 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
AIFB-WebScience at SemEval-2022 Task 12: Relation Extraction First -- Using Relation Extraction to Identify Entities
Mar 10, 2022
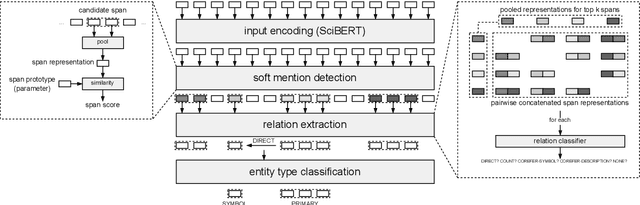
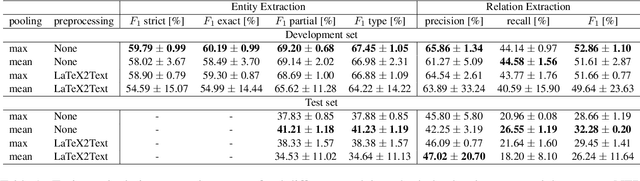
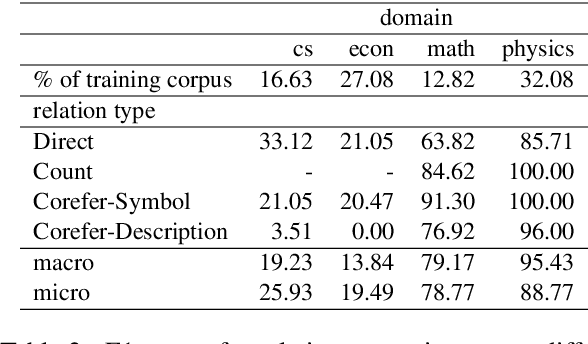
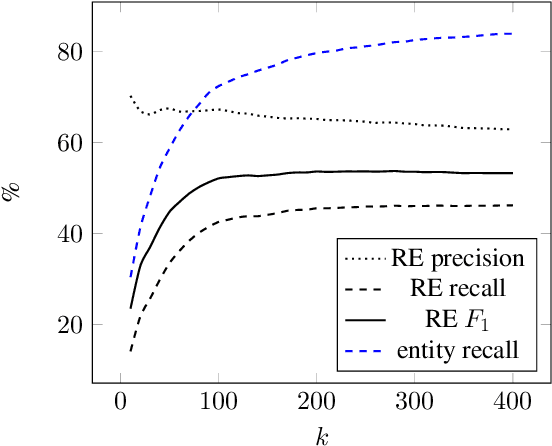
In this paper, we present an end-to-end joint entity and relation extraction approach based on transformer-based language models. We apply the model to the task of linking mathematical symbols to their descriptions in LaTeX documents. In contrast to existing approaches, which perform entity and relation extraction in sequence, our system incorporates information from relation extraction into entity extraction. This means that the system can be trained even on data sets where only a subset of all valid entity spans is annotated. We provide an extensive evaluation of the proposed system and its strengths and weaknesses. Our approach, which can be scaled dynamically in computational complexity at inference time, produces predictions with high precision and reaches 3rd place in the leaderboard of SemEval-2022 Task 12. For inputs in the domain of physics and math, it achieves high relation extraction macro f1 scores of 95.43% and 79.17%, respectively. The code used for training and evaluating our models is available at: https://github.com/nicpopovic/RE1st
Winograd Convolution: A Perspective from Fault Tolerance
Feb 17, 2022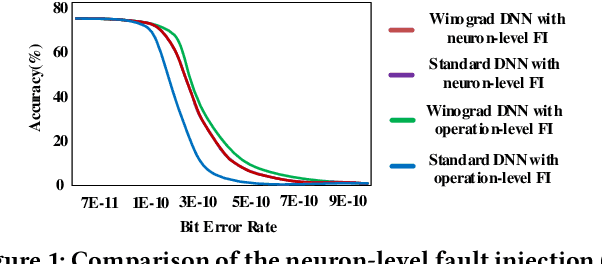
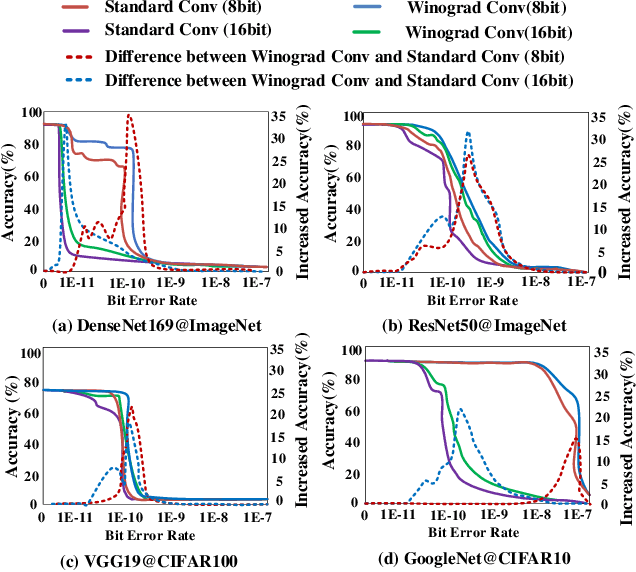
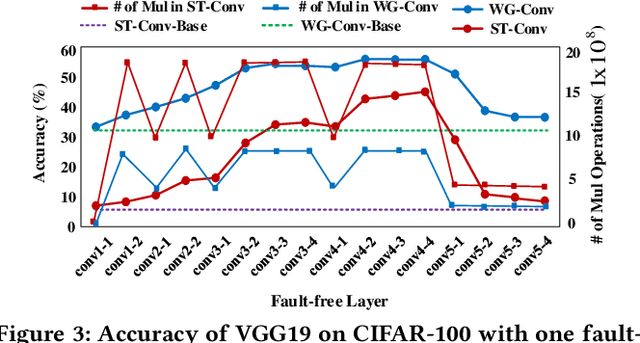
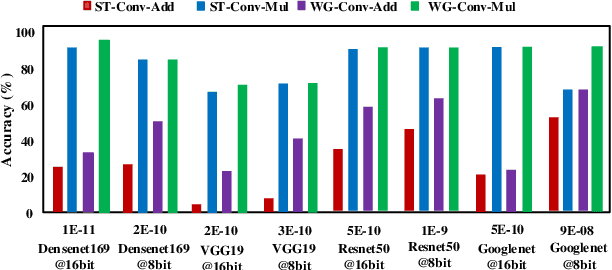
Winograd convolution is originally proposed to reduce the computing overhead by converting multiplication in neural network (NN) with addition via linear transformation. Other than the computing efficiency, we observe its great potential in improving NN fault tolerance and evaluate its fault tolerance comprehensively for the first time. Then, we explore the use of fault tolerance of winograd convolution for either fault-tolerant or energy-efficient NN processing. According to our experiments, winograd convolution can be utilized to reduce fault-tolerant design overhead by 27.49\% or energy consumption by 7.19\% without any accuracy loss compared to that without being aware of the fault tolerance
Learning Scene Flow in 3D Point Clouds with Noisy Pseudo Labels
Mar 23, 2022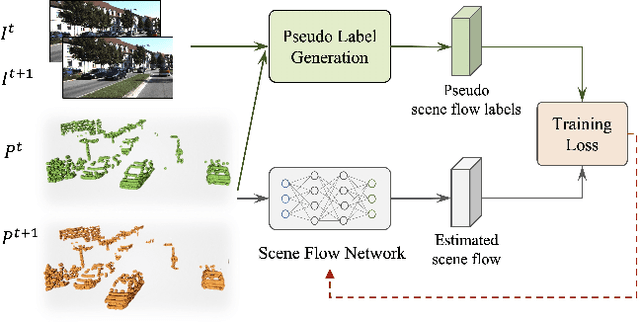
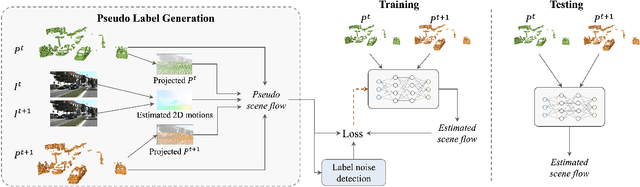

We propose a novel scene flow method that captures 3D motions from point clouds without relying on ground-truth scene flow annotations. Due to the irregularity and sparsity of point clouds, it is expensive and time-consuming to acquire ground-truth scene flow annotations. Some state-of-the-art approaches train scene flow networks in a self-supervised learning manner via approximating pseudo scene flow labels from point clouds. However, these methods fail to achieve the performance level of fully supervised methods, due to the limitations of point cloud such as sparsity and lacking color information. To provide an alternative, we propose a novel approach that utilizes monocular RGB images and point clouds to generate pseudo scene flow labels for training scene flow networks. Our pseudo label generation module infers pseudo scene labels for point clouds by jointly leveraging rich appearance information in monocular images and geometric information of point clouds. To further reduce the negative effect of noisy pseudo labels on the training, we propose a noisy-label-aware training scheme by exploiting the geometric relations of points. Experiment results show that our method not only outperforms state-of-the-art self-supervised approaches, but also outperforms some supervised approaches that use accurate ground-truth flows.
The Braess Paradox in Dynamic Traffic
Mar 07, 2022
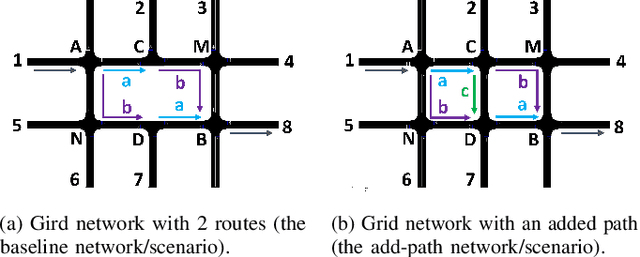
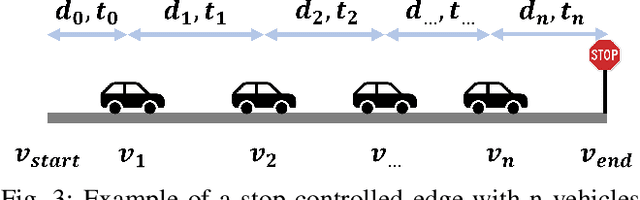
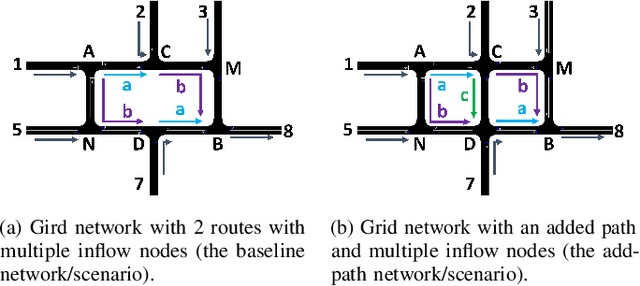
The Braess's Paradox (BP) is the observation that adding one or more roads to the existing road network will counter-intuitively increase traffic congestion and slow down the overall traffic flow. Previously, the existence of the BP is modeled using the static traffic assignment model, which solves for the user equilibrium subject to network flow conservation to find the equilibrium state and distributes all vehicles instantaneously. Such approach neglects the dynamic nature of real-world traffic, including vehicle behaviors and the interaction between vehicles and the infrastructure. As such, this article proposes a dynamic traffic network model and empirically validates the existence of the BP under dynamic traffic. In particular, we use microsimulation environment to study the impacts of an added path on a grid network. We explore how the network flow, vehicle travel time, and network capacity respond, as well as when the BP will occur.
Real-Time Glaucoma Detection from Digital Fundus Images using Self-ONNs
Sep 28, 2021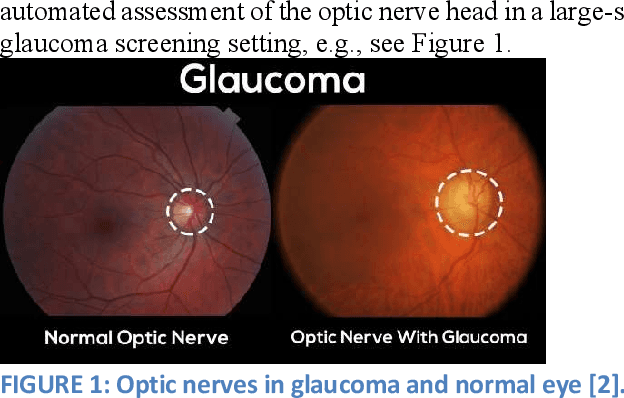
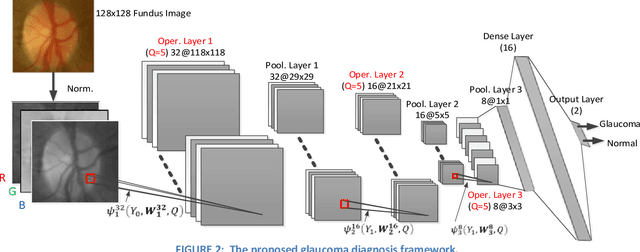
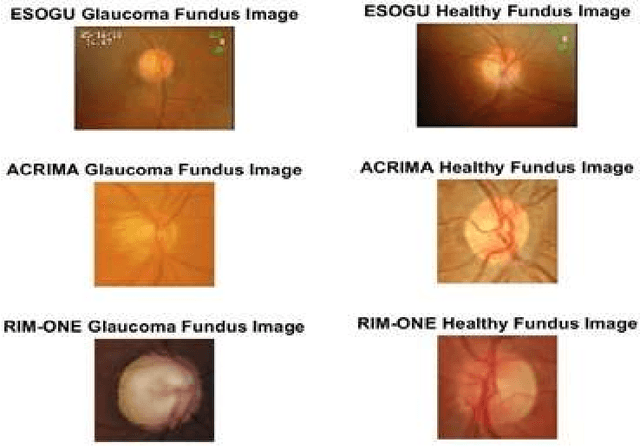

Glaucoma leads to permanent vision disability by damaging the optical nerve that transmits visual images to the brain. The fact that glaucoma does not show any symptoms as it progresses and cannot be stopped at the later stages, makes it critical to be diagnosed in its early stages. Although various deep learning models have been applied for detecting glaucoma from digital fundus images, due to the scarcity of labeled data, their generalization performance was limited along with high computational complexity and special hardware requirements. In this study, compact Self-Organized Operational Neural Networks (Self- ONNs) are proposed for early detection of glaucoma in fundus images and their performance is compared against the conventional (deep) Convolutional Neural Networks (CNNs) over three benchmark datasets: ACRIMA, RIM-ONE, and ESOGU. The experimental results demonstrate that Self-ONNs not only achieve superior detection performance but can also significantly reduce the computational complexity making it a potentially suitable network model for biomedical datasets especially when the data is scarce.
A Scalable Model Specialization Framework for Training and Inference using Submodels and its Application to Speech Model Personalization
Mar 23, 2022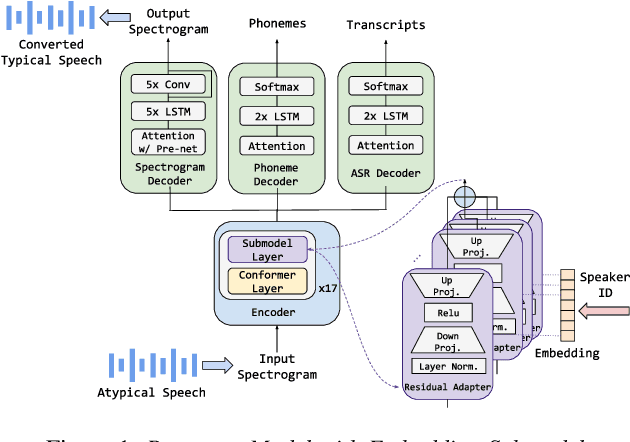
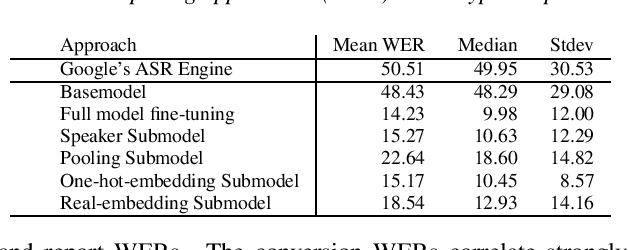
Model fine-tuning and adaptation have become a common approach for model specialization for downstream tasks or domains. Fine-tuning the entire model or a subset of the parameters using light-weight adaptation has shown considerable success across different specialization tasks. Fine-tuning a model for a large number of domains typically requires starting a new training job for every domain posing scaling limitations. Once these models are trained, deploying them also poses significant scalability challenges for inference for real-time applications. In this paper, building upon prior light-weight adaptation techniques, we propose a modular framework that enables us to substantially improve scalability for model training and inference. We introduce Submodels that can be quickly and dynamically loaded for on-the-fly inference. We also propose multiple approaches for training those Submodels in parallel using an embedding space in the same training job. We test our framework on an extreme use-case which is speech model personalization for atypical speech, requiring a Submodel for each user. We obtain 128x Submodel throughput with a fixed computation budget without a loss of accuracy. We also show that learning a speaker-embedding space can scale further and reduce the amount of personalization training data required per speaker.
Fast Doubly-Adaptive MCMC to Estimate the Gibbs Partition Function with Weak Mixing Time Bounds
Nov 14, 2021
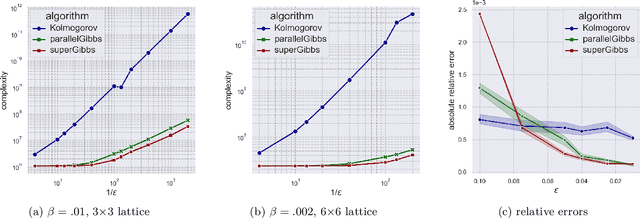
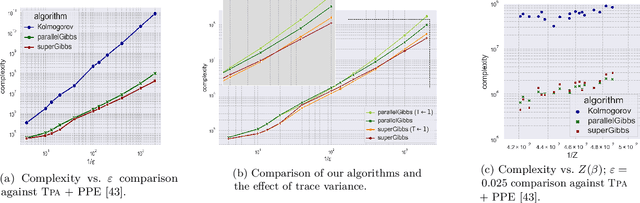
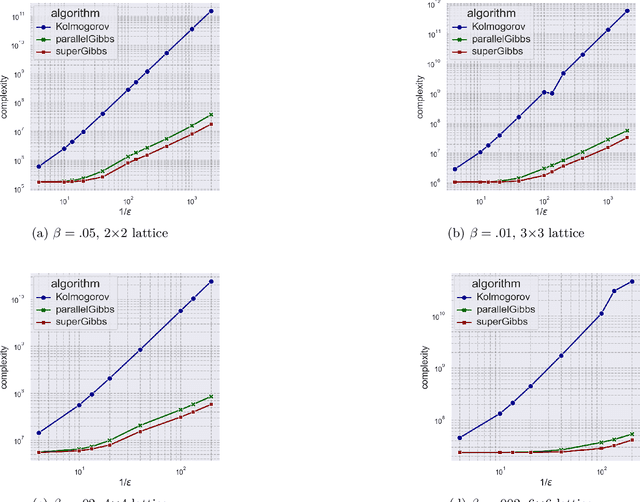
We present a novel method for reducing the computational complexity of rigorously estimating the partition functions (normalizing constants) of Gibbs (Boltzmann) distributions, which arise ubiquitously in probabilistic graphical models. A major obstacle to practical applications of Gibbs distributions is the need to estimate their partition functions. The state of the art in addressing this problem is multi-stage algorithms, which consist of a cooling schedule, and a mean estimator in each step of the schedule. While the cooling schedule in these algorithms is adaptive, the mean estimation computations use MCMC as a black-box to draw approximate samples. We develop a doubly adaptive approach, combining the adaptive cooling schedule with an adaptive MCMC mean estimator, whose number of Markov chain steps adapts dynamically to the underlying chain. Through rigorous theoretical analysis, we prove that our method outperforms the state of the art algorithms in several factors: (1) The computational complexity of our method is smaller; (2) Our method is less sensitive to loose bounds on mixing times, an inherent component in these algorithms; and (3) The improvement obtained by our method is particularly significant in the most challenging regime of high-precision estimation. We demonstrate the advantage of our method in experiments run on classic factor graphs, such as voting models and Ising models.
Echo-enabled Direction-of-Arrival and range estimation of a mobile source in Ambisonic domain
Mar 10, 2022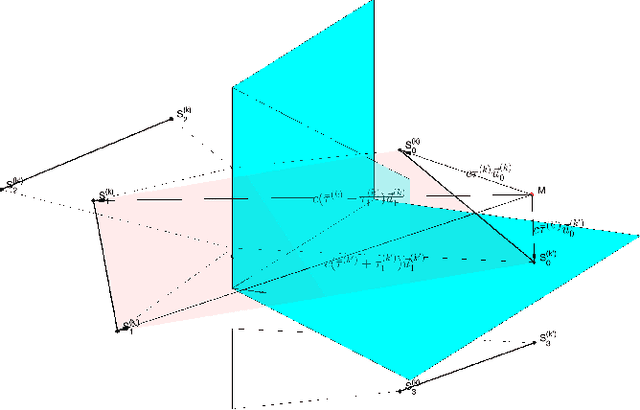
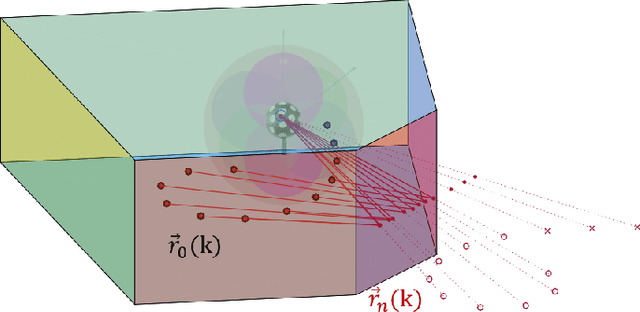

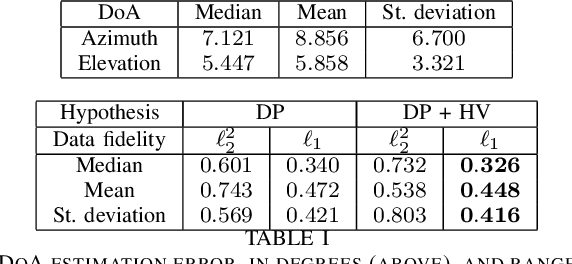
Range estimation of a far field sound source in a reverberant environment is known to be a notoriously difficult problem, hence most localization methods are only capable of estimating the source's Direction-of-Arrival (DoA). In an earlier work, we have demonstrated that, under certain restrictive acoustic conditions and given the orientation of a reflecting surface, one can exploit the dominant acoustic reflection to evaluate the DoA \emph{and} the distance to a static sound source in Ambisonic domain. In this article, we leverage the recently presented Generalized Time-domain Velocity Vector (GTVV) representation to estimate these quantities for a moving sound source without an a priori knowledge of reflectors' orientations. We show that the trajectories of a moving source and the corresponding reflections are spatially and temporally related, which can be used to infer the absolute delay of the propagating source signal and, therefore, approximate the microphone-to-source distance. Experiments on real sound data confirm the validity of the proposed approach.
DONeRF: Towards Real-Time Rendering of Neural Radiance Fields using Depth Oracle Networks
Mar 04, 2021
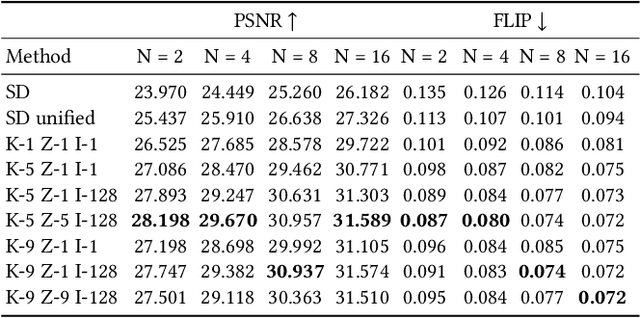
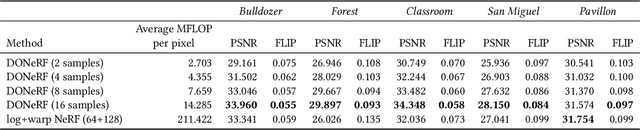
The recent research explosion around Neural Radiance Fields (NeRFs) shows that there is immense potential for implicitly storing scene and lighting information in neural networks, e.g., for novel view generation. However, one major limitation preventing the widespread use of NeRFs is the prohibitive computational cost of excessive network evaluations along each view ray, requiring dozens of petaFLOPS when aiming for real-time rendering on current devices. We show that the number of samples required for each view ray can be significantly reduced when local samples are placed around surfaces in the scene. To this end, we propose a depth oracle network, which predicts ray sample locations for each view ray with a single network evaluation. We show that using a classification network around logarithmically discretized and spherically warped depth values is essential to encode surface locations rather than directly estimating depth. The combination of these techniques leads to DONeRF, a dual network design with a depth oracle network as a first step and a locally sampled shading network for ray accumulation. With our design, we reduce the inference costs by up to 48x compared to NeRF. Using an off-the-shelf inference API in combination with simple compute kernels, we are the first to render raymarching-based neural representations at interactive frame rates (15 frames per second at 800x800) on a single GPU. At the same time, since we focus on the important parts of the scene around surfaces, we achieve equal or better quality compared to NeRF.
Monocular Robot Navigation with Self-Supervised Pretrained Vision Transformers
Mar 07, 2022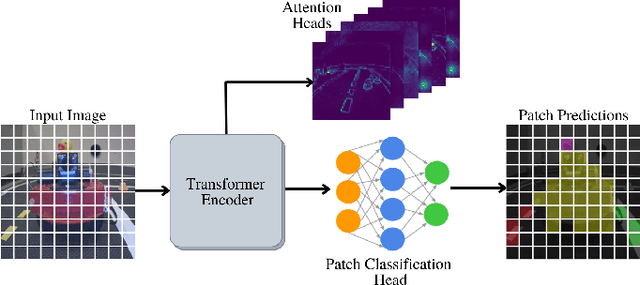

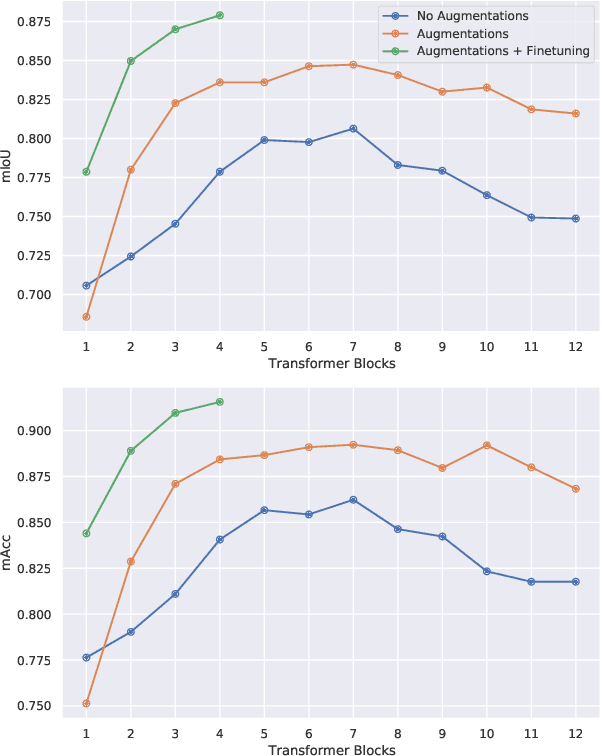

In this work, we consider the problem of learning a perception model for monocular robot navigation using few annotated images. Using a Vision Transformer (ViT) pretrained with a label-free self-supervised method, we successfully train a coarse image segmentation model for the Duckietown environment using 70 training images. Our model performs coarse image segmentation at the 8x8 patch level, and the inference resolution can be adjusted to balance prediction granularity and real-time perception constraints. We study how best to adapt a ViT to our task and environment, and find that some lightweight architectures can yield good single-image segmentations at a usable frame rate, even on CPU. The resulting perception model is used as the backbone for a simple yet robust visual servoing agent, which we deploy on a differential drive mobile robot to perform two tasks: lane following and obstacle avoidance.