 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Chatter Detection in Turning Using Machine Learning and Similarity Measures of Time Series via Dynamic Time Warping
Aug 05, 2019

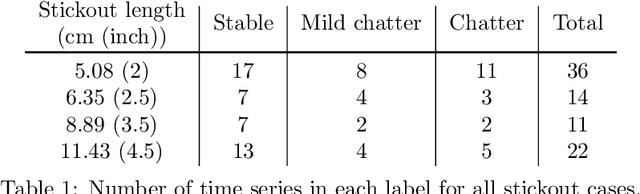
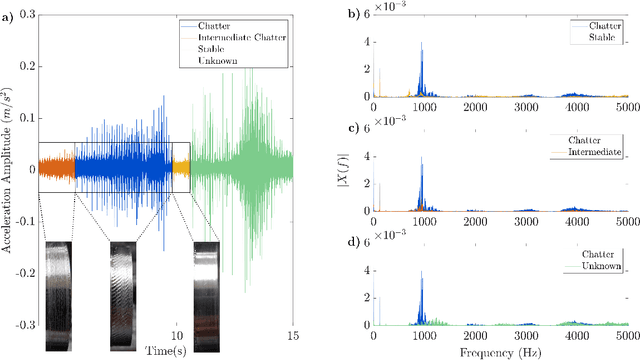
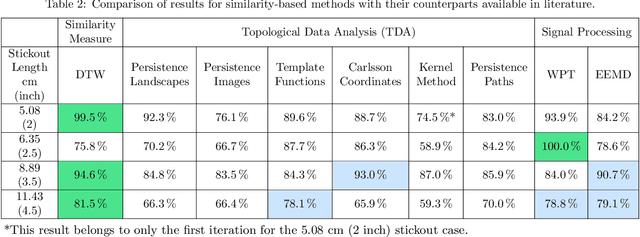
Chatter detection from sensor signals has been an active field of research. While some success has been reported using several featurization tools and machine learning algorithms, existing methods have several drawbacks such as manual preprocessing and requiring a large data set. In this paper, we present an alternative approach for chatter detection based on K-Nearest Neighbor (kNN) algorithm for classification and the Dynamic Time Warping (DTW) as a time series similarity measure. The used time series are the acceleration signals acquired from the tool holder in a series of turning experiments. Our results, show that this approach achieves detection accuracies that in most cases outperform existing methods. We compare our results to the traditional methods based on Wavelet Packet Transform (WPT) and the Ensemble Empirical Mode Decomposition (EEMD), as well as to the more recent Topological Data Analysis (TDA) based approach. We show that in three out of four cutting configurations our DTW-based approach attains the highest average classification rate reaching in one case as high as 99% accuracy. Our approach does not require feature extraction, is capable of reusing a classifier across different cutting configurations, and it uses reasonably sized training sets. Although the resulting high accuracy in our approach is associated with high computational cost, this is specific to the DTW implementation that we used. Specifically, we highlight available, very fast DTW implementations that can even be implemented on small consumer electronics. Therefore, further code optimization and the significantly reduced computational effort during the implementation phase make our approach a viable option for in-process chatter detection.
Reinforcement learning for bandwidth estimation and congestion control in real-time communications
Dec 04, 2019

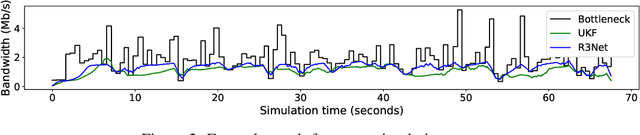
Bandwidth estimation and congestion control for real-time communications (i.e., audio and video conferencing) remains a difficult problem, despite many years of research. Achieving high quality of experience (QoE) for end users requires continual updates due to changing network architectures and technologies. In this paper, we apply reinforcement learning for the first time to the problem of real-time communications (RTC), where we seek to optimize user-perceived quality. We present initial proof-of-concept results, where we learn an agent to control sending rate in an RTC system, evaluating using both network simulation and real Internet video calls. We discuss the challenges we observed, particularly in designing realistic reward functions that reflect QoE, and in bridging the gap between the training environment and real-world networks.
CLIP-Forge: Towards Zero-Shot Text-to-Shape Generation
Oct 06, 2021
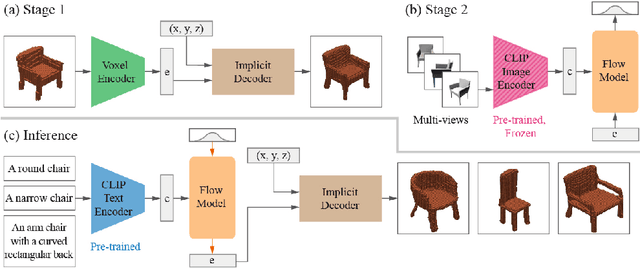


While recent progress has been made in text-to-image generation, text-to-shape generation remains a challenging problem due to the unavailability of paired text and shape data at a large scale. We present a simple yet effective method for zero-shot text-to-shape generation based on a two-stage training process, which only depends on an unlabelled shape dataset and a pre-trained image-text network such as CLIP. Our method not only demonstrates promising zero-shot generalization, but also avoids expensive inference time optimization and can generate multiple shapes for a given text.
Metamorphic Relation Prioritization for Effective Regression Testing
Sep 20, 2021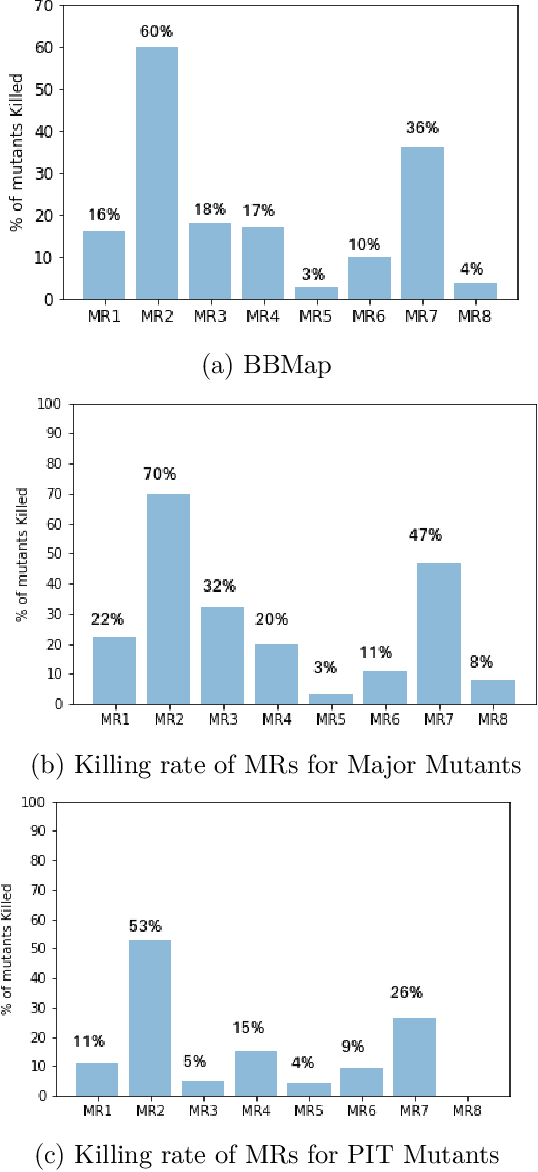
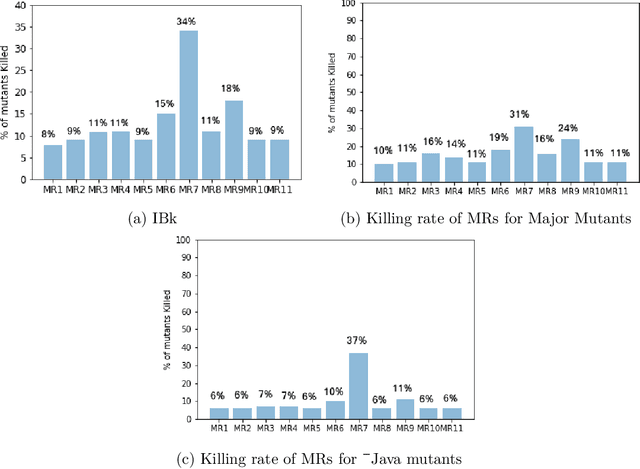
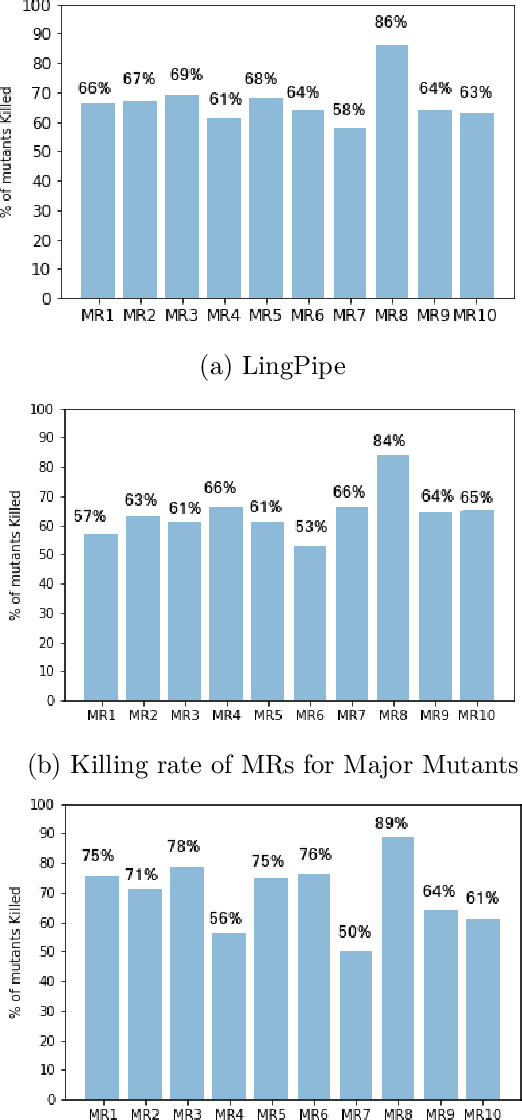
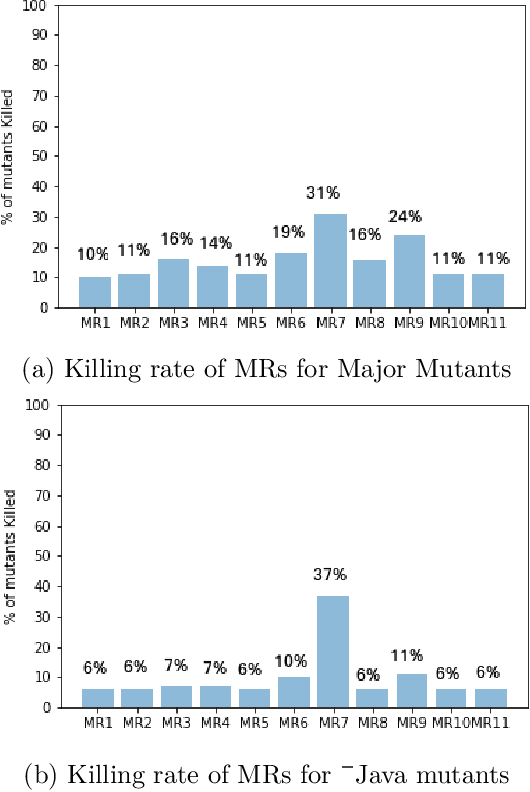
Metamorphic testing (MT) is widely used for testing programs that face the oracle problem. It uses a set of metamorphic relations (MRs), which are relations among multiple inputs and their corresponding outputs to determine whether the program under test is faulty. Typically, MRs vary in their ability to detect faults in the program under test, and some MRs tend to detect the same set of faults. In this paper, we propose approaches to prioritize MRs to improve the efficiency and effectiveness of MT for regression testing. We present two MR prioritization approaches: (1) fault-based and (2) coverage-based. To evaluate these MR prioritization approaches, we conduct experiments on three complex open-source software systems. Our results show that the MR prioritization approaches developed by us significantly outperform the current practice of executing the source and follow-up test cases of the MRs in an ad-hoc manner in terms of fault detection effectiveness. Further, fault-based MR prioritization leads to reducing the number of source and follow-up test cases that needs to be executed as well as reducing the average time taken to detect a fault, which would result in saving time and cost during the testing process.
Meta-Voice: Fast few-shot style transfer for expressive voice cloning using meta learning
Nov 14, 2021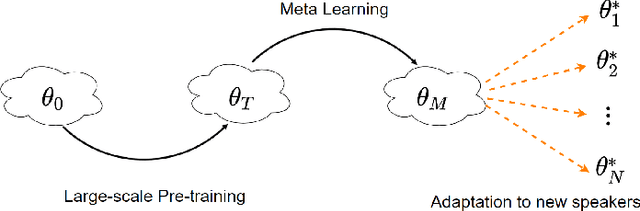
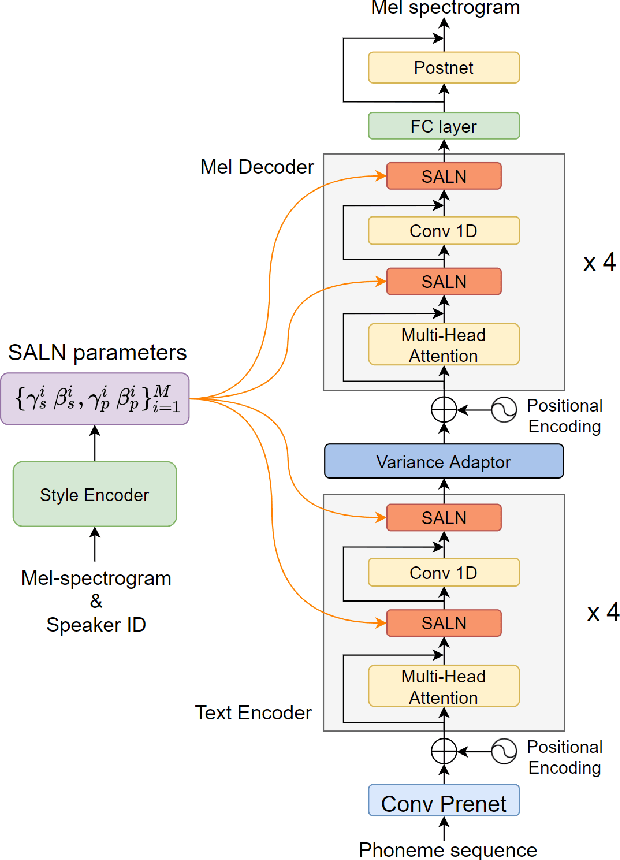
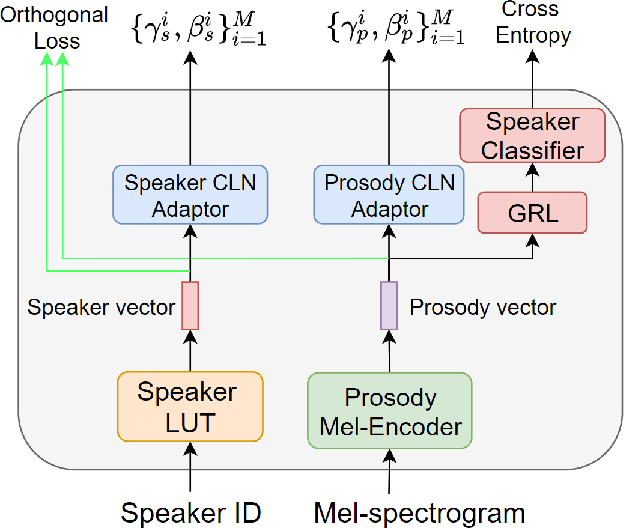
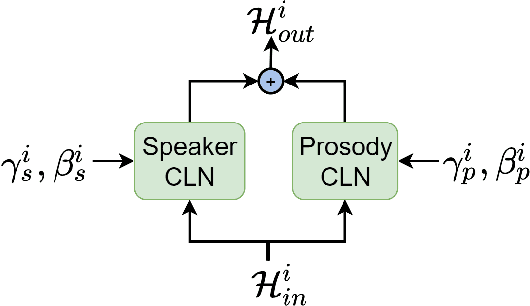
The task of few-shot style transfer for voice cloning in text-to-speech (TTS) synthesis aims at transferring speaking styles of an arbitrary source speaker to a target speaker's voice using very limited amount of neutral data. This is a very challenging task since the learning algorithm needs to deal with few-shot voice cloning and speaker-prosody disentanglement at the same time. Accelerating the adaptation process for a new target speaker is of importance in real-world applications, but even more challenging. In this paper, we approach to the hard fast few-shot style transfer for voice cloning task using meta learning. We investigate the model-agnostic meta-learning (MAML) algorithm and meta-transfer a pre-trained multi-speaker and multi-prosody base TTS model to be highly sensitive for adaptation with few samples. Domain adversarial training mechanism and orthogonal constraint are adopted to disentangle speaker and prosody representations for effective cross-speaker style transfer. Experimental results show that the proposed approach is able to conduct fast voice cloning using only 5 samples (around 12 second speech data) from a target speaker, with only 100 adaptation steps. Audio samples are available online.
Flexible Pattern Discovery and Analysis
Nov 24, 2021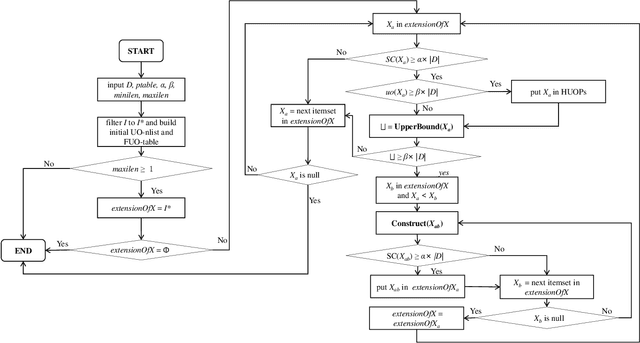
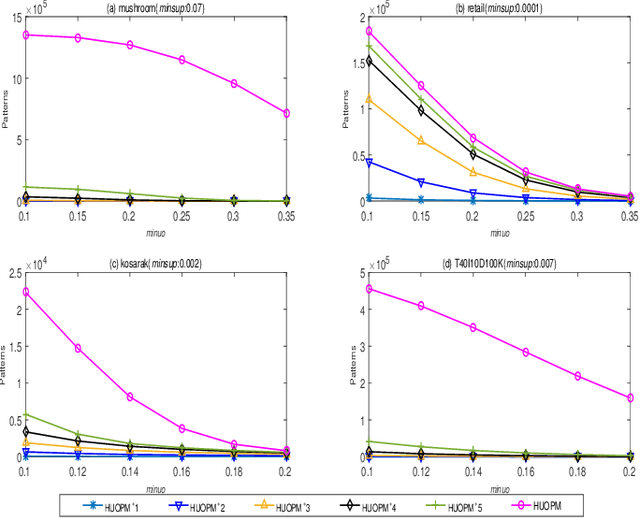
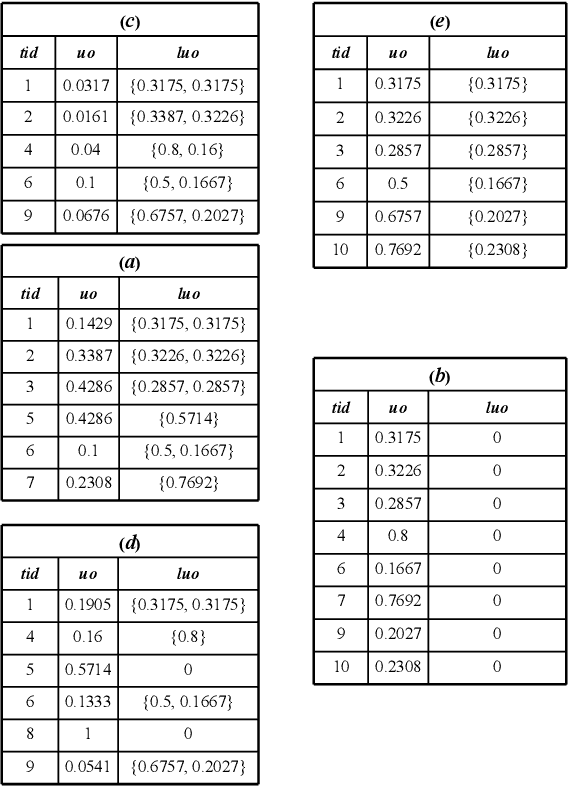
Based on the analysis of the proportion of utility in the supporting transactions used in the field of data mining, high utility-occupancy pattern mining (HUOPM) has recently attracted widespread attention. Unlike high-utility pattern mining (HUPM), which involves the enumeration of high-utility (e.g., profitable) patterns, HUOPM aims to find patterns representing a collection of existing transactions. In practical applications, however, not all patterns are used or valuable. For example, a pattern might contain too many items, that is, the pattern might be too specific and therefore lack value for users in real life. To achieve qualified patterns with a flexible length, we constrain the minimum and maximum lengths during the mining process and introduce a novel algorithm for the mining of flexible high utility-occupancy patterns. Our algorithm is referred to as HUOPM+. To ensure the flexibility of the patterns and tighten the upper bound of the utility-occupancy, a strategy called the length upper-bound (LUB) is presented to prune the search space. In addition, a utility-occupancy nested list (UO-nlist) and a frequency-utility-occupancy table (FUO-table) are employed to avoid multiple scans of the database. Evaluation results of the subsequent experiments confirm that the proposed algorithm can effectively control the length of the derived patterns, for both real-world and synthetic datasets. Moreover, it can decrease the execution time and memory consumption.
Rendering Spatial Sound for Interoperable Experiences in the Audio Metaverse
Sep 26, 2021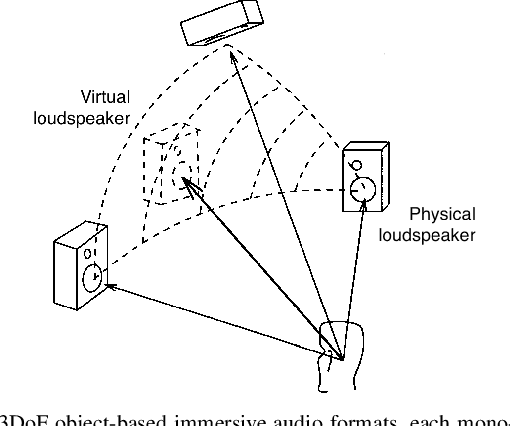
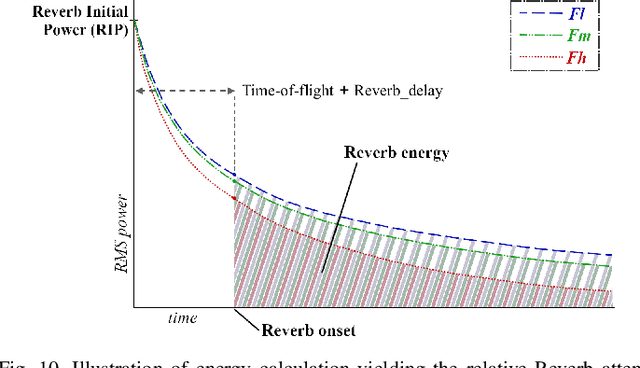
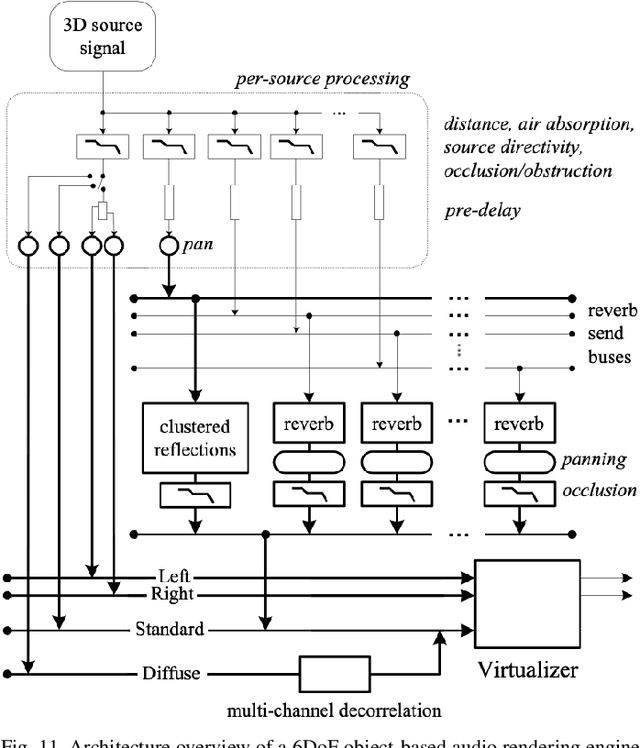
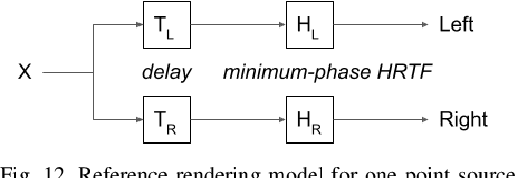
Interactive audio spatialization technology previously developed for video game authoring and rendering has evolved into an essential component of platforms enabling shared immersive virtual experiences for future co-presence, remote collaboration and entertainment applications. New wearable virtual and augmented reality displays employ real-time binaural audio computing engines rendering multiple digital objects and supporting the free navigation of networked participants or their avatars through a juxtaposition of environments, real and virtual, often referred to as the Metaverse. These applications require a parametric audio scene programming interface to facilitate the creation and deployment of shared, dynamic and realistic virtual 3D worlds on mobile computing platforms and remote servers. We propose a practical approach for designing parametric 6-degree-of-freedom object-based interactive audio engines to deliver the perceptually relevant binaural cues necessary for audio/visual and virtual/real congruence in Metaverse experiences. We address the effects of room reverberation, acoustic reflectors, and obstacles in both the virtual and real environments, and discuss how such effects may be driven by combinations of pre-computed and real-time acoustic propagation solvers. We envision an open scene description model distilled to facilitate the development of interoperable applications distributed across multiple platforms, where each audio object represents, to the user, a natural sound source having controllable distance, size, orientation, and acoustic radiation properties.
Robust and efficient change point detection using novel multivariate rank-energy GoF test
Oct 29, 2021

In this paper, we use and further develop upon a recently proposed multivariate, distribution-free Goodness-of-Fit (GoF) test based on the theory of Optimal Transport (OT) called the Rank Energy (RE) [1], for non-parametric and unsupervised Change Point Detection (CPD) in multivariate time series data. We show that directly using RE leads to high sensitivity to very small changes in distributions (causing high false alarms) and it requires large sample complexity and huge computational cost. To alleviate these drawbacks, we propose a new GoF test statistic called as soft-Rank Energy (sRE) that is based on entropy regularized OT and employ it towards CPD. We discuss the advantages of using sRE over RE and demonstrate that the proposed sRE based CPD outperforms all the existing methods in terms of Area Under the Curve (AUC) and F1-score on real and synthetic data sets.
Cleaning Inconsistent Data in Temporal DL-Lite Under Best Repair Semantics
Aug 30, 2021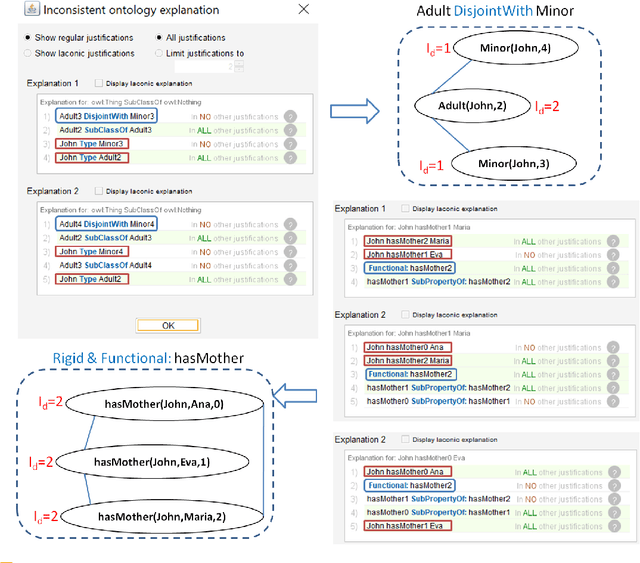
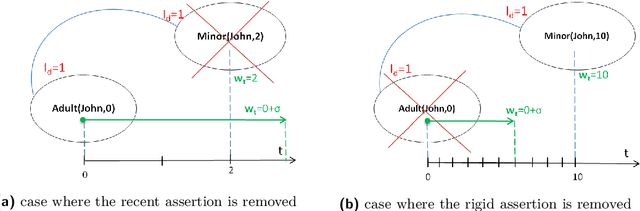
In this paper, we address the problem of handling inconsistent data in Temporal Description Logic (TDL) knowledge bases. Considering the data part of the Knowledge Base as the source of inconsistency over time, we propose an ABox repair approach. This is the first work handling the repair in TDL Knowledge bases. To do so, our goal is twofold: 1) detect temporal inconsistencies and 2) propose a data temporal reparation. For the inconsistency detection, we propose a reduction approach from TDL to DL which allows to provide a tight NP-complete upper bound for TDL concept satisfiability and to use highly optimised DL reasoners that can bring precise explanation (the set of inconsistent data assertions). Thereafter, from the obtained explanation, we propose a method for automatically computing the best repair in the temporal setting based on the allowed rigid predicates and the time order of assertions.
Learning to Learn End-to-End Goal-Oriented Dialog From Related Dialog Tasks
Oct 10, 2021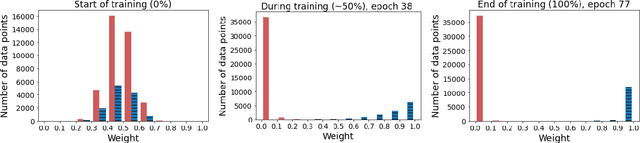
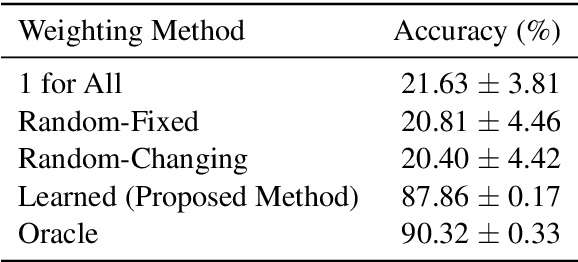
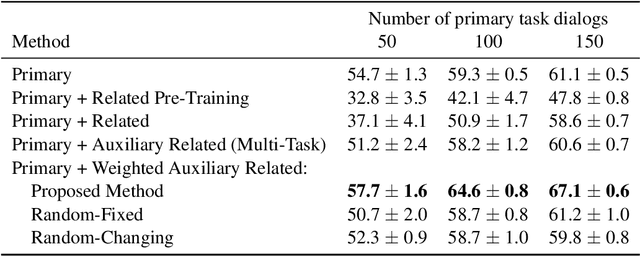
For each goal-oriented dialog task of interest, large amounts of data need to be collected for end-to-end learning of a neural dialog system. Collecting that data is a costly and time-consuming process. Instead, we show that we can use only a small amount of data, supplemented with data from a related dialog task. Naively learning from related data fails to improve performance as the related data can be inconsistent with the target task. We describe a meta-learning based method that selectively learns from the related dialog task data. Our approach leads to significant accuracy improvements in an example dialog task.