 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Associating Objects with Transformers for Video Object Segmentation
Jun 22, 2021
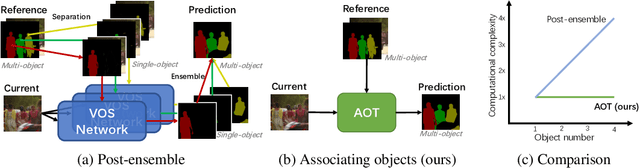
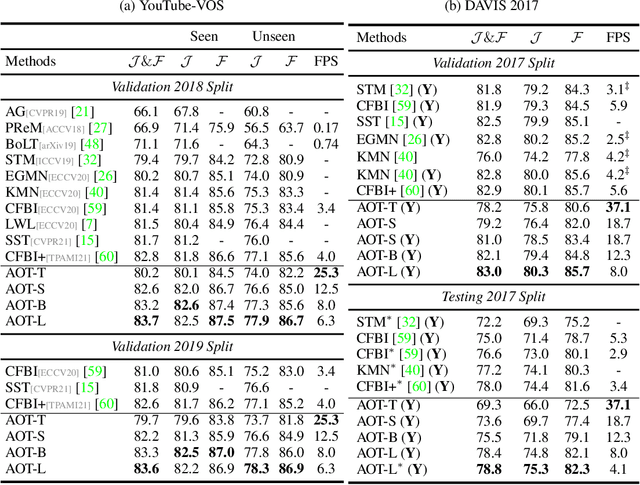
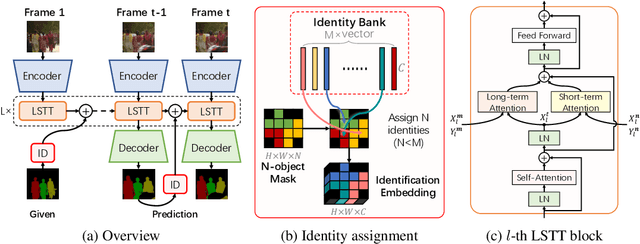
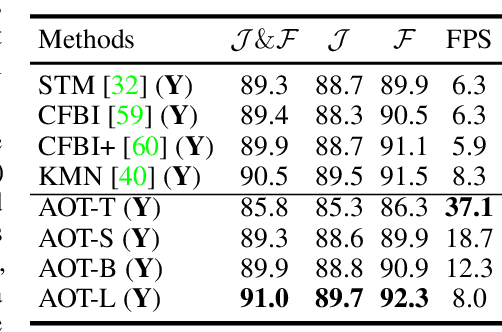
This paper investigates how to realize better and more efficient embedding learning to tackle the semi-supervised video object segmentation under challenging multi-object scenarios. The state-of-the-art methods learn to decode features with a single positive object and thus have to match and segment each target separately under multi-object scenarios, consuming multiple times computing resources. To solve the problem, we propose an Associating Objects with Transformers (AOT) approach to match and decode multiple objects uniformly. In detail, AOT employs an identification mechanism to associate multiple targets into the same high-dimensional embedding space. Thus, we can simultaneously process the matching and segmentation decoding of multiple objects as efficiently as processing a single object. For sufficiently modeling multi-object association, a Long Short-Term Transformer is designed for constructing hierarchical matching and propagation. We conduct extensive experiments on both multi-object and single-object benchmarks to examine AOT variant networks with different complexities. Particularly, our AOT-L outperforms all the state-of-the-art competitors on three popular benchmarks, i.e., YouTube-VOS (83.7% J&F), DAVIS 2017 (83.0%), and DAVIS 2016 (91.0%), while keeping more than 3X faster multi-object run-time. Meanwhile, our AOT-T can maintain real-time multi-object speed on the above benchmarks. We ranked 1st in the 3rd Large-scale Video Object Segmentation Challenge. The code will be publicly available at https://github.com/z-x-yang/AOT.
Hierarchical RNNs-Based Transformers MADDPG for Mixed Cooperative-Competitive Environments
May 11, 2021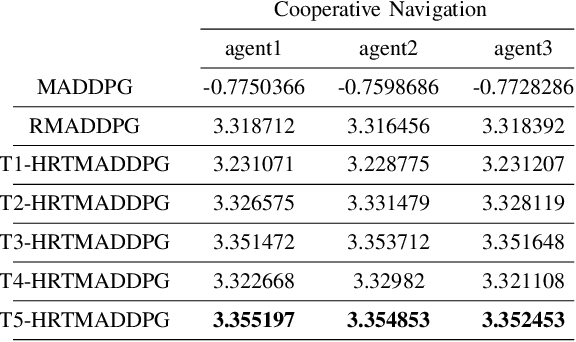
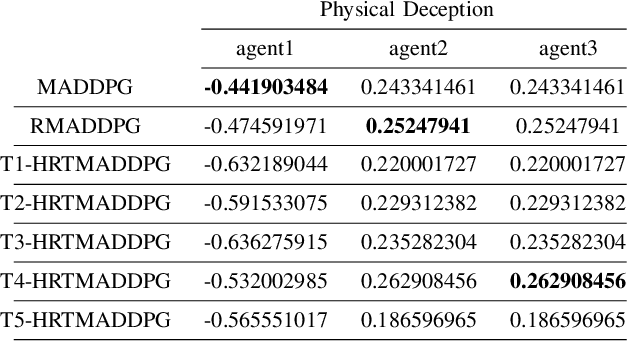
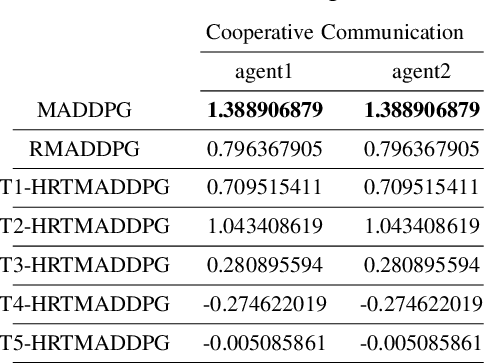
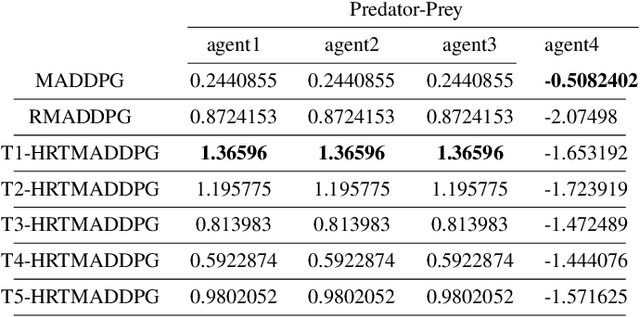
At present, attention mechanism has been widely applied to the fields of deep learning models. Structural models that based on attention mechanism can not only record the relationships between features position, but also can measure the importance of different features based on their weights. By establishing dynamically weighted parameters for choosing relevant and irrelevant features, the key information can be strengthened, and the irrelevant information can be weakened. Therefore, the efficiency of deep learning algorithms can be significantly elevated and improved. Although transformers have been performed very well in many fields including reinforcement learning, there are still many problems and applications can be solved and made with transformers within this area. MARL (known as Multi-Agent Reinforcement Learning) can be recognized as a set of independent agents trying to adapt and learn through their way to reach the goal. In order to emphasize the relationship between each MDP decision in a certain time period, we applied the hierarchical coding method and validated the effectiveness of this method. This paper proposed a hierarchical transformers MADDPG based on RNN which we call it Hierarchical RNNs-Based Transformers MADDPG(HRTMADDPG). It consists of a lower level encoder based on RNNs that encodes multiple step sizes in each time sequence, and it also consists of an upper sequence level encoder based on transformer for learning the correlations between multiple sequences so that we can capture the causal relationship between sub-time sequences and make HRTMADDPG more efficient.
Temporal Adaptation of BERT and Performance on Downstream Document Classification: Insights from Social Media
Apr 16, 2021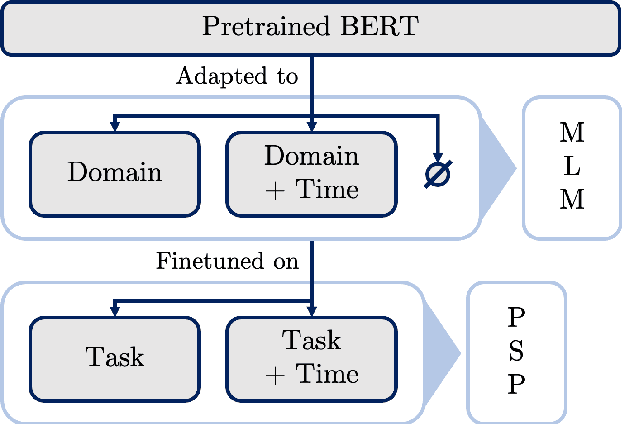
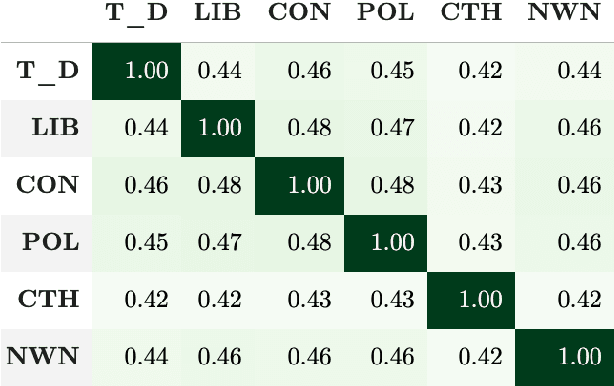
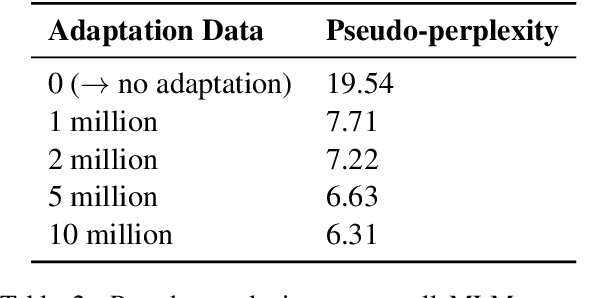
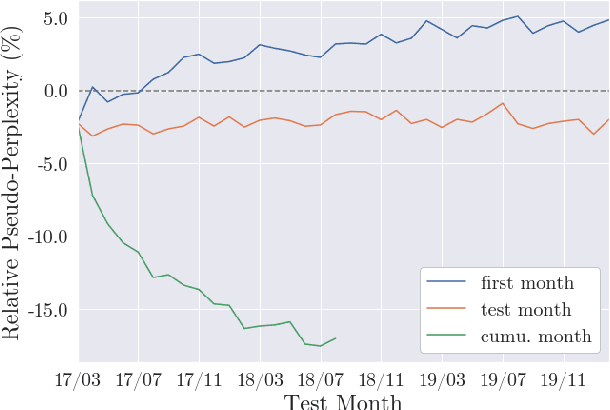
Language use differs between domains and even within a domain, language use changes over time. Previous work shows that adapting pretrained language models like BERT to domain through continued pretraining improves performance on in-domain downstream tasks. In this article, we investigate whether adapting BERT to time in addition to domain can increase performance even further. For this purpose, we introduce a benchmark corpus of social media comments sampled over three years. The corpus consists of 36.36m unlabelled comments for adaptation and evaluation on an upstream masked language modelling task as well as 0.9m labelled comments for finetuning and evaluation on a downstream document classification task. We find that temporality matters for both tasks: temporal adaptation improves upstream task performance and temporal finetuning improves downstream task performance. However, we do not find clear evidence that adapting BERT to time and domain improves downstream task performance over just adapting to domain. Temporal adaptation captures changes in language use in the downstream task, but not those changes that are actually relevant to performance on it.
Deep Gated Recurrent and Convolutional Network Hybrid Model for Univariate Time Series Classification
Dec 27, 2018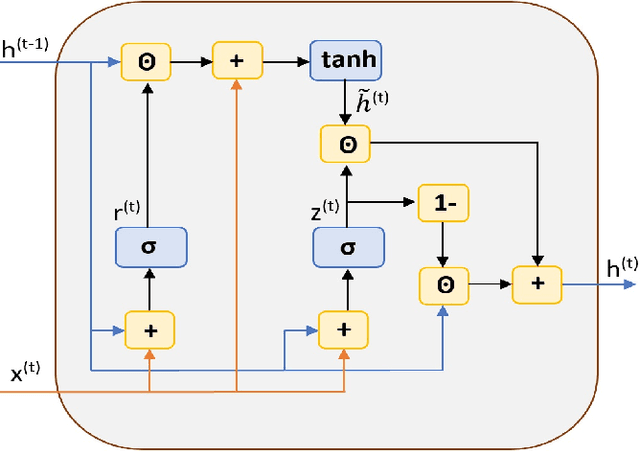
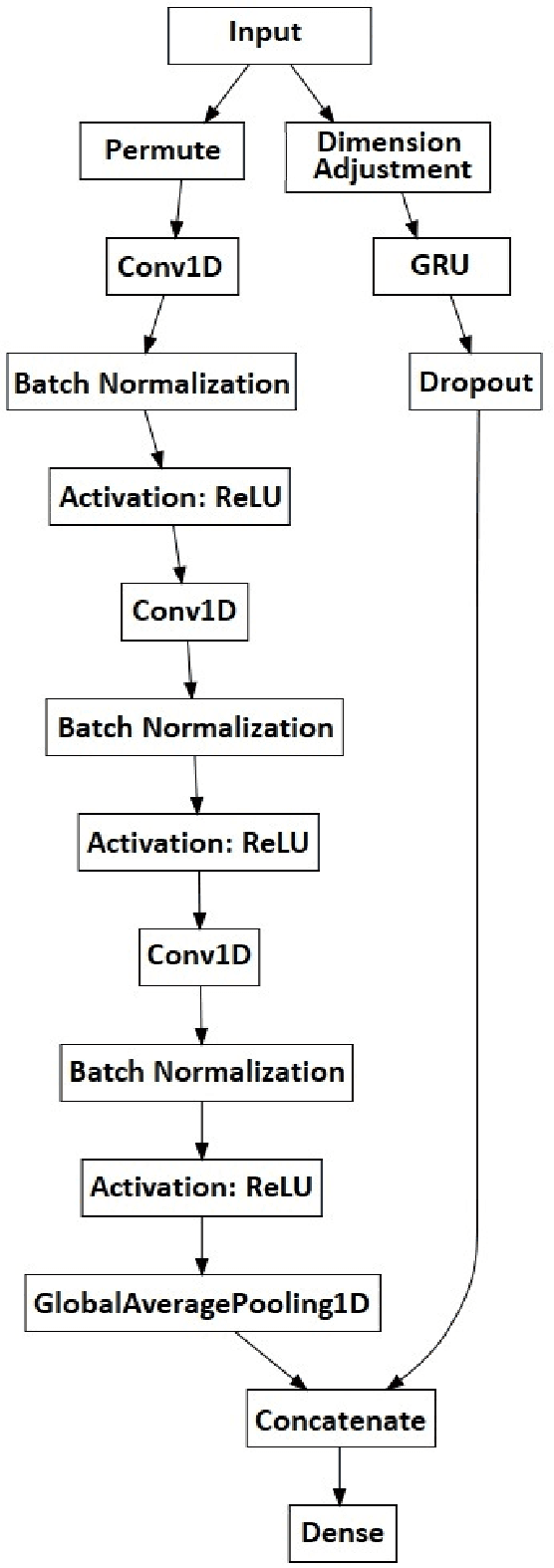
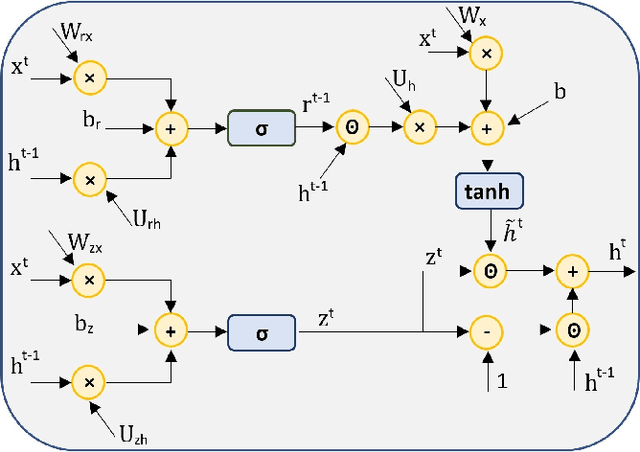
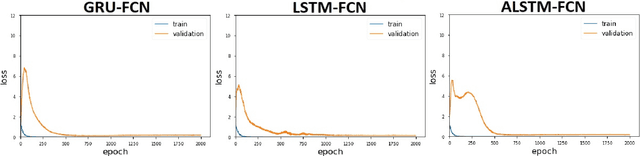
Hybrid LSTM-fully convolutional networks (LSTM-FCN) for time series classification have produced state-of-the-art classification results on univariate time series. We show that replacing the LSTM with a gated recurrent unit (GRU) to create a GRU-fully convolutional network hybrid model (GRU-FCN) can offer even better performance on many time series datasets. The proposed GRU-FCN model outperforms state-of-the-art classification performance in many univariate and multivariate time series datasets. In addition, since the GRU uses a simpler architecture than the LSTM, it has fewer training parameters, less training time, and a simpler hardware implementation, compared to the LSTM-based models.
Short-Term Electricity Price Forecasting based on Graph Convolution Network and Attention Mechanism
Jul 26, 2021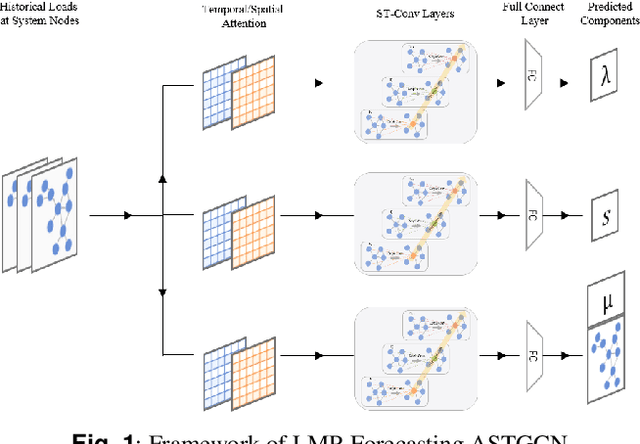
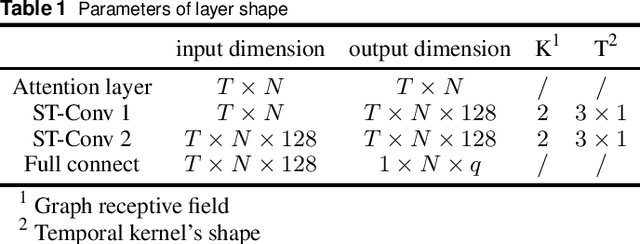
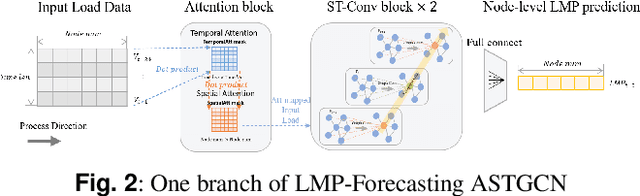

In electricity markets, locational marginal price (LMP) forecasting is particularly important for market participants in making reasonable bidding strategies, managing potential trading risks, and supporting efficient system planning and operation. Unlike existing methods that only consider LMPs' temporal features, this paper tailors a spectral graph convolutional network (GCN) to greatly improve the accuracy of short-term LMP forecasting. A three-branch network structure is then designed to match the structure of LMPs' compositions. Such kind of network can extract the spatial-temporal features of LMPs, and provide fast and high-quality predictions for all nodes simultaneously. The attention mechanism is also implemented to assign varying importance weights between different nodes and time slots. Case studies based on the IEEE-118 test system and real-world data from the PJM validate that the proposed model outperforms existing forecasting models in accuracy, and maintains a robust performance by avoiding extreme errors.
Joint Learning of Deep Retrieval Model and Product Quantization based Embedding Index
May 11, 2021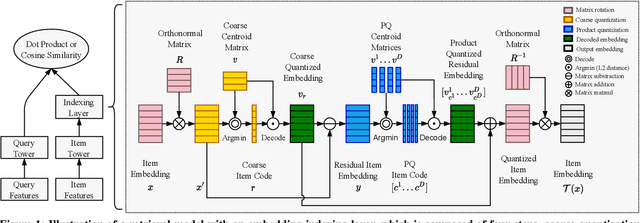
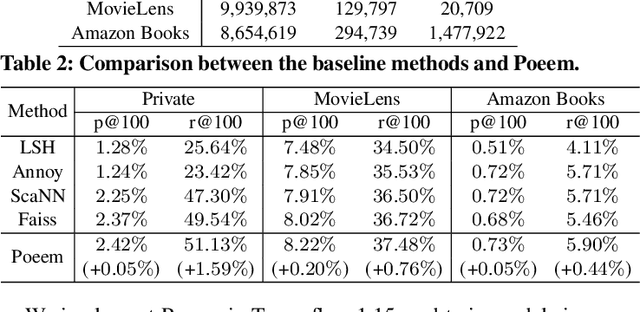
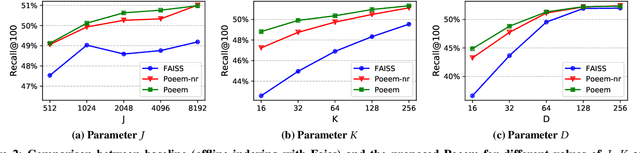
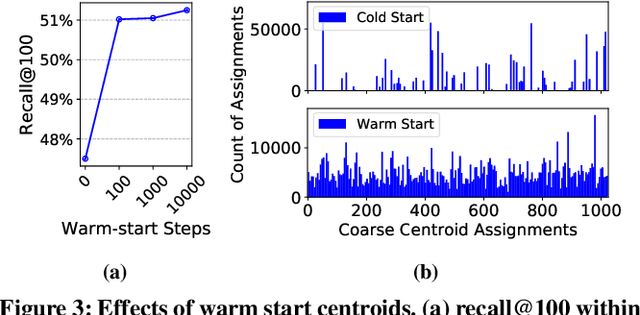
Embedding index that enables fast approximate nearest neighbor(ANN) search, serves as an indispensable component for state-of-the-art deep retrieval systems. Traditional approaches, often separating the two steps of embedding learning and index building, incur additional indexing time and decayed retrieval accuracy. In this paper, we propose a novel method called Poeem, which stands for product quantization based embedding index jointly trained with deep retrieval model, to unify the two separate steps within an end-to-end training, by utilizing a few techniques including the gradient straight-through estimator, warm start strategy, optimal space decomposition and Givens rotation. Extensive experimental results show that the proposed method not only improves retrieval accuracy significantly but also reduces the indexing time to almost none. We have open sourced our approach for the sake of comparison and reproducibility.
Activity Recognition for Autism Diagnosis
Aug 25, 2021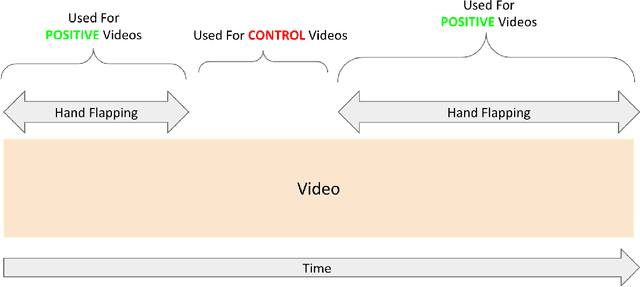
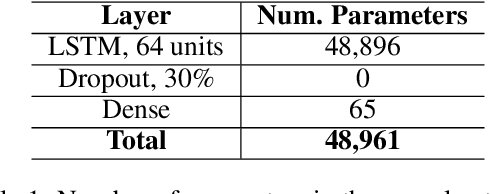


A formal autism diagnosis is an inefficient and lengthy process. Families often have to wait years before receiving a diagnosis for their child; some may not receive one at all due to this delay. One approach to this problem is to use digital technologies to detect the presence of behaviors related to autism, which in aggregate may lead to remote and automated diagnostics. One of the strongest indicators of autism is stimming, which is a set of repetitive, self-stimulatory behaviors such as hand flapping, headbanging, and spinning. Using computer vision to detect hand flapping is especially difficult due to the sparsity of public training data in this space and excessive shakiness and motion in such data. Our work demonstrates a novel method that overcomes these issues: we use hand landmark detection over time as a feature representation which is then fed into a Long Short-Term Memory (LSTM) model. We achieve a validation accuracy and F1 Score of about 72% on detecting whether videos from the Self-Stimulatory Behaviour Dataset (SSBD) contain hand flapping or not. Our best model also predicts accurately on external videos we recorded of ourselves outside of the dataset it was trained on. This model uses less than 26,000 parameters, providing promise for fast deployment into ubiquitous and wearable digital settings for a remote autism diagnosis.
Future semantic segmentation of time-lapsed videos with large temporal displacement
Dec 27, 2018

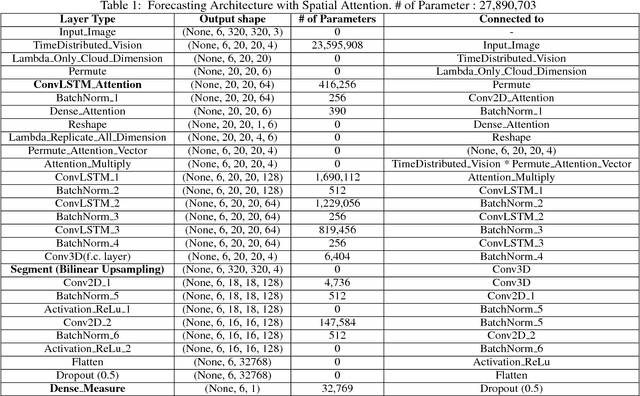
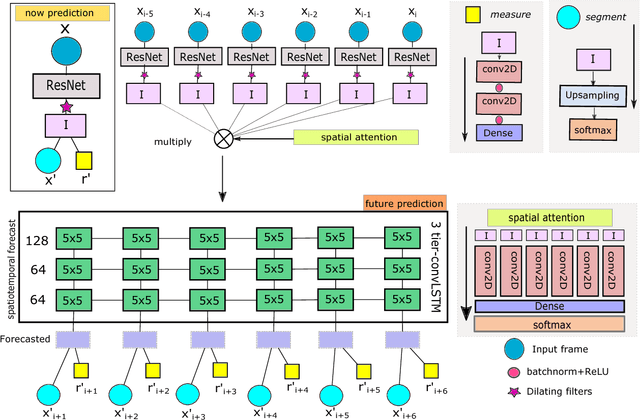
An important aspect of video understanding is the ability to predict the evolution of its content in the future. This paper presents a future frame semantic segmentation technique for predicting semantic masks of the current and future frames in a time-lapsed video. We specifically focus on time-lapsed videos with large temporal displacement to highlight the model's ability to capture large motions in time. We first introduce a unique semantic segmentation prediction dataset with over 120,000 time-lapsed sky-video frames and all corresponding semantic masks captured over a span of five years in North America region. The dataset has immense practical value for cloud cover analysis, which are treated as non-rigid objects of interest. %Here the model provides both semantic segmentation of cloud region and solar irradiance emitted from a region from the sky-videos. Next, our proposed recurrent network architecture departs from existing trend of using temporal convolutional networks (TCN) (or feed-forward networks), by explicitly learning an internal representations for the evolution of video content with time. Experimental evaluation shows an improvement of mean IoU over TCNs in the segmentation task by 10.8% for 10 mins (21% over 60 mins) ahead of time predictions. Further, our model simultaneously measures both the current and future solar irradiance from the same video frames with a normalized-MAE of 10.5% over two years. These results indicate that recurrent memory networks with attention mechanism are able to capture complex advective and diffused flow characteristic of dense fluids even with sparse temporal sampling and are more suitable for future frame prediction tasks for longer duration videos.
Tackling the Overestimation of Forest Carbon with Deep Learning and Aerial Imagery
Aug 19, 2021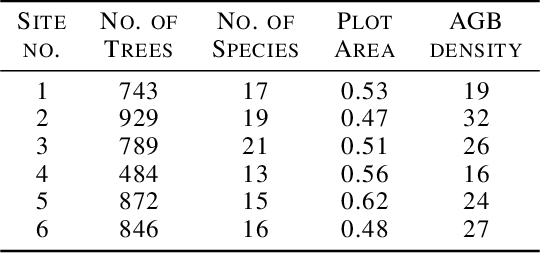
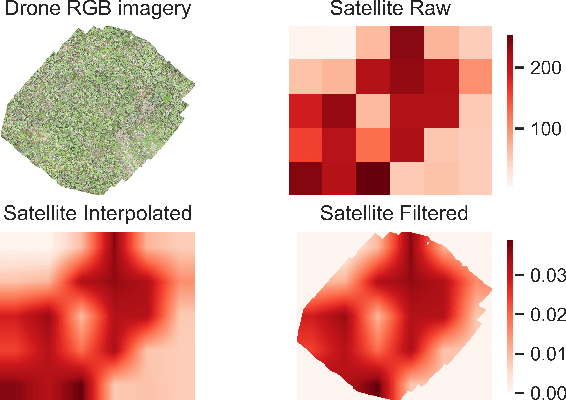
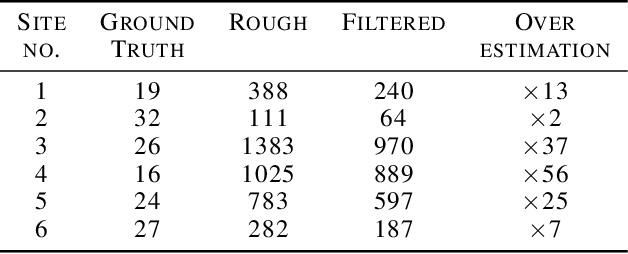
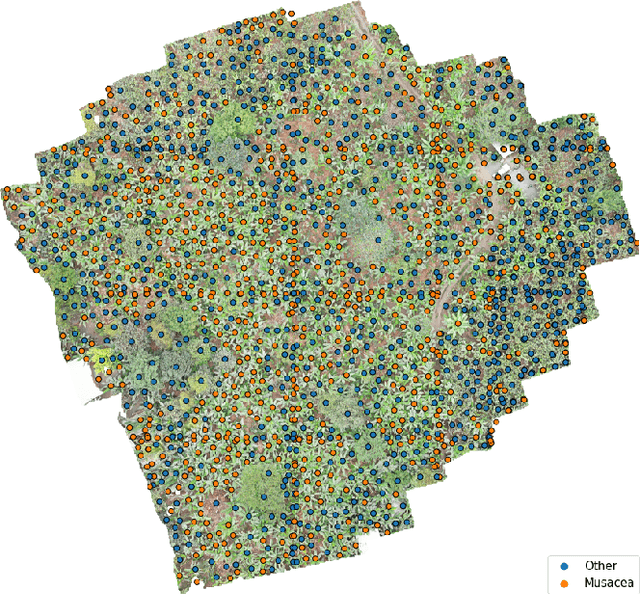
Forest carbon offsets are increasingly popular and can play a significant role in financing climate mitigation, forest conservation, and reforestation. Measuring how much carbon is stored in forests is, however, still largely done via expensive, time-consuming, and sometimes unaccountable field measurements. To overcome these limitations, many verification bodies are leveraging machine learning (ML) algorithms to estimate forest carbon from satellite or aerial imagery. Aerial imagery allows for tree species or family classification, which improves the satellite imagery-based forest type classification. However, aerial imagery is significantly more expensive to collect and it is unclear by how much the higher resolution improves the forest carbon estimation. This proposal paper describes the first systematic comparison of forest carbon estimation from aerial imagery, satellite imagery, and ground-truth field measurements via deep learning-based algorithms for a tropical reforestation project. Our initial results show that forest carbon estimates from satellite imagery can overestimate above-ground biomass by up to 10-times for tropical reforestation projects. The significant difference between aerial and satellite-derived forest carbon measurements shows the potential for aerial imagery-based ML algorithms and raises the importance to extend this study to a global benchmark between options for carbon measurements.
Robust Factorization of Real-world Tensor Streams with Patterns, Missing Values, and Outliers
Feb 16, 2021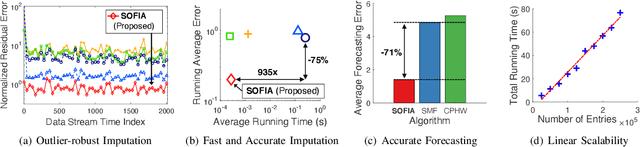
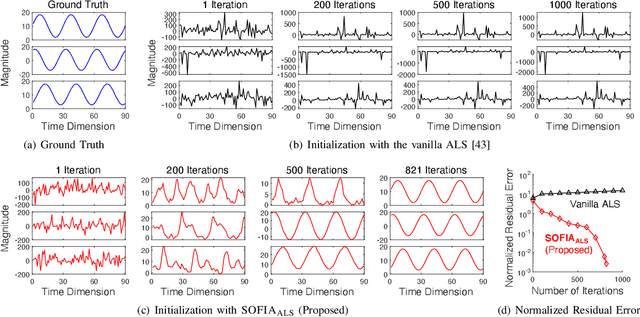
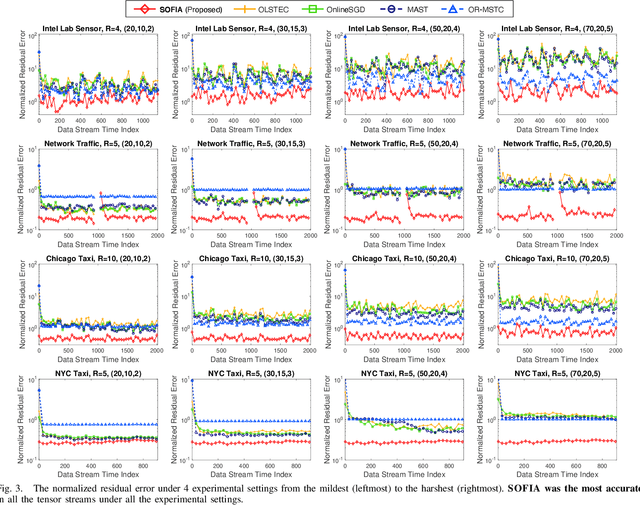
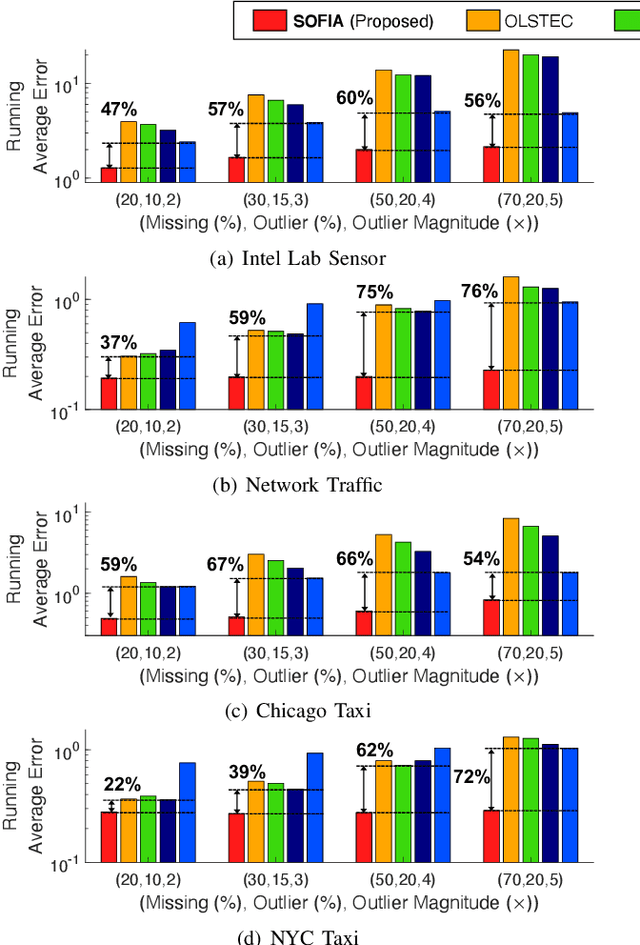
Consider multiple seasonal time series being collected in real-time, in the form of a tensor stream. Real-world tensor streams often include missing entries (e.g., due to network disconnection) and at the same time unexpected outliers (e.g., due to system errors). Given such a real-world tensor stream, how can we estimate missing entries and predict future evolution accurately in real-time? In this work, we answer this question by introducing SOFIA, a robust factorization method for real-world tensor streams. In a nutshell, SOFIA smoothly and tightly integrates tensor factorization, outlier removal, and temporal-pattern detection, which naturally reinforce each other. Moreover, SOFIA integrates them in linear time, in an online manner, despite the presence of missing entries. We experimentally show that SOFIA is (a) robust and accurate: yielding up to 76% lower imputation error and 71% lower forecasting error; (b) fast: up to 935X faster than the second-most accurate competitor; and (c) scalable: scaling linearly with the number of new entries per time step.