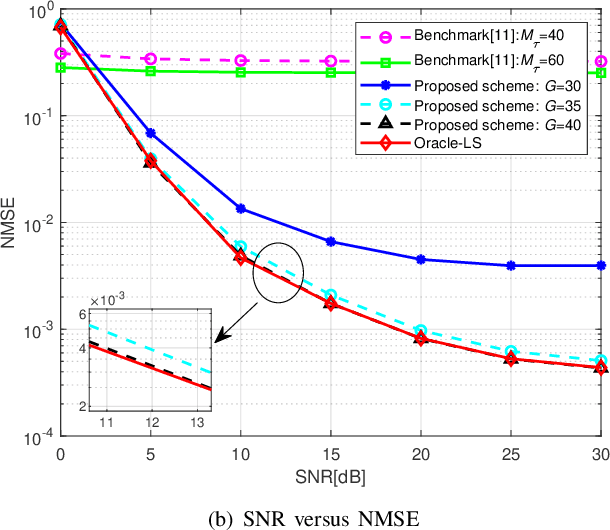

The flourishing low-Earth orbit (LEO) constellation communication network provides a promising solution for seamless coverage services to Internet-of-Things (IoT) terminals. However, confronted with massive connectivity and rapid variation of terrestrial-satellite link (TSL), the traditional grant-free random-access schemes always fail to match this scenario. In this paper, a new non-orthogonal multiple-access (NOMA) transmission protocol that incorporates orthogonal time frequency space (OTFS) modulation is proposed to solve these problems. Furthermore, we propose a two-stages joint active user detection and channel estimation scheme based on the training sequences aided OTFS data frame structure. Specifically, in the first stage, with the aid of training sequences, we perform active user detection and coarse channel estimation by recovering the sparse sampled channel vectors. And then, we develop a parametric approach to facilitate more accurate result of channel estimation with the previously recovered sampled channel vectors according to the inherent characteristics of TSL channel. Simulation results demonstrate the superiority of the proposed method in this kind of high-mobility scenario in the end.
Direct Reconstruction of Linear Parametric Images from Dynamic PET Using Nonlocal Deep Image Prior
Jun 18, 2021
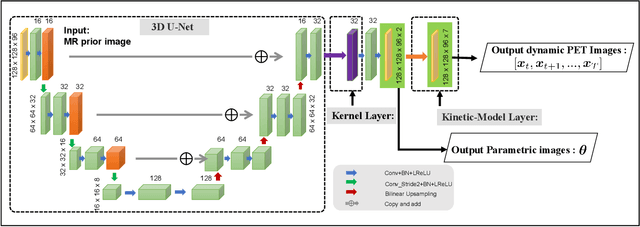
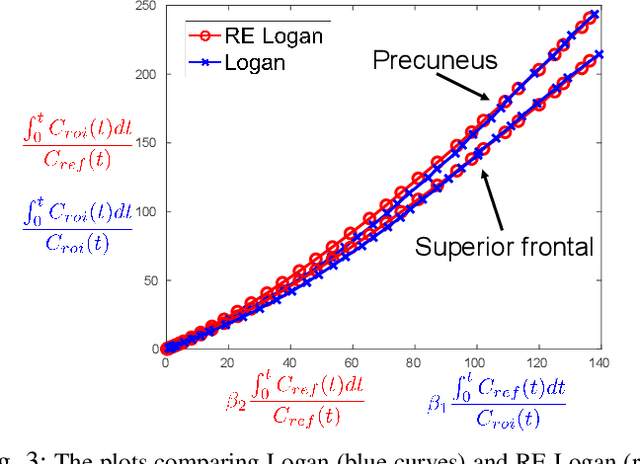
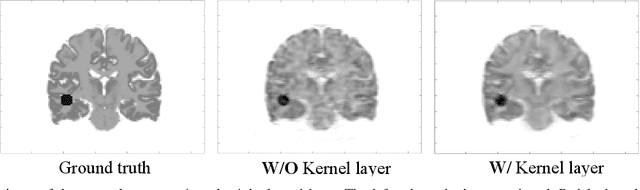
Direct reconstruction methods have been developed to estimate parametric images directly from the measured PET sinograms by combining the PET imaging model and tracer kinetics in an integrated framework. Due to limited counts received, signal-to-noise-ratio (SNR) and resolution of parametric images produced by direct reconstruction frameworks are still limited. Recently supervised deep learning methods have been successfully applied to medical imaging denoising/reconstruction when large number of high-quality training labels are available. For static PET imaging, high-quality training labels can be acquired by extending the scanning time. However, this is not feasible for dynamic PET imaging, where the scanning time is already long enough. In this work, we proposed an unsupervised deep learning framework for direct parametric reconstruction from dynamic PET, which was tested on the Patlak model and the relative equilibrium Logan model. The patient's anatomical prior image, which is readily available from PET/CT or PET/MR scans, was supplied as the network input to provide a manifold constraint, and also utilized to construct a kernel layer to perform non-local feature denoising. The linear kinetic model was embedded in the network structure as a 1x1 convolution layer. The training objective function was based on the PET statistical model. Evaluations based on dynamic datasets of 18F-FDG and 11C-PiB tracers show that the proposed framework can outperform the traditional and the kernel method-based direct reconstruction methods.
Detecting Faults during Automatic Screwdriving: A Dataset and Use Case of Anomaly Detection for Automatic Screwdriving
Jul 05, 2021
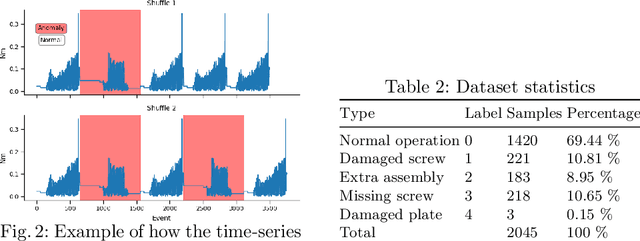
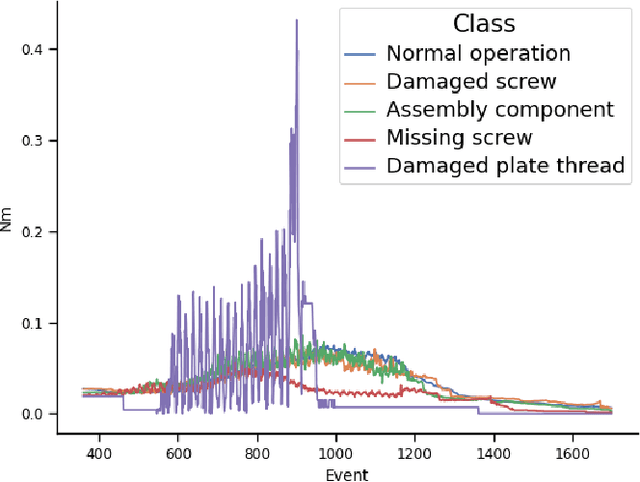
Detecting faults in manufacturing applications can be difficult, especially if each fault model is to be engineered by hand. Data-driven approaches, using Machine Learning (ML) for detecting faults have recently gained increasing interest, where a ML model can be trained on a set of data from a manufacturing process. In this paper, we present a use case of using ML models for detecting faults during automated screwdriving operations, and introduce a new dataset containing fully monitored and registered data from a Universal Robot and OnRobot screwdriver during both normal and anomalous operations. We illustrate, with the use of two time-series ML models, how to detect faults in an automated screwdriving application.
PIXOR: Real-time 3D Object Detection from Point Clouds
Feb 17, 2019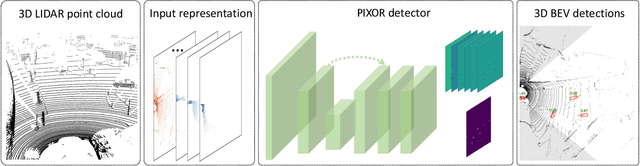

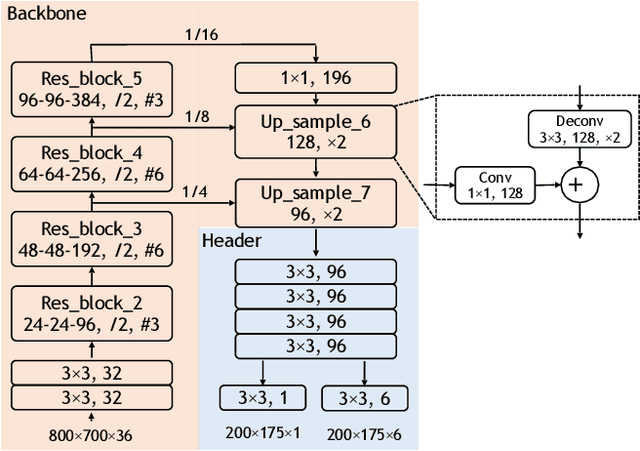

We address the problem of real-time 3D object detection from point clouds in the context of autonomous driving. Computation speed is critical as detection is a necessary component for safety. Existing approaches are, however, expensive in computation due to high dimensionality of point clouds. We utilize the 3D data more efficiently by representing the scene from the Bird's Eye View (BEV), and propose PIXOR, a proposal-free, single-stage detector that outputs oriented 3D object estimates decoded from pixel-wise neural network predictions. The input representation, network architecture, and model optimization are especially designed to balance high accuracy and real-time efficiency. We validate PIXOR on two datasets: the KITTI BEV object detection benchmark, and a large-scale 3D vehicle detection benchmark. In both datasets we show that the proposed detector surpasses other state-of-the-art methods notably in terms of Average Precision (AP), while still runs at >28 FPS.
Jointly Optimizing Query Encoder and Product Quantization to Improve Retrieval Performance
Aug 22, 2021
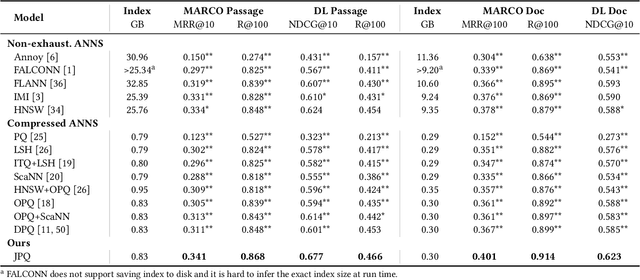
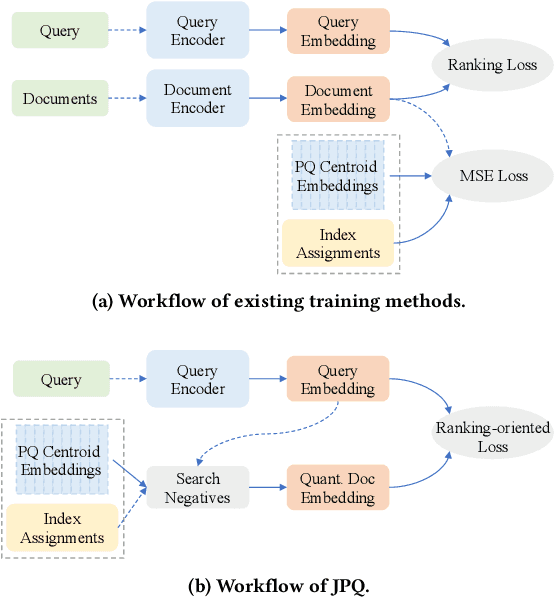
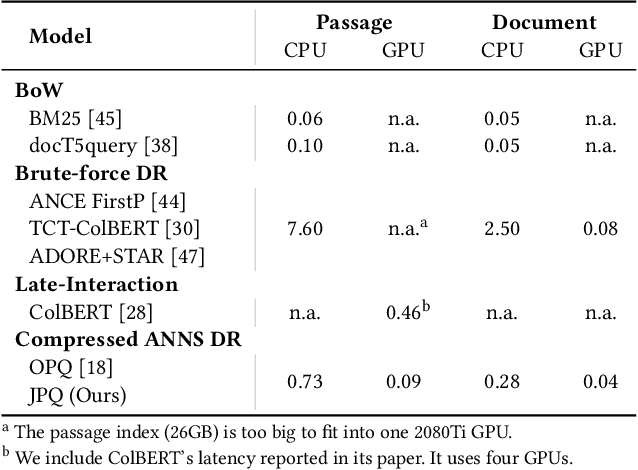
Recently, Information Retrieval community has witnessed fast-paced advances in Dense Retrieval (DR), which performs first-stage retrieval with embedding-based search. Despite the impressive ranking performance, previous studies usually adopt brute-force search to acquire candidates, which is prohibitive in practical Web search scenarios due to its tremendous memory usage and time cost. To overcome these problems, vector compression methods have been adopted in many practical embedding-based retrieval applications. One of the most popular methods is Product Quantization (PQ). However, although existing vector compression methods including PQ can help improve the efficiency of DR, they incur severely decayed retrieval performance due to the separation between encoding and compression. To tackle this problem, we present JPQ, which stands for Joint optimization of query encoding and Product Quantization. It trains the query encoder and PQ index jointly in an end-to-end manner based on three optimization strategies, namely ranking-oriented loss, PQ centroid optimization, and end-to-end negative sampling. We evaluate JPQ on two publicly available retrieval benchmarks. Experimental results show that JPQ significantly outperforms popular vector compression methods. Compared with previous DR models that use brute-force search, JPQ almost matches the best retrieval performance with 30x compression on index size. The compressed index further brings 10x speedup on CPU and 2x speedup on GPU in query latency.