 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Benchmark Study on Time Series Clustering
Apr 26, 2020
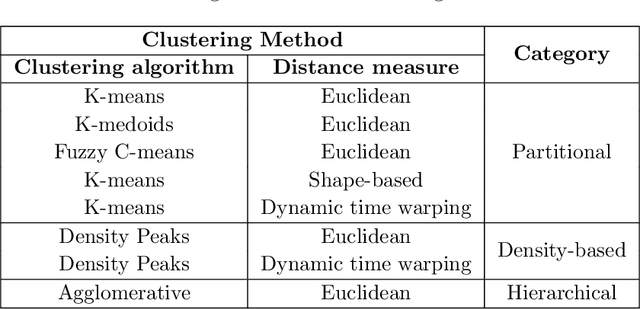
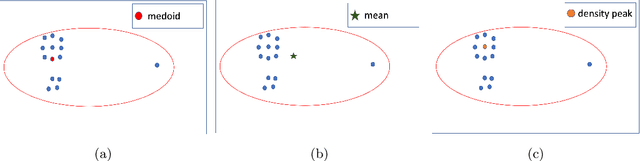
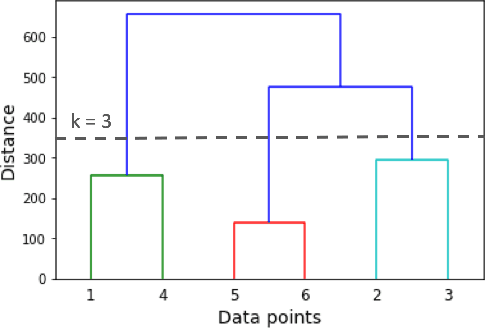
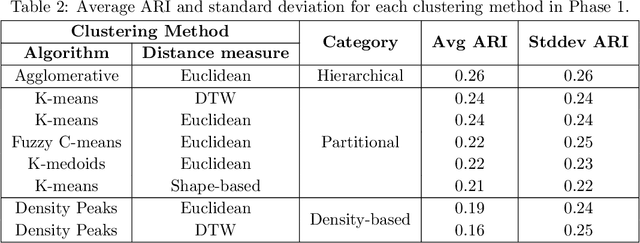
This paper presents the first time series clustering benchmark utilizing all time series datasets currently available in the University of California Riverside (UCR) archive -- the state of the art repository of time series data. Specifically, the benchmark examines eight popular clustering methods representing three categories of clustering algorithms (partitional, hierarchical and density-based) and three types of distance measures (Euclidean, dynamic time warping, and shape-based). We lay out six restrictions with special attention to making the benchmark as unbiased as possible. A phased evaluation approach was then designed for summarizing dataset-level assessment metrics and discussing the results. The benchmark study presented can be a useful reference for the research community on its own; and the dataset-level assessment metrics reported may be used for designing evaluation frameworks to answer different research questions.
Narcissus: A Practical Clean-Label Backdoor Attack with Limited Information
Apr 11, 2022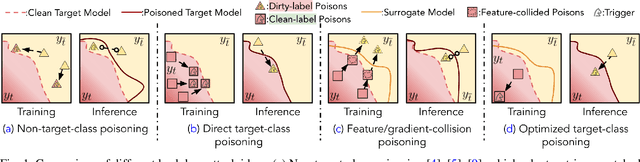

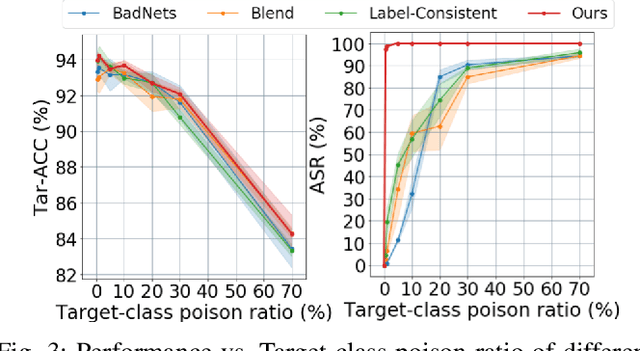
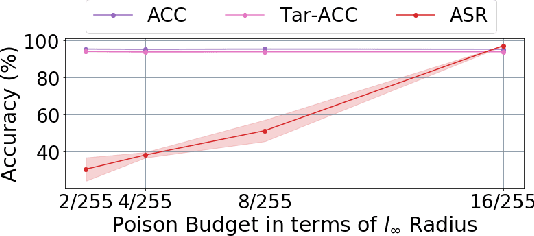
Backdoor attacks insert malicious data into a training set so that, during inference time, it misclassifies inputs that have been patched with a backdoor trigger as the malware specified label. For backdoor attacks to bypass human inspection, it is essential that the injected data appear to be correctly labeled. The attacks with such property are often referred to as "clean-label attacks." Existing clean-label backdoor attacks require knowledge of the entire training set to be effective. Obtaining such knowledge is difficult or impossible because training data are often gathered from multiple sources (e.g., face images from different users). It remains a question whether backdoor attacks still present a real threat. This paper provides an affirmative answer to this question by designing an algorithm to mount clean-label backdoor attacks based only on the knowledge of representative examples from the target class. With poisoning equal to or less than 0.5% of the target-class data and 0.05% of the training set, we can train a model to classify test examples from arbitrary classes into the target class when the examples are patched with a backdoor trigger. Our attack works well across datasets and models, even when the trigger presents in the physical world. We explore the space of defenses and find that, surprisingly, our attack can evade the latest state-of-the-art defenses in their vanilla form, or after a simple twist, we can adapt to the downstream defenses. We study the cause of the intriguing effectiveness and find that because the trigger synthesized by our attack contains features as persistent as the original semantic features of the target class, any attempt to remove such triggers would inevitably hurt the model accuracy first.
Video based real-time positional tracker
Oct 02, 2020
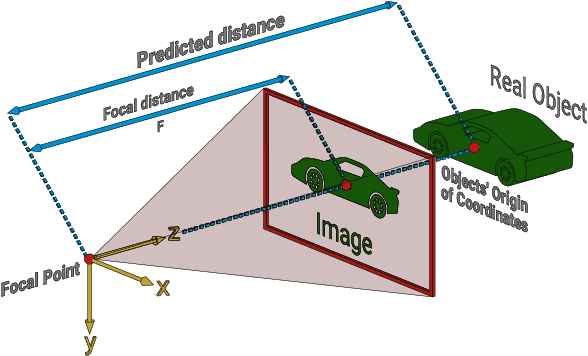
We propose a system that uses video as the input to track the position of objects relative to their surrounding environment in real-time. The neural network employed is trained on a 100% synthetic dataset coming from our own automated generator. The positional tracker relies on a range of 1 to n video cameras placed around an arena of choice. The system returns the positions of the tracked objects relative to the broader world by understanding the overlapping matrices formed by the cameras and therefore these can be extrapolated into real world coordinates. In most cases, we achieve a higher update rate and positioning precision than any of the existing GPS-based systems, in particular for indoor objects or those occluded from clear sky.
A Continuous-Time Approach for 3D Radar-to-Camera Extrinsic Calibration
Mar 12, 2021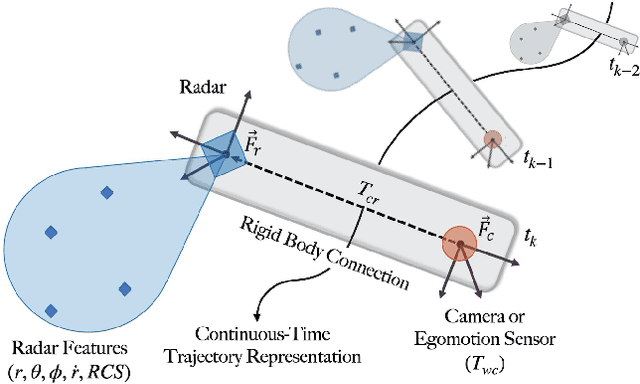
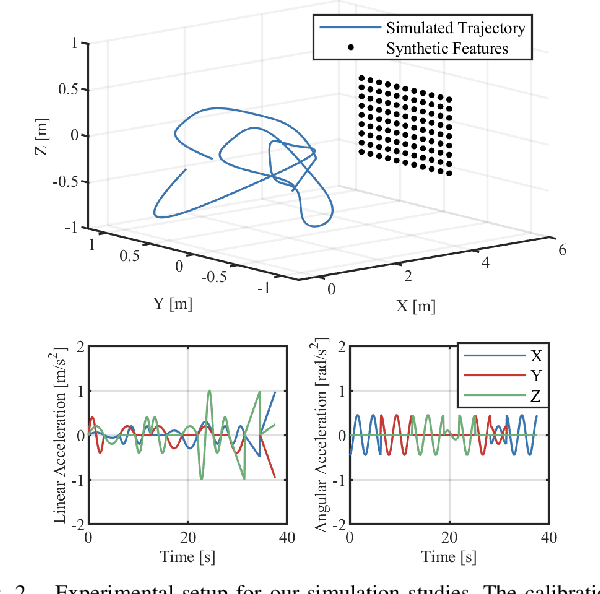
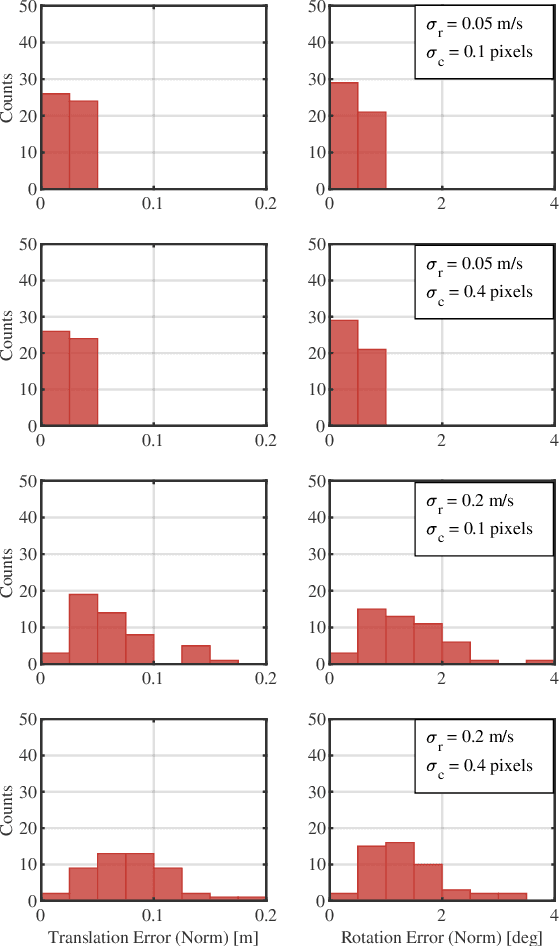

Reliable operation in inclement weather is essential to the deployment of safe autonomous vehicles (AVs). Robustness and reliability can be achieved by fusing data from the standard AV sensor suite (i.e., lidars, cameras) with weather robust sensors, such as millimetre-wavelength radar. Critically, accurate sensor data fusion requires knowledge of the rigid-body transform between sensor pairs, which can be determined through the process of extrinsic calibration. A number of extrinsic calibration algorithms have been designed for 2D (planar) radar sensors - however, recently-developed, low-cost 3D millimetre-wavelength radars are set to displace their 2D counterparts in many applications. In this paper, we present a continuous-time 3D radar-to-camera extrinsic calibration algorithm that utilizes radar velocity measurements and, unlike the majority of existing techniques, does not require specialized radar retroreflectors to be present in the environment. We derive the observability properties of our formulation and demonstrate the efficacy of our algorithm through synthetic and real-world experiments.
Fast Automatic Feature Selection for Multi-Period Sliding Window Aggregate in Time Series
Dec 02, 2020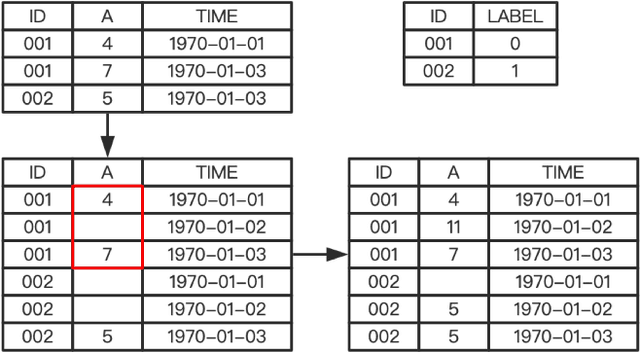
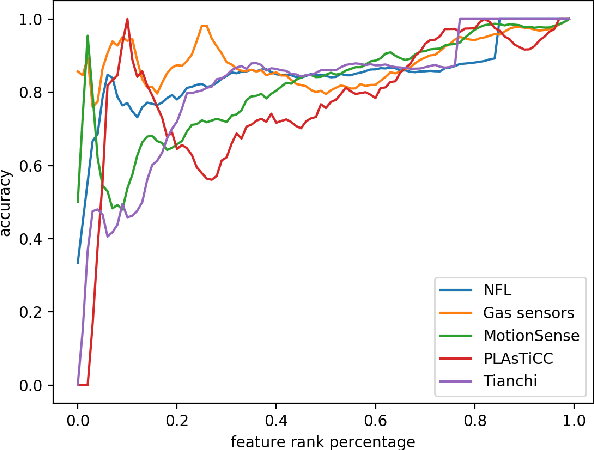
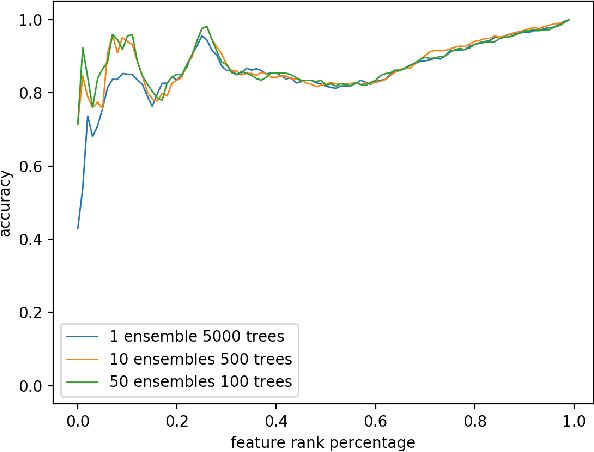
As one of the most well-known artificial feature sampler, the sliding window is widely used in scenarios where spatial and temporal information exists, such as computer vision, natural language process, data stream, and time series. Among which time series is common in many scenarios like credit card payment, user behavior, and sensors. General feature selection for features extracted by sliding window aggregate calls for time-consuming iteration to generate features, and then traditional feature selection methods are employed to rank them. The decision of key parameter, i.e. the period of sliding windows, depends on the domain knowledge and calls for trivial. Currently, there is no automatic method to handle the sliding window aggregate features selection. As the time consumption of feature generation with different periods and sliding windows is huge, it is very hard to enumerate them all and then select them. In this paper, we propose a general framework using Markov Chain to solve this problem. This framework is very efficient and has high accuracy, such that it is able to perform feature selection on a variety of features and period options. We show the detail by 2 common sliding windows and 3 types of aggregation operators. And it is easy to extend more sliding windows and aggregation operators in this framework by employing existing theory about Markov Chain.
Deep Reinforcement Agent for Efficient Instant Search
Mar 17, 2022
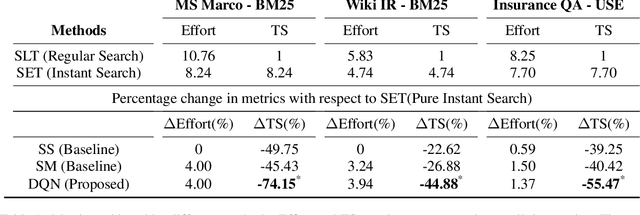
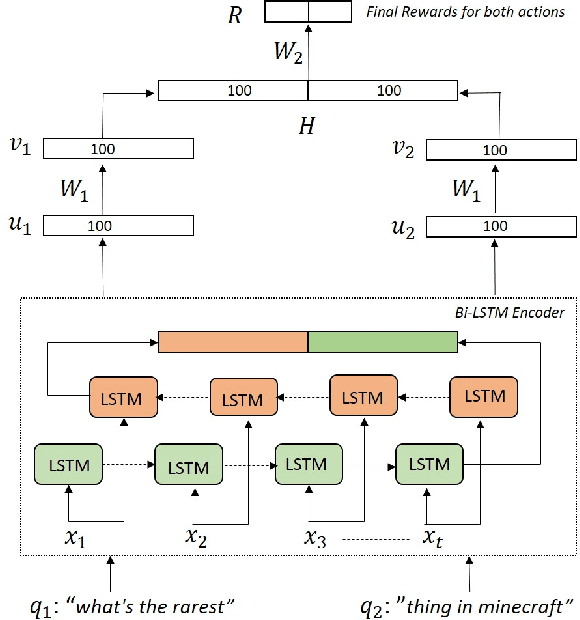
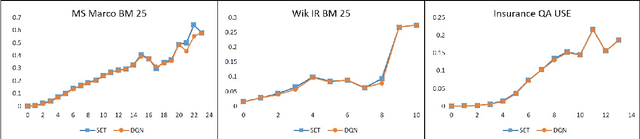
Instant Search is a paradigm where a search system retrieves answers on the fly while typing. The na\"ive implementation of an Instant Search system would hit the search back-end for results each time a user types a key, imposing a very high load on the underlying search system. In this paper, we propose to address the load issue by identifying tokens that are semantically more salient towards retrieving relevant documents and utilize this knowledge to trigger an instant search selectively. We train a reinforcement agent that interacts directly with the search engine and learns to predict the word's importance. Our proposed method treats the underlying search system as a black box and is more universally applicable to a diverse set of architectures. Furthermore, a novel evaluation framework is presented to study the trade-off between the number of triggered searches and the system's performance. We utilize the framework to evaluate and compare the proposed reinforcement method with other intuitive baselines. Experimental results demonstrate the efficacy of the proposed method towards achieving a superior trade-off.
Deep Neural Networks to Recover Unknown Physical Parameters from Oscillating Time Series
Jan 11, 2021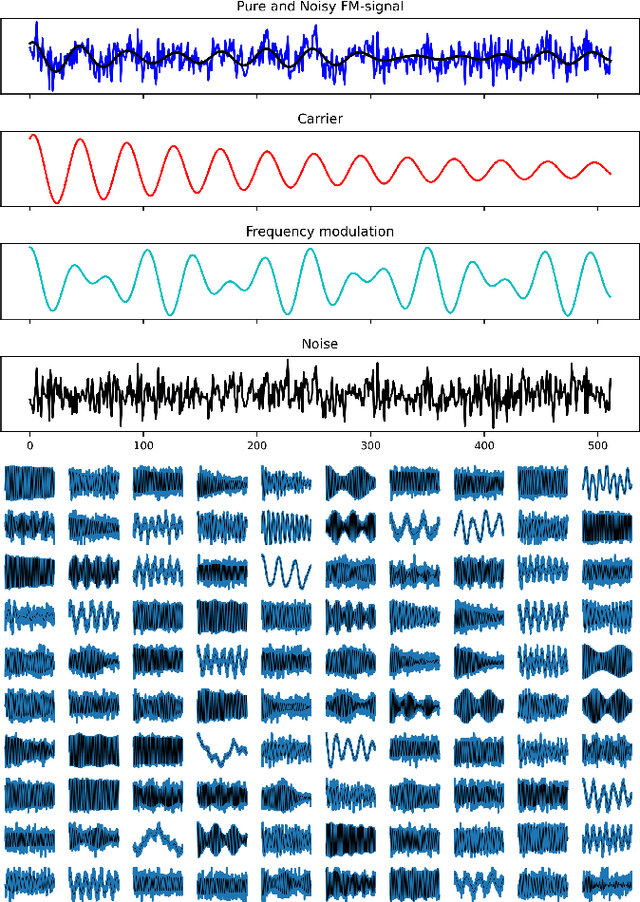
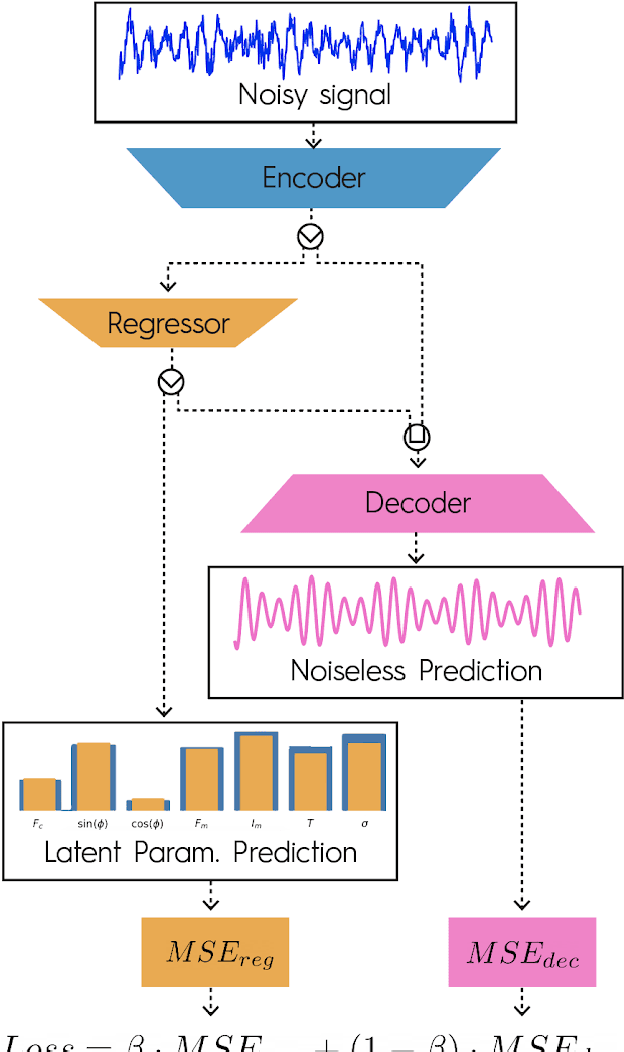
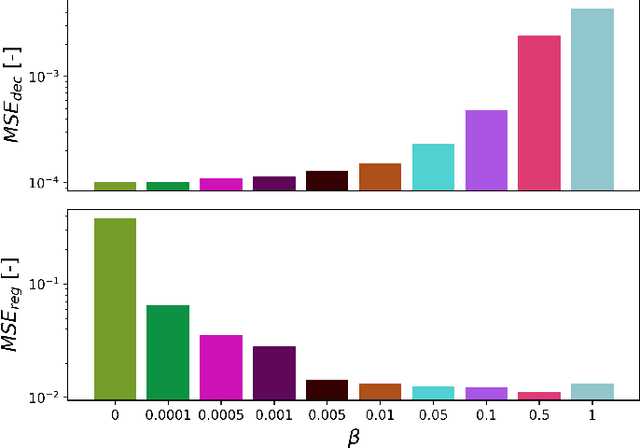
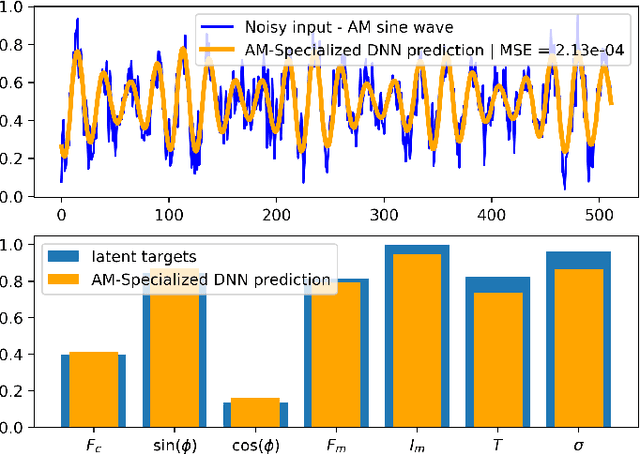
Deep neural networks (DNNs) are widely used in pattern-recognition tasks for which a human comprehensible, quantitative description of the data-generating process, e.g., in the form of equations, cannot be achieved. While doing so, DNNs often produce an abstract (entangled and non-interpretable) representation of the data-generating process. This is one of the reasons why DNNs are not extensively used in physics-signal processing: physicists generally require their analyses to yield quantitative information about the studied systems. In this article we use DNNs to disentangle components of oscillating time series, and recover meaningful information. We show that, because DNNs can find useful abstract feature representations, they can be used when prior knowledge about the signal-generating process exists, but is not complete, as it is particularly the case in "new-physics" searches. To this aim, we train our DNN on synthetic oscillating time series to perform two tasks: a regression of the signal latent parameters and signal denoising by an Autoencoder-like architecture. We show that the regression and denoising performance is similar to those of least-square curve fittings (LS-fit) with true latent parameters' initial guesses, in spite of the DNN needing no initial guesses at all. We then explore applications in which we believe our architecture could prove useful for time-series processing in physics, when prior knowledge is incomplete. As an example, we employ DNNs as a tool to inform LS-fits when initial guesses are unknown. We show that the regression can be performed on some latent parameters, while ignoring the existence of others. Because the Autoencoder needs no prior information about the physical model, the remaining unknown latent parameters can still be captured, thus making use of partial prior knowledge, while leaving space for data exploration and discoveries.
Aligning Videos in Space and Time
Jul 09, 2020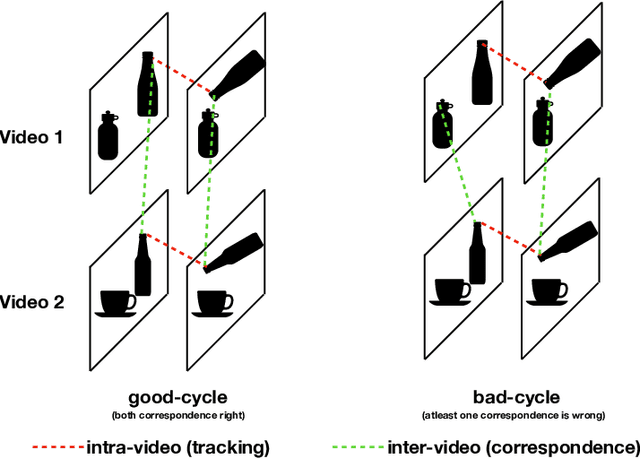

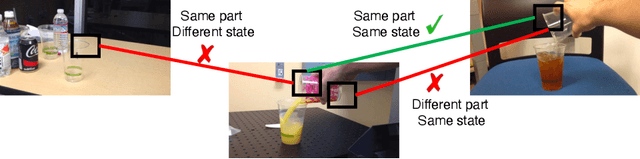

In this paper, we focus on the task of extracting visual correspondences across videos. Given a query video clip from an action class, we aim to align it with training videos in space and time. Obtaining training data for such a fine-grained alignment task is challenging and often ambiguous. Hence, we propose a novel alignment procedure that learns such correspondence in space and time via cross video cycle-consistency. During training, given a pair of videos, we compute cycles that connect patches in a given frame in the first video by matching through frames in the second video. Cycles that connect overlapping patches together are encouraged to score higher than cycles that connect non-overlapping patches. Our experiments on the Penn Action and Pouring datasets demonstrate that the proposed method can successfully learn to correspond semantically similar patches across videos, and learns representations that are sensitive to object and action states.
MultiRocket: Effective summary statistics for convolutional outputs in time series classification
Jan 31, 2021
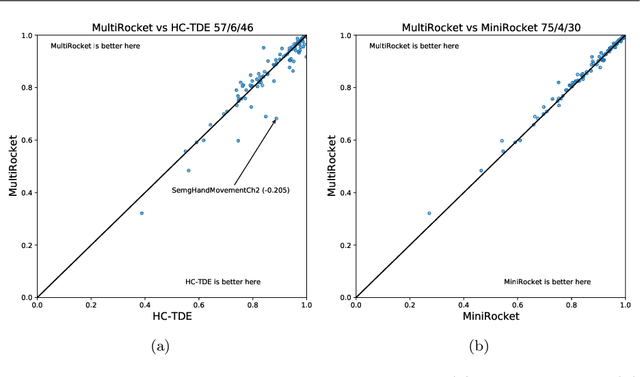

Rocket and MiniRocket, while two of the fastest methods for time series classification, are both somewhat less accurate than the current most accurate methods (namely, HIVE-COTE and its variants). We show that it is possible to significantly improve the accuracy of MiniRocket (and Rocket), with some additional computational expense, by expanding the set of features produced by the transform, making MultiRocket (for MiniRocket with Multiple Features) overall the single most accurate method on the datasets in the UCR archive, while still being orders of magnitude faster than any algorithm of comparable accuracy other than its precursors
HyperMixer: An MLP-based Green AI Alternative to Transformers
Mar 07, 2022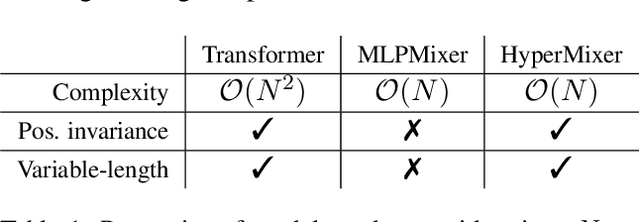
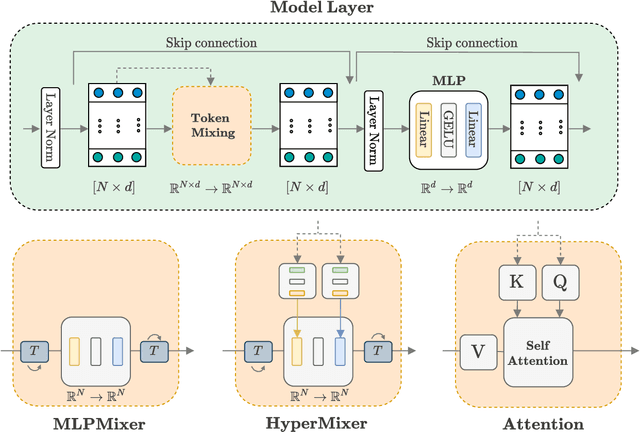
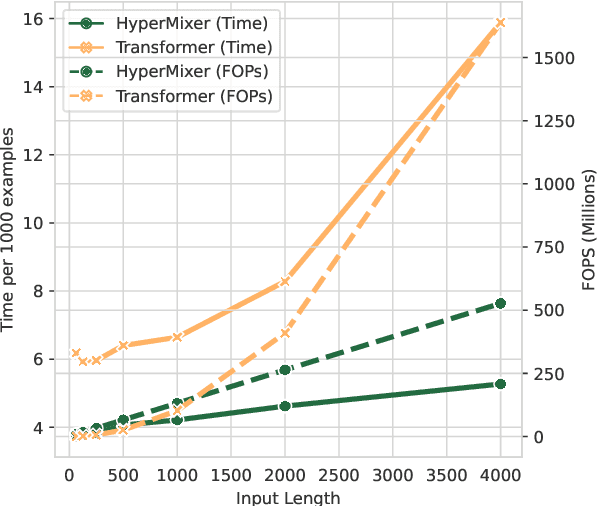
Transformer-based architectures are the model of choice for natural language understanding, but they come at a significant cost, as they have quadratic complexity in the input length and can be difficult to tune. In the pursuit of Green AI, we investigate simple MLP-based architectures. We find that existing architectures such as MLPMixer, which achieves token mixing through a static MLP applied to each feature independently, are too detached from the inductive biases required for natural language understanding. In this paper, we propose a simple variant, HyperMixer, which forms the token mixing MLP dynamically using hypernetworks. Empirically, we demonstrate that our model performs better than alternative MLP-based models, and on par with Transformers. In contrast to Transformers, HyperMixer achieves these results at substantially lower costs in terms of processing time, training data, and hyperparameter tuning.