 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Hybrid Transformer Network for Different Horizons-based Enriched Wind Speed Forecasting
Apr 07, 2022
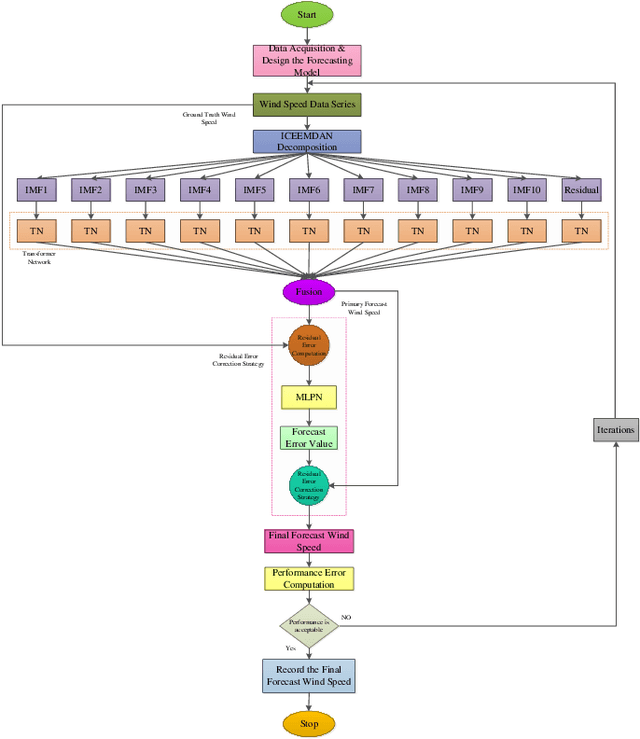
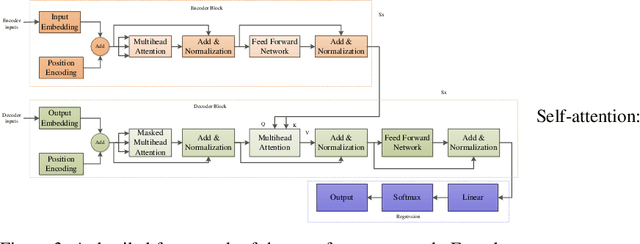
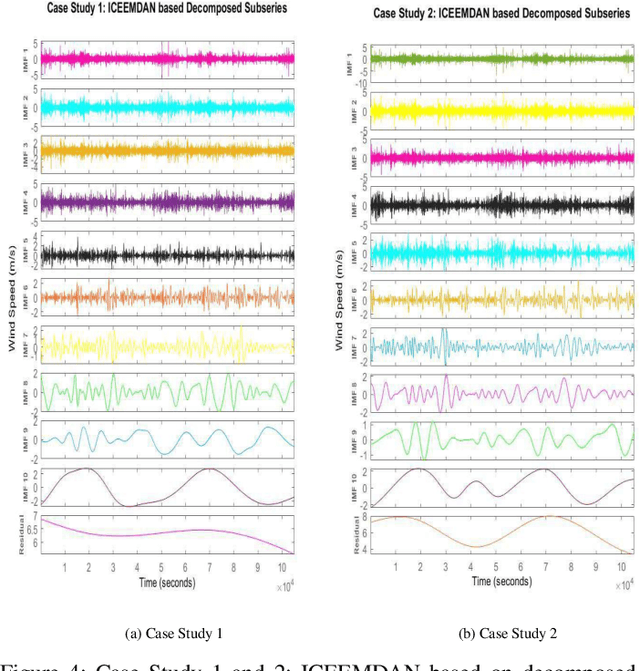
Highly accurate different horizon-based wind speed forecasting facilitates a better modern power system. This paper proposed a novel astute hybrid wind speed forecasting model and applied it to different horizons. The proposed hybrid forecasting model decomposes the original wind speed data into IMFs (Intrinsic Mode Function) using Improved Complete Ensemble Empirical Mode Decomposition with Adaptive Noise (ICEEMDAN). We fed the obtained subseries from ICEEMDAN to the transformer network. Each transformer network computes the forecast subseries and then passes to the fusion phase. Get the primary wind speed forecasting from the fusion of individual transformer network forecast subseries. Estimate the residual error values and predict errors using a multilayer perceptron neural network. The forecast error is added to the primary forecast wind speed to leverage the high accuracy of wind speed forecasting. Comparative analysis with real-time Kethanur, India wind farm dataset results reveals the proposed ICEEMDAN-TNF-MLPN-RECS hybrid model's superior performance with MAE=1.7096*10^-07, MAPE=2.8416*10^-06, MRE=2.8416*10^-08, MSE=5.0206*10^-14, and RMSE=2.2407*10^-07 for case study 1 and MAE=6.1565*10^-07, MAPE=9.5005*10^-06, MRE=9.5005*10^-08, MSE=8.9289*10^-13, and RMSE=9.4493*10^-07 for case study 2 enriched wind speed forecasting than state-of-the-art methods and reduces the burden on the power system engineer.
Backward Reachability Analysis for Neural Feedback Loops
Apr 14, 2022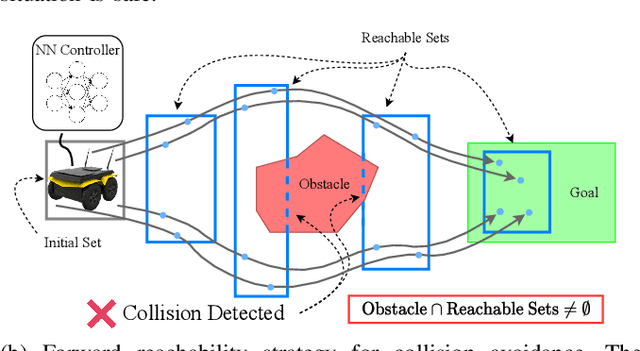
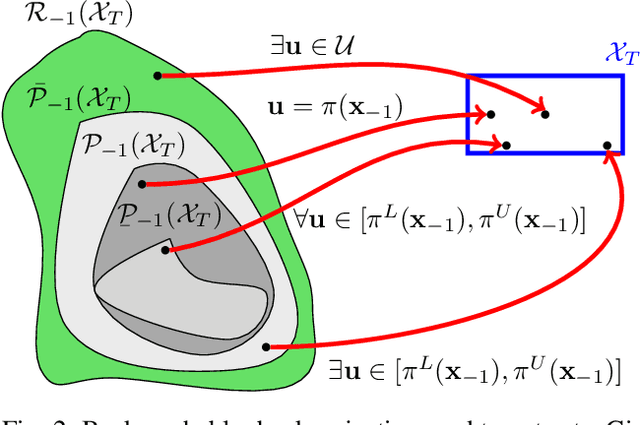
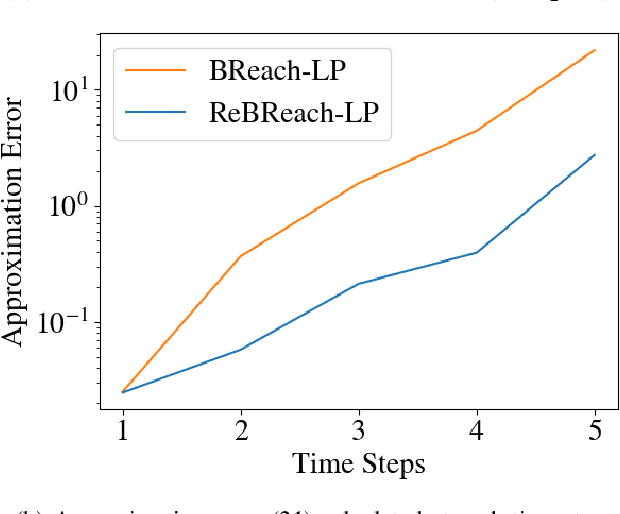
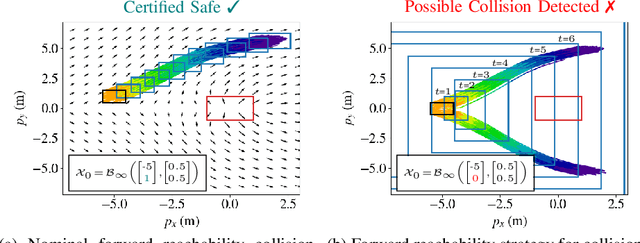
The increasing prevalence of neural networks (NNs) in safety-critical applications calls for methods to certify their behavior and guarantee safety. This paper presents a backward reachability approach for safety verification of neural feedback loops (NFLs), i.e., closed-loop systems with NN control policies. While recent works have focused on forward reachability as a strategy for safety certification of NFLs, backward reachability offers advantages over the forward strategy, particularly in obstacle avoidance scenarios. Prior works have developed techniques for backward reachability analysis for systems without NNs, but the presence of NNs in the feedback loop presents a unique set of problems due to the nonlinearities in their activation functions and because NN models are generally not invertible. To overcome these challenges, we use existing forward NN analysis tools to find affine bounds on the control inputs and solve a series of linear programs (LPs) to efficiently find an approximation of the backprojection (BP) set, i.e., the set of states for which the NN control policy will drive the system to a given target set. We present an algorithm to iteratively find BP set estimates over a given time horizon and demonstrate the ability to reduce conservativeness in the BP set estimates by up to 88% with low additional computational cost. We use numerical results from a double integrator model to verify the efficacy of these algorithms and demonstrate the ability to certify safety for a linearized ground robot model in a collision avoidance scenario where forward reachability fails.
Joint Sensing, Communication and Localization of a Silent Abnormality Using Molecular Diffusion
Mar 30, 2022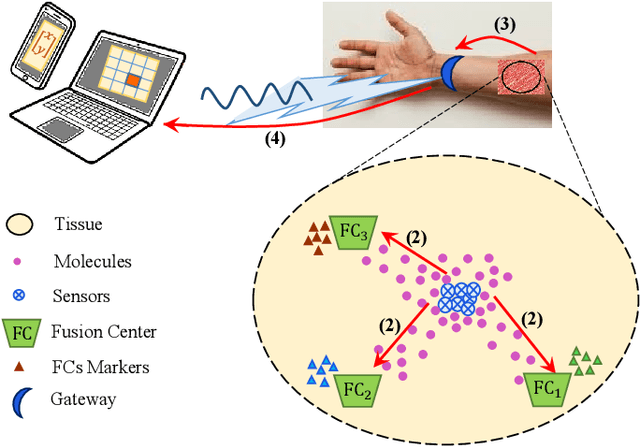
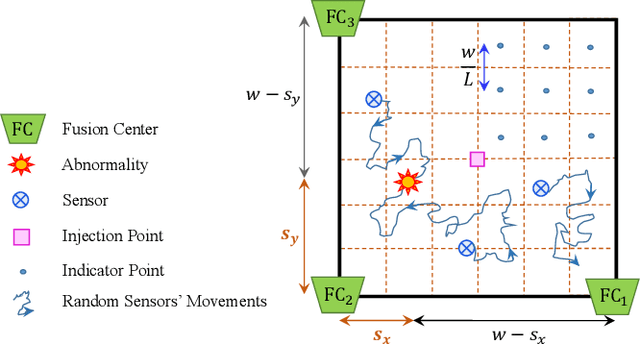
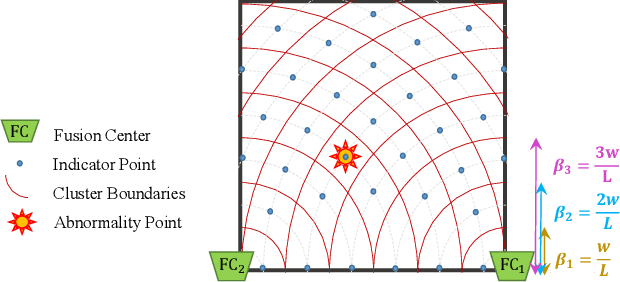
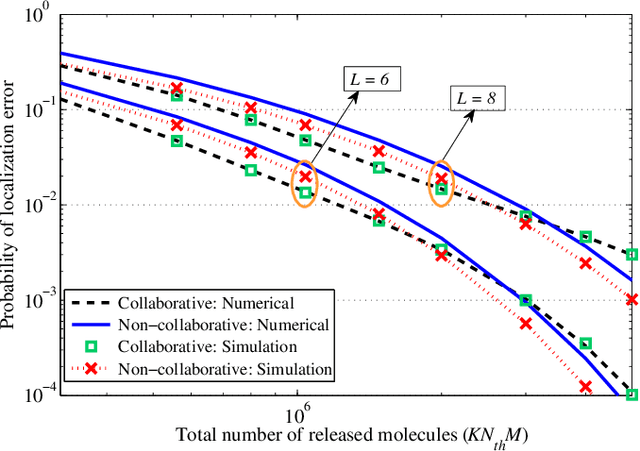
In this paper, we propose a molecular communication system to localize an abnormality in a diffusion based medium. We consider a general setup to perform joint sensing, communication and localization. This setup consists of three types of devices, each for a different task: mobile sensors for navigation and molecule releasing (for communication), fusion centers (FC)s for sampling, amplifying and forwarding the signal, and a gateway for making decision or exchanging the information with an external device. The sensors move randomly in the environment to reach the abnormality. We consider both collaborative and non-collaborative sensors that simultaneously release their molecules to the FCs when the number of activated sensors or the moving time reach a certain threshold, respectively. The FCs amplify the received signal and forward it to the gateway for decision making using either an ideal or a noisy communication channel. A practical application of the proposed model is drug delivery in a tissue of human body, in order to guide the nanomachine bound drug to the exact location. The decision rules and probabilities of error are obtained for two considered sensors types in both ideal and noisy communication channels.
NeRFusion: Fusing Radiance Fields for Large-Scale Scene Reconstruction
Mar 21, 2022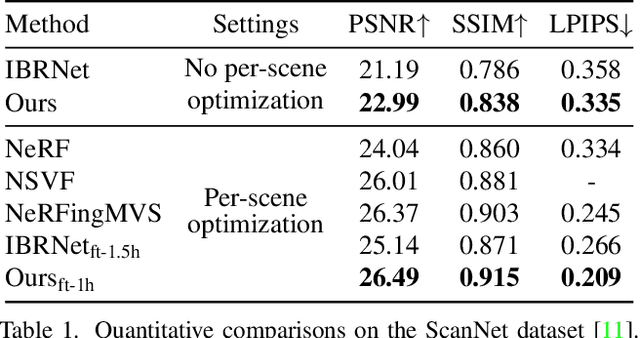
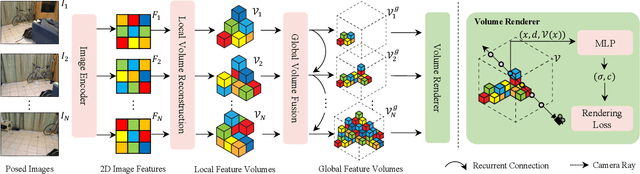
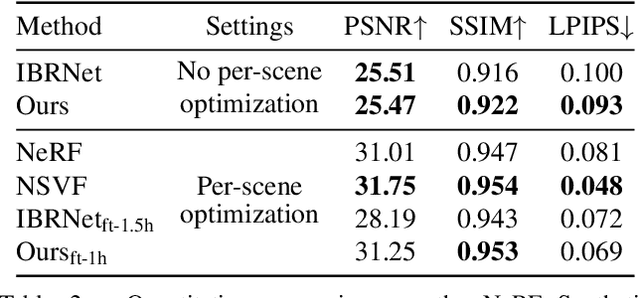
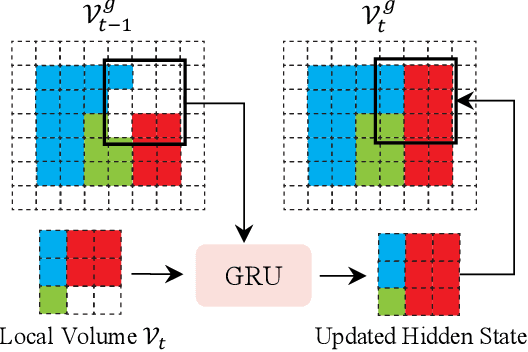
While NeRF has shown great success for neural reconstruction and rendering, its limited MLP capacity and long per-scene optimization times make it challenging to model large-scale indoor scenes. In contrast, classical 3D reconstruction methods can handle large-scale scenes but do not produce realistic renderings. We propose NeRFusion, a method that combines the advantages of NeRF and TSDF-based fusion techniques to achieve efficient large-scale reconstruction and photo-realistic rendering. We process the input image sequence to predict per-frame local radiance fields via direct network inference. These are then fused using a novel recurrent neural network that incrementally reconstructs a global, sparse scene representation in real-time at 22 fps. This global volume can be further fine-tuned to boost rendering quality. We demonstrate that NeRFusion achieves state-of-the-art quality on both large-scale indoor and small-scale object scenes, with substantially faster reconstruction than NeRF and other recent methods.
Real-Time Reinforcement Learning
Nov 14, 2019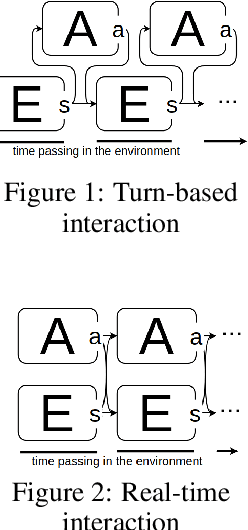
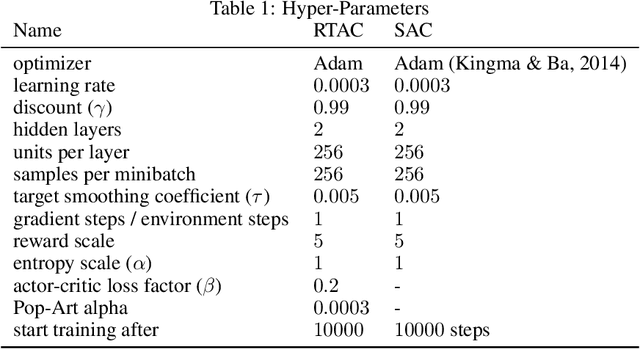
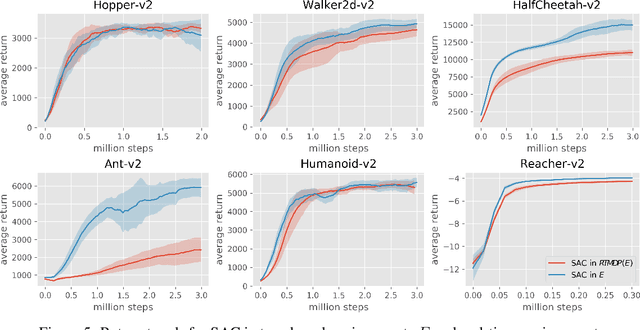
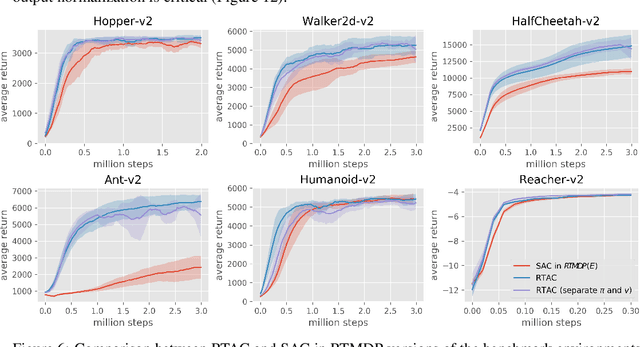
Markov Decision Processes (MDPs), the mathematical framework underlying most algorithms in Reinforcement Learning (RL), are often used in a way that wrongfully assumes that the state of an agent's environment does not change during action selection. As RL systems based on MDPs begin to find application in real-world safety critical situations, this mismatch between the assumptions underlying classical MDPs and the reality of real-time computation may lead to undesirable outcomes. In this paper, we introduce a new framework, in which states and actions evolve simultaneously and show how it is related to the classical MDP formulation. We analyze existing algorithms under the new real-time formulation and show why they are suboptimal when used in real-time. We then use those insights to create a new algorithm Real-Time Actor-Critic (RTAC) that outperforms the existing state-of-the-art continuous control algorithm Soft Actor-Critic both in real-time and non-real-time settings. Code and videos can be found at https://github.com/rmst/rtrl.
* NeurIPS 2019
A Framework for Real-time Traffic Trajectory Tracking, Speed Estimation, and Driver Behavior Calibration at Urban Intersections Using Virtual Traffic Lanes
Jun 18, 2021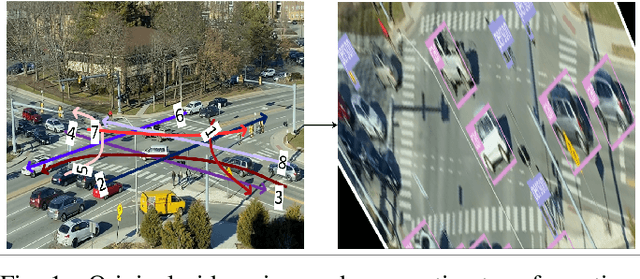
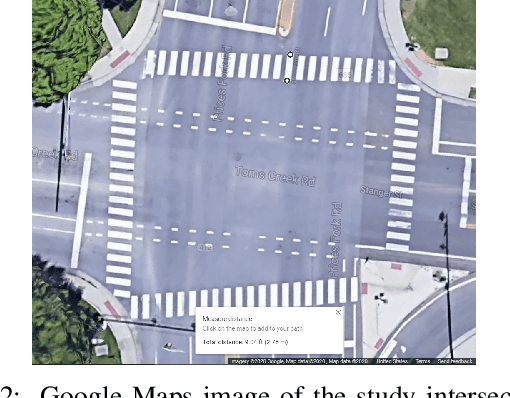


In a previous study, we presented VT-Lane, a three-step framework for real-time vehicle detection, tracking, and turn movement classification at urban intersections. In this study, we present a case study incorporating the highly accurate trajectories and movement classification obtained via VT-Lane for the purpose of speed estimation and driver behavior calibration for traffic at urban intersections. First, we use a highly instrumented vehicle to verify the estimated speeds obtained from video inference. The results of the speed validation show that our method can estimate the average travel speed of detected vehicles in real-time with an error of 0.19 m/sec, which is equivalent to 2% of the average observed travel speeds in the intersection of the study. Instantaneous speeds (at the resolution of 30 Hz) were found to be estimated with an average error of 0.21 m/sec and 0.86 m/sec respectively for free-flowing and congested traffic conditions. We then use the estimated speeds to calibrate the parameters of a driver behavior model for the vehicles in the area of study. The results show that the calibrated model replicates the driving behavior with an average error of 0.45 m/sec, indicating the high potential for using this framework for automated, large-scale calibration of car-following models from roadside traffic video data, which can lead to substantial improvements in traffic modeling via microscopic simulation.
Spatially Adaptive Online Prediction of Piecewise Regular Functions
Mar 30, 2022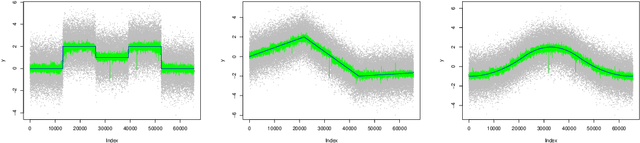
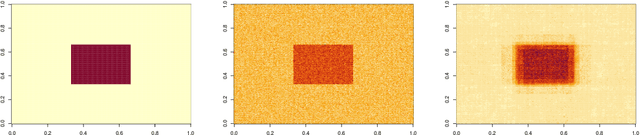
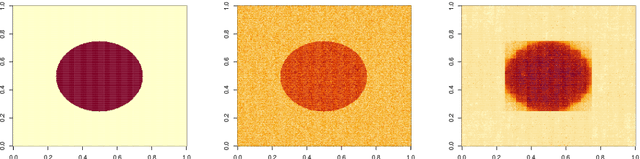
We consider the problem of estimating piecewise regular functions in an online setting, i.e., the data arrive sequentially and at any round our task is to predict the value of the true function at the next revealed point using the available data from past predictions. We propose a suitably modified version of a recently developed online learning algorithm called the sleeping experts aggregation algorithm. We show that this estimator satisfies oracle risk bounds simultaneously for all local regions of the domain. As concrete instantiations of the expert aggregation algorithm proposed here, we study an online mean aggregation and an online linear regression aggregation algorithm where experts correspond to the set of dyadic subrectangles of the domain. The resulting algorithms are near linear time computable in the sample size. We specifically focus on the performance of these online algorithms in the context of estimating piecewise polynomial and bounded variation function classes in the fixed design setup. The simultaneous oracle risk bounds we obtain for these estimators in this context provide new and improved (in certain aspects) guarantees even in the batch setting and are not available for the state of the art batch learning estimators.
Factored Adaptation for Non-Stationary Reinforcement Learning
Mar 30, 2022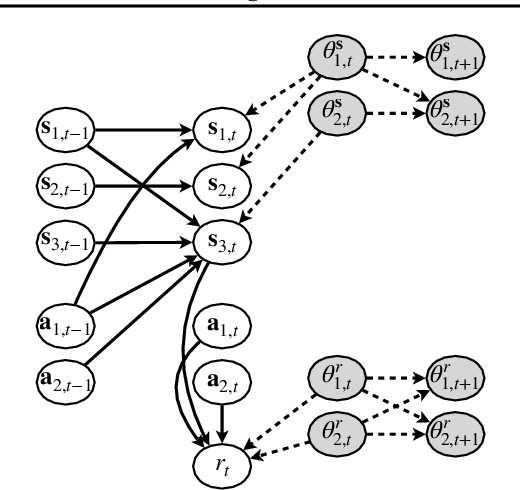
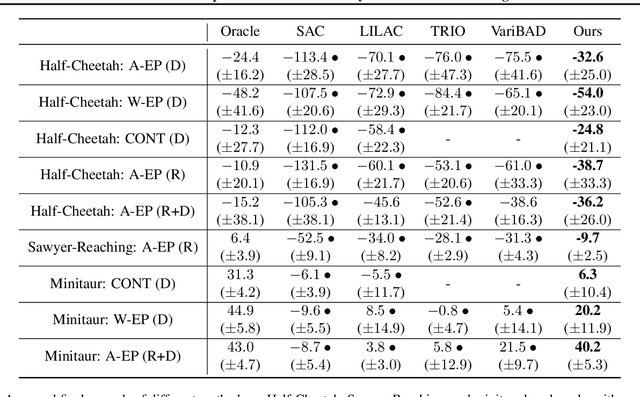
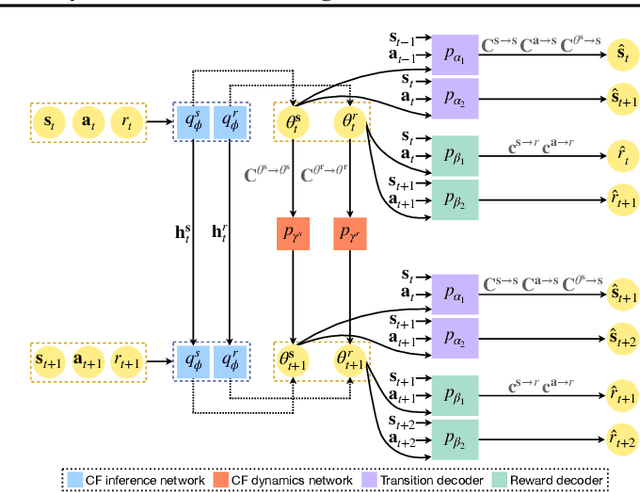

Dealing with non-stationarity in environments (i.e., transition dynamics) and objectives (i.e., reward functions) is a challenging problem that is crucial in real-world applications of reinforcement learning (RL). Most existing approaches only focus on families of stationary MDPs, in which the non-stationarity is episodic, i.e., the change is only possible across episodes. The few works that do consider non-stationarity without a specific boundary, i.e., also allow for changes within an episode, model the changes monolithically in a single shared embedding vector. In this paper, we propose Factored Adaptation for Non-Stationary RL (FANS-RL), a factored adaption approach that explicitly learns the individual latent change factors affecting the transition dynamics and reward functions. FANS-RL learns jointly the structure of a factored MDP and a factored representation of the time-varying change factors, as well as the specific state components that they affect, via a factored non-stationary variational autoencoder. Through this general framework, we can consider general non-stationary scenarios with different changing function types and changing frequency. Experimental results demonstrate that FANS-RL outperforms existing approaches in terms of rewards, compactness of the latent state representation and robustness to varying degrees of non-stationarity.
Learning to Act with Affordance-Aware Multimodal Neural SLAM
Feb 04, 2022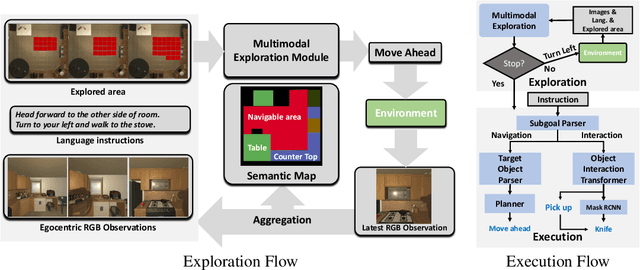

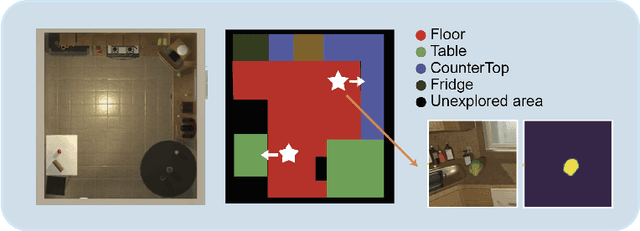
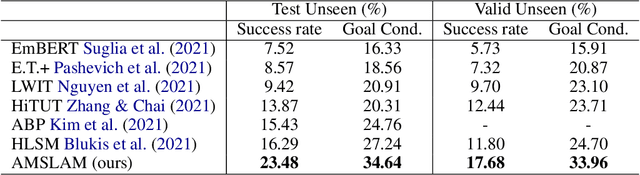
Recent years have witnessed an emerging paradigm shift toward embodied artificial intelligence, in which an agent must learn to solve challenging tasks by interacting with its environment. There are several challenges in solving embodied multimodal tasks, including long-horizon planning, vision-and-language grounding, and efficient exploration. We focus on a critical bottleneck, namely the performance of planning and navigation. To tackle this challenge, we propose a Neural SLAM approach that, for the first time, utilizes several modalities for exploration, predicts an affordance-aware semantic map, and plans over it at the same time. This significantly improves exploration efficiency, leads to robust long-horizon planning, and enables effective vision-and-language grounding. With the proposed Affordance-aware Multimodal Neural SLAM (AMSLAM) approach, we obtain more than $40\%$ improvement over prior published work on the ALFRED benchmark and set a new state-of-the-art generalization performance at a success rate of $23.48\%$ on the test unseen scenes.
The Conceptual VAE
Mar 21, 2022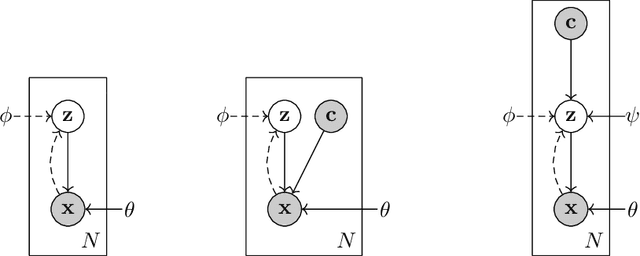
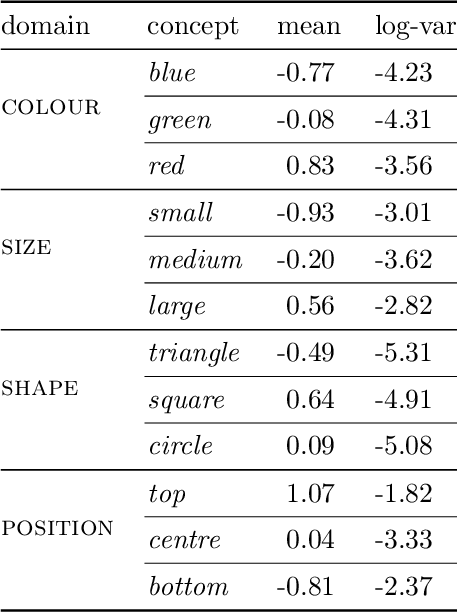
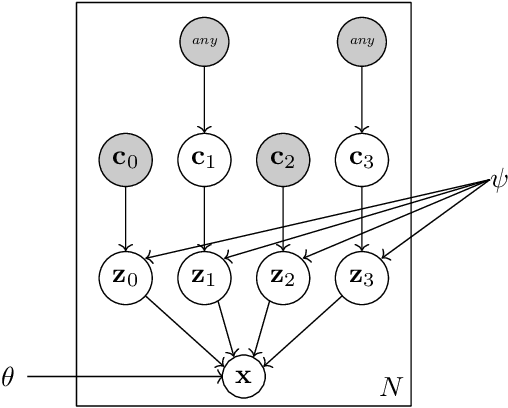
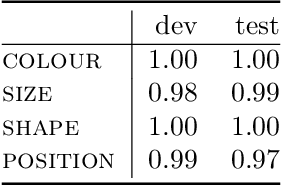
In this report we present a new model of concepts, based on the framework of variational autoencoders, which is designed to have attractive properties such as factored conceptual domains, and at the same time be learnable from data. The model is inspired by, and closely related to, the Beta-VAE model of concepts, but is designed to be more closely connected with language, so that the names of concepts form part of the graphical model. We provide evidence that our model -- which we call the Conceptual VAE -- is able to learn interpretable conceptual representations from simple images of coloured shapes together with the corresponding concept labels. We also show how the model can be used as a concept classifier, and how it can be adapted to learn from fewer labels per instance. Finally, we formally relate our model to Gardenfors' theory of conceptual spaces, showing how the Gaussians we use to represent concepts can be formalised in terms of "fuzzy concepts" in such a space.