 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Neural CDEs for Long Time Series via the Log-ODE Method
Sep 17, 2020
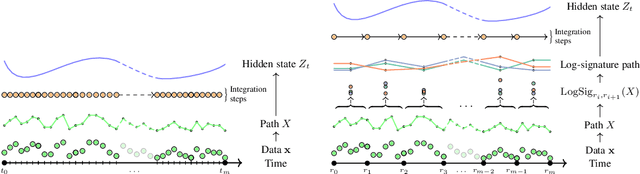
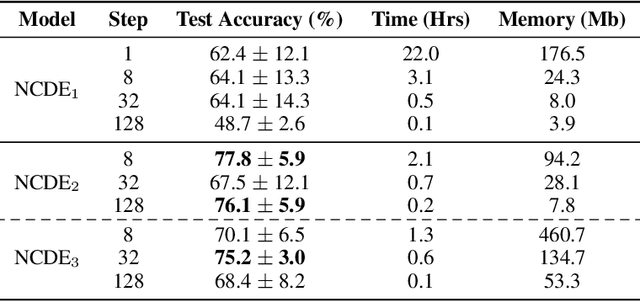
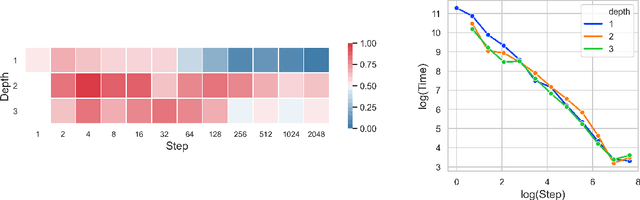
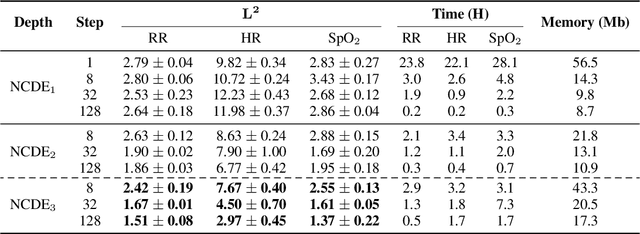
Neural Controlled Differential Equations (Neural CDEs) are the continuous-time analogue of an RNN, just as Neural ODEs are analogous to ResNets. However just like RNNs, training Neural CDEs can be difficult for long time series. Here, we propose to apply a technique drawn from stochastic analysis, namely the log-ODE method. Instead of using the original input sequence, our procedure summarises the information over local time intervals via the log-signature map, and uses the resulting shorter stream of log-signatures as the new input. This represents a length/channel trade-off. In doing so we demonstrate efficacy on problems of length up to 17k observations and observe significant training speed-ups, improvements in model performance, and reduced memory requirements compared to the existing algorithm.
Echofilter: A Deep Learning Segmentation Model Improves the Automation, Standardization, and Timeliness for Post-Processing Echosounder Data in Tidal Energy Streams
Feb 19, 2022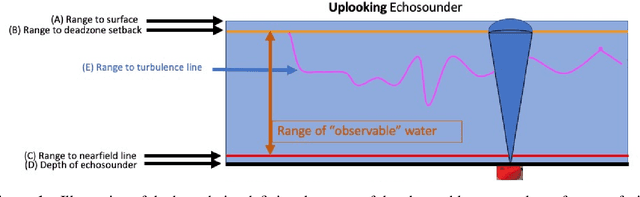

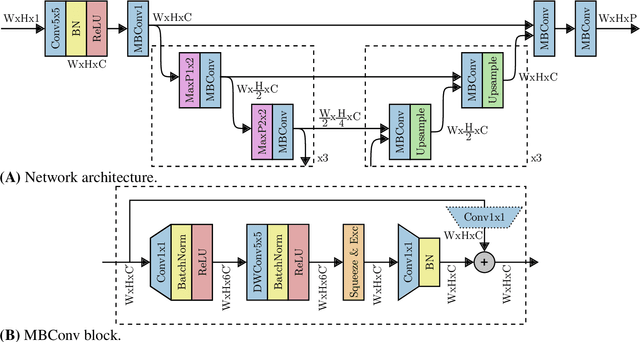

Understanding the abundance and distribution of fish in tidal energy streams is important for assessing the risk presented by the introduction of tidal energy devices into the habitat. However, the impressive tidal currents that make sites favorable for tidal energy development are often highly turbulent and entrain air into the water, complicating the interpretation of echosounder data. The portion of the water column contaminated by returns from entrained air must be excluded from data used for biological analyses. Application of a single algorithm to identify the depth-of-penetration of entrained-air is insufficient for a boundary that is discontinuous, depth-dynamic, porous, and widely variable across the tidal flow speeds which can range from 0 to 5m/s. Using a case study at a tidal energy demonstration site in the Bay of Fundy, we describe the development and application of deep learning models that produce a pronounced, consistent, substantial, and measurable improvement of the automated detection of the extent to which entrained-air has penetrated the water column. Our model, Echofilter, was highly responsive to the dynamic range of turbulence conditions and sensitive to the fine-scale nuances in the boundary position, producing an entrained-air boundary line with an average error of 0.32m on mobile downfacing and 0.5-1.0m on stationary upfacing data. The model's annotations had a high level of agreement with the human segmentation (mobile downfacing Jaccard index: 98.8%; stationary upfacing: 93-95%). This resulted in a 50% reduction in the time required for manual edits compared to the time required to manually edit the line placed by currently available algorithms. Because of the improved initial automated placement, the implementation of the models generated a marked increase in the standardization and repeatability of line placement.
Recursive Decoding: A Situated Cognition Approach to Compositional Generation in Grounded Language Understanding
Jan 27, 2022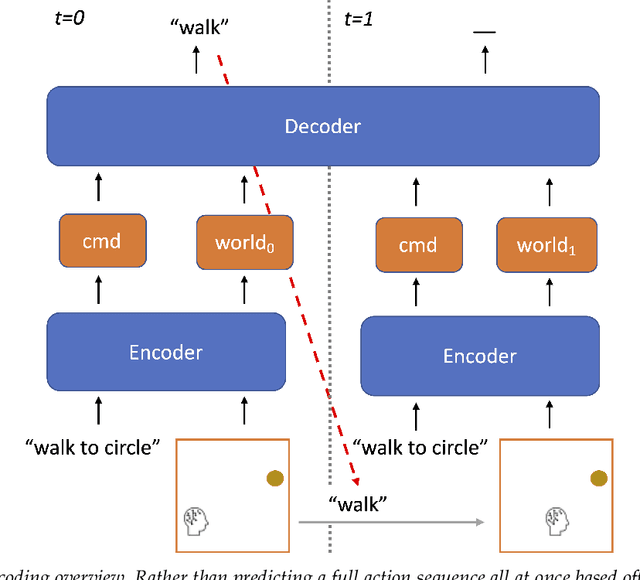
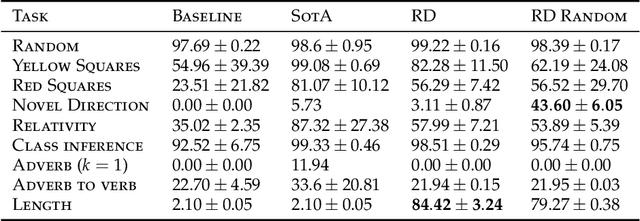
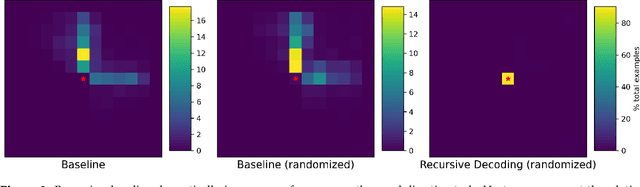
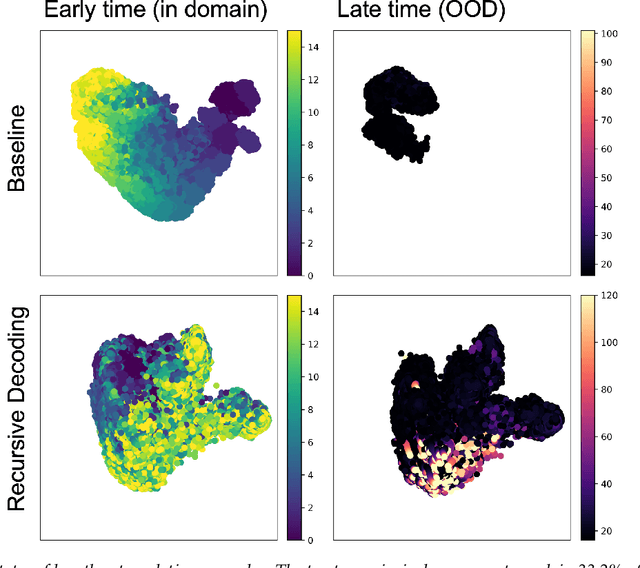
Compositional generalization is a troubling blind spot for neural language models. Recent efforts have presented techniques for improving a model's ability to encode novel combinations of known inputs, but less work has focused on generating novel combinations of known outputs. Here we focus on this latter "decode-side" form of generalization in the context of gSCAN, a synthetic benchmark for compositional generalization in grounded language understanding. We present Recursive Decoding (RD), a novel procedure for training and using seq2seq models, targeted towards decode-side generalization. Rather than generating an entire output sequence in one pass, models are trained to predict one token at a time. Inputs (i.e., the external gSCAN environment) are then incrementally updated based on predicted tokens, and re-encoded for the next decoder time step. RD thus decomposes a complex, out-of-distribution sequence generation task into a series of incremental predictions that each resemble what the model has already seen during training. RD yields dramatic improvement on two previously neglected generalization tasks in gSCAN. We provide analyses to elucidate these gains over failure of a baseline, and then discuss implications for generalization in naturalistic grounded language understanding, and seq2seq more generally.
Dynamic imaging using Motion-Compensated SmooThness Regularization on Manifolds (MoCo-SToRM)
Dec 06, 2021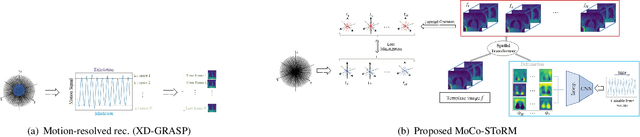
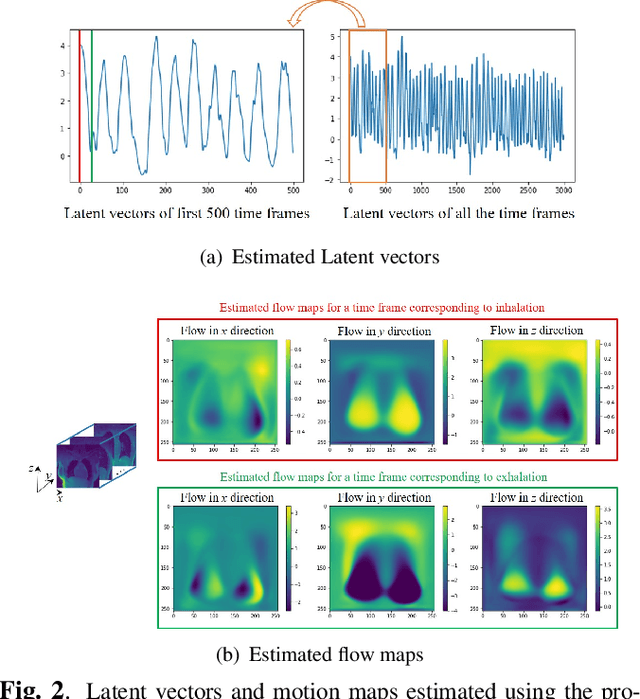
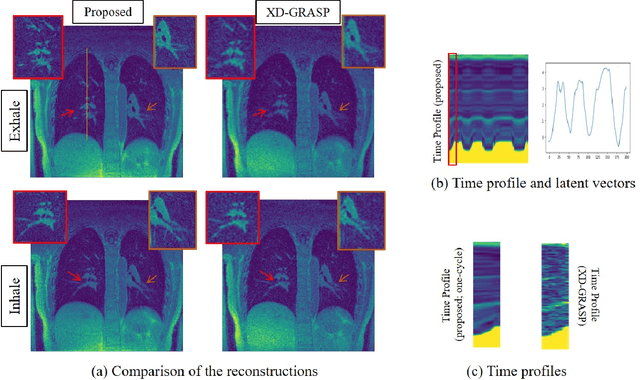
We introduce an unsupervised motion-compensated reconstruction scheme for high-resolution free-breathing pulmonary MRI. We model the image frames in the time series as the deformed version of the 3D template image volume. We assume the deformation maps to be points on a smooth manifold in high-dimensional space. Specifically, we model the deformation map at each time instant as the output of a CNN-based generator that has the same weight for all time-frames, driven by a low-dimensional latent vector. The time series of latent vectors account for the dynamics in the dataset, including respiratory motion and bulk motion. The template image volume, the parameters of the generator, and the latent vectors are learned directly from the k-t space data in an unsupervised fashion. Our experimental results show improved reconstructions compared to state-of-the-art methods, especially in the context of bulk motion during the scans.
Meta-Learning for Online Update of Recommender Systems
Mar 19, 2022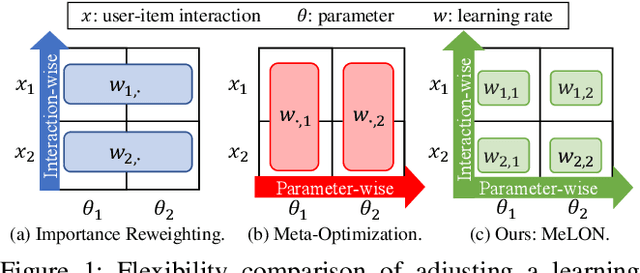
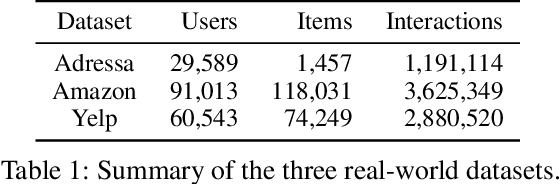
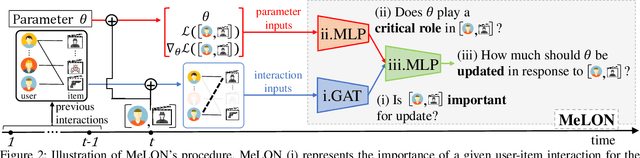
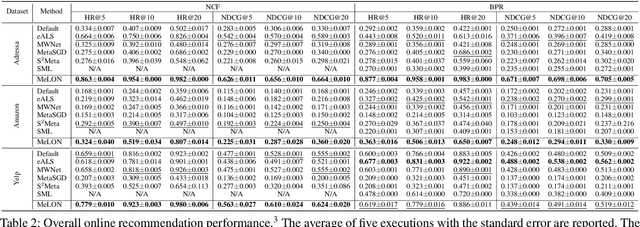
Online recommender systems should be always aligned with users' current interest to accurately suggest items that each user would like. Since user interest usually evolves over time, the update strategy should be flexible to quickly catch users' current interest from continuously generated new user-item interactions. Existing update strategies focus either on the importance of each user-item interaction or the learning rate for each recommender parameter, but such one-directional flexibility is insufficient to adapt to varying relationships between interactions and parameters. In this paper, we propose MeLON, a meta-learning based novel online recommender update strategy that supports two-directional flexibility. It is featured with an adaptive learning rate for each parameter-interaction pair for inducing a recommender to quickly learn users' up-to-date interest. The procedure of MeLON is optimized following a meta-learning approach: it learns how a recommender learns to generate the optimal learning rates for future updates. Specifically, MeLON first enriches the meaning of each interaction based on previous interactions and identifies the role of each parameter for the interaction; and then combines these two pieces of information to generate an adaptive learning rate. Theoretical analysis and extensive evaluation on three real-world online recommender datasets validate the effectiveness of MeLON.
* 11 pages, 6 figures
Weisfeiler-Lehman meets Gromov-Wasserstein
Feb 05, 2022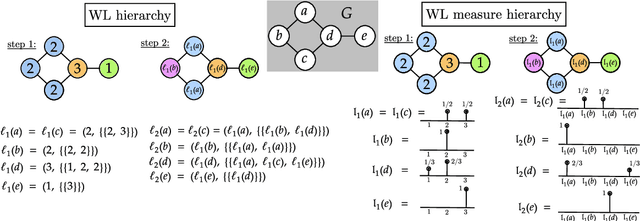


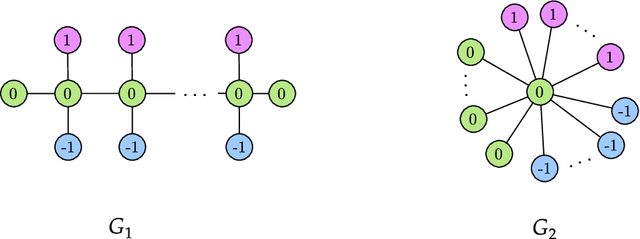
The Weisfeiler-Lehman (WL) test is a classical procedure for graph isomorphism testing. The WL test has also been widely used both for designing graph kernels and for analyzing graph neural networks. In this paper, we propose the Weisfeiler-Lehman (WL) distance, a notion of distance between labeled measure Markov chains (LMMCs), of which labeled graphs are special cases. The WL distance is polynomial time computable and is also compatible with the WL test in the sense that the former is positive if and only if the WL test can distinguish the two involved graphs. The WL distance captures and compares subtle structures of the underlying LMMCs and, as a consequence of this, it is more discriminating than the distance between graphs used for defining the state-of-the-art Wasserstein Weisfeiler-Lehman graph kernel. Inspired by the structure of the WL distance we identify a neural network architecture on LMMCs which turns out to be universal w.r.t. continuous functions defined on the space of all LMMCs (which includes all graphs) endowed with the WL distance. Finally, the WL distance turns out to be stable w.r.t. a natural variant of the Gromov-Wasserstein (GW) distance for comparing metric Markov chains that we identify. Hence, the WL distance can also be construed as a polynomial time lower bound for the GW distance which is in general NP-hard to compute.
Occlusion-Aware Self-Supervised Monocular 6D Object Pose Estimation
Mar 19, 2022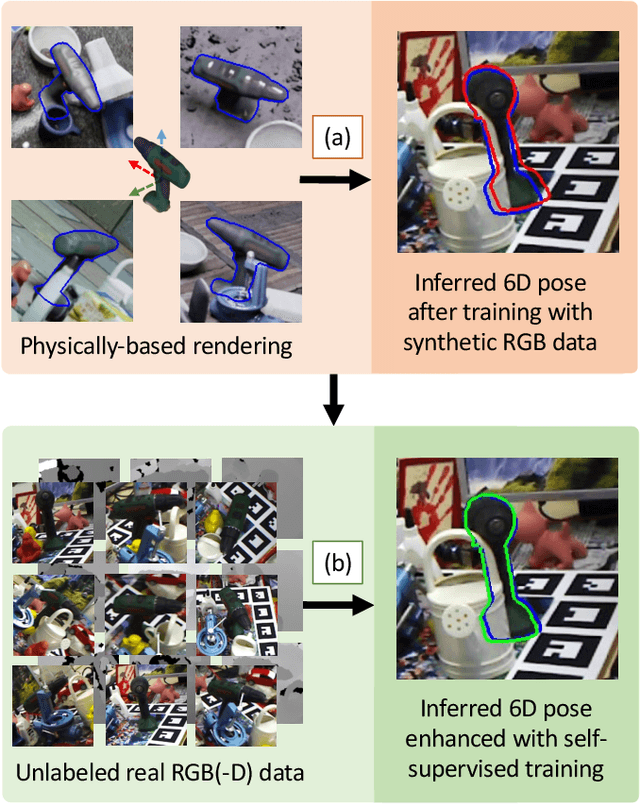

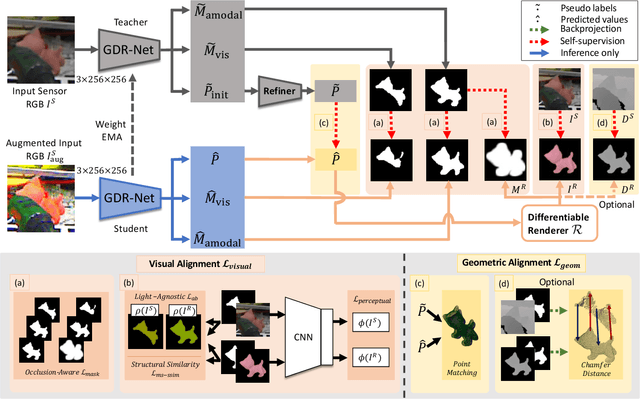

6D object pose estimation is a fundamental yet challenging problem in computer vision. Convolutional Neural Networks (CNNs) have recently proven to be capable of predicting reliable 6D pose estimates even under monocular settings. Nonetheless, CNNs are identified as being extremely data-driven, and acquiring adequate annotations is oftentimes very time-consuming and labor intensive. To overcome this limitation, we propose a novel monocular 6D pose estimation approach by means of self-supervised learning, removing the need for real annotations. After training our proposed network fully supervised with synthetic RGB data, we leverage current trends in noisy student training and differentiable rendering to further self-supervise the model on these unsupervised real RGB(-D) samples, seeking for a visually and geometrically optimal alignment. Moreover, employing both visible and amodal mask information, our self-supervision becomes very robust towards challenging scenarios such as occlusion. Extensive evaluations demonstrate that our proposed self-supervision outperforms all other methods relying on synthetic data or employing elaborate techniques from the domain adaptation realm. Noteworthy, our self-supervised approach consistently improves over its synthetically trained baseline and often almost closes the gap towards its fully supervised counterpart. The code and models are publicly available at https://github.com/THU-DA-6D-Pose-Group/self6dpp.git.
Neural Ordinary Differential Equations for Nonlinear System Identification
Feb 28, 2022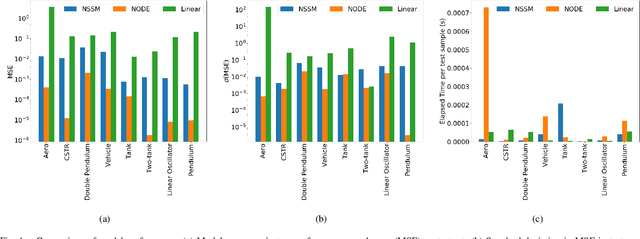
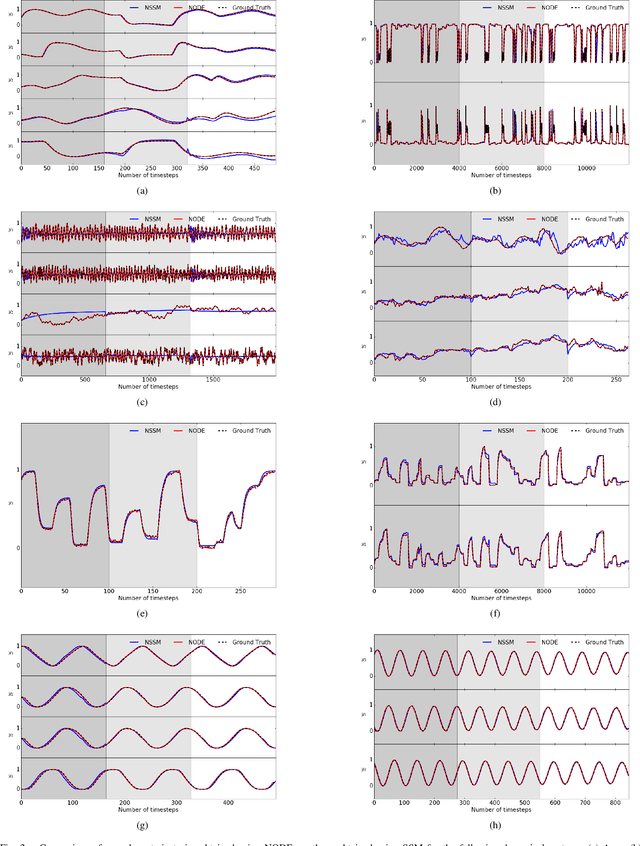
Neural ordinary differential equations (NODE) have been recently proposed as a promising approach for nonlinear system identification tasks. In this work, we systematically compare their predictive performance with current state-of-the-art nonlinear and classical linear methods. In particular, we present a quantitative study comparing NODE's performance against neural state-space models and classical linear system identification methods. We evaluate the inference speed and prediction performance of each method on open-loop errors across eight different dynamical systems. The experiments show that NODEs can consistently improve the prediction accuracy by an order of magnitude compared to benchmark methods. Besides improved accuracy, we also observed that NODEs are less sensitive to hyperparameters compared to neural state-space models. On the other hand, these performance gains come with a slight increase of computation at the inference time.
Interspace Pruning: Using Adaptive Filter Representations to Improve Training of Sparse CNNs
Mar 15, 2022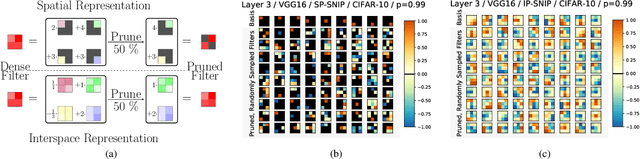

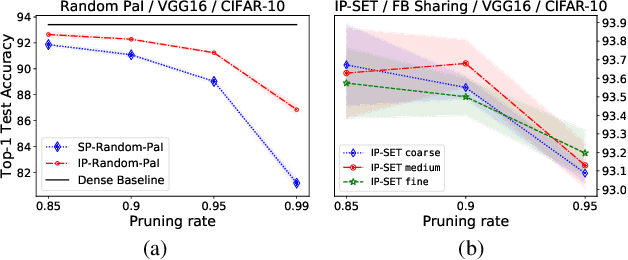
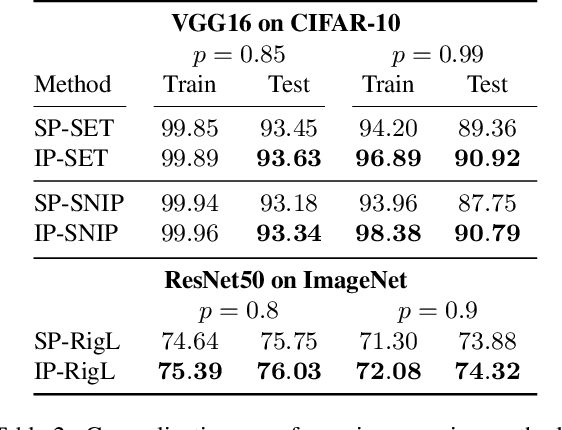
Unstructured pruning is well suited to reduce the memory footprint of convolutional neural networks (CNNs), both at training and inference time. CNNs contain parameters arranged in $K \times K$ filters. Standard unstructured pruning (SP) reduces the memory footprint of CNNs by setting filter elements to zero, thereby specifying a fixed subspace that constrains the filter. Especially if pruning is applied before or during training, this induces a strong bias. To overcome this, we introduce interspace pruning (IP), a general tool to improve existing pruning methods. It uses filters represented in a dynamic interspace by linear combinations of an underlying adaptive filter basis (FB). For IP, FB coefficients are set to zero while un-pruned coefficients and FBs are trained jointly. In this work, we provide mathematical evidence for IP's superior performance and demonstrate that IP outperforms SP on all tested state-of-the-art unstructured pruning methods. Especially in challenging situations, like pruning for ImageNet or pruning to high sparsity, IP greatly exceeds SP with equal runtime and parameter costs. Finally, we show that advances of IP are due to improved trainability and superior generalization ability.
A 1V 5-bits Low Power Level Crossing ADC with OFF state in idle time for bio-medical applications in 0.18um CMOS
Aug 17, 2021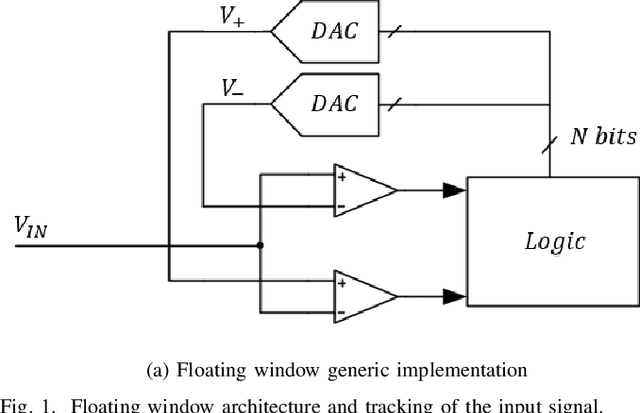
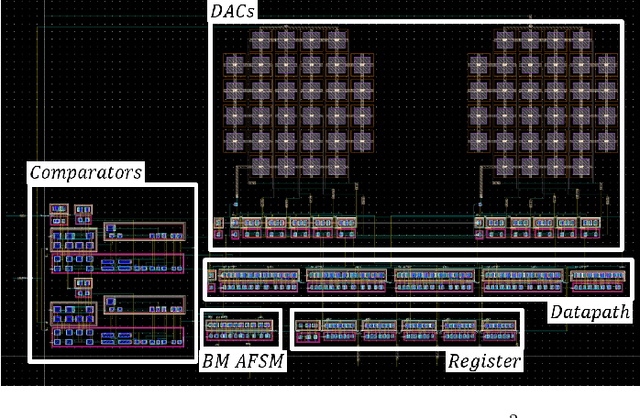
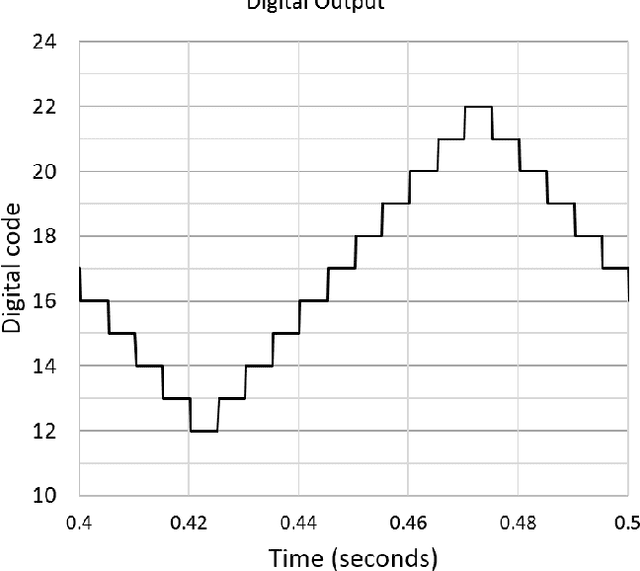
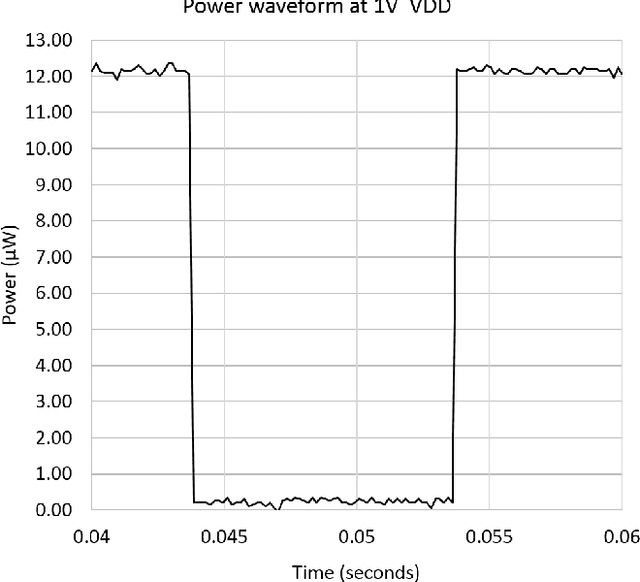
The ubiquitous use of sensing and signal processing is increasing exponentially with the advance of the Internet of Everything (IoE). In this context, the design of every time more power efficient sensor nodes is a must. Within these nodes, one of the most power-hungry components are the analog-to-digital converters (ADC). These components are used everywhere to translate real-world analog signals into computer intelligible digital signals. One of the promising architecture for the sensing of physiological signals is the level crossing ADC due to the sparse characteristics of those signals. One of the challenges to improve the power efficiency of this type of ADC lies in the use of continuous comparators to keep track of the input signal within the voltage references. The aim of this work is to investigate the impact of using continuous comparator which can be turned off without incurring error to the conversion of the level crossing ADC. New boundaries will be set for the correct behavior of the level crossing ADC together with the conditions for power saving with the proposed architecture. A 1V 5-bits level crossing ADC was implemented using the TSMC 0.18um process and fabricated for laboratory measurements. The ADC consumes 12.2uW during tracking state and with the proposed technique, the reduction of the average power can go from 4.2% to 45.5% depending on the activity and the type of the input signal.