 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTerminalWorld: Benchmarking Agents on Real-World Terminal Tasks
May 21, 2026We introduce TerminalWorld, a scalable data engine that automatically reverse-engineers high-fidelity evaluation tasks from "in-the-wild" terminal recordings. Processing 80,870 terminal recordings, the engine yields a full benchmark of 1,530 validated tasks, spanning 18 real-world categories, ranging from short everyday operations to workflows exceeding 50 steps, and covering 1,280 unique commands. From these, we curate a Verified subset of 200 representative, manually reviewed tasks. Comprehensive benchmarking on TerminalWorld-Verified across eight frontier models and six agents reveals that current systems still struggle with authentic terminal workflows, achieving a maximum pass rate of only 62.5%. Moreover, TerminalWorld captures real-world terminal capabilities distinct from existing expert-curated benchmarks (e.g., Terminal-Bench), with only a weak correlation to their scores (Pearson r=0.20). The automated engine makes TerminalWorld authentic and scalable by construction, enabling it to evaluate agents in real-world terminal environments as developer practices evolve. Data and code are available at https://github.com/EuniAI/TerminalWorld.
SkillMOO: Multi-Objective Optimization of Agent Skills for Software Engineering
Apr 10, 2026Agent skills provide modular, task-specific guidance for LLM- based coding agents, but manually tuning skill bundles to balance success rate, cost, and runtime is expensive and fragile. We present SkillMOO, a multi-objective optimization framework that automatically evolves skill bundles using LLM-proposed edits and NSGA-II survivor selection: a solver agent evaluates candidate skill bundles on coding tasks and an optimizer agent proposes bundle edits based on failure analysis. On three SkillsBench software engineering tasks, SkillMOO improves pass rate by up to 131% while reducing cost up to 32% relative to the best baseline per task at low optimization overhead. Pattern analysis reveals pruning and substitution as primary drivers of improvement, suggesting effective bundles favor minimal, focused content over accumulated instructions.
Generative AI for Testing of Autonomous Driving Systems: A Survey
Aug 27, 2025Autonomous driving systems (ADS) have been an active area of research, with the potential to deliver significant benefits to society. However, before large-scale deployment on public roads, extensive testing is necessary to validate their functionality and safety under diverse driving conditions. Therefore, different testing approaches are required, and achieving effective and efficient testing of ADS remains an open challenge. Recently, generative AI has emerged as a powerful tool across many domains, and it is increasingly being applied to ADS testing due to its ability to interpret context, reason about complex tasks, and generate diverse outputs. To gain a deeper understanding of its role in ADS testing, we systematically analyzed 91 relevant studies and synthesized their findings into six major application categories, primarily centered on scenario-based testing of ADS. We also reviewed their effectiveness and compiled a wide range of datasets, simulators, ADS, metrics, and benchmarks used for evaluation, while identifying 27 limitations. This survey provides an overview and practical insights into the use of generative AI for testing ADS, highlights existing challenges, and outlines directions for future research in this rapidly evolving field.
When Prompts Go Wrong: Evaluating Code Model Robustness to Ambiguous, Contradictory, and Incomplete Task Descriptions
Jul 27, 2025



Large Language Models (LLMs) have demonstrated impressive performance in code generation tasks under idealized conditions, where task descriptions are clear and precise. However, in practice, task descriptions frequently exhibit ambiguity, incompleteness, or internal contradictions. In this paper, we present the first empirical study examining the robustness of state-of-the-art code generation models when faced with such unclear task descriptions. We extend the HumanEval and MBPP benchmarks by systematically introducing realistic task descriptions flaws through guided mutation strategies, producing a dataset that mirrors the messiness of informal developer instructions. We evaluate multiple LLMs of varying sizes and architectures, analyzing their functional correctness and failure modes across task descriptions categories. Our findings reveal that even minor imperfections in task description phrasing can cause significant performance degradation, with contradictory task descriptions resulting in numerous logical errors. Moreover, while larger models tend to be more resilient than smaller variants, they are not immune to the challenges posed by unclear requirements. We further analyze semantic error patterns and identify correlations between description clarity, model behavior, and error types. Our results underscore the critical need for developing LLMs that are not only powerful but also robust to the imperfections inherent in natural user tasks, highlighting important considerations for improving model training strategies, designing more realistic evaluation benchmarks, and ensuring reliable deployment in practical software development environments.
How Do Generative Models Draw a Software Engineer? A Case Study on Stable Diffusion Bias
Jan 15, 2025



Generative models are nowadays widely used to generate graphical content used for multiple purposes, e.g. web, art, advertisement. However, it has been shown that the images generated by these models could reinforce societal biases already existing in specific contexts. In this paper, we focus on understanding if this is the case when one generates images related to various software engineering tasks. In fact, the Software Engineering (SE) community is not immune from gender and ethnicity disparities, which could be amplified by the use of these models. Hence, if used without consciousness, artificially generated images could reinforce these biases in the SE domain. Specifically, we perform an extensive empirical evaluation of the gender and ethnicity bias exposed by three versions of the Stable Diffusion (SD) model (a very popular open-source text-to-image model) - SD 2, SD XL, and SD 3 - towards SE tasks. We obtain 6,720 images by feeding each model with two sets of prompts describing different software-related tasks: one set includes the Software Engineer keyword, and one set does not include any specification of the person performing the task. Next, we evaluate the gender and ethnicity disparities in the generated images. Results show how all models are significantly biased towards male figures when representing software engineers. On the contrary, while SD 2 and SD XL are strongly biased towards White figures, SD 3 is slightly more biased towards Asian figures. Nevertheless, all models significantly under-represent Black and Arab figures, regardless of the prompt style used. The results of our analysis highlight severe concerns about adopting those models to generate content for SE tasks and open the field for future research on bias mitigation in this context.
On the Compression of Language Models for Code: An Empirical Study on CodeBERT
Dec 18, 2024



Language models have proven successful across a wide range of software engineering tasks, but their significant computational costs often hinder their practical adoption. To address this challenge, researchers have begun applying various compression strategies to improve the efficiency of language models for code. These strategies aim to optimize inference latency and memory usage, though often at the cost of reduced model effectiveness. However, there is still a significant gap in understanding how these strategies influence the efficiency and effectiveness of language models for code. Here, we empirically investigate the impact of three well-known compression strategies -- knowledge distillation, quantization, and pruning -- across three different classes of software engineering tasks: vulnerability detection, code summarization, and code search. Our findings reveal that the impact of these strategies varies greatly depending on the task and the specific compression method employed. Practitioners and researchers can use these insights to make informed decisions when selecting the most appropriate compression strategy, balancing both efficiency and effectiveness based on their specific needs.
Diversity Drives Fairness: Ensemble of Higher Order Mutants for Intersectional Fairness of Machine Learning Software
Dec 11, 2024



Intersectional fairness is a critical requirement for Machine Learning (ML) software, demanding fairness across subgroups defined by multiple protected attributes. This paper introduces FairHOME, a novel ensemble approach using higher order mutation of inputs to enhance intersectional fairness of ML software during the inference phase. Inspired by social science theories highlighting the benefits of diversity, FairHOME generates mutants representing diverse subgroups for each input instance, thus broadening the array of perspectives to foster a fairer decision-making process. Unlike conventional ensemble methods that combine predictions made by different models, FairHOME combines predictions for the original input and its mutants, all generated by the same ML model, to reach a final decision. Notably, FairHOME is even applicable to deployed ML software as it bypasses the need for training new models. We extensively evaluate FairHOME against seven state-of-the-art fairness improvement methods across 24 decision-making tasks using widely adopted metrics. FairHOME consistently outperforms existing methods across all metrics considered. On average, it enhances intersectional fairness by 47.5%, surpassing the currently best-performing method by 9.6 percentage points.
Exploring LLM-Driven Explanations for Quantum Algorithms
Sep 26, 2024



Background: Quantum computing is a rapidly growing new programming paradigm that brings significant changes to the design and implementation of algorithms. Understanding quantum algorithms requires knowledge of physics and mathematics, which can be challenging for software developers. Aims: In this work, we provide a first analysis of how LLMs can support developers' understanding of quantum code. Method: We empirically analyse and compare the quality of explanations provided by three widely adopted LLMs (Gpt3.5, Llama2, and Tinyllama) using two different human-written prompt styles for seven state-of-the-art quantum algorithms. We also analyse how consistent LLM explanations are over multiple rounds and how LLMs can improve existing descriptions of quantum algorithms. Results: Llama2 provides the highest quality explanations from scratch, while Gpt3.5 emerged as the LLM best suited to improve existing explanations. In addition, we show that adding a small amount of context to the prompt significantly improves the quality of explanations. Finally, we observe how explanations are qualitatively and syntactically consistent over multiple rounds. Conclusions: This work highlights promising results, and opens challenges for future research in the field of LLMs for quantum code explanation. Future work includes refining the methods through prompt optimisation and parsing of quantum code explanations, as well as carrying out a systematic assessment of the quality of explanations.
GreenStableYolo: Optimizing Inference Time and Image Quality of Text-to-Image Generation
Jul 20, 2024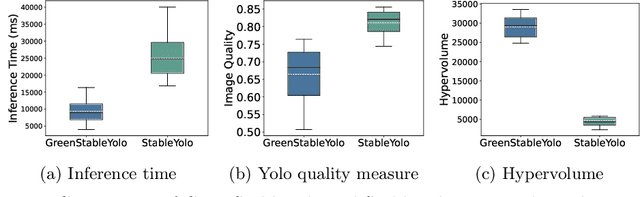
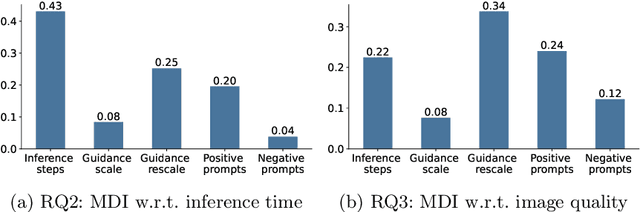
Tuning the parameters and prompts for improving AI-based text-to-image generation has remained a substantial yet unaddressed challenge. Hence we introduce GreenStableYolo, which improves the parameters and prompts for Stable Diffusion to both reduce GPU inference time and increase image generation quality using NSGA-II and Yolo. Our experiments show that despite a relatively slight trade-off (18%) in image quality compared to StableYolo (which only considers image quality), GreenStableYolo achieves a substantial reduction in inference time (266% less) and a 526% higher hypervolume, thereby advancing the state-of-the-art for text-to-image generation.
The Quest for Content: A Survey of Search-Based Procedural Content Generation for Video Games
Nov 08, 2023



Video games demand is constantly increasing, which requires the costly production of large amounts of content. Towards this challenge, researchers have developed Search-Based Procedural Content Generation (SBPCG), that is, the (semi-)automated creation of content through search algorithms. We survey the current state of SBPCG, reporting work appeared in the field between 2011-2022 and identifying open research challenges. The results lead to recommendations for practitioners and to the identification of several potential future research avenues for SBPCG.