 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting Associations between Solar Flares and Coronal Mass Ejections Using SDO/HMI Magnetograms and a Hybrid Neural Network
Apr 11, 2026Solar eruptions, including flares and coronal mass ejections (CMEs), have a significant impact on Earth. Some flares are associated with CMEs, and some flares are not. The association between flares and CMEs is not always obvious. In this study, we propose a new deep learning method, specifically a hybrid neural network (HNN) that combines a vision transformer with long short-term memory, to predict associations between flares and CMEs. HNN finds spatio-temporal patterns in the time series of line-of-sight magnetograms of solar active regions (ARs) collected by the Helioseismic and Magnetic Imager on board the Solar Dynamics Observatory and uses the patterns to predict whether a flare projected to occur within the next 24 hours will be eruptive (i.e., CME-associated) or confined (i.e., not CME-associated). Our experimental results demonstrate the good performance of the HNN method. Furthermore, the results show that magnetic flux cancellation in polarity inversion line regions may well play a role in triggering flare-associated CMEs, a finding consistent with literature.
Enhancing Explainability in Solar Energetic Particle Event Prediction: A Global Feature Mapping Approach
Nov 12, 2025Solar energetic particle (SEP) events, as one of the most prominent manifestations of solar activity, can generate severe hazardous radiation when accelerated by solar flares or shock waves formed aside from coronal mass ejections (CMEs). However, most existing data-driven methods used for SEP predictions are operated as black-box models, making it challenging for solar physicists to interpret the results and understand the underlying physical causes of such events rather than just obtain a prediction. To address this challenge, we propose a novel framework that integrates global explanations and ad-hoc feature mapping to enhance model transparency and provide deeper insights into the decision-making process. We validate our approach using a dataset of 341 SEP events, including 244 significant (>=10 MeV) proton events exceeding the Space Weather Prediction Center S1 threshold, spanning solar cycles 22, 23, and 24. Furthermore, we present an explainability-focused case study of major SEP events, demonstrating how our method improves explainability and facilitates a more physics-informed understanding of SEP event prediction.
Generative Simulations of The Solar Corona Evolution With Denoising Diffusion : Proof of Concept
Oct 28, 2024



The solar magnetized corona is responsible for various manifestations with a space weather impact, such as flares, coronal mass ejections (CMEs) and, naturally, the solar wind. Modeling the corona's dynamics and evolution is therefore critical for improving our ability to predict space weather In this work, we demonstrate that generative deep learning methods, such as Denoising Diffusion Probabilistic Models (DDPM), can be successfully applied to simulate future evolutions of the corona as observed in Extreme Ultraviolet (EUV) wavelengths. Our model takes a 12-hour video of an Active Region (AR) as input and simulate the potential evolution of the AR over the subsequent 12 hours, with a time-resolution of two hours. We propose a light UNet backbone architecture adapted to our problem by adding 1D temporal convolutions after each classical 2D spatial ones, and spatio-temporal attention in the bottleneck part. The model not only produce visually realistic outputs but also captures the inherent stochasticity of the system's evolution. Notably, the simulations enable the generation of reliable confidence intervals for key predictive metrics such as the EUV peak flux and fluence of the ARs, paving the way for probabilistic and interpretable space weather forecasting. Future studies will focus on shorter forecasting horizons with increased spatial and temporal resolution, aiming at reducing the uncertainty of the simulations and providing practical applications for space weather forecasting. The code used for this study is available at the following link: https://github.com/gfrancisco20/video_diffusion
Magnetogram-to-Magnetogram: Generative Forecasting of Solar Evolution
Jul 16, 2024


Investigating the solar magnetic field is crucial to understand the physical processes in the solar interior as well as their effects on the interplanetary environment. We introduce a novel method to predict the evolution of the solar line-of-sight (LoS) magnetogram using image-to-image translation with Denoising Diffusion Probabilistic Models (DDPMs). Our approach combines "computer science metrics" for image quality and "physics metrics" for physical accuracy to evaluate model performance. The results indicate that DDPMs are effective in maintaining the structural integrity, the dynamic range of solar magnetic fields, the magnetic flux and other physical features such as the size of the active regions, surpassing traditional persistence models, also in flaring situation. We aim to use deep learning not only for visualisation but as an integrative and interactive tool for telescopes, enhancing our understanding of unexpected physical events like solar flares. Future studies will aim to integrate more diverse solar data to refine the accuracy and applicability of our generative model.
Explainable Deep Learning-based Solar Flare Prediction with post hoc Attention for Operational Forecasting
Aug 04, 2023This paper presents a post hoc analysis of a deep learning-based full-disk solar flare prediction model. We used hourly full-disk line-of-sight magnetogram images and selected binary prediction mode to predict the occurrence of $\geq$M1.0-class flares within 24 hours. We leveraged custom data augmentation and sample weighting to counter the inherent class-imbalance problem and used true skill statistic and Heidke skill score as evaluation metrics. Recent advancements in gradient-based attention methods allow us to interpret models by sending gradient signals to assign the burden of the decision on the input features. We interpret our model using three post hoc attention methods: (i) Guided Gradient-weighted Class Activation Mapping, (ii) Deep Shapley Additive Explanations, and (iii) Integrated Gradients. Our analysis shows that full-disk predictions of solar flares align with characteristics related to the active regions. The key findings of this study are: (1) We demonstrate that our full disk model can tangibly locate and predict near-limb solar flares, which is a critical feature for operational flare forecasting, (2) Our candidate model achieves an average TSS=0.51$\pm$0.05 and HSS=0.38$\pm$0.08, and (3) Our evaluation suggests that these models can learn conspicuous features corresponding to active regions from full-disk magnetograms.
All-Clear Flare Prediction Using Interval-based Time Series Classifiers
May 03, 2021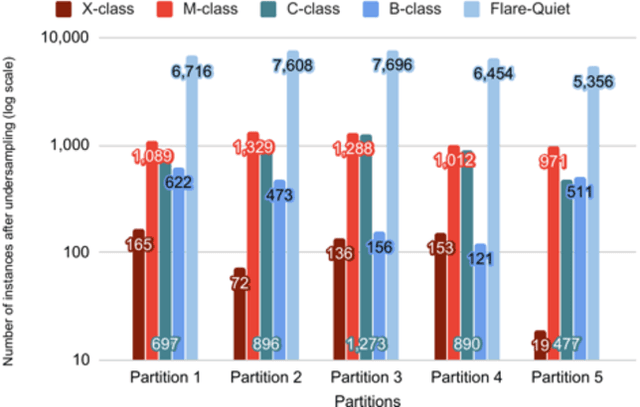
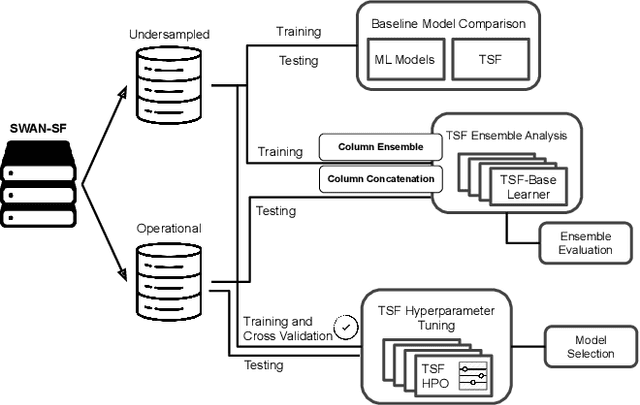
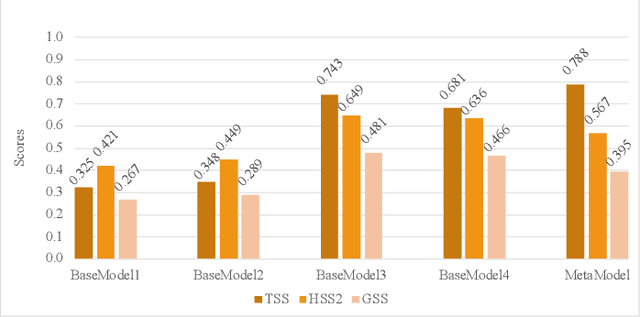
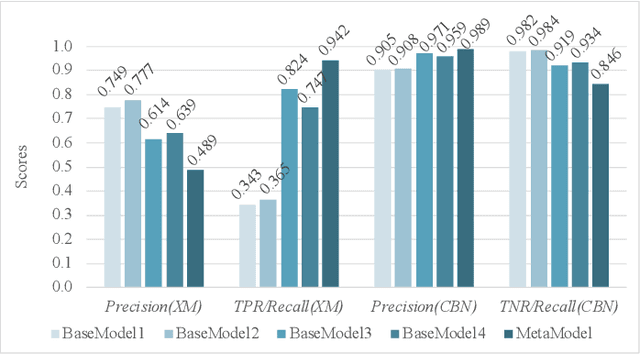
An all-clear flare prediction is a type of solar flare forecasting that puts more emphasis on predicting non-flaring instances (often relatively small flares and flare quiet regions) with high precision while still maintaining valuable predictive results. While many flare prediction studies do not address this problem directly, all-clear predictions can be useful in operational context. However, in all-clear predictions, finding the right balance between avoiding false negatives (misses) and reducing the false positives (false alarms) is often challenging. Our study focuses on training and testing a set of interval-based time series classifiers named Time Series Forest (TSF). These classifiers will be used towards building an all-clear flare prediction system by utilizing multivariate time series data. Throughout this paper, we demonstrate our data collection, predictive model building and evaluation processes, and compare our time series classification models with baselines using our benchmark datasets. Our results show that time series classifiers provide better forecasting results in terms of skill scores, precision and recall metrics, and they can be further improved for more precise all-clear forecasts by tuning model hyperparameters.
How to Train Your Flare Prediction Model: Revisiting Robust Sampling of Rare Events
Mar 12, 2021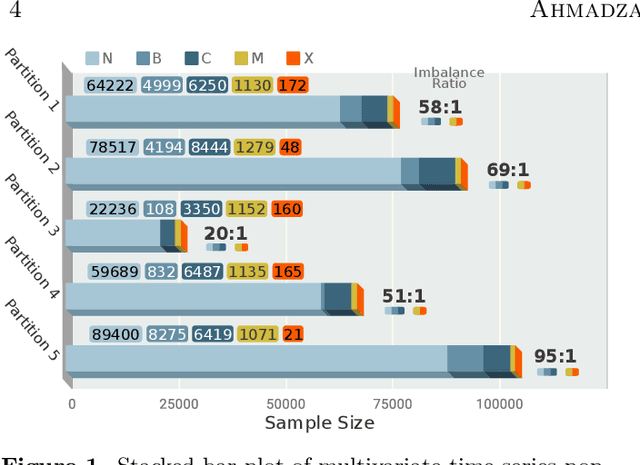
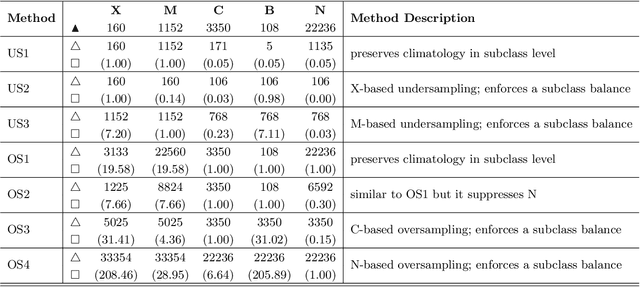
We present a case study of solar flare forecasting by means of metadata feature time series, by treating it as a prominent class-imbalance and temporally coherent problem. Taking full advantage of pre-flare time series in solar active regions is made possible via the Space Weather Analytics for Solar Flares (SWAN-SF) benchmark dataset; a partitioned collection of multivariate time series of active region properties comprising 4075 regions and spanning over 9 years of the Solar Dynamics Observatory (SDO) period of operations. We showcase the general concept of temporal coherence triggered by the demand of continuity in time series forecasting and show that lack of proper understanding of this effect may spuriously enhance models' performance. We further address another well-known challenge in rare event prediction, namely, the class-imbalance issue. The SWAN-SF is an appropriate dataset for this, with a 60:1 imbalance ratio for GOES M- and X-class flares and a 800:1 for X-class flares against flare-quiet instances. We revisit the main remedies for these challenges and present several experiments to illustrate the exact impact that each of these remedies may have on performance. Moreover, we acknowledge that some basic data manipulation tasks such as data normalization and cross validation may also impact the performance -- we discuss these problems as well. In this framework we also review the primary advantages and disadvantages of using true skill statistic and Heidke skill score, as two widely used performance verification metrics for the flare forecasting task. In conclusion, we show and advocate for the benefits of time series vs. point-in-time forecasting, provided that the above challenges are measurably and quantitatively addressed.
Challenges with Extreme Class-Imbalance and Temporal Coherence: A Study on Solar Flare Data
Nov 20, 2019
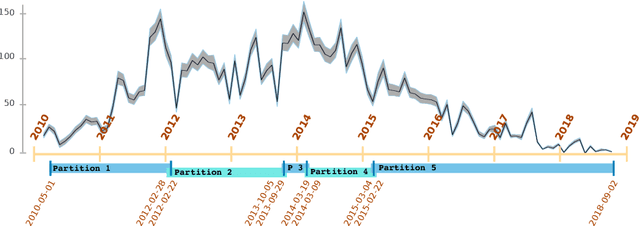
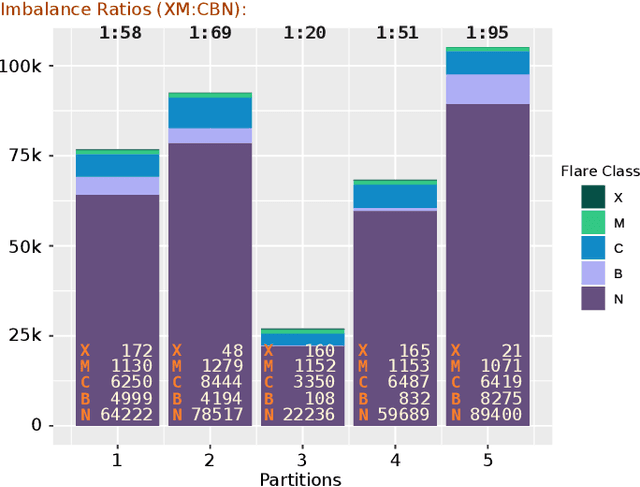
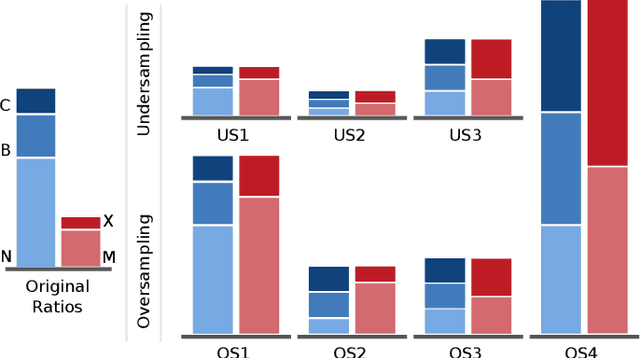
In analyses of rare-events, regardless of the domain of application, class-imbalance issue is intrinsic. Although the challenges are known to data experts, their explicit impact on the analytic and the decisions made based on the findings are often overlooked. This is in particular prevalent in interdisciplinary research where the theoretical aspects are sometimes overshadowed by the challenges of the application. To show-case these undesirable impacts, we conduct a series of experiments on a recently created benchmark data, named Space Weather ANalytics for Solar Flares (SWAN-SF). This is a multivariate time series dataset of magnetic parameters of active regions. As a remedy for the imbalance issue, we study the impact of data manipulation (undersampling and oversampling) and model manipulation (using class weights). Furthermore, we bring to focus the auto-correlation of time series that is inherited from the use of sliding window for monitoring flares' history. Temporal coherence, as we call this phenomenon, invalidates the randomness assumption, thus impacting all sampling practices including different cross-validation techniques. We illustrate how failing to notice this concept could give an artificial boost in the forecast performance and result in misleading findings. Throughout this study we utilized Support Vector Machine as a classifier, and True Skill Statistics as a verification metric for comparison of experiments. We conclude our work by specifying the correct practice in each case, and we hope that this study could benefit researchers in other domains where time series of rare events are of interest.