 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A multi-stage semi-supervised improved deep embedded clustering (MS-SSIDEC) method for bearing fault diagnosis under the situation of insufficient labeled samples
Sep 28, 2021
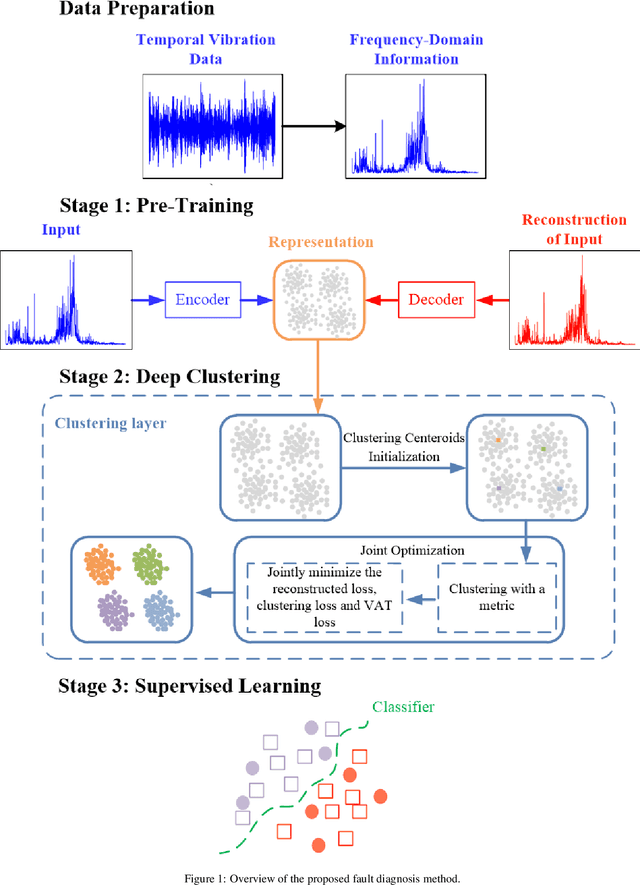
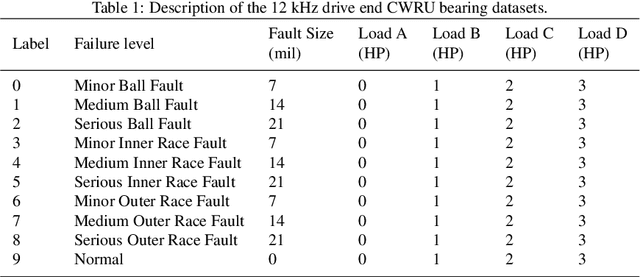
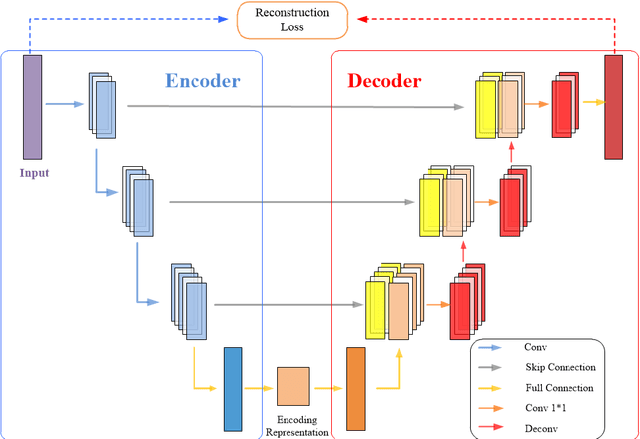
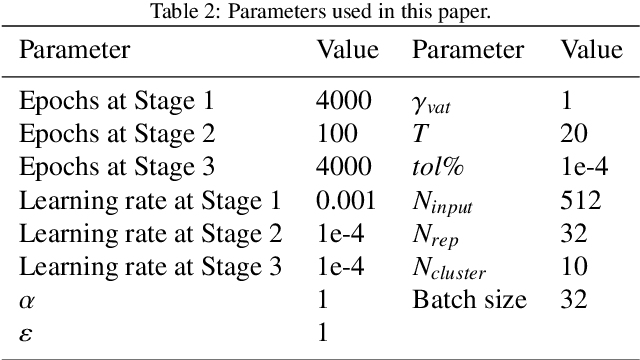
Intelligent data-driven fault diagnosis methods have been widely applied, but most of these methods need a large number of high-quality labeled samples. It costs a lot of labor and time to label data in actual industrial processes, which challenges the application of intelligent fault diagnosis methods. To solve this problem, a multi-stage semi-supervised improved deep embedded clustering (MS-SSIDEC) method is proposed for the bearing fault diagnosis under the insufficient labeled samples situation. This method includes three stages: pre-training, deep clustering and enhanced supervised learning. In the first stage, a skip-connection based convolutional auto-encoder (SCCAE) is proposed and pre-trained to automatically learn low-dimensional representations. In the second stage, a semi-supervised improved deep embedded clustering (SSIDEC) model that integrates the pre-trained auto-encoder with a clustering layer is proposed for deep clustering. Additionally, virtual adversarial training (VAT) is introduced as a regularization term to overcome the overfitting in the model's training. In the third stage, high-quality clustering results obtained in the second stage are assigned to unlabeled samples as pseudo labels. The labeled dataset is augmented by those pseudo-labeled samples and used to train a bearing fault discriminative model. The effectiveness of the method is evaluated on the Case Western Reserve University (CWRU) bearing dataset. The results show that the method can not only satisfy the semi-supervised learning under a small number of labeled samples, but also solve the problem of unsupervised learning, and has achieved better results than traditional diagnosis methods. This method provides a new research idea for fault diagnosis with limited labeled samples by effectively using unsupervised data.
LightMove: A Lightweight Next-POI Recommendation for Taxicab Rooftop Advertising
Aug 16, 2021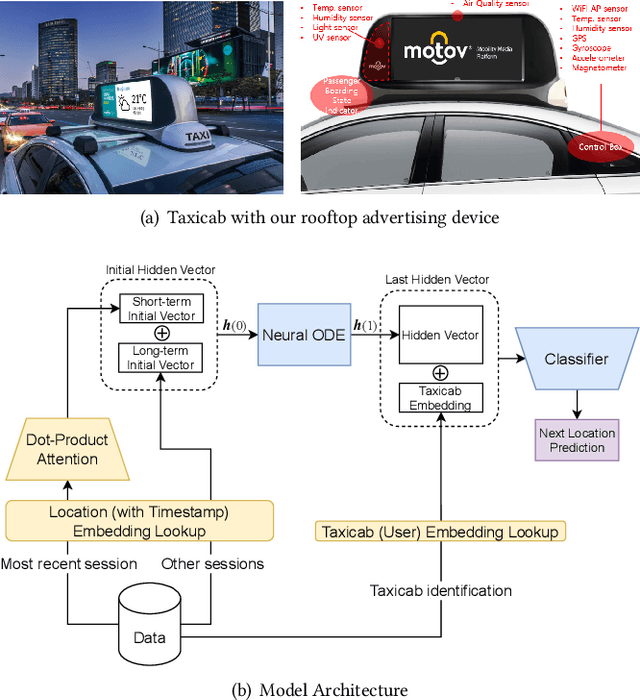

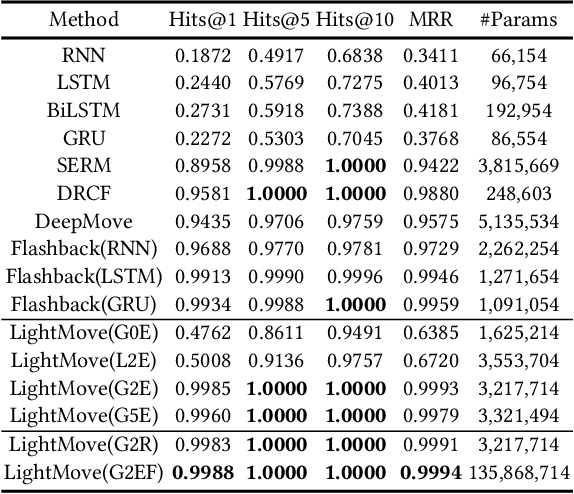
Mobile digital billboards are an effective way to augment brand-awareness. Among various such mobile billboards, taxicab rooftop devices are emerging in the market as a brand new media. Motov is a leading company in South Korea in the taxicab rooftop advertising market. In this work, we present a lightweight yet accurate deep learning-based method to predict taxicabs' next locations to better prepare for targeted advertising based on demographic information of locations. Considering the fact that next POI recommendation datasets are frequently sparse, we design our presented model based on neural ordinary differential equations (NODEs), which are known to be robust to sparse/incorrect input, with several enhancements. Our model, which we call LightMove, has a larger prediction accuracy, a smaller number of parameters, and/or a smaller training/inference time, when evaluating with various datasets, in comparison with state-of-the-art models.
Change is Everywhere: Single-Temporal Supervised Object Change Detection in Remote Sensing Imagery
Aug 16, 2021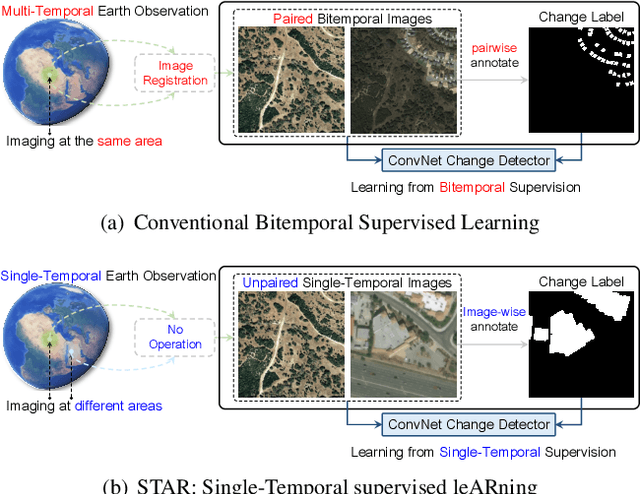
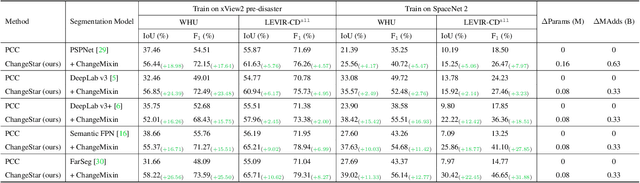

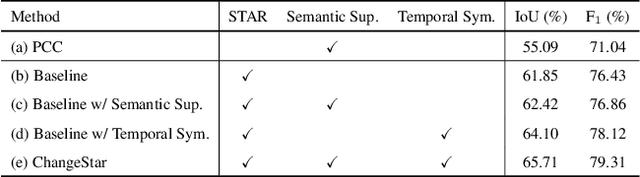
For high spatial resolution (HSR) remote sensing images, bitemporal supervised learning always dominates change detection using many pairwise labeled bitemporal images. However, it is very expensive and time-consuming to pairwise label large-scale bitemporal HSR remote sensing images. In this paper, we propose single-temporal supervised learning (STAR) for change detection from a new perspective of exploiting object changes in unpaired images as supervisory signals. STAR enables us to train a high-accuracy change detector only using \textbf{unpaired} labeled images and generalize to real-world bitemporal images. To evaluate the effectiveness of STAR, we design a simple yet effective change detector called ChangeStar, which can reuse any deep semantic segmentation architecture by the ChangeMixin module. The comprehensive experimental results show that ChangeStar outperforms the baseline with a large margin under single-temporal supervision and achieves superior performance under bitemporal supervision. Code is available at https://github.com/Z-Zheng/ChangeStar
Addressing the IEEE AV Test Challenge with Scenic and VerifAI
Aug 20, 2021

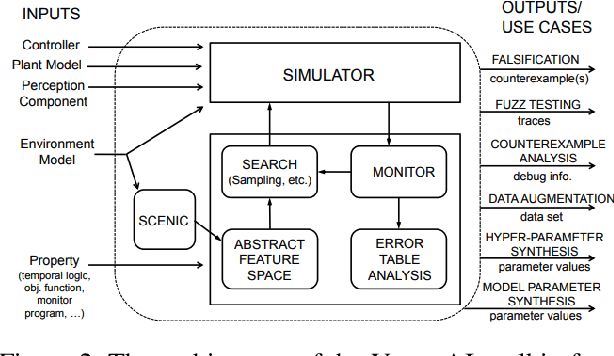
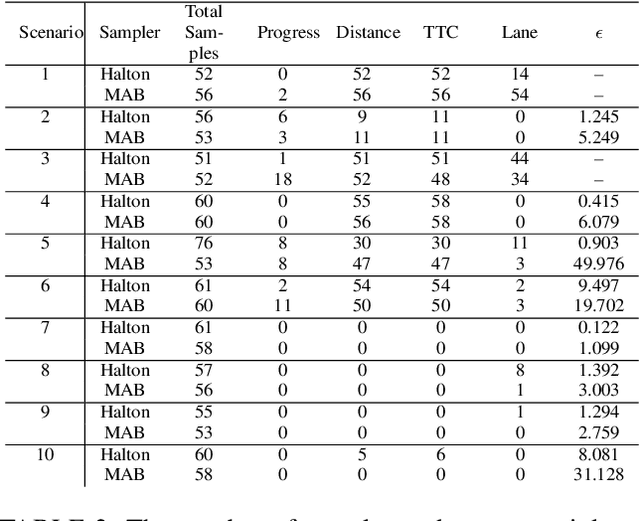
This paper summarizes our formal approach to testing autonomous vehicles (AVs) in simulation for the IEEE AV Test Challenge. We demonstrate a systematic testing framework leveraging our previous work on formally-driven simulation for intelligent cyber-physical systems. First, to model and generate interactive scenarios involving multiple agents, we used Scenic, a probabilistic programming language for specifying scenarios. A Scenic program defines an abstract scenario as a distribution over configurations of physical objects and their behaviors over time. Sampling from an abstract scenario yields many different concrete scenarios which can be run as test cases for the AV. Starting from a Scenic program encoding an abstract driving scenario, we can use the VerifAI toolkit to search within the scenario for failure cases with respect to multiple AV evaluation metrics. We demonstrate the effectiveness of our testing framework by identifying concrete failure scenarios for an open-source autopilot, Apollo, starting from a variety of realistic traffic scenarios.
Automated Generation of Accurate \& Fluent Medical X-ray Reports
Aug 27, 2021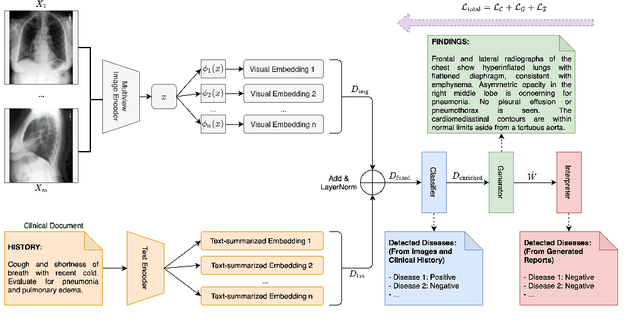
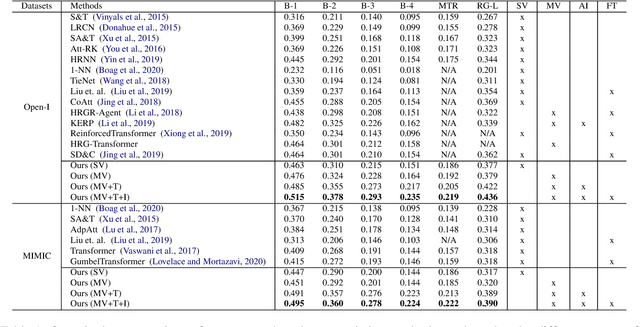
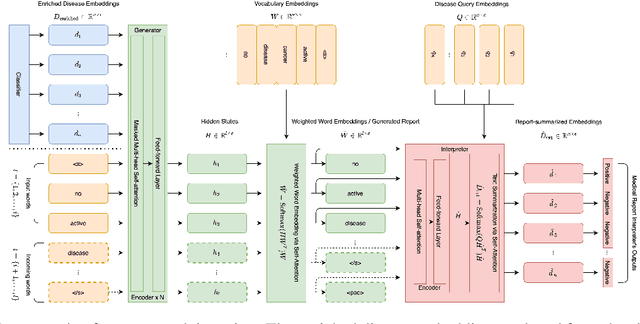
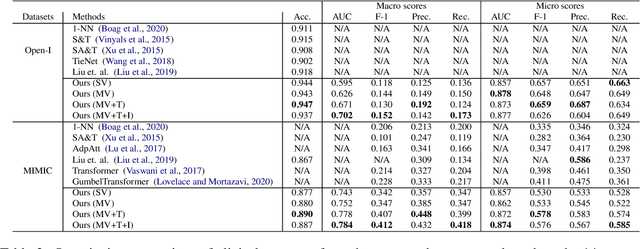
Our paper focuses on automating the generation of medical reports from chest X-ray image inputs, a critical yet time-consuming task for radiologists. Unlike existing medical re-port generation efforts that tend to produce human-readable reports, we aim to generate medical reports that are both fluent and clinically accurate. This is achieved by our fully differentiable and end-to-end paradigm containing three complementary modules: taking the chest X-ray images and clinical his-tory document of patients as inputs, our classification module produces an internal check-list of disease-related topics, referred to as enriched disease embedding; the embedding representation is then passed to our transformer-based generator, giving rise to the medical reports; meanwhile, our generator also pro-duces the weighted embedding representation, which is fed to our interpreter to ensure consistency with respect to disease-related topics.Our approach achieved promising results on commonly-used metrics concerning language fluency and clinical accuracy. Moreover, noticeable performance gains are consistently ob-served when additional input information is available, such as the clinical document and extra scans of different views.
SLIDE: Single Image 3D Photography with Soft Layering and Depth-aware Inpainting
Sep 02, 2021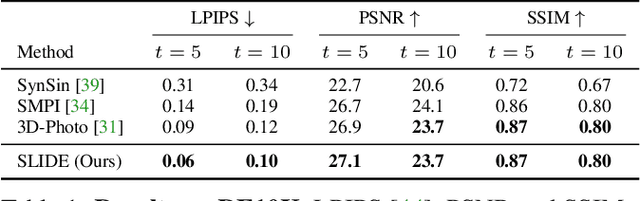
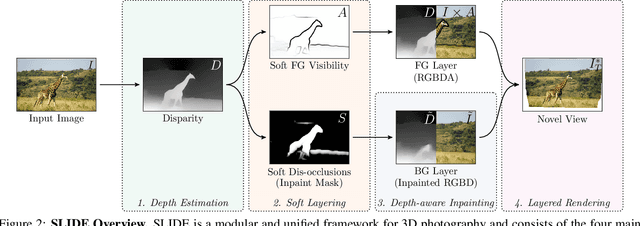
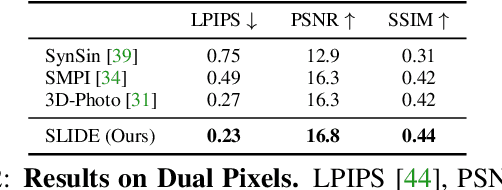

Single image 3D photography enables viewers to view a still image from novel viewpoints. Recent approaches combine monocular depth networks with inpainting networks to achieve compelling results. A drawback of these techniques is the use of hard depth layering, making them unable to model intricate appearance details such as thin hair-like structures. We present SLIDE, a modular and unified system for single image 3D photography that uses a simple yet effective soft layering strategy to better preserve appearance details in novel views. In addition, we propose a novel depth-aware training strategy for our inpainting module, better suited for the 3D photography task. The resulting SLIDE approach is modular, enabling the use of other components such as segmentation and matting for improved layering. At the same time, SLIDE uses an efficient layered depth formulation that only requires a single forward pass through the component networks to produce high quality 3D photos. Extensive experimental analysis on three view-synthesis datasets, in combination with user studies on in-the-wild image collections, demonstrate superior performance of our technique in comparison to existing strong baselines while being conceptually much simpler. Project page: https://varunjampani.github.io/slide
Recognition Awareness: An Application of Latent Cognizance to Open-Set Recognition
Aug 27, 2021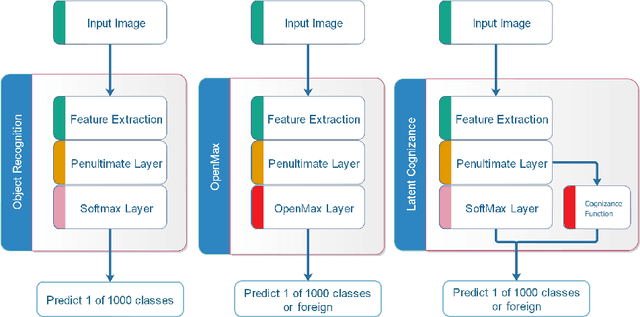

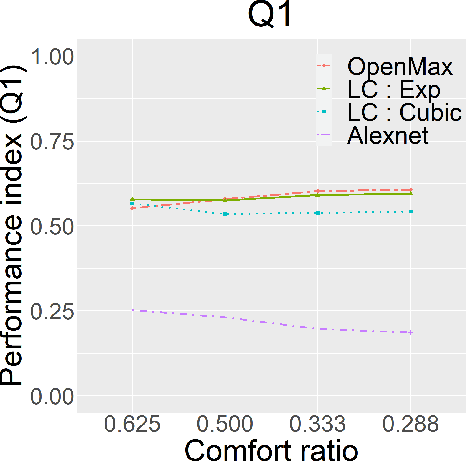
This study investigates an application of a new probabilistic interpretation of a softmax output to Open-Set Recognition (OSR). Softmax is a mechanism wildly used in classification and object recognition. However, a softmax mechanism forces a model to operate under a closed-set paradigm, i.e., to predict an object class out of a set of pre-defined labels. This characteristic contributes to efficacy in classification, but poses a risk of non-sense prediction in object recognition. Object recognition is often operated under a dynamic and diverse condition. A foreign object -- an object of any unprepared class -- can be encountered at any time. OSR is intended to address an issue of identifying a foreign object in object recognition. Based on Bayes theorem and the emphasis of conditioning on the context, softmax inference has been re-interpreted. This re-interpretation has led to a new approach to OSR, called Latent Cognizance (LC). Our investigation employs various scenarios, using Imagenet 2012 dataset as well as fooling and open-set images. The findings support LC hypothesis and show its effectiveness on OSR.
Dynamic Scene Novel View Synthesis via Deferred Spatio-temporal Consistency
Sep 02, 2021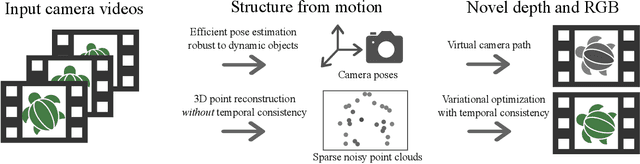


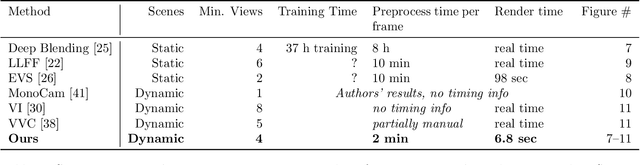
Structure from motion (SfM) enables us to reconstruct a scene via casual capture from cameras at different viewpoints, and novel view synthesis (NVS) allows us to render a captured scene from a new viewpoint. Both are hard with casual capture and dynamic scenes: SfM produces noisy and spatio-temporally sparse reconstructed point clouds, resulting in NVS with spatio-temporally inconsistent effects. We consider SfM and NVS parts together to ease the challenge. First, for SfM, we recover stable camera poses, then we defer the requirement for temporally-consistent points across the scene and reconstruct only a sparse point cloud per timestep that is noisy in space-time. Second, for NVS, we present a variational diffusion formulation on depths and colors that lets us robustly cope with the noise by enforcing spatio-temporal consistency via per-pixel reprojection weights derived from the input views. Together, this deferred approach generates novel views for dynamic scenes without requiring challenging spatio-temporally consistent reconstructions nor training complex models on large datasets. We demonstrate our algorithm on real-world dynamic scenes against classic and more recent learning-based baseline approaches.
Self-Supervised Structure-from-Motion through Tightly-Coupled Depth and Egomotion Networks
Jun 07, 2021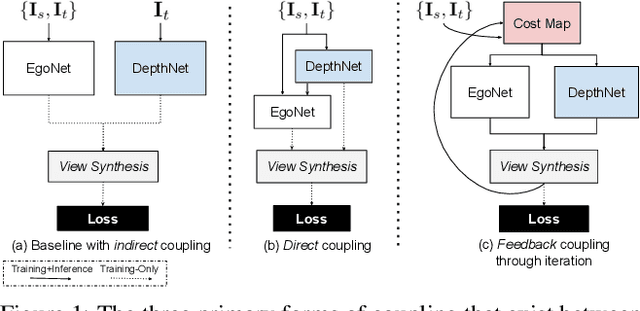
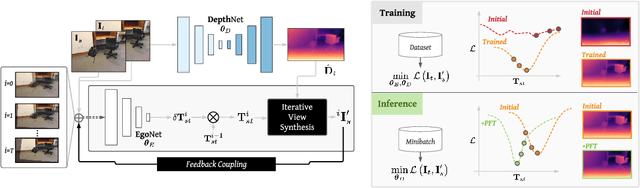
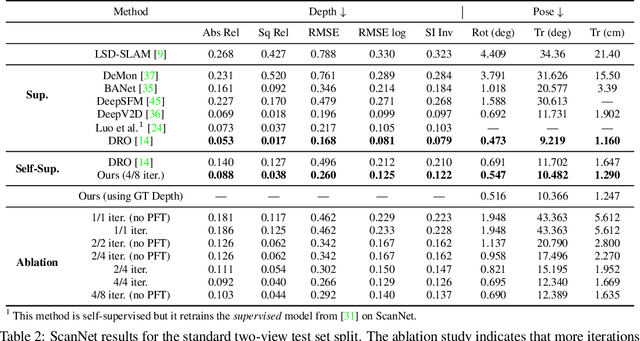

Much recent literature has formulated structure-from-motion (SfM) as a self-supervised learning problem where the goal is to jointly learn neural network models of depth and egomotion through view synthesis. Herein, we address the open problem of how to optimally couple the depth and egomotion network components. Toward this end, we introduce several notions of coupling, categorize existing approaches, and present a novel tightly-coupled approach that leverages the interdependence of depth and egomotion at training and at inference time. Our approach uses iterative view synthesis to recursively update the egomotion network input, permitting contextual information to be passed between the components without explicit weight sharing. Through substantial experiments, we demonstrate that our approach promotes consistency between the depth and egomotion predictions at test time, improves generalization on new data, and leads to state-of-the-art accuracy on indoor and outdoor depth and egomotion evaluation benchmarks.
Aegis: A Trusted, Automatic and Accurate Verification Framework for Vertical Federated Learning
Aug 16, 2021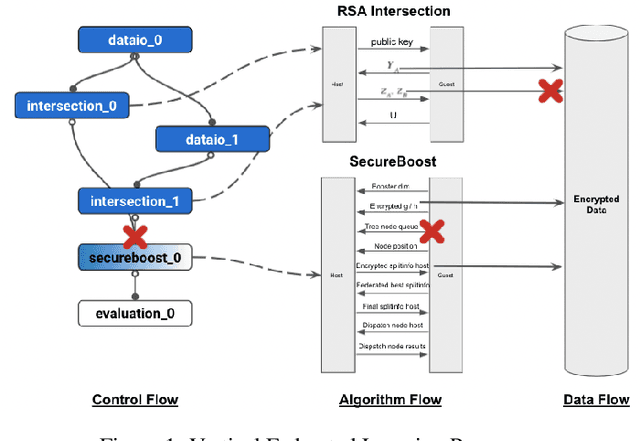
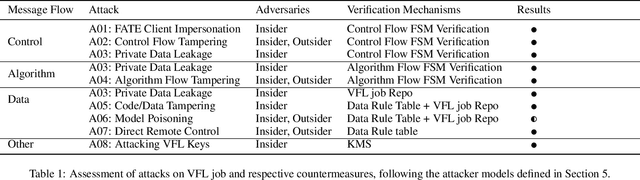
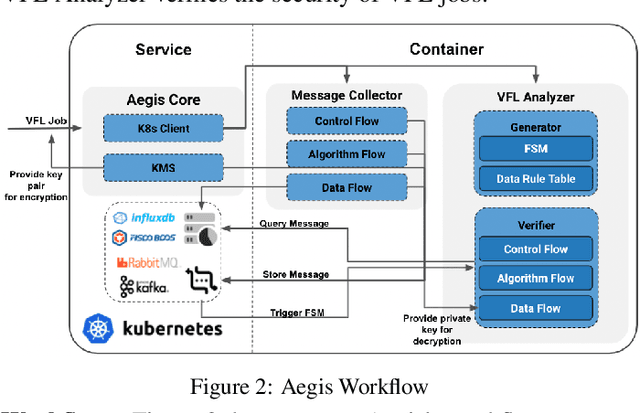
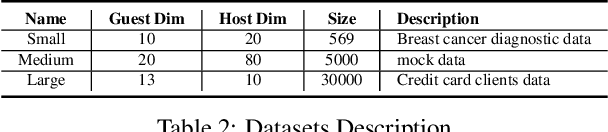
Vertical federated learning (VFL) leverages various privacy-preserving algorithms, e.g., homomorphic encryption or secret sharing based SecureBoost, to ensure data privacy. However, these algorithms all require a semi-honest secure definition, which raises concerns in real-world applications. In this paper, we present Aegis, a trusted, automatic, and accurate verification framework to verify the security of VFL jobs. Aegis is separated from local parties to ensure the security of the framework. Furthermore, it automatically adapts to evolving VFL algorithms by defining the VFL job as a finite state machine to uniformly verify different algorithms and reproduce the entire job to provide more accurate verification. We implement and evaluate Aegis with different threat models on financial and medical datasets. Evaluation results show that: 1) Aegis can detect 95% threat models, and 2) it provides fine-grained verification results within 84% of the total VFL job time.