 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving Robustness and Uncertainty Modelling in Neural Ordinary Differential Equations
Dec 23, 2021
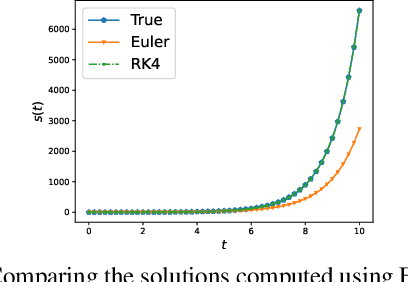

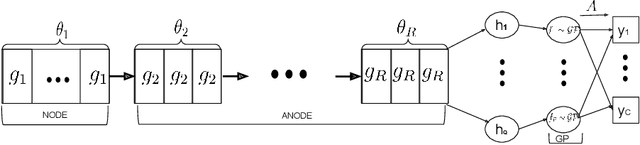

Neural ordinary differential equations (NODE) have been proposed as a continuous depth generalization to popular deep learning models such as Residual networks (ResNets). They provide parameter efficiency and automate the model selection process in deep learning models to some extent. However, they lack the much-required uncertainty modelling and robustness capabilities which are crucial for their use in several real-world applications such as autonomous driving and healthcare. We propose a novel and unique approach to model uncertainty in NODE by considering a distribution over the end-time $T$ of the ODE solver. The proposed approach, latent time NODE (LT-NODE), treats $T$ as a latent variable and apply Bayesian learning to obtain a posterior distribution over $T$ from the data. In particular, we use variational inference to learn an approximate posterior and the model parameters. Prediction is done by considering the NODE representations from different samples of the posterior and can be done efficiently using a single forward pass. As $T$ implicitly defines the depth of a NODE, posterior distribution over $T$ would also help in model selection in NODE. We also propose, adaptive latent time NODE (ALT-NODE), which allow each data point to have a distinct posterior distribution over end-times. ALT-NODE uses amortized variational inference to learn an approximate posterior using inference networks. We demonstrate the effectiveness of the proposed approaches in modelling uncertainty and robustness through experiments on synthetic and several real-world image classification data.
* Winter Conference on Applications of Computer Vision, 2021
PREVIS -- A Combined Machine Learning and Visual Interpolation Approach for Interactive Reverse Engineering in Assembly Quality Control
Jan 25, 2022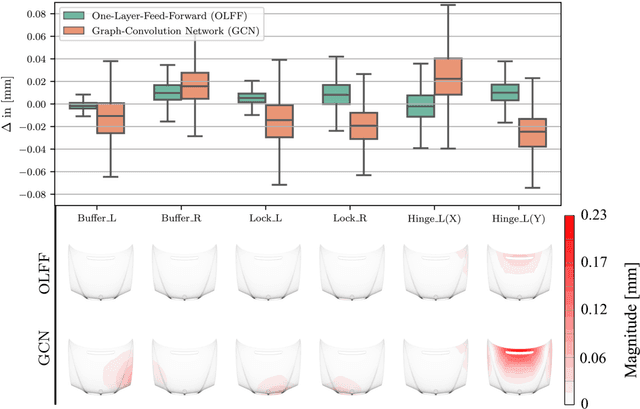
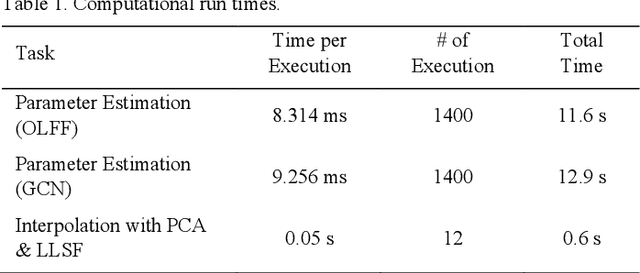
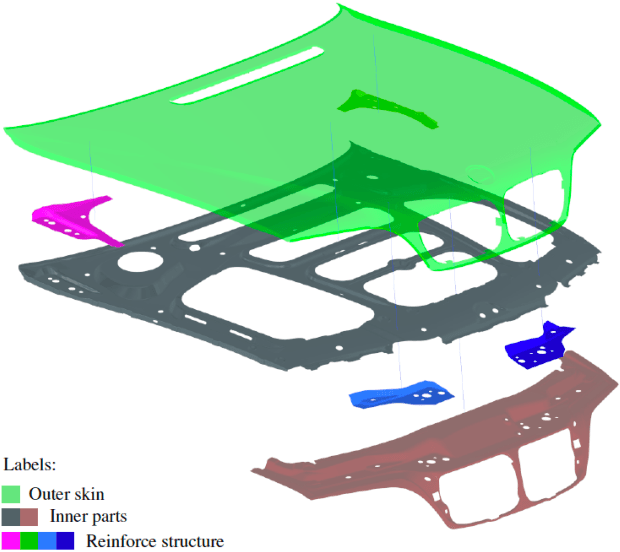
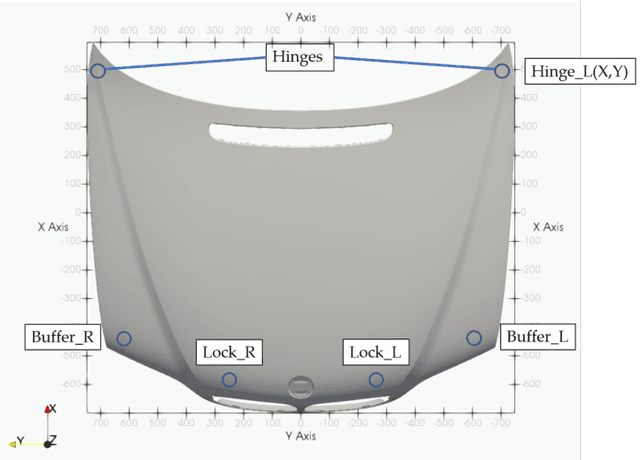
We present PREVIS, a visual analytics tool, enhancing machine learning performance analysis in engineering applications. The presented toolchain allows for a direct comparison of regression models. In addition, we provide a methodology to visualize the impact of regression errors on the underlying field of interest in the original domain, the part geometry, via exploiting standard interpolation methods. Further, we allow a real-time preview of user-driven parameter changes in the displacement field via visual interpolation. This allows for fast and accountable online change management. We demonstrate the effectiveness with an ex-ante optimization of an automotive engine hood.
IDP-Z3: a reasoning engine for FO(.)
Feb 01, 2022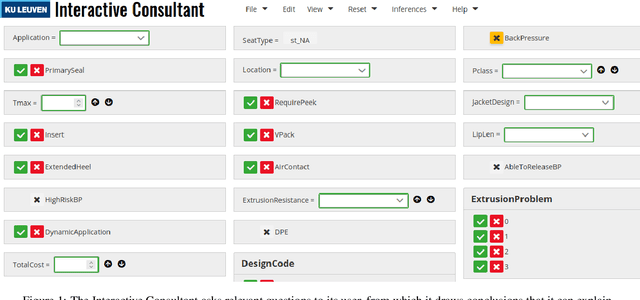



FO(.) (aka FO-dot) is a language that extends classical first-order logic with constructs to allow complex knowledge to be represented in a natural and elaboration-tolerant way. IDP-Z3 is a new reasoning engine for the FO(.) language: it can perform a variety of generic computational tasks using knowledge represented in FO(.). It supersedes IDP3, its predecessor, with new capabilities such as support for linear arithmetic over reals and quantification over concepts. We present four knowledge-intensive industrial use cases, and show that IDP-Z3 delivers real value to its users at low development costs: it supports interactive applications in a variety of problem domains, with a response time typically below 3 seconds.
Lightweight Temporal Self-Attention for Classifying Satellite Image Time Series
Jul 06, 2020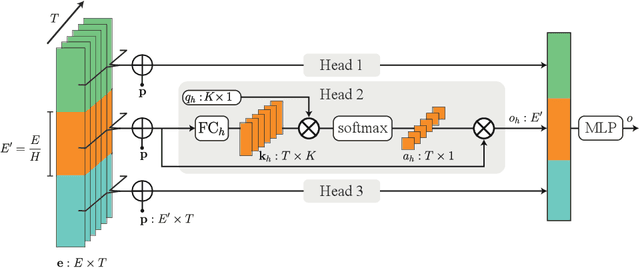
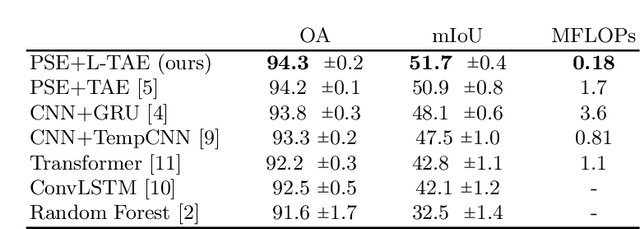
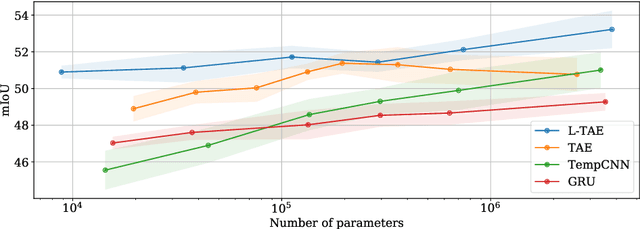
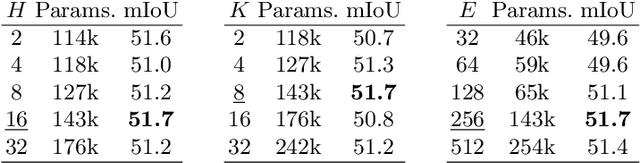
The increasing accessibility and precision of Earth observation satellite data offers considerable opportunities for industrial and state actors alike. This calls however for efficient methods able to process time-series on a global scale. Building on recent work employing multi-headed self-attention mechanisms to classify remote sensing time sequences, we propose a modification of the Temporal Attention Encoder. In our network, the channels of the temporal inputs are distributed among several compact attention heads operating in parallel. Each head extracts highly-specialized temporal features which are in turn concatenated into a single representation. Our approach outperforms other state-of-the-art time series classification algorithms on an open-access satellite image dataset, while using significantly fewer parameters and with a reduced computational complexity.
Augmenting Neural Networks with Priors on Function Values
Feb 21, 2022



The need for function estimation in label-limited settings is common in the natural sciences. At the same time, prior knowledge of function values is often available in these domains. For example, data-free biophysics-based models can be informative on protein properties, while quantum-based computations can be informative on small molecule properties. How can we coherently leverage such prior knowledge to help improve a neural network model that is quite accurate in some regions of input space -- typically near the training data -- but wildly wrong in other regions? Bayesian neural networks (BNN) enable the user to specify prior information only on the neural network weights, not directly on the function values. Moreover, there is in general no clear mapping between these. Herein, we tackle this problem by developing an approach to augment BNNs with prior information on the function values themselves. Our probabilistic approach yields predictions that rely more heavily on the prior information when the epistemic uncertainty is large, and more heavily on the neural network when the epistemic uncertainty is small.
Deep Impulse Responses: Estimating and Parameterizing Filters with Deep Networks
Feb 07, 2022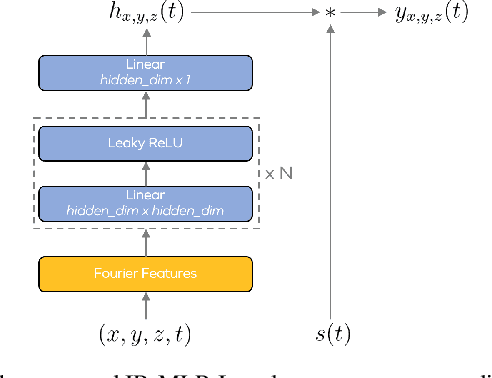

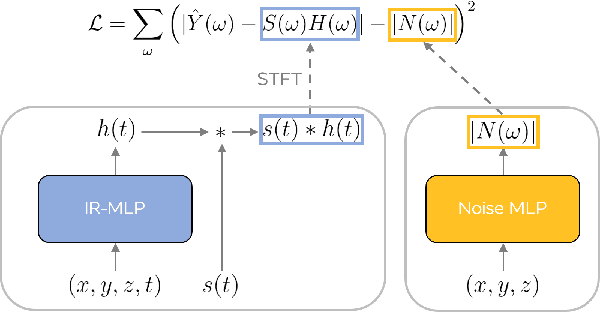
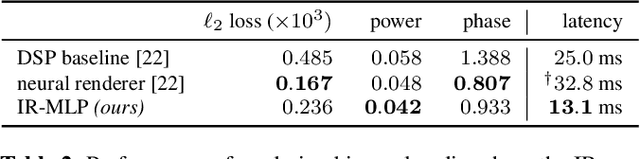
Impulse response estimation in high noise and in-the-wild settings, with minimal control of the underlying data distributions, is a challenging problem. We propose a novel framework for parameterizing and estimating impulse responses based on recent advances in neural representation learning. Our framework is driven by a carefully designed neural network that jointly estimates the impulse response and the (apriori unknown) spectral noise characteristics of an observed signal given the source signal. We demonstrate robustness in estimation, even under low signal-to-noise ratios, and show strong results when learning from spatio-temporal real-world speech data. Our framework provides a natural way to interpolate impulse responses on a spatial grid, while also allowing for efficiently compressing and storing them for real-time rendering applications in augmented and virtual reality.
Double Thompson Sampling in Finite stochastic Games
Feb 21, 2022We consider the trade-off problem between exploration and exploitation under finite discounted Markov Decision Process, where the state transition matrix of the underlying environment stays unknown. We propose a double Thompson sampling reinforcement learning algorithm(DTS) to solve this kind of problem. This algorithm achieves a total regret bound of $\tilde{\mathcal{O}}(D\sqrt{SAT})$\footnote{The symbol $\tilde{\mathcal{O}}$ means $\mathcal{O}$ with log factors ignored} in time horizon $T$ with $S$ states, $A$ actions and diameter $D$. DTS consists of two parts, the first part is the traditional part where we apply the posterior sampling method on transition matrix based on prior distribution. In the second part, we employ a count-based posterior update method to balance between the local optimal action and the long-term optimal action in order to find the global optimal game value. We established a regret bound of $\tilde{\mathcal{O}}(\sqrt{T}/S^{2})$. Which is by far the best regret bound for finite discounted Markov Decision Process to our knowledge. Numerical results proves the efficiency and superiority of our approach.
NeRF-Pose: A First-Reconstruct-Then-Regress Approach for Weakly-supervised 6D Object Pose Estimation
Mar 09, 2022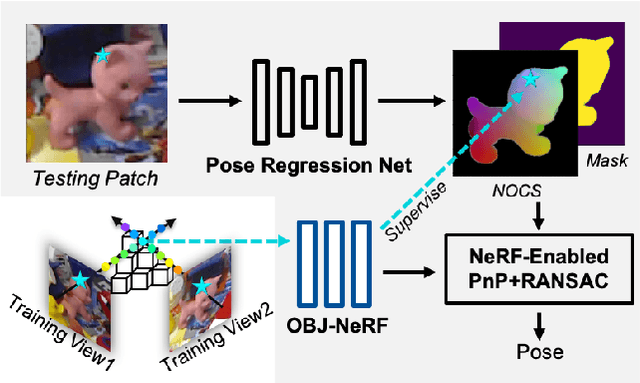
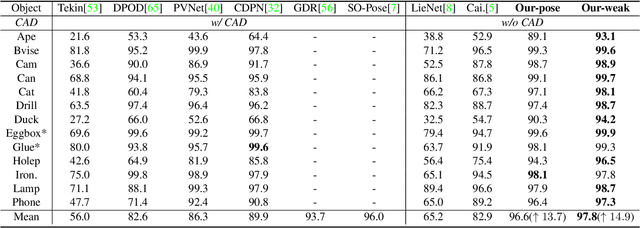
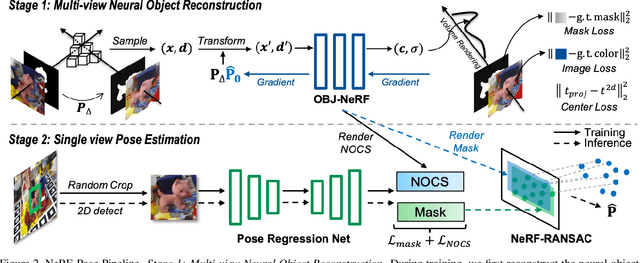
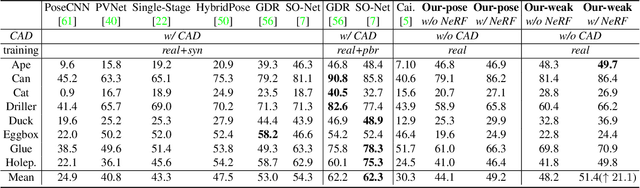
Pose estimation of 3D objects in monocular images is a fundamental and long-standing problem in computer vision. Existing deep learning approaches for 6D pose estimation typically rely on the assumption of availability of 3D object models and 6D pose annotations. However, precise annotation of 6D poses in real data is intricate, time-consuming and not scalable, while synthetic data scales well but lacks realism. To avoid these problems, we present a weakly-supervised reconstruction-based pipeline, named NeRF-Pose, which needs only 2D object segmentation and known relative camera poses during training. Following the first-reconstruct-then-regress idea, we first reconstruct the objects from multiple views in the form of an implicit neural representation. Then, we train a pose regression network to predict pixel-wise 2D-3D correspondences between images and the reconstructed model. At inference, the approach only needs a single image as input. A NeRF-enabled PnP+RANSAC algorithm is used to estimate stable and accurate pose from the predicted correspondences. Experiments on LineMod and LineMod-Occlusion show that the proposed method has state-of-the-art accuracy in comparison to the best 6D pose estimation methods in spite of being trained only with weak labels. Besides, we extend the Homebrewed DB dataset with more real training images to support the weakly supervised task and achieve compelling results on this dataset. The extended dataset and code will be released soon.
Deep Layer-wise Networks Have Closed-Form Weights
Feb 07, 2022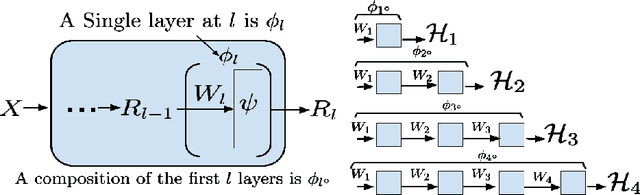
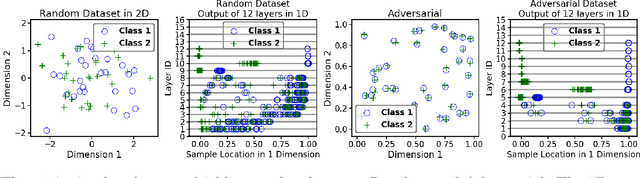
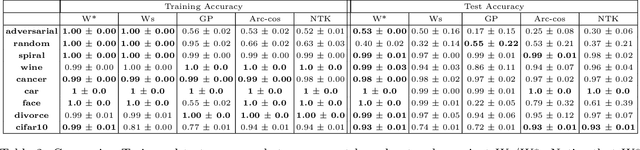
There is currently a debate within the neuroscience community over the likelihood of the brain performing backpropagation (BP). To better mimic the brain, training a network \textit{one layer at a time} with only a "single forward pass" has been proposed as an alternative to bypass BP; we refer to these networks as "layer-wise" networks. We continue the work on layer-wise networks by answering two outstanding questions. First, $\textit{do they have a closed-form solution?}$ Second, $\textit{how do we know when to stop adding more layers?}$ This work proves that the Kernel Mean Embedding is the closed-form weight that achieves the network global optimum while driving these networks to converge towards a highly desirable kernel for classification; we call it the $\textit{Neural Indicator Kernel}$.
* Since this version is similar to an older version, I should have updated the older version instead of creating a new version. I will now retract this version, and update a previous version to this. See arXiv:2006.08539
Neural Data-Dependent Transform for Learned Image Compression
Mar 09, 2022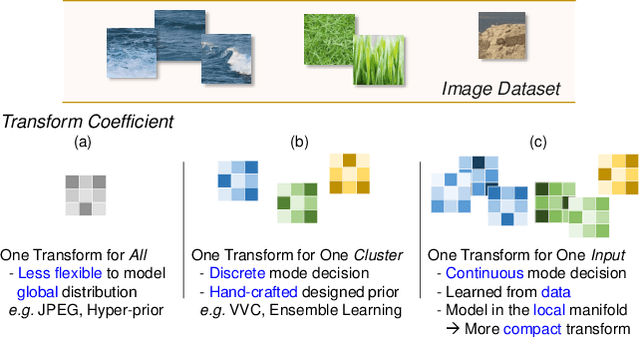
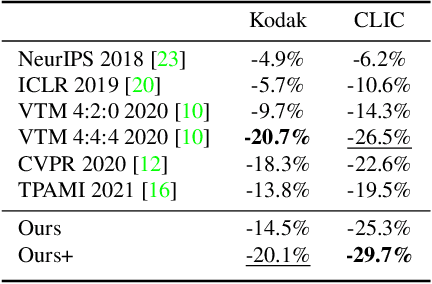
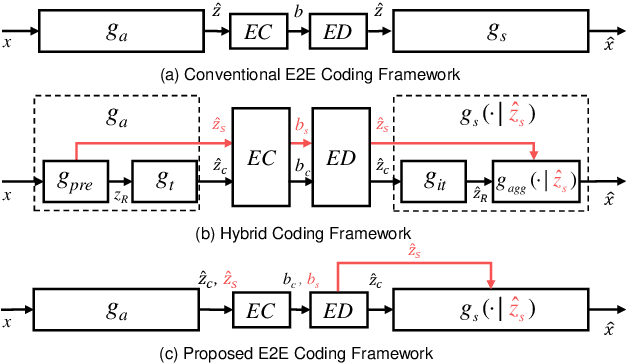
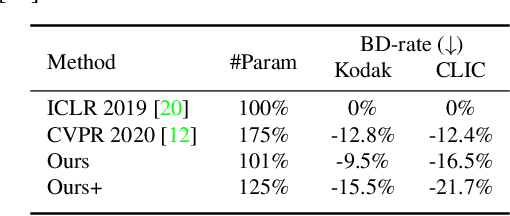
Learned image compression has achieved great success due to its excellent modeling capacity, but seldom further considers the Rate-Distortion Optimization (RDO) of each input image. To explore this potential in the learned codec, we make the first attempt to build a neural data-dependent transform and introduce a continuous online mode decision mechanism to jointly optimize the coding efficiency for each individual image. Specifically, apart from the image content stream, we employ an additional model stream to generate the transform parameters at the decoder side. The presence of a model stream enables our model to learn more abstract neural-syntax, which helps cluster the latent representations of images more compactly. Beyond the transform stage, we also adopt neural-syntax based post-processing for the scenarios that require higher quality reconstructions regardless of extra decoding overhead. Moreover, the involvement of the model stream further makes it possible to optimize both the representation and the decoder in an online way, i.e. RDO at the testing time. It is equivalent to a continuous online mode decision, like coding modes in the traditional codecs, to improve the coding efficiency based on the individual input image. The experimental results show the effectiveness of the proposed neural-syntax design and the continuous online mode decision mechanism, demonstrating the superiority of our method in coding efficiency compared to the latest conventional standard Versatile Video Coding (VVC) and other state-of-the-art learning-based methods.