 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Cross-speaker Emotion Transfer Based on Speaker Condition Layer Normalization and Semi-Supervised Training in Text-To-Speech
Oct 11, 2021
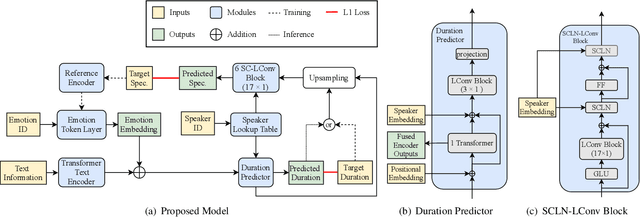
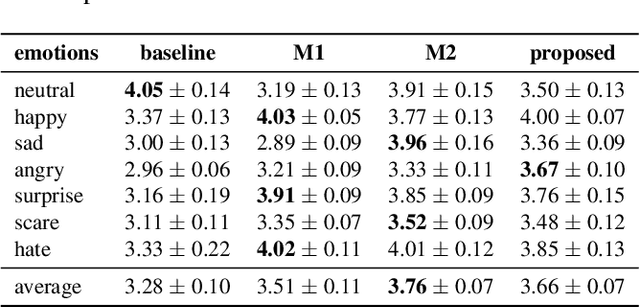
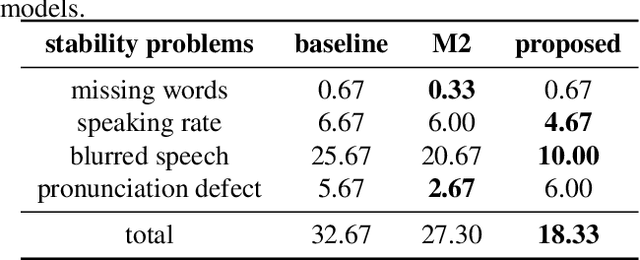
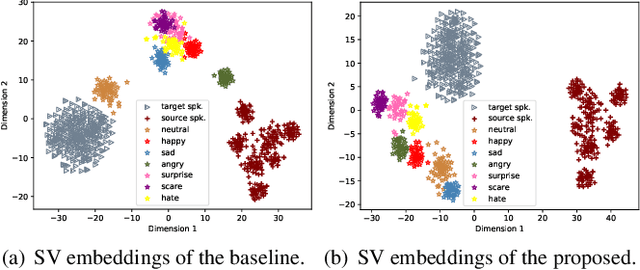
In expressive speech synthesis, there are high requirements for emotion interpretation. However, it is time-consuming to acquire emotional audio corpus for arbitrary speakers due to their deduction ability. In response to this problem, this paper proposes a cross-speaker emotion transfer method that can realize the transfer of emotions from source speaker to target speaker. A set of emotion tokens is firstly defined to represent various categories of emotions. They are trained to be highly correlated with corresponding emotions for controllable synthesis by cross-entropy loss and semi-supervised training strategy. Meanwhile, to eliminate the down-gradation to the timbre similarity from cross-speaker emotion transfer, speaker condition layer normalization is implemented to model speaker characteristics. Experimental results show that the proposed method outperforms the multi-reference based baseline in terms of timbre similarity, stability and emotion perceive evaluations.
Big Data Testing Techniques: Taxonomy, Challenges and Future Trends
Nov 04, 2021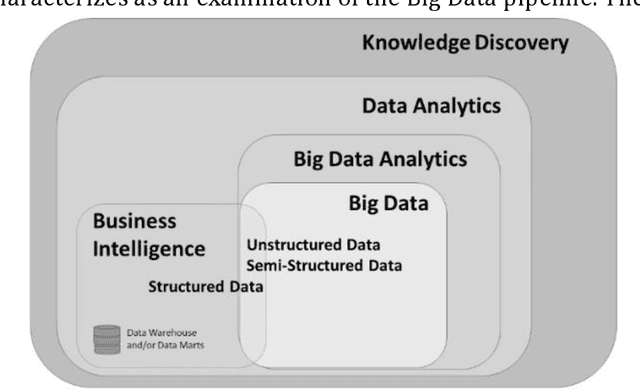
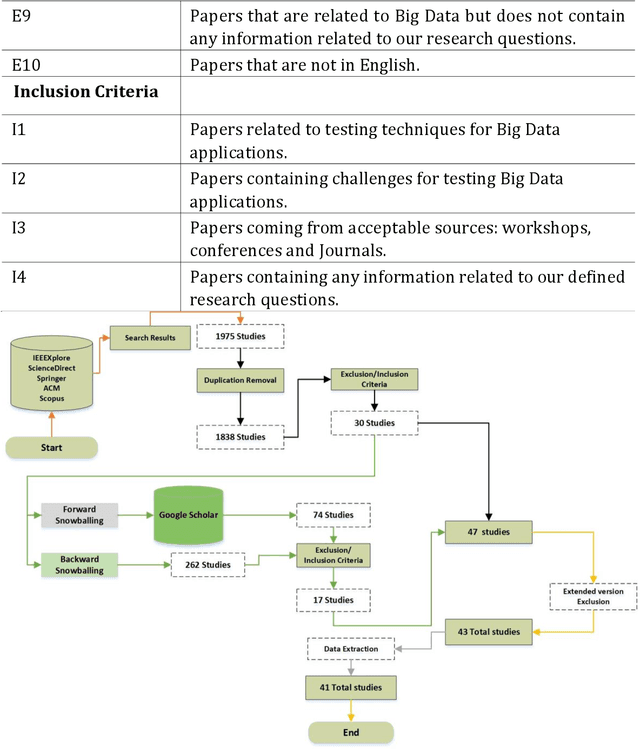
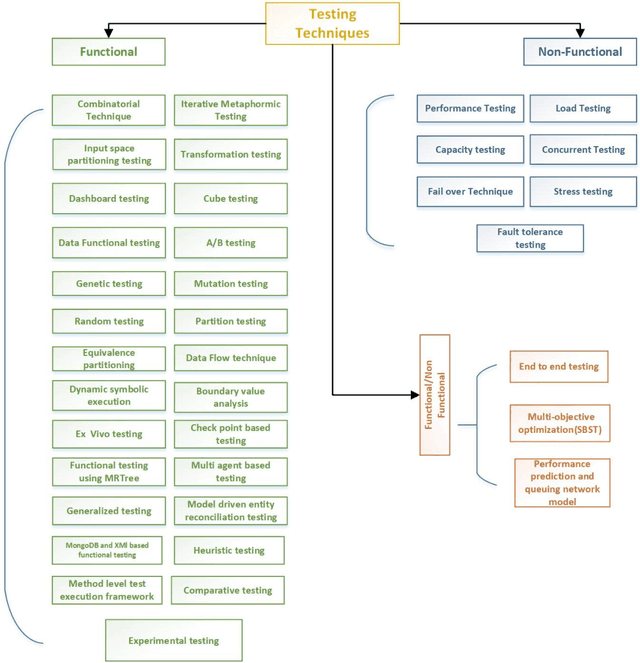

Big Data is reforming many industrial domains by providing decision support through analyzing large volumes of data. Big Data testing aims to ensure that Big Data systems run smoothly and error-free while maintaining the performance and quality of data. However, because of the diversity and complexity of data, testing Big Data is challenging. Though numerous researches deal with Big Data testing, a comprehensive review to address testing techniques and challenges is not conflate yet. Therefore, we have conducted a systematic review of the Big Data testing techniques period (2010 - 2021). This paper discusses the processing of testing data by highlighting the techniques used in every processing phase. Furthermore, we discuss the challenges and future directions. Our finding shows that diverse functional, non-functional and combined (functional and non-functional) testing techniques have been used to solve specific problems related to Big Data. At the same time, most of the testing challenges have been faced during the MapReduce validation phase. In addition, the combinatorial testing technique is one of the most applied techniques in combination with other techniques (i.e., random testing, mutation testing, input space partitioning and equivalence testing) to solve various functional faults challenges faced during Big Data testing.
Deep Learning Approximation of Diffeomorphisms via Linear-Control Systems
Oct 24, 2021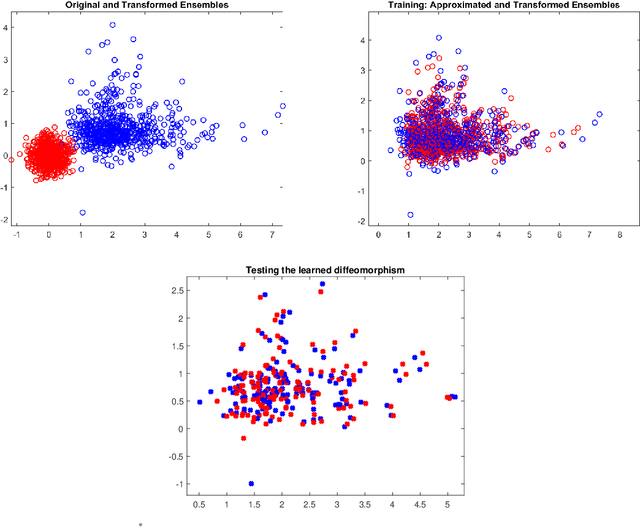
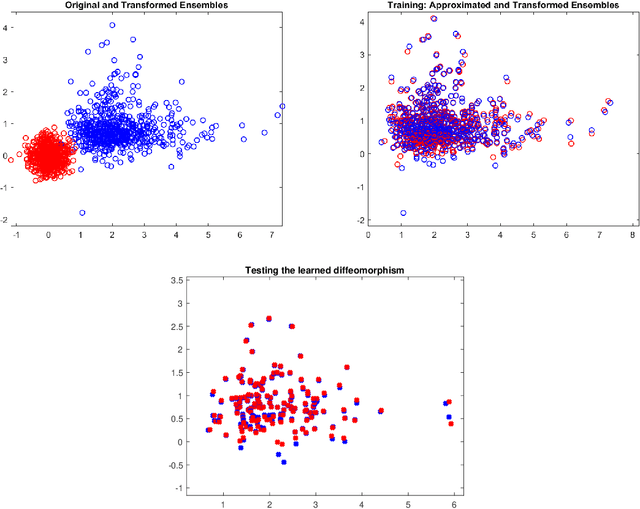
In this paper we propose a Deep Learning architecture to approximate diffeomorphisms isotopic to the identity. We consider a control system of the form $\dot x = \sum_{i=1}^lF_i(x)u_i$, with linear dependence in the controls, and we use the corresponding flow to approximate the action of a diffeomorphism on a compact ensemble of points. Despite the simplicity of the control system, it has been recently shown that a Universal Approximation Property holds. The problem of minimizing the sum of the training error and of a regularizing term induces a gradient flow in the space of admissible controls. A possible training procedure for the discrete-time neural network consists in projecting the gradient flow onto a finite-dimensional subspace of the admissible controls. An alternative approach relies on an iterative method based on Pontryagin Maximum Principle for the numerical resolution of Optimal Control problems. Here the maximization of the Hamiltonian can be carried out with an extremely low computational effort, owing to the linear dependence of the system in the control variables.
Reinforcement Learning Based Sparse Black-box Adversarial Attack on Video Recognition Models
Aug 29, 2021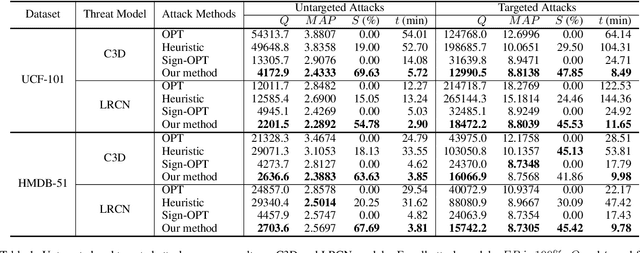

We explore the black-box adversarial attack on video recognition models. Attacks are only performed on selected key regions and key frames to reduce the high computation cost of searching adversarial perturbations on a video due to its high dimensionality. To select key frames, one way is to use heuristic algorithms to evaluate the importance of each frame and choose the essential ones. However, it is time inefficient on sorting and searching. In order to speed up the attack process, we propose a reinforcement learning based frame selection strategy. Specifically, the agent explores the difference between the original class and the target class of videos to make selection decisions. It receives rewards from threat models which indicate the quality of the decisions. Besides, we also use saliency detection to select key regions and only estimate the sign of gradient instead of the gradient itself in zeroth order optimization to further boost the attack process. We can use the trained model directly in the untargeted attack or with little fine-tune in the targeted attack, which saves computation time. A range of empirical results on real datasets demonstrate the effectiveness and efficiency of the proposed method.
* Accepted as a conference paper of IJCAI-21 (the 30th International Joint Conference on Artificial Intelligence)
Stochastic Super-Resolution for Downscaling Time-Evolving Atmospheric Fields with a Generative Adversarial Network
May 20, 2020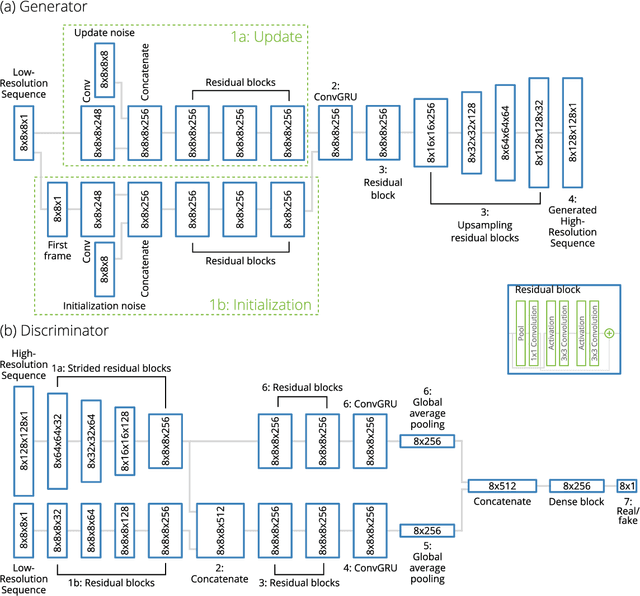
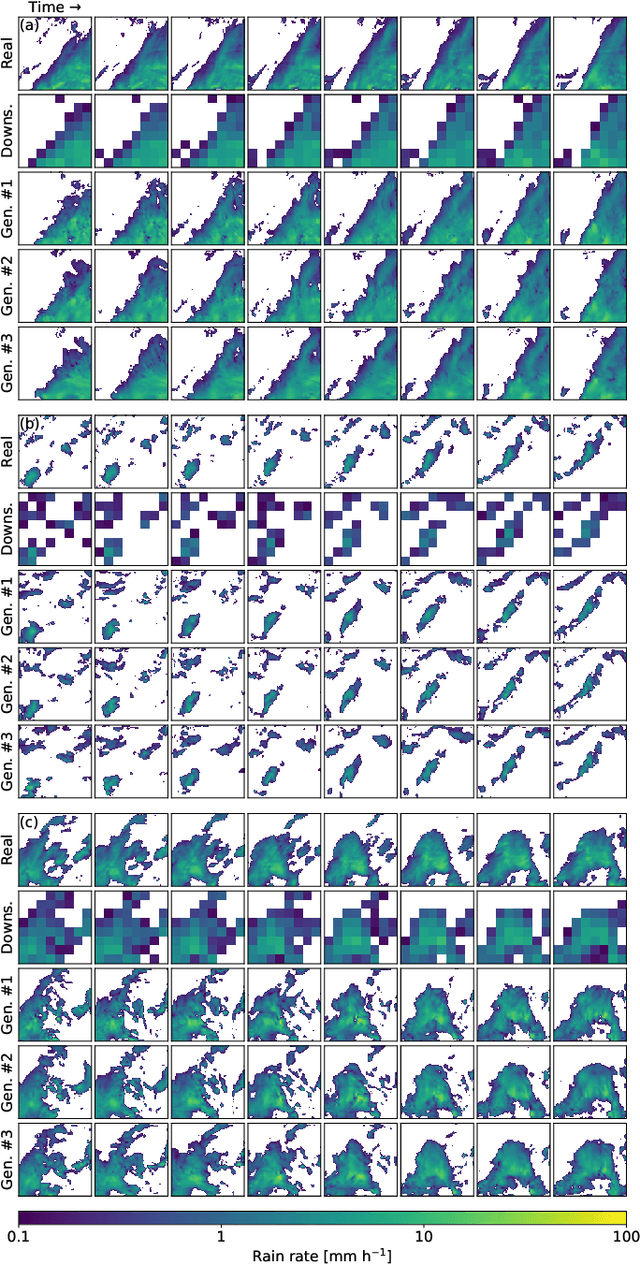
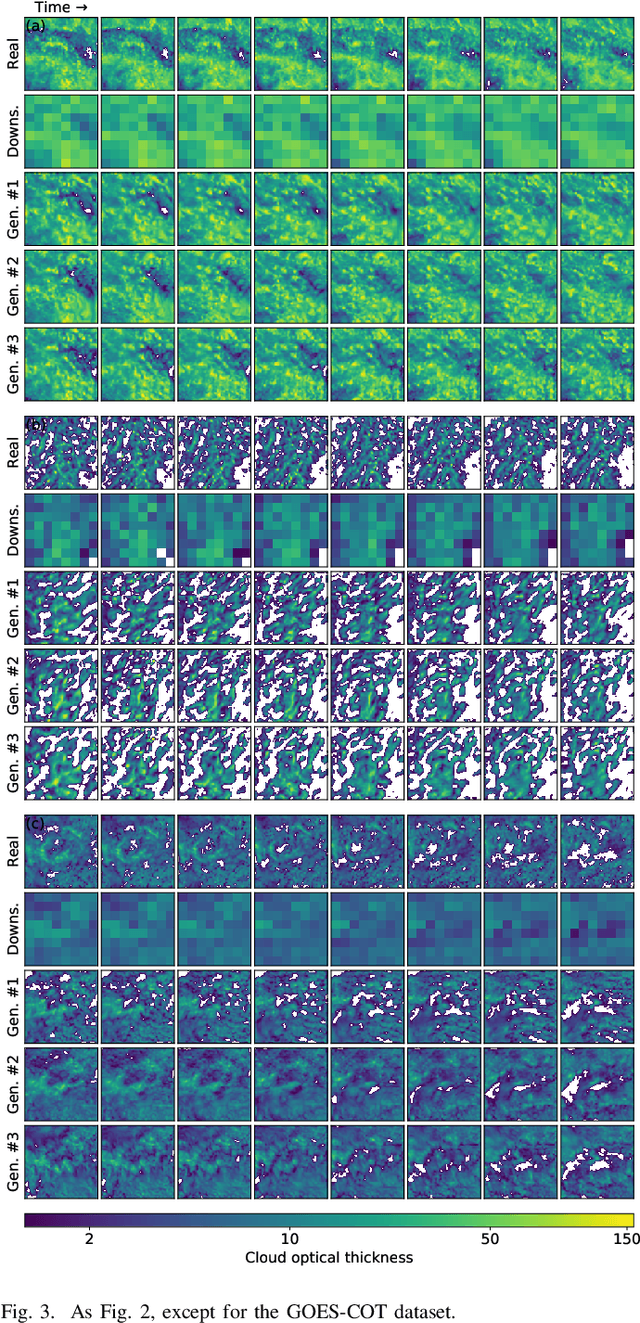
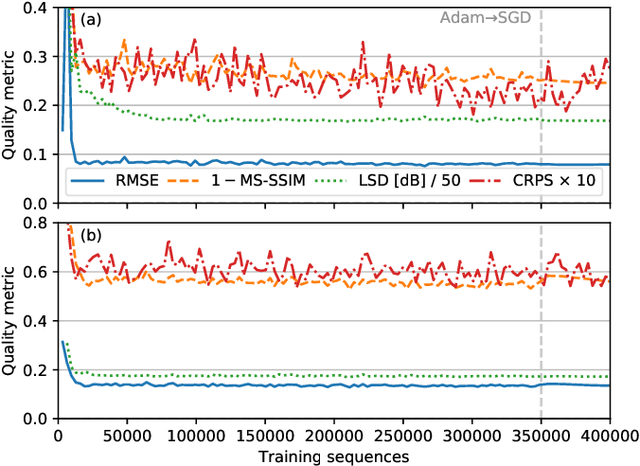
Generative adversarial networks (GANs) have been recently adopted for super-resolution, an application closely related to what is referred to as "downscaling" in the atmospheric sciences. The ability of conditional GANs to generate an ensemble of solutions for a given input lends itself naturally to stochastic downscaling, but the stochastic nature of GANs is not usually considered in super-resolution applications. Here, we introduce a recurrent, stochastic super-resolution GAN that can generate ensembles of time-evolving high-resolution atmospheric fields for an input consisting of a low-resolution sequence of images of the same field. We test the GAN using two datasets, one consisting of radar-measured precipitation from Switzerland, the other of cloud optical thickness derived from the Geostationary Earth Observing Satellite 16 (GOES-16). We find that the GAN can generate realistic, temporally consistent solutions for both datasets. The statistical properties of the generated ensemble are analyzed using rank statistics, a method adapted from ensemble weather forecasting; these analyses indicate that the GAN produces close to the correct amount of variability in its outputs. As the GAN generator is fully convolutional, it can be applied after training to input images larger than the images used to train it. It is also able to generate time series much longer than the training sequences, as demonstrated by applying the generator to a three-month dataset of the precipitation radar data.
Emotion Recognition of the Singing Voice: Toward a Real-Time Analysis Tool for Singers
May 01, 2021

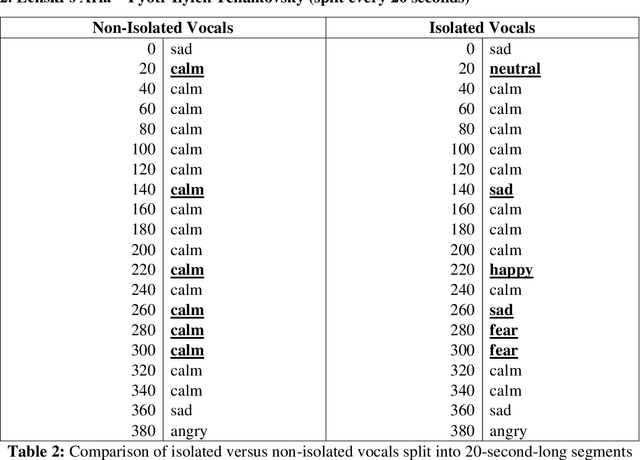
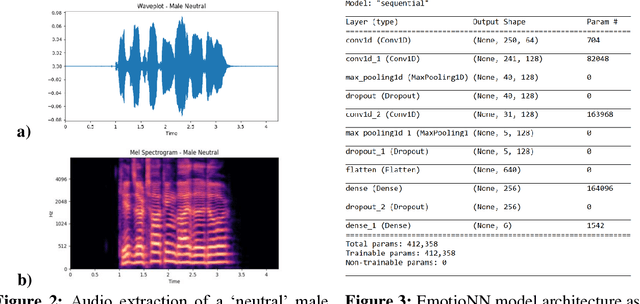
Current computational-emotion research has focused on applying acoustic properties to analyze how emotions are perceived mathematically or used in natural language processing machine learning models. With most recent interest being in analyzing emotions from the spoken voice, little experimentation has been performed to discover how emotions are recognized in the singing voice -- both in noiseless and noisy data (i.e., data that is either inaccurate, difficult to interpret, has corrupted/distorted/nonsense information like actual noise sounds in this case, or has a low ratio of usable/unusable information). Not only does this ignore the challenges of training machine learning models on more subjective data and testing them with much noisier data, but there is also a clear disconnect in progress between advancing the development of convolutional neural networks and the goal of emotionally cognizant artificial intelligence. By training a new model to include this type of information with a rich comprehension of psycho-acoustic properties, not only can models be trained to recognize information within extremely noisy data, but advancement can be made toward more complex biofeedback applications -- including creating a model which could recognize emotions given any human information (language, breath, voice, body, posture) and be used in any performance medium (music, speech, acting) or psychological assistance for patients with disorders such as BPD, alexithymia, autism, among others. This paper seeks to reflect and expand upon the findings of related research and present a stepping-stone toward this end goal.
RAVE: A variational autoencoder for fast and high-quality neural audio synthesis
Nov 09, 2021
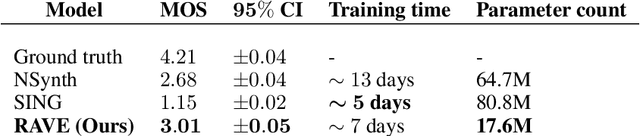
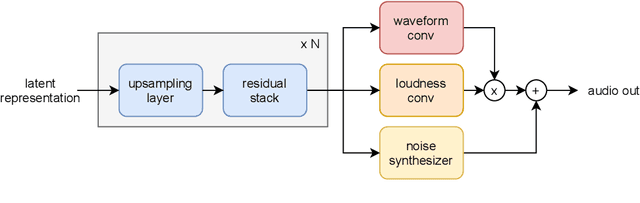

Deep generative models applied to audio have improved by a large margin the state-of-the-art in many speech and music related tasks. However, as raw waveform modelling remains an inherently difficult task, audio generative models are either computationally intensive, rely on low sampling rates, are complicated to control or restrict the nature of possible signals. Among those models, Variational AutoEncoders (VAE) give control over the generation by exposing latent variables, although they usually suffer from low synthesis quality. In this paper, we introduce a Realtime Audio Variational autoEncoder (RAVE) allowing both fast and high-quality audio waveform synthesis. We introduce a novel two-stage training procedure, namely representation learning and adversarial fine-tuning. We show that using a post-training analysis of the latent space allows a direct control between the reconstruction fidelity and the representation compactness. By leveraging a multi-band decomposition of the raw waveform, we show that our model is the first able to generate 48kHz audio signals, while simultaneously running 20 times faster than real-time on a standard laptop CPU. We evaluate synthesis quality using both quantitative and qualitative subjective experiments and show the superiority of our approach compared to existing models. Finally, we present applications of our model for timbre transfer and signal compression. All of our source code and audio examples are publicly available.
Using Interaction Data to Predict Engagement with Interactive Media
Aug 04, 2021
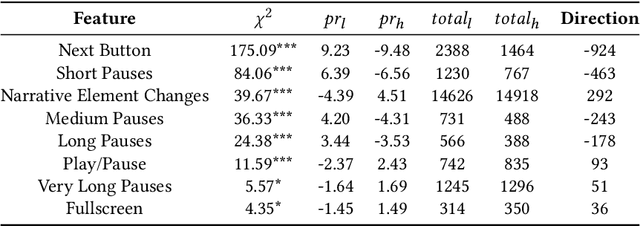
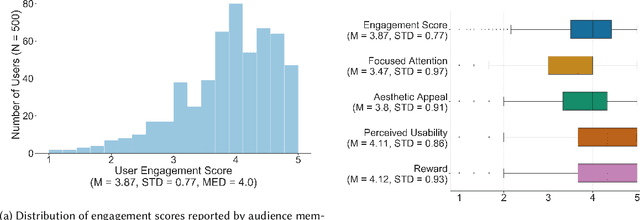
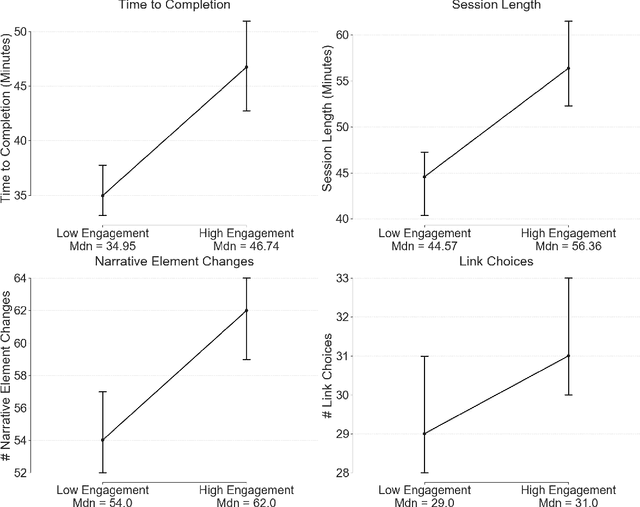
Media is evolving from traditional linear narratives to personalised experiences, where control over information (or how it is presented) is given to individual audience members. Measuring and understanding audience engagement with this media is important in at least two ways: (1) a post-hoc understanding of how engaged audiences are with the content will help production teams learn from experience and improve future productions; (2), this type of media has potential for real-time measures of engagement to be used to enhance the user experience by adapting content on-the-fly. Engagement is typically measured by asking samples of users to self-report, which is time consuming and expensive. In some domains, however, interaction data have been used to infer engagement. Fortuitously, the nature of interactive media facilitates a much richer set of interaction data than traditional media; our research aims to understand if these data can be used to infer audience engagement. In this paper, we report a study using data captured from audience interactions with an interactive TV show to model and predict engagement. We find that temporal metrics, including overall time spent on the experience and the interval between events, are predictive of engagement. The results demonstrate that interaction data can be used to infer users' engagement during and after an experience, and the proposed techniques are relevant to better understand audience preference and responses.
Highly Scalable and Provably Accurate Classification in Poincare Balls
Sep 09, 2021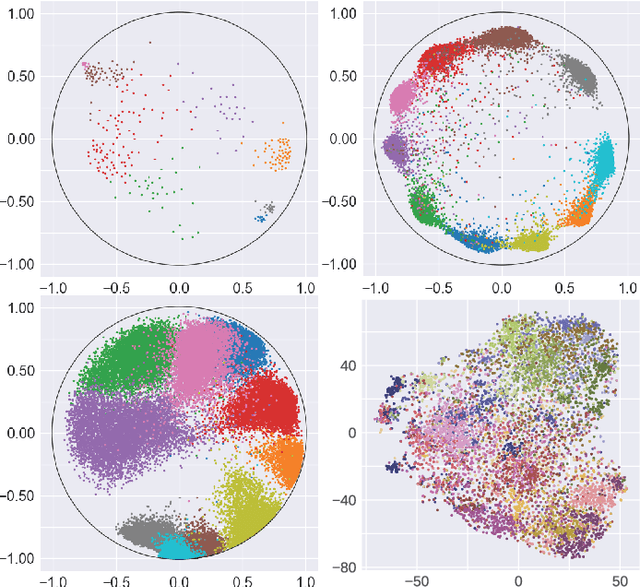
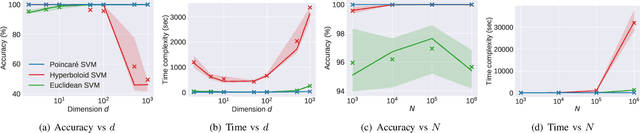
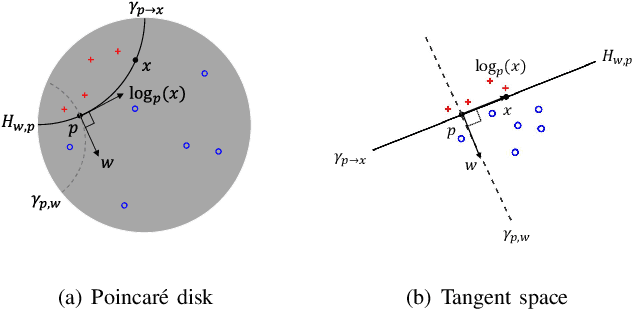
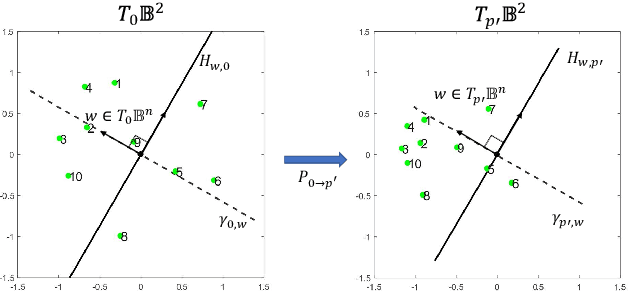
Many high-dimensional and large-volume data sets of practical relevance have hierarchical structures induced by trees, graphs or time series. Such data sets are hard to process in Euclidean spaces and one often seeks low-dimensional embeddings in other space forms to perform required learning tasks. For hierarchical data, the space of choice is a hyperbolic space since it guarantees low-distortion embeddings for tree-like structures. Unfortunately, the geometry of hyperbolic spaces has properties not encountered in Euclidean spaces that pose challenges when trying to rigorously analyze algorithmic solutions. Here, for the first time, we establish a unified framework for learning scalable and simple hyperbolic linear classifiers with provable performance guarantees. The gist of our approach is to focus on Poincar\'e ball models and formulate the classification problems using tangent space formalisms. Our results include a new hyperbolic and second-order perceptron algorithm as well as an efficient and highly accurate convex optimization setup for hyperbolic support vector machine classifiers. All algorithms provably converge and are highly scalable as they have complexities comparable to those of their Euclidean counterparts. Their performance accuracies on synthetic data sets comprising millions of points, as well as on complex real-world data sets such as single-cell RNA-seq expression measurements, CIFAR10, Fashion-MNIST and mini-ImageNet.
PDBL: Improving Histopathological Tissue Classification with Plug-and-Play Pyramidal Deep-Broad Learning
Nov 04, 2021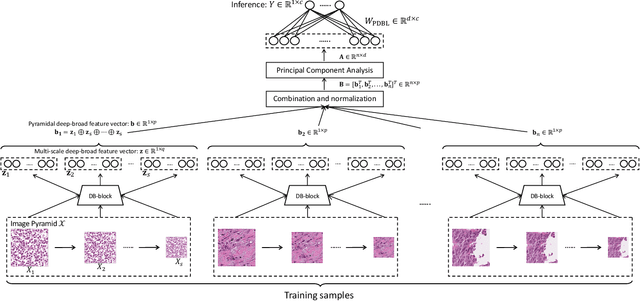
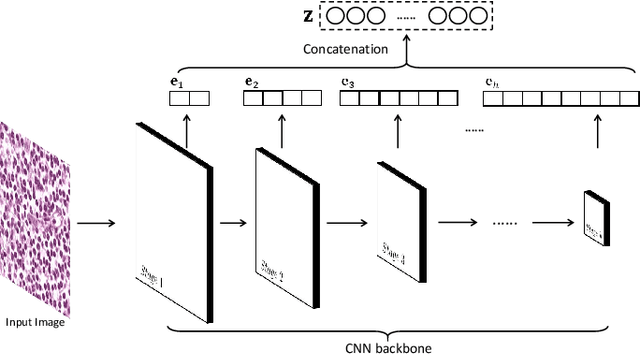

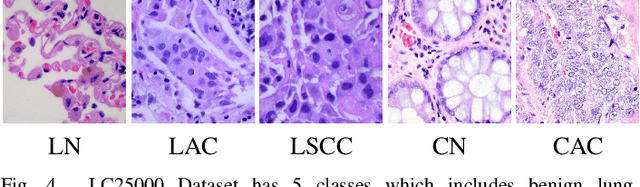
Histopathological tissue classification is a fundamental task in pathomics cancer research. Precisely differentiating different tissue types is a benefit for the downstream researches, like cancer diagnosis, prognosis and etc. Existing works mostly leverage the popular classification backbones in computer vision to achieve histopathological tissue classification. In this paper, we proposed a super lightweight plug-and-play module, named Pyramidal Deep-Broad Learning (PDBL), for any well-trained classification backbone to further improve the classification performance without a re-training burden. We mimic how pathologists observe pathology slides in different magnifications and construct an image pyramid for the input image in order to obtain the pyramidal contextual information. For each level in the pyramid, we extract the multi-scale deep-broad features by our proposed Deep-Broad block (DB-block). We equipped PDBL in three popular classification backbones, ShuffLeNetV2, EfficientNetb0, and ResNet50 to evaluate the effectiveness and efficiency of our proposed module on two datasets (Kather Multiclass Dataset and the LC25000 Dataset). Experimental results demonstrate the proposed PDBL can steadily improve the tissue-level classification performance for any CNN backbones, especially for the lightweight models when given a small among of training samples (less than 10%), which greatly saves the computational time and annotation efforts.