 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Demystify Optimization and Generalization of Over-parameterized PAC-Bayesian Learning
Feb 04, 2022
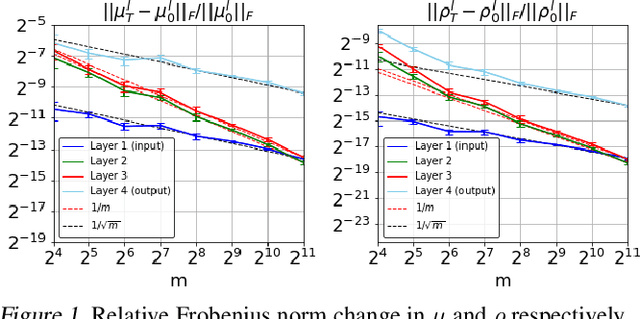
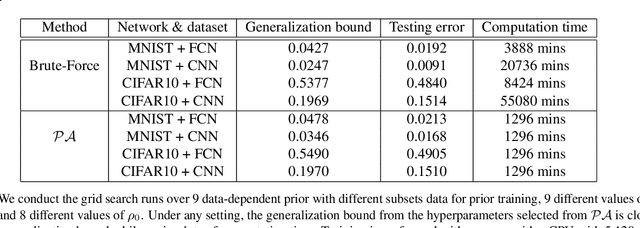
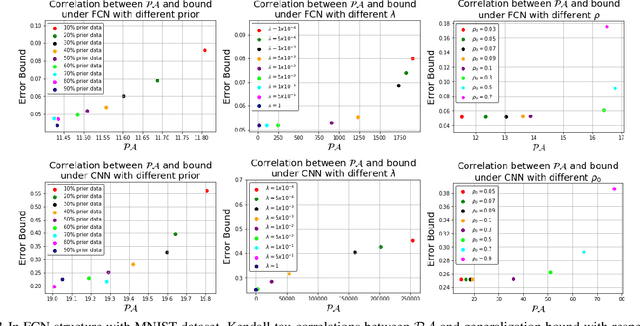
PAC-Bayesian is an analysis framework where the training error can be expressed as the weighted average of the hypotheses in the posterior distribution whilst incorporating the prior knowledge. In addition to being a pure generalization bound analysis tool, PAC-Bayesian bound can also be incorporated into an objective function to train a probabilistic neural network, making them a powerful and relevant framework that can numerically provide a tight generalization bound for supervised learning. For simplicity, we call probabilistic neural network learned using training objectives derived from PAC-Bayesian bounds as {\it PAC-Bayesian learning}. Despite their empirical success, the theoretical analysis of PAC-Bayesian learning for neural networks is rarely explored. This paper proposes a new class of convergence and generalization analysis for PAC-Bayes learning when it is used to train the over-parameterized neural networks by the gradient descent method. For a wide probabilistic neural network, we show that when PAC-Bayes learning is applied, the convergence result corresponds to solving a kernel ridge regression when the probabilistic neural tangent kernel (PNTK) is used as its kernel. Based on this finding, we further characterize the uniform PAC-Bayesian generalization bound which improves over the Rademacher complexity-based bound for non-probabilistic neural network. Finally, drawing the insight from our theoretical results, we propose a proxy measure for efficient hyperparameters selection, which is proven to be time-saving.
Animal Behavior Classification via Accelerometry Data and Recurrent Neural Networks
Nov 24, 2021
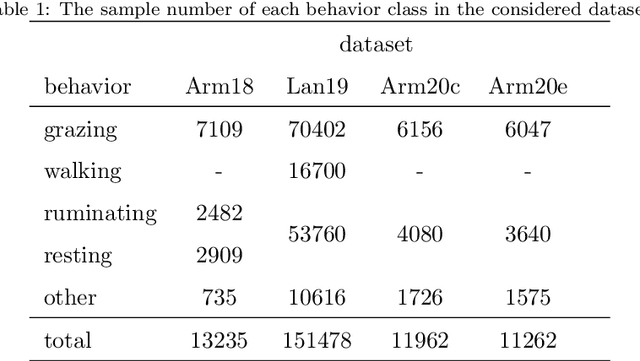

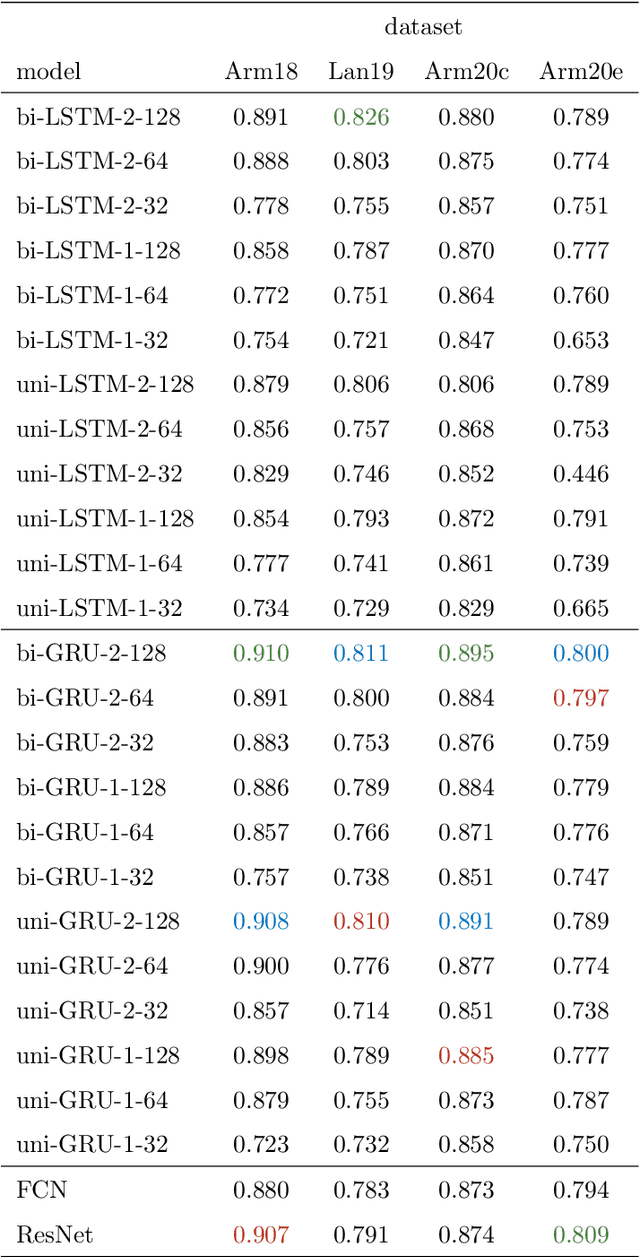
We study the classification of animal behavior using accelerometry data through various recurrent neural network (RNN) models. We evaluate the classification performance and complexity of the considered models, which feature long short-time memory (LSTM) or gated recurrent unit (GRU) architectures with varying depths and widths, using four datasets acquired from cattle via collar or ear tags. We also include two state-of-the-art convolutional neural network (CNN)-based time-series classification models in the evaluations. The results show that the RNN-based models can achieve similar or higher classification accuracy compared with the CNN-based models while having less computational and memory requirements. We also observe that the models with GRU architecture generally outperform the ones with LSTM architecture in terms of classification accuracy despite being less complex. A single-layer uni-directional GRU model with 64 hidden units appears to offer a good balance between accuracy and complexity making it suitable for implementation on edge/embedded devices.
Fast Differentiable Matrix Square Root
Jan 21, 2022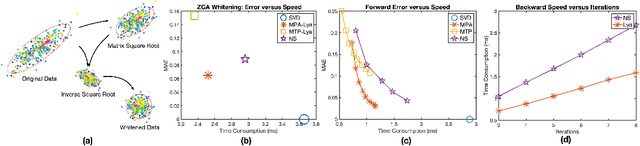

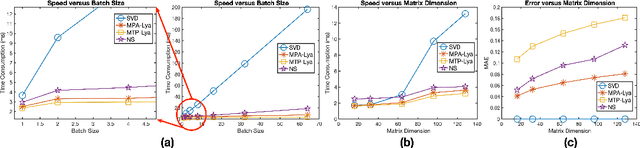
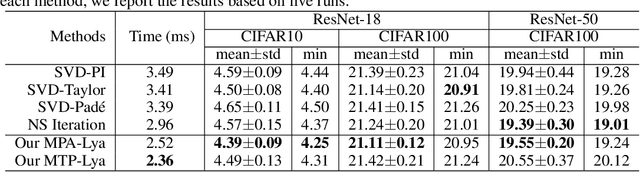
Computing the matrix square root or its inverse in a differentiable manner is important in a variety of computer vision tasks. Previous methods either adopt the Singular Value Decomposition (SVD) to explicitly factorize the matrix or use the Newton-Schulz iteration (NS iteration) to derive the approximate solution. However, both methods are not computationally efficient enough in either the forward pass or in the backward pass. In this paper, we propose two more efficient variants to compute the differentiable matrix square root. For the forward propagation, one method is to use Matrix Taylor Polynomial (MTP), and the other method is to use Matrix Pad\'e Approximants (MPA). The backward gradient is computed by iteratively solving the continuous-time Lyapunov equation using the matrix sign function. Both methods yield considerable speed-up compared with the SVD or the Newton-Schulz iteration. Experimental results on the de-correlated batch normalization and second-order vision transformer demonstrate that our methods can also achieve competitive and even slightly better performances. The code is available at \href{https://github.com/KingJamesSong/FastDifferentiableMatSqrt}{https://github.com/KingJamesSong/FastDifferentiableMatSqrt}.
Parallel Extraction of Long-term Trends and Short-term Fluctuation Framework for Multivariate Time Series Forecasting
Sep 07, 2020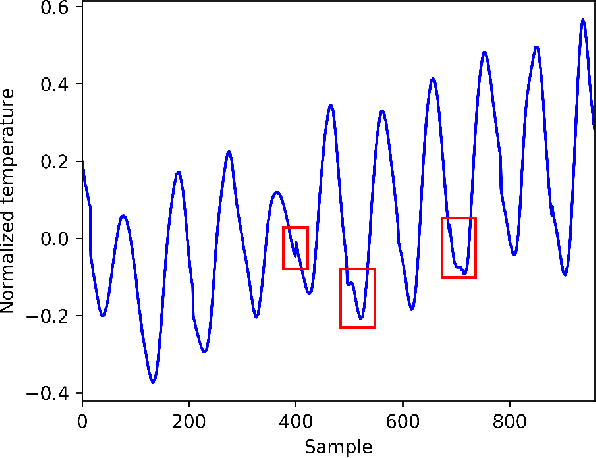
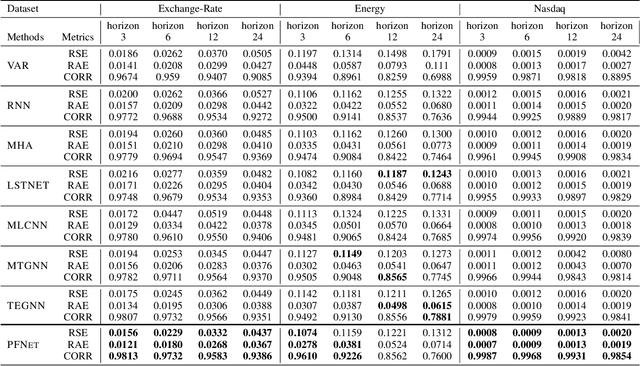
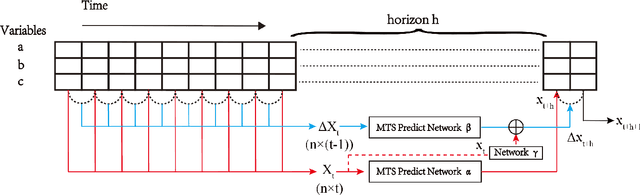
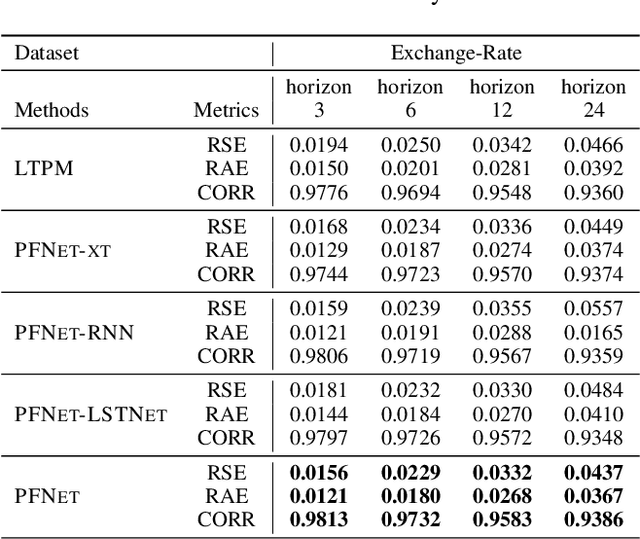
Multivariate time series forecasting is widely used in various fields. Reasonable prediction results can assist people in planning and decision-making, generate benefits and avoid risks. Normally, there are two characteristics of time series, that is, long-term trend and short-term fluctuation. For example, stock prices will have a long-term upward trend with the market, but there may be a small decline in the short term. These two characteristics are often relatively independent of each other. However, the existing prediction methods often do not distinguish between them, which reduces the accuracy of the prediction model. In this paper, a MTS forecasting framework that can capture the long-term trends and short-term fluctuations of time series in parallel is proposed. This method uses the original time series and its first difference to characterize long-term trends and short-term fluctuations. Three prediction sub-networks are constructed to predict long-term trends, short-term fluctuations and the final value to be predicted. In the overall optimization goal, the idea of multi-task learning is used for reference, which is to make the prediction results of long-term trends and short-term fluctuations as close to the real values as possible while requiring to approximate the values to be predicted. In this way, the proposed method uses more supervision information and can more accurately capture the changing trend of the time series, thereby improving the forecasting performance.
A Multi-channel Training Method Boost the Performance
Dec 27, 2021
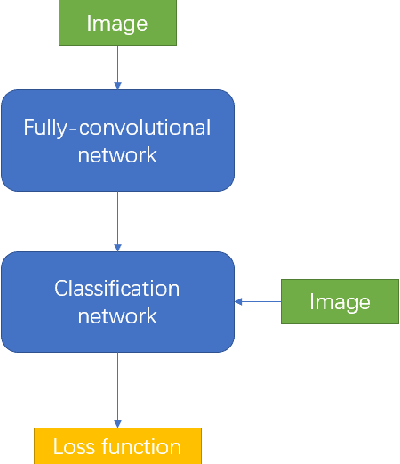
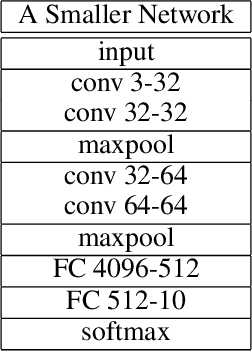
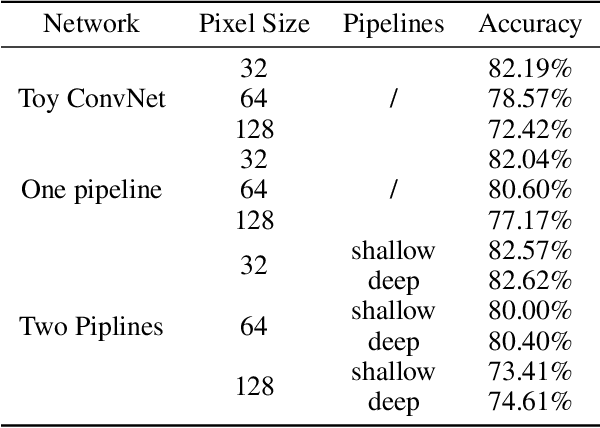
Deep convolutional neural network has made huge revolution and shown its superior performance on computer vision tasks such as classification and segmentation. Recent years, researches devote much effort to scaling down size of network while maintaining its ability, to adapt to the limited memory on embedded systems like mobile phone. In this paper, we propose a multi-channel training procedure which can highly facilitate the performance and robust of the target network. The proposed procedure contains two sets of networks and two information pipelines which can work independently hinge on the computation ability of the embedded platform, while in the mean time, the classification accuracy is also admirably enhanced.
Deep Q-learning: a robust control approach
Jan 21, 2022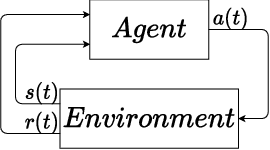

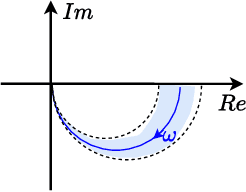
In this paper, we place deep Q-learning into a control-oriented perspective and study its learning dynamics with well-established techniques from robust control. We formulate an uncertain linear time-invariant model by means of the neural tangent kernel to describe learning. We show the instability of learning and analyze the agent's behavior in frequency-domain. Then, we ensure convergence via robust controllers acting as dynamical rewards in the loss function. We synthesize three controllers: state-feedback gain scheduling $\mathcal{H}_2$, dynamic $\mathcal{H}_\infty$, and constant gain $\mathcal{H}_\infty$ controllers. Setting up the learning agent with a control-oriented tuning methodology is more transparent and has well-established literature compared to the heuristics in reinforcement learning. In addition, our approach does not use a target network and randomized replay memory. The role of the target network is overtaken by the control input, which also exploits the temporal dependency of samples (opposed to a randomized memory buffer). Numerical simulations in different OpenAI Gym environments suggest that the $\mathcal{H}_\infty$ controlled learning performs slightly better than Double deep Q-learning.
Joint Superposition Coding and Training for Federated Learning over Multi-Width Neural Networks
Dec 05, 2021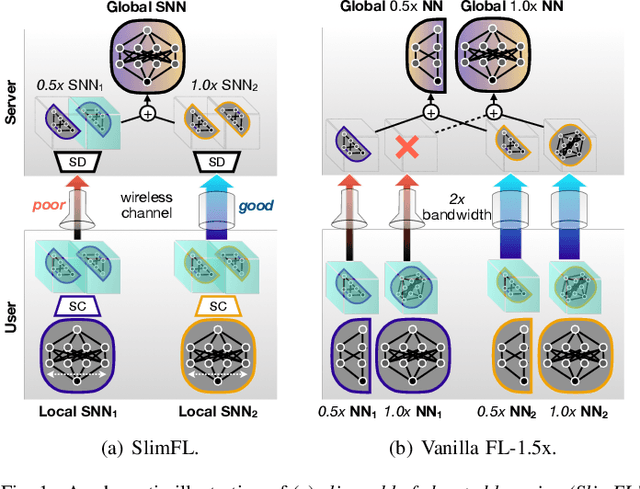
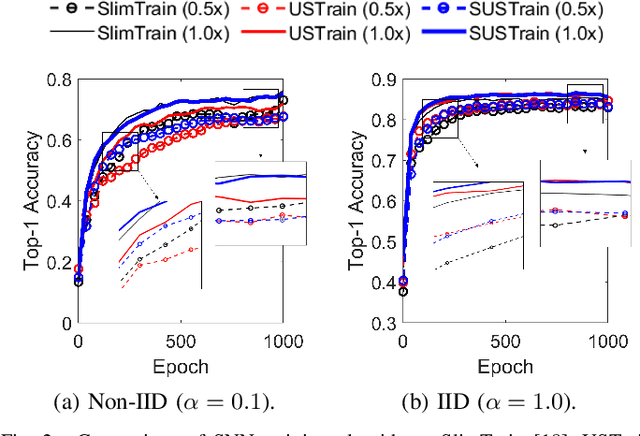
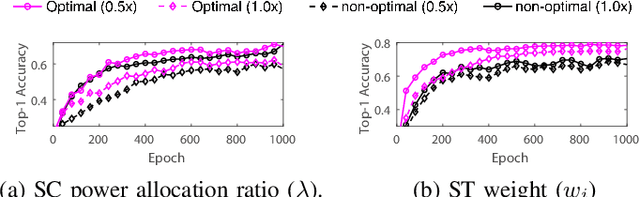
This paper aims to integrate two synergetic technologies, federated learning (FL) and width-adjustable slimmable neural network (SNN) architectures. FL preserves data privacy by exchanging the locally trained models of mobile devices. By adopting SNNs as local models, FL can flexibly cope with the time-varying energy capacities of mobile devices. Combining FL and SNNs is however non-trivial, particularly under wireless connections with time-varying channel conditions. Furthermore, existing multi-width SNN training algorithms are sensitive to the data distributions across devices, so are ill-suited to FL. Motivated by this, we propose a communication and energy-efficient SNN-based FL (named SlimFL) that jointly utilizes superposition coding (SC) for global model aggregation and superposition training (ST) for updating local models. By applying SC, SlimFL exchanges the superposition of multiple width configurations that are decoded as many as possible for a given communication throughput. Leveraging ST, SlimFL aligns the forward propagation of different width configurations, while avoiding the inter-width interference during backpropagation. We formally prove the convergence of SlimFL. The result reveals that SlimFL is not only communication-efficient but also can counteract non-IID data distributions and poor channel conditions, which is also corroborated by simulations.
On-Board Federated Learning for Dense LEO Constellations
Nov 24, 2021
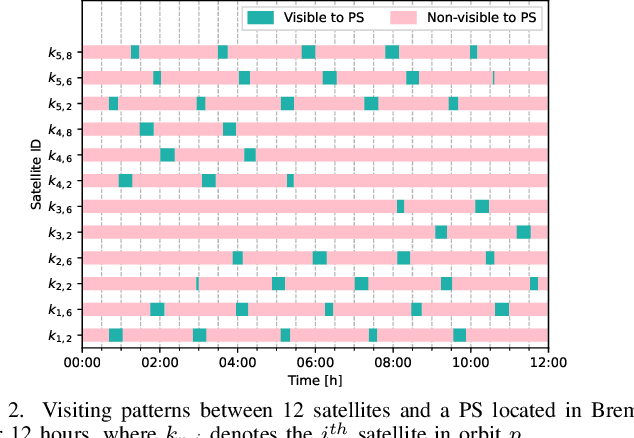
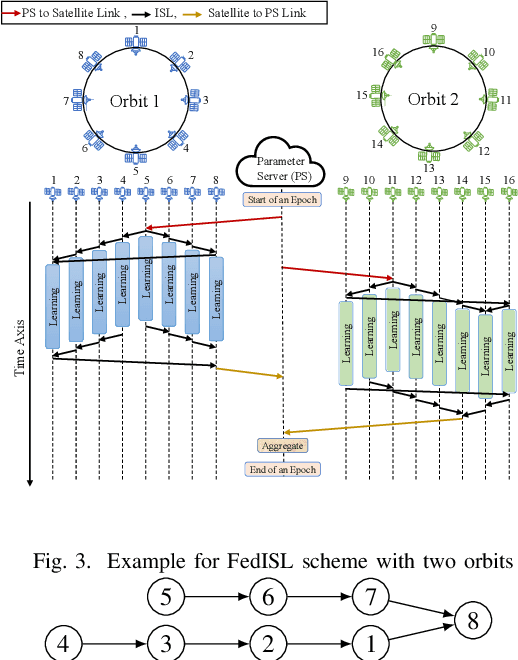

Mega-constellations of small-size Low Earth Orbit (LEO) satellites are currently planned and deployed by various private and public entities. While global connectivity is the main rationale, these constellations also offer the potential to gather immense amounts of data, e.g., for Earth observation. Power and bandwidth constraints together with motives like privacy, limiting delay, or resiliency make it desirable to process this data directly within the constellation. We consider the implementation of on-board federated learning (FL) orchestrated by an out-of-constellation parameter server (PS) and propose a novel communication scheme tailored to support FL. It leverages intra-orbit inter-satellite links, the predictability of satellite movements and partial aggregating to massively reduce the training time and communication costs. In particular, for a constellation with 40 satellites equally distributed among five low Earth orbits and the PS in medium Earth orbit, we observe a 29x speed-up in the training process time and a 8x traffic reduction at the PS over the baseline.
DSFormer: A Dual-domain Self-supervised Transformer for Accelerated Multi-contrast MRI Reconstruction
Jan 26, 2022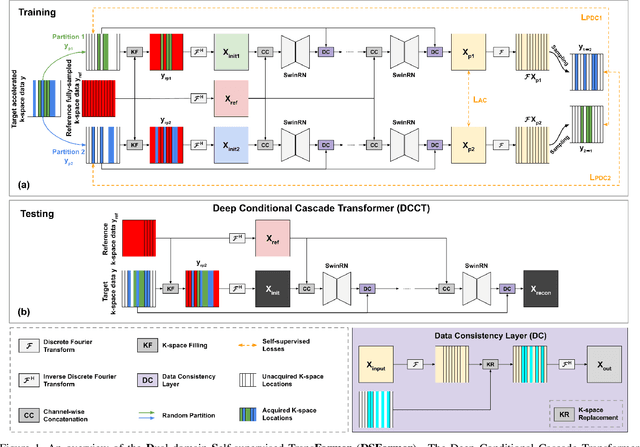
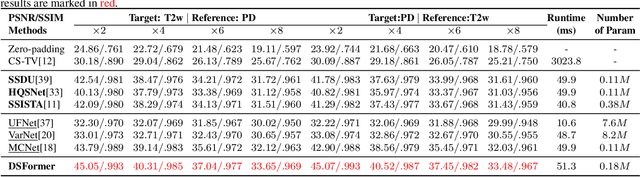
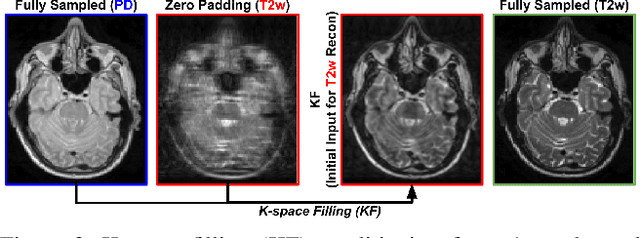
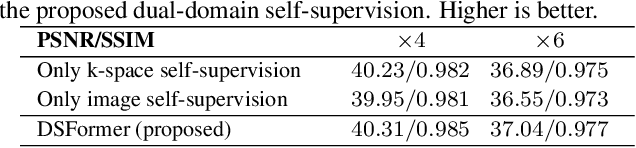
Multi-contrast MRI (MC-MRI) captures multiple complementary imaging modalities to aid in radiological decision-making. Given the need for lowering the time cost of multiple acquisitions, current deep accelerated MRI reconstruction networks focus on exploiting the redundancy between multiple contrasts. However, existing works are largely supervised with paired data and/or prohibitively expensive fully-sampled MRI sequences. Further, reconstruction networks typically rely on convolutional architectures which are limited in their capacity to model long-range interactions and may lead to suboptimal recovery of fine anatomical detail. To these ends, we present a dual-domain self-supervised transformer (DSFormer) for accelerated MC-MRI reconstruction. DSFormer develops a deep conditional cascade transformer (DCCT) consisting of several cascaded Swin transformer reconstruction networks (SwinRN) trained under two deep conditioning strategies to enable MC-MRI information sharing. We further present a dual-domain (image and k-space) self-supervised learning strategy for DCCT to alleviate the costs of acquiring fully sampled training data. DSFormer generates high-fidelity reconstructions which experimentally outperform current fully-supervised baselines. Moreover, we find that DSFormer achieves nearly the same performance when trained either with full supervision or with our proposed dual-domain self-supervision.
Recursive Least Squares Policy Control with Echo State Network
Jan 13, 2022The echo state network (ESN) is a special type of recurrent neural networks for processing the time-series dataset. However, limited by the strong correlation among sequential samples of the agent, ESN-based policy control algorithms are difficult to use the recursive least squares (RLS) algorithm to update the ESN's parameters. To solve this problem, we propose two novel policy control algorithms, ESNRLS-Q and ESNRLS-Sarsa. Firstly, to reduce the correlation of training samples, we use the leaky integrator ESN and the mini-batch learning mode. Secondly, to make RLS suitable for training ESN in mini-batch mode, we present a new mean-approximation method for updating the RLS correlation matrix. Thirdly, to prevent ESN from over-fitting, we use the L1 regularization technique. Lastly, to prevent the target state-action value from overestimation, we employ the Mellowmax method. Simulation results show that our algorithms have good convergence performance.