 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimulation of Neural Responses to Classical Music Using Organoid Intelligence Methods
Jul 25, 2024Music is a complex auditory stimulus capable of eliciting significant changes in brain activity, influencing cognitive processes such as memory, attention, and emotional regulation. However, the underlying mechanisms of music-induced cognitive processes remain largely unknown. Organoid intelligence and deep learning models show promise for simulating and analyzing these neural responses to classical music, an area significantly unexplored in computational neuroscience. Hence, we present the PyOrganoid library, an innovative tool that facilitates the simulation of organoid learning models, integrating sophisticated machine learning techniques with biologically inspired organoid simulations. Our study features the development of the Pianoid model, a "deep organoid learning" model that utilizes a Bidirectional LSTM network to predict EEG responses based on audio features from classical music recordings. This model demonstrates the feasibility of using computational methods to replicate complex neural processes, providing valuable insights into music perception and cognition. Likewise, our findings emphasize the utility of synthetic models in neuroscience research and highlight the PyOrganoid library's potential as a versatile tool for advancing studies in neuroscience and artificial intelligence.
Emotion Recognition of the Singing Voice: Toward a Real-Time Analysis Tool for Singers
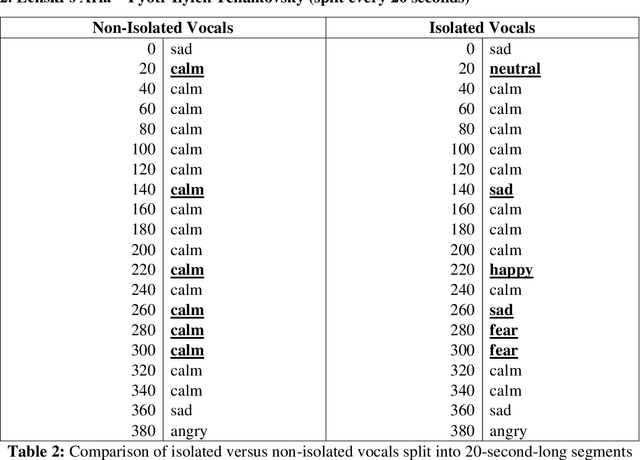
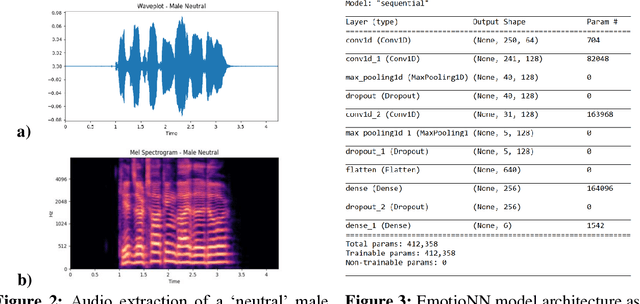
May 01, 2021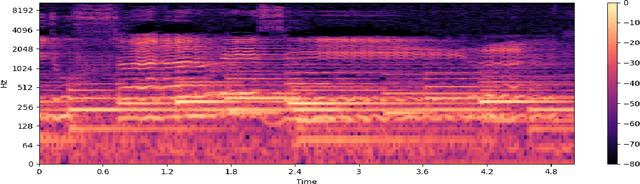

Current computational-emotion research has focused on applying acoustic properties to analyze how emotions are perceived mathematically or used in natural language processing machine learning models. With most recent interest being in analyzing emotions from the spoken voice, little experimentation has been performed to discover how emotions are recognized in the singing voice -- both in noiseless and noisy data (i.e., data that is either inaccurate, difficult to interpret, has corrupted/distorted/nonsense information like actual noise sounds in this case, or has a low ratio of usable/unusable information). Not only does this ignore the challenges of training machine learning models on more subjective data and testing them with much noisier data, but there is also a clear disconnect in progress between advancing the development of convolutional neural networks and the goal of emotionally cognizant artificial intelligence. By training a new model to include this type of information with a rich comprehension of psycho-acoustic properties, not only can models be trained to recognize information within extremely noisy data, but advancement can be made toward more complex biofeedback applications -- including creating a model which could recognize emotions given any human information (language, breath, voice, body, posture) and be used in any performance medium (music, speech, acting) or psychological assistance for patients with disorders such as BPD, alexithymia, autism, among others. This paper seeks to reflect and expand upon the findings of related research and present a stepping-stone toward this end goal.
Generative Deep Learning for Virtuosic Classical Music: Generative Adversarial Networks as Renowned Composers
Jan 01, 2021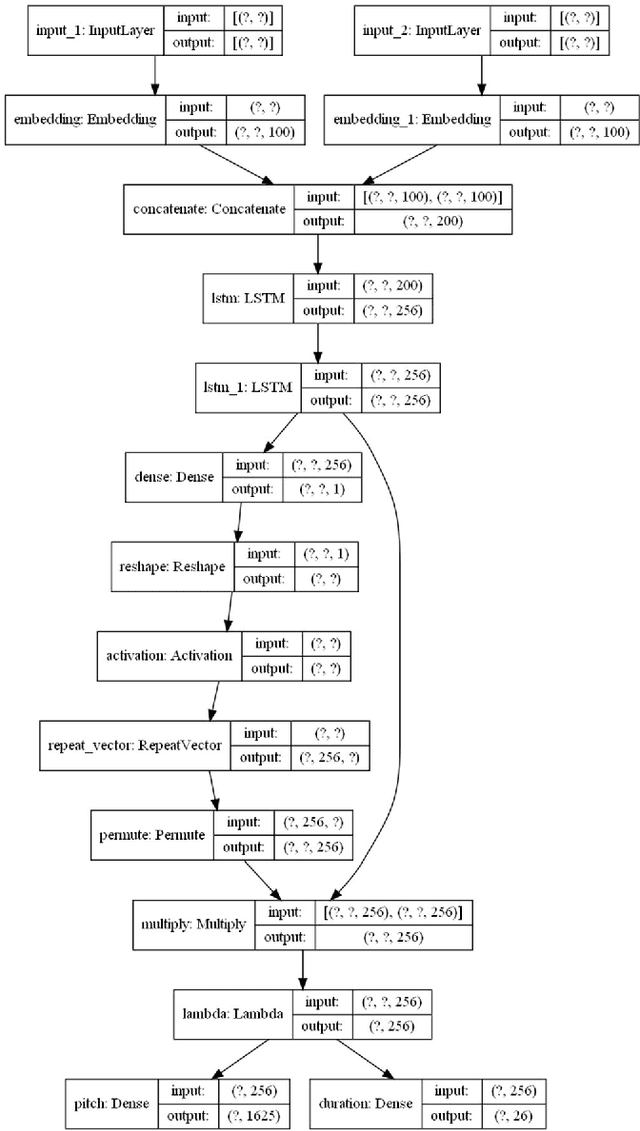
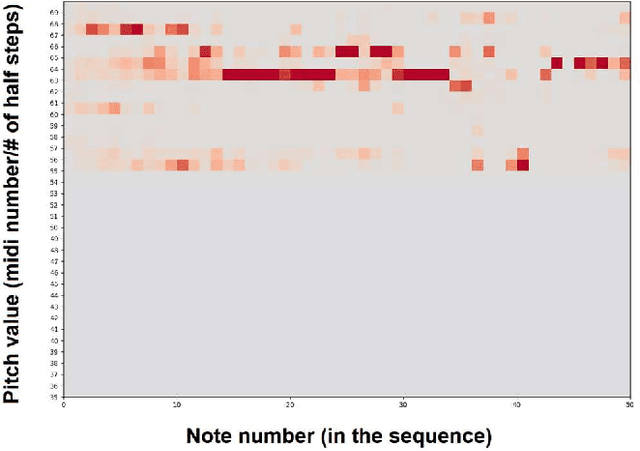
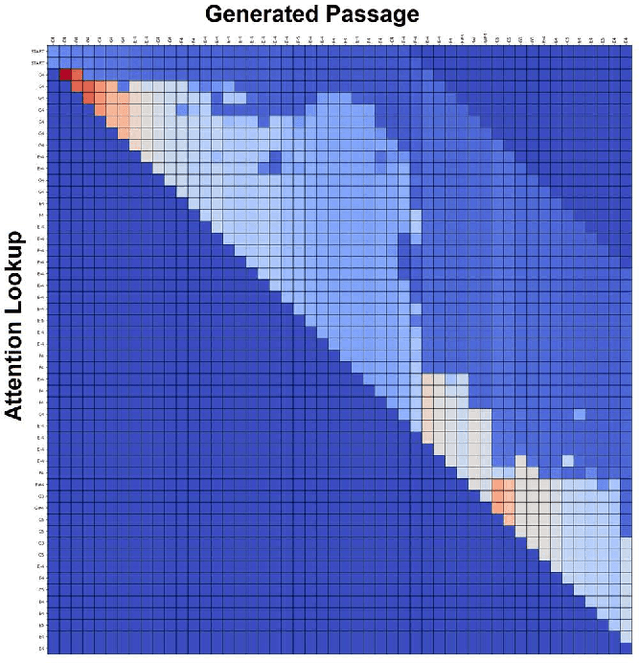
Current AI-generated music lacks fundamental principles of good compositional techniques. By narrowing down implementation issues both programmatically and musically, we can create a better understanding of what parameters are necessary for a generated composition nearly indistinguishable from that of a master composer.