 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Rail Vehicle Localization and Mapping with LiDAR-Vision-Inertial-GNSS Fusion
Dec 16, 2021

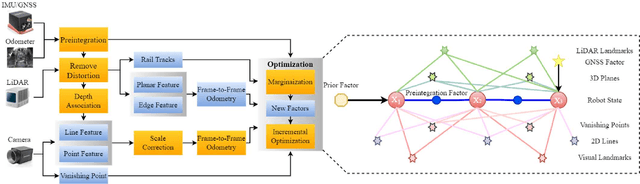
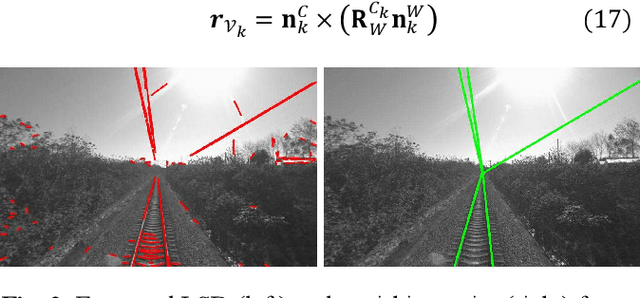

In this paper, we present a global navigation satellite system (GNSS) aided LiDAR-visual-inertial scheme, RailLoMer-V, for accurate and robust rail vehicle localization and mapping. RailLoMer-V is formulated atop a factor graph and consists of two subsystems: an odometer assisted LiDAR-inertial system (OLIS) and an odometer integrated Visual-inertial system (OVIS). Both the subsystem exploits the typical geometry structure on the railroads. The plane constraints from extracted rail tracks are used to complement the rotation and vertical errors in OLIS. Besides, the line features and vanishing points are leveraged to constrain rotation drifts in OVIS. The proposed framework is extensively evaluated on datasets over 800 km, gathered for more than a year on both general-speed and high-speed railways, day and night. Taking advantage of the tightly-coupled integration of all measurements from individual sensors, our framework is accurate to long-during tasks and robust enough to grievously degenerated scenarios (railway tunnels). In addition, the real-time performance can be achieved with an onboard computer.
M-FasterSeg: An Efficient Semantic Segmentation Network Based on Neural Architecture Search
Dec 30, 2021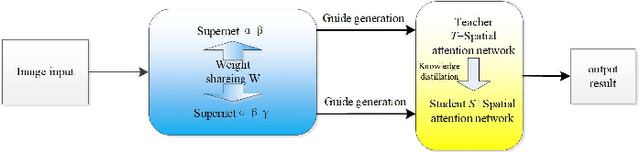
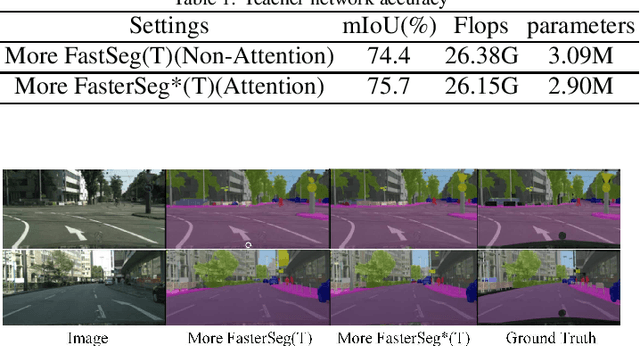
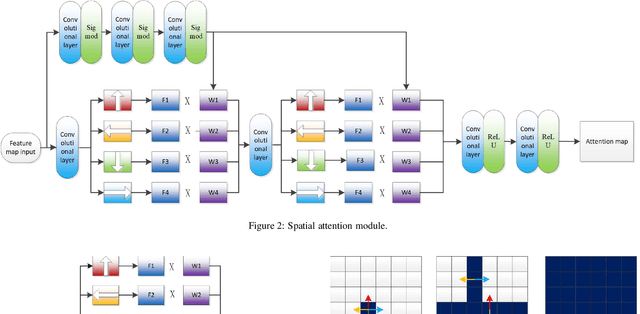
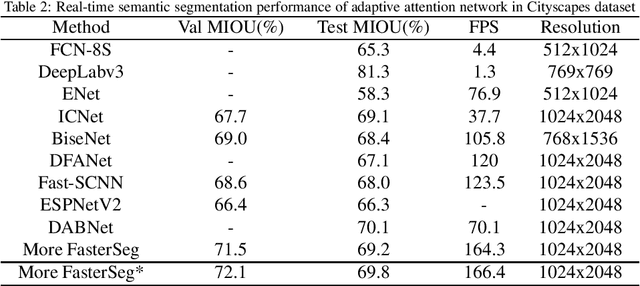
Image semantic segmentation technology is one of the key technologies for intelligent systems to understand natural scenes. As one of the important research directions in the field of visual intelligence, this technology has broad application scenarios in the fields of mobile robots, drones, smart driving, and smart security. However, in the actual application of mobile robots, problems such as inaccurate segmentation semantic label prediction and loss of edge information of segmented objects and background may occur. This paper proposes an improved structure of a semantic segmentation network based on a deep learning network that combines self-attention neural network and neural network architecture search methods. First, a neural network search method NAS (Neural Architecture Search) is used to find a semantic segmentation network with multiple resolution branches. In the search process, combine the self-attention network structure module to adjust the searched neural network structure, and then combine the semantic segmentation network searched by different branches to form a fast semantic segmentation network structure, and input the picture into the network structure to get the final forecast result. The experimental results on the Cityscapes dataset show that the accuracy of the algorithm is 69.8%, and the segmentation speed is 48/s. It achieves a good balance between real-time and accuracy, can optimize edge segmentation, and has a better performance in complex scenes. Good robustness is suitable for practical application.
Low dosage 3D volume fluorescence microscopy imaging using compressive sensing
Jan 03, 2022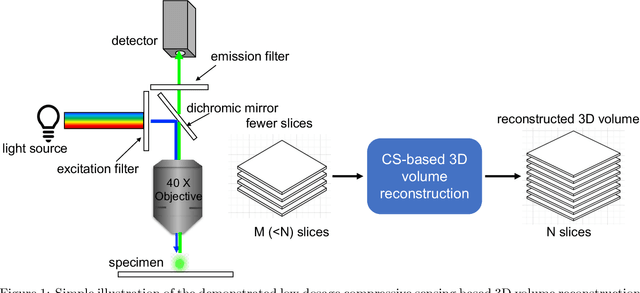
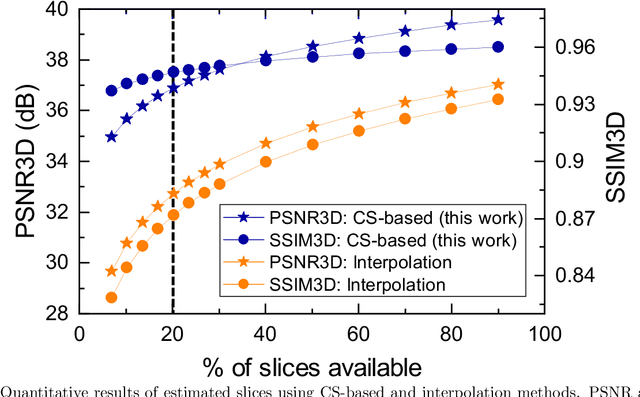

Fluorescence microscopy has been a significant tool to observe long-term imaging of embryos (in vivo) growth over time. However, cumulative exposure is phototoxic to such sensitive live samples. While techniques like light-sheet fluorescence microscopy (LSFM) allow for reduced exposure, it is not well suited for deep imaging models. Other computational techniques are computationally expensive and often lack restoration quality. To address this challenge, one can use various low-dosage imaging techniques that are developed to achieve the 3D volume reconstruction using a few slices in the axial direction (z-axis); however, they often lack restoration quality. Also, acquiring dense images (with small steps) in the axial direction is computationally expensive. To address this challenge, we present a compressive sensing (CS) based approach to fully reconstruct 3D volumes with the same signal-to-noise ratio (SNR) with less than half of the excitation dosage. We present the theory and experimentally validate the approach. To demonstrate our technique, we capture a 3D volume of the RFP labeled neurons in the zebrafish embryo spinal cord (30um thickness) with the axial sampling of 0.1um using a confocal microscope. From the results, we observe the CS-based approach achieves accurate 3D volume reconstruction from less than 20% of the entire stack optical sections. The developed CS-based methodology in this work can be easily applied to other deep imaging modalities such as two-photon and light-sheet microscopy, where reducing sample photo-toxicity is a critical challenge.
Descriptors for Machine Learning Model of Generalized Force Field in Condensed Matter Systems
Jan 03, 2022
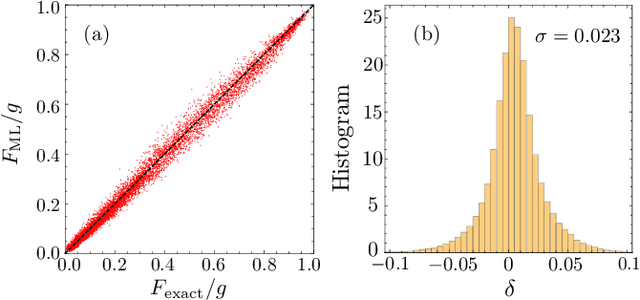
We outline the general framework of machine learning (ML) methods for multi-scale dynamical modeling of condensed matter systems, and in particular of strongly correlated electron models. Complex spatial temporal behaviors in these systems often arise from the interplay between quasi-particles and the emergent dynamical classical degrees of freedom, such as local lattice distortions, spins, and order-parameters. Central to the proposed framework is the ML energy model that, by successfully emulating the time-consuming electronic structure calculation, can accurately predict a local energy based on the classical field in the intermediate neighborhood. In order to properly include the symmetry of the electron Hamiltonian, a crucial component of the ML energy model is the descriptor that transforms the neighborhood configuration into invariant feature variables, which are input to the learning model. A general theory of the descriptor for the classical fields is formulated, and two types of models are distinguished depending on the presence or absence of an internal symmetry for the classical field. Several specific approaches to the descriptor of the classical fields are presented. Our focus is on the group-theoretical method that offers a systematic and rigorous approach to compute invariants based on the bispectrum coefficients. We propose an efficient implementation of the bispectrum method based on the concept of reference irreducible representations. Finally, the implementations of the various descriptors are demonstrated on well-known electronic lattice models.
ELight: Enabling Efficient Photonic In-Memory Neurocomputing with Life Enhancement
Dec 15, 2021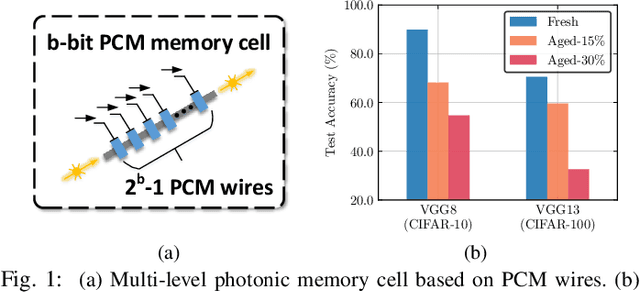
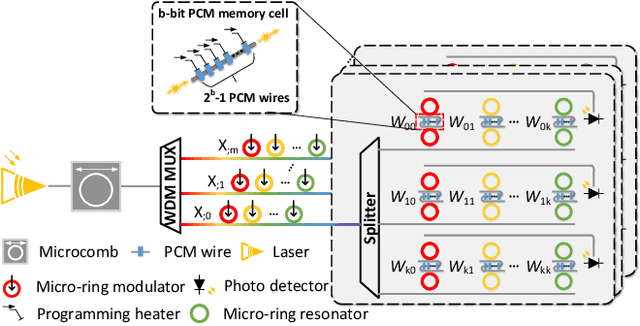
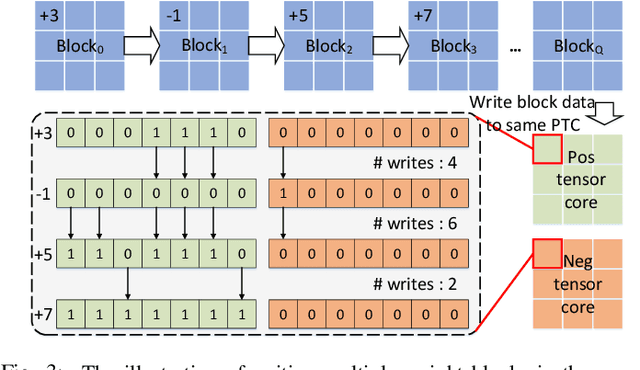
With the recent advances in optical phase change material (PCM), photonic in-memory neurocomputing has demonstrated its superiority in optical neural network (ONN) designs with near-zero static power consumption, time-of-light latency, and compact footprint. However, photonic tensor cores require massive hardware reuse to implement large matrix multiplication due to the limited single-core scale. The resultant large number of PCM writes leads to serious dynamic power and overwhelms the fragile PCM with limited write endurance. In this work, we propose a synergistic optimization framework, ELight, to minimize the overall write efforts for efficient and reliable optical in-memory neurocomputing. We first propose write-aware training to encourage the similarity among weight blocks, and combine it with a post-training optimization method to reduce programming efforts by eliminating redundant writes. Experiments show that ELight can achieve over 20X reduction in the total number of writes and dynamic power with comparable accuracy. With our ELight, photonic in-memory neurocomputing will step forward towards viable applications in machine learning with preserved accuracy, order-of-magnitude longer lifetime, and lower programming energy.
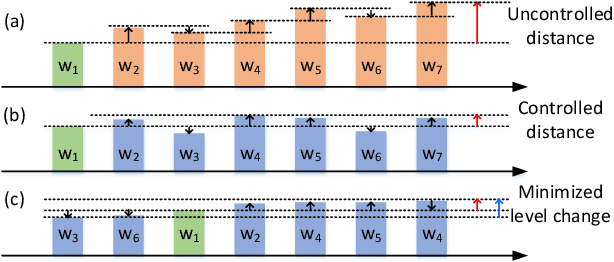
Deep Learning for Agile Effort Estimation Have We Solved the Problem Yet?
Jan 14, 2022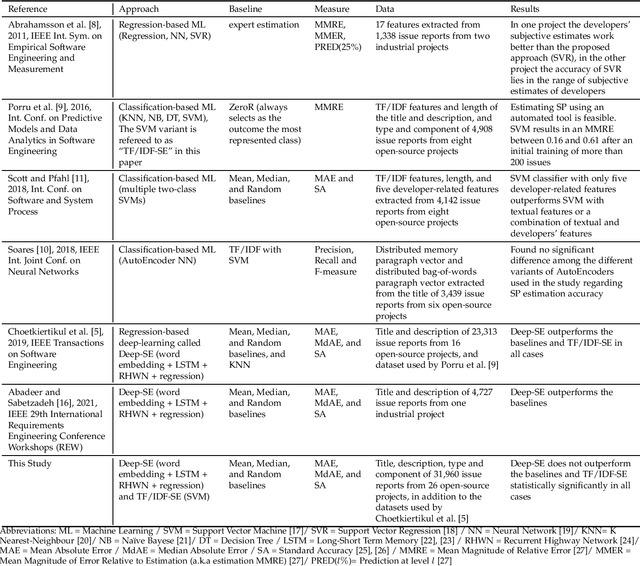
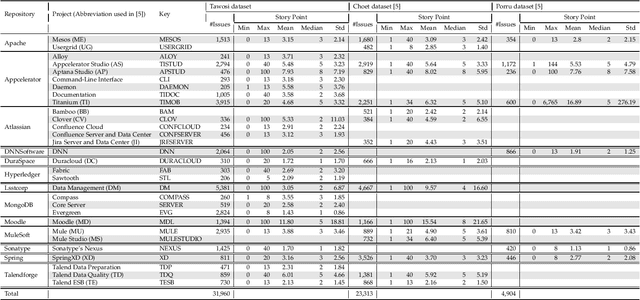
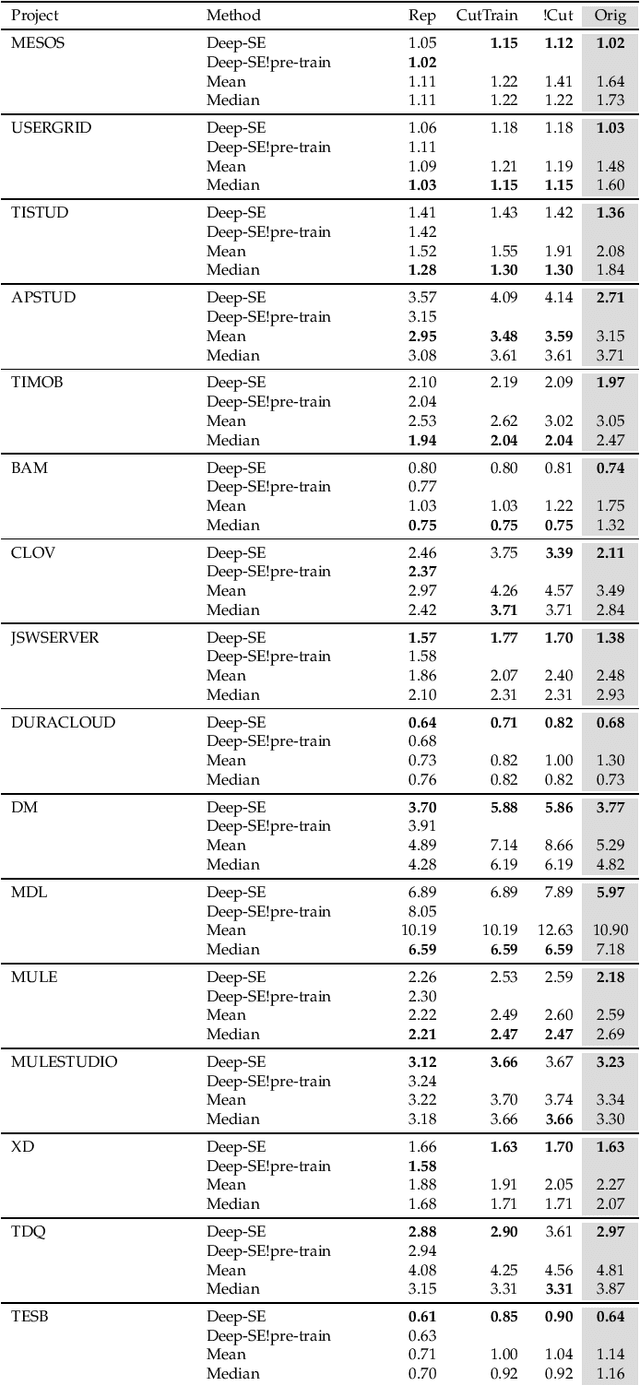
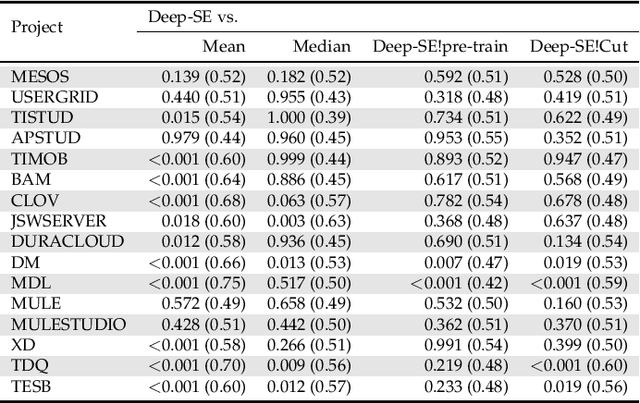
In the last decade, several studies have proposed the use of automated techniques to estimate the effort of agile software development. In this paper we perform a close replication and extension of a seminal work proposing the use of Deep Learning for agile effort estimation (namely Deep-SE), which has set the state-of-the-art since. Specifically, we replicate three of the original research questions aiming at investigating the effectiveness of Deep-SE for both within-project and cross-project effort estimation. We benchmark Deep-SE against three baseline techniques (i.e., Random, Mean and Median effort prediction) and a previously proposed method to estimate agile software project development effort (dubbed TF/IDF-SE), as done in the original study. To this end, we use both the data from the original study and a new larger dataset of 31,960 issues, which we mined from 29 open-source projects. Using more data allows us to strengthen our confidence in the results and further mitigate the threat to the external validity of the study. We also extend the original study by investigating two additional research questions. One evaluates the accuracy of Deep-SE when the training set is augmented with issues from all other projects available in the repository at the time of estimation, and the other examines whether an expensive pre-training step used by the original Deep-SE, has any beneficial effect on its accuracy and convergence speed. The results of our replication show that Deep-SE outperforms the Median baseline estimator and TF/IDF-SE in only very few cases with statistical significance (8/42 and 9/32 cases, respectively), thus confounding previous findings on the efficacy of Deep-SE. The two additional RQs revealed that neither augmenting the training set nor pre-training Deep-SE play a role in improving its accuracy and convergence speed. ...
The Layout Generation Algorithm of Graphic Design Based on Transformer-CVAE
Oct 08, 2021
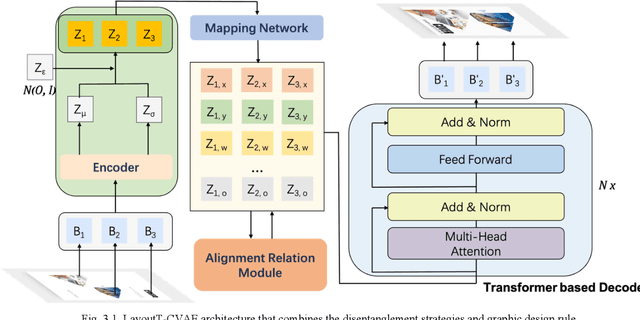
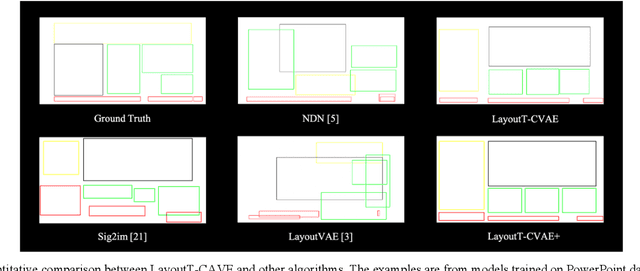
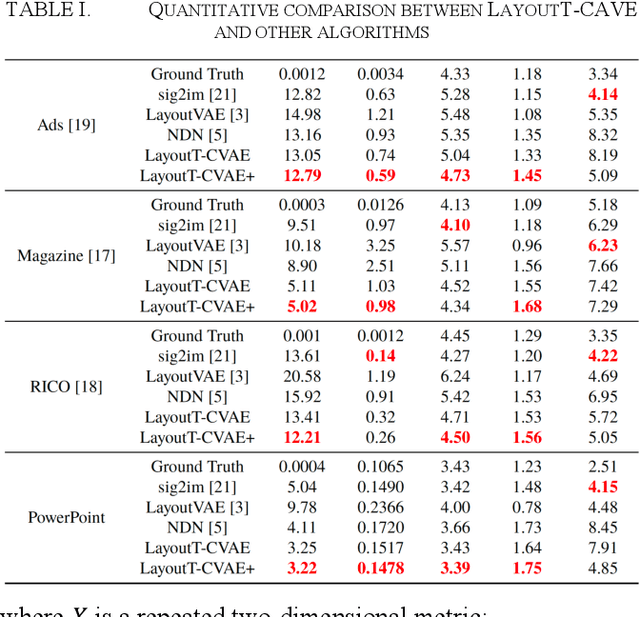
Graphic design is ubiquitous in people's daily lives. For graphic design, the most time-consuming task is laying out various components in the interface. Repetitive manual layout design will waste a lot of time for professional graphic designers. Existing templates are usually rudimentary and not suitable for most designs, reducing efficiency and limiting creativity. This paper implemented the Transformer model and conditional variational autoencoder (CVAE) to the graphic design layout generation task. It proposed an end-to-end graphic design layout generation model named LayoutT-CVAE. We also proposed element disentanglement and feature-based disentanglement strategies and introduce new graphic design principles and similarity metrics into the model, which significantly increased the controllability and interpretability of the deep model. Compared with the existing state-of-art models, the layout generated by ours performs better on many metrics.
Quantum Algorithms for Reinforcement Learning with a Generative Model
Dec 15, 2021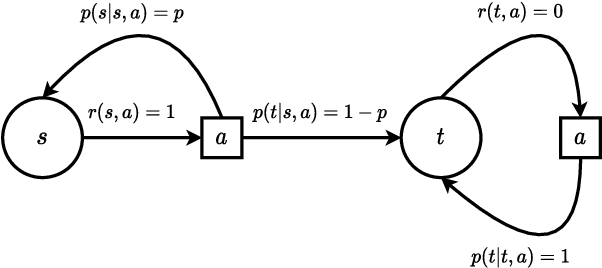
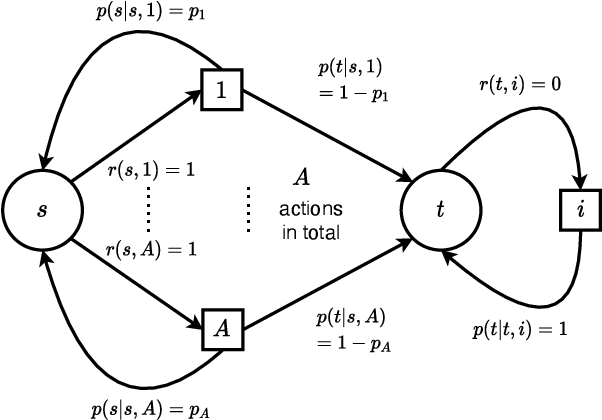
Reinforcement learning studies how an agent should interact with an environment to maximize its cumulative reward. A standard way to study this question abstractly is to ask how many samples an agent needs from the environment to learn an optimal policy for a $\gamma$-discounted Markov decision process (MDP). For such an MDP, we design quantum algorithms that approximate an optimal policy ($\pi^*$), the optimal value function ($v^*$), and the optimal $Q$-function ($q^*$), assuming the algorithms can access samples from the environment in quantum superposition. This assumption is justified whenever there exists a simulator for the environment; for example, if the environment is a video game or some other program. Our quantum algorithms, inspired by value iteration, achieve quadratic speedups over the best-possible classical sample complexities in the approximation accuracy ($\epsilon$) and two main parameters of the MDP: the effective time horizon ($\frac{1}{1-\gamma}$) and the size of the action space ($A$). Moreover, we show that our quantum algorithm for computing $q^*$ is optimal by proving a matching quantum lower bound.
* 26 pages
TransVOD: End-to-end Video Object Detection with Spatial-Temporal Transformers
Jan 14, 2022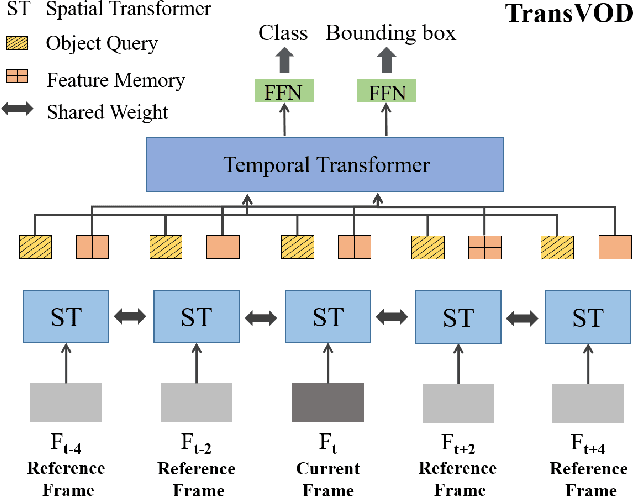
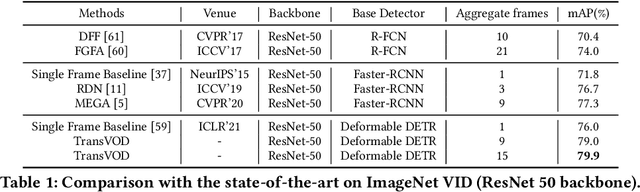
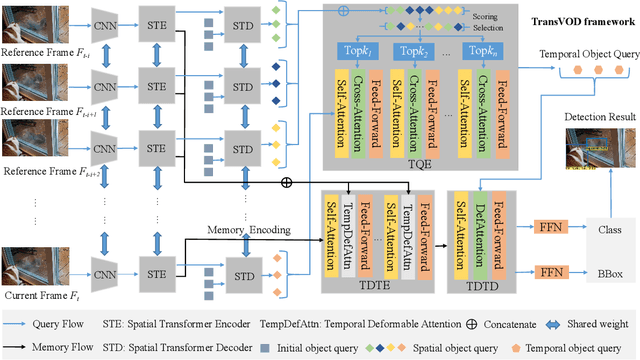
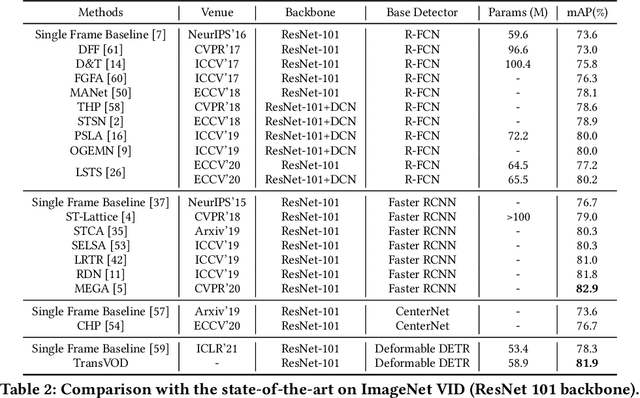
Detection Transformer (DETR) and Deformable DETR have been proposed to eliminate the need for many hand-designed components in object detection while demonstrating good performance as previous complex hand-crafted detectors. However, their performance on Video Object Detection (VOD) has not been well explored. In this paper, we present TransVOD, the first end-to-end video object detection system based on spatial-temporal Transformer architectures. The first goal of this paper is to streamline the pipeline of VOD, effectively removing the need for many hand-crafted components for feature aggregation, e.g., optical flow model, relation networks. Besides, benefited from the object query design in DETR, our method does not need complicated post-processing methods such as Seq-NMS. In particular, we present a temporal Transformer to aggregate both the spatial object queries and the feature memories of each frame. Our temporal transformer consists of two components: Temporal Query Encoder (TQE) to fuse object queries, and Temporal Deformable Transformer Decoder (TDTD) to obtain current frame detection results. These designs boost the strong baseline deformable DETR by a significant margin (3%-4% mAP) on the ImageNet VID dataset. Then, we present two improved versions of TransVOD including TransVOD++ and TransVOD Lite. The former fuses object-level information into object query via dynamic convolution while the latter models the entire video clips as the output to speed up the inference time. We give detailed analysis of all three models in the experiment part. In particular, our proposed TransVOD++ sets a new state-of-the-art record in terms of accuracy on ImageNet VID with 90.0% mAP. Our proposed TransVOD Lite also achieves the best speed and accuracy trade-off with 83.7% mAP while running at around 30 FPS on a single V100 GPU device. Code and models will be available for further research.
Multi-Dialect Arabic Speech Recognition
Dec 25, 2021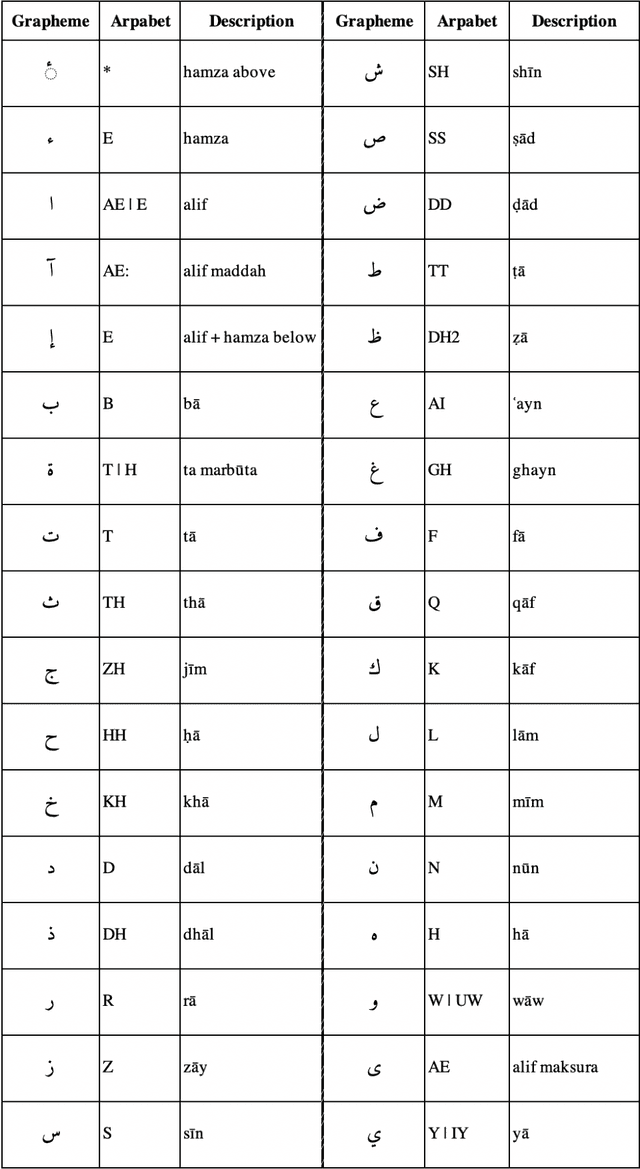
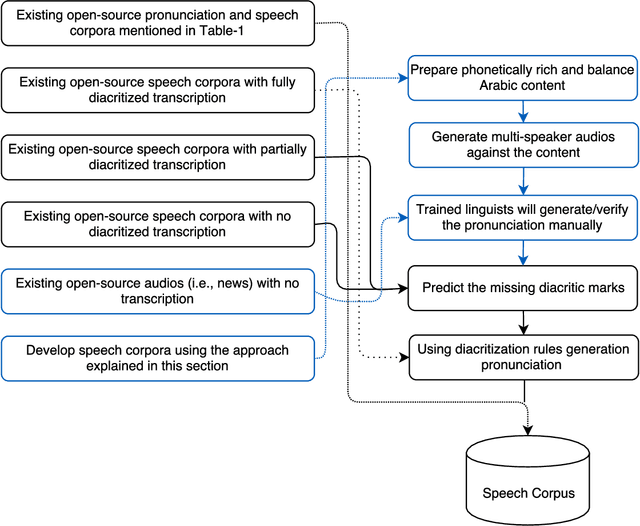
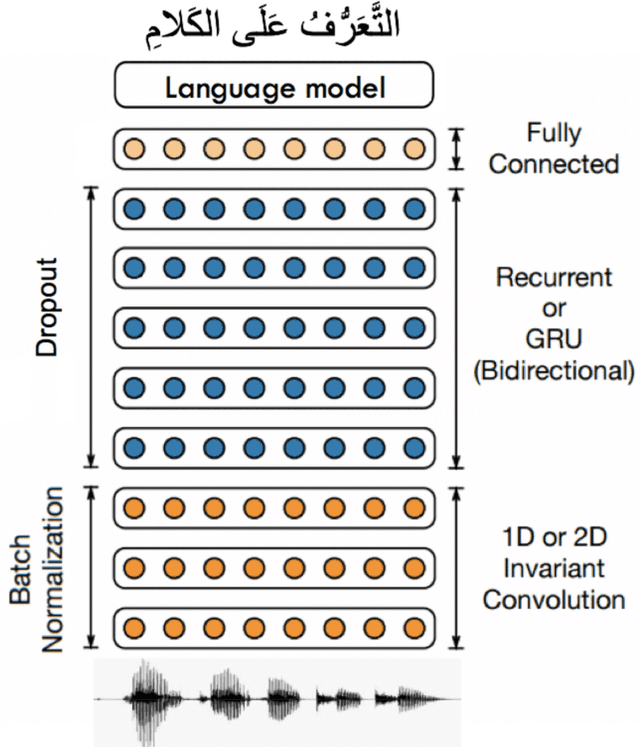

This paper presents the design and development of multi-dialect automatic speech recognition for Arabic. Deep neural networks are becoming an effective tool to solve sequential data problems, particularly, adopting an end-to-end training of the system. Arabic speech recognition is a complex task because of the existence of multiple dialects, non-availability of large corpora, and missing vocalization. Thus, the first contribution of this work is the development of a large multi-dialectal corpus with either full or at least partially vocalized transcription. Additionally, the open-source corpus has been gathered from multiple sources that bring non-standard Arabic alphabets in transcription which are normalized by defining a common character-set. The second contribution is the development of a framework to train an acoustic model achieving state-of-the-art performance. The network architecture comprises of a combination of convolutional and recurrent layers. The spectrogram features of the audio data are extracted in the frequency vs time domain and fed in the network. The output frames, produced by the recurrent model, are further trained to align the audio features with its corresponding transcription sequences. The sequence alignment is performed using a beam search decoder with a tetra-gram language model. The proposed system achieved a 14% error rate which outperforms previous systems.