 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning to Guide Multiple Heterogeneous Actors from a Single Human Demonstration via Automatic Curriculum Learning in StarCraft II
May 11, 2022


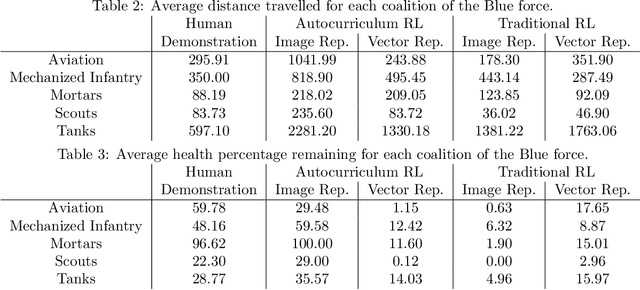
Traditionally, learning from human demonstrations via direct behavior cloning can lead to high-performance policies given that the algorithm has access to large amounts of high-quality data covering the most likely scenarios to be encountered when the agent is operating. However, in real-world scenarios, expert data is limited and it is desired to train an agent that learns a behavior policy general enough to handle situations that were not demonstrated by the human expert. Another alternative is to learn these policies with no supervision via deep reinforcement learning, however, these algorithms require a large amount of computing time to perform well on complex tasks with high-dimensional state and action spaces, such as those found in StarCraft II. Automatic curriculum learning is a recent mechanism comprised of techniques designed to speed up deep reinforcement learning by adjusting the difficulty of the current task to be solved according to the agent's current capabilities. Designing a proper curriculum, however, can be challenging for sufficiently complex tasks, and thus we leverage human demonstrations as a way to guide agent exploration during training. In this work, we aim to train deep reinforcement learning agents that can command multiple heterogeneous actors where starting positions and overall difficulty of the task are controlled by an automatically-generated curriculum from a single human demonstration. Our results show that an agent trained via automated curriculum learning can outperform state-of-the-art deep reinforcement learning baselines and match the performance of the human expert in a simulated command and control task in StarCraft II modeled over a real military scenario.
Theoretical Understanding of the Information Flow on Continual Learning Performance
May 02, 2022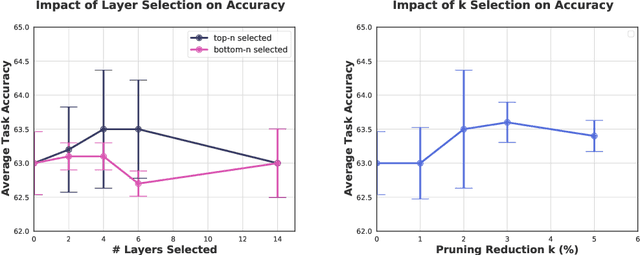
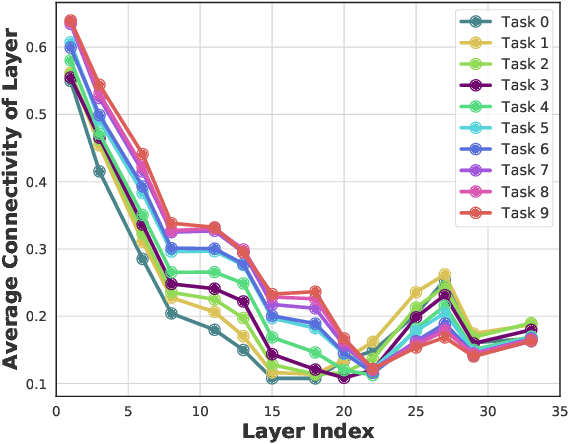
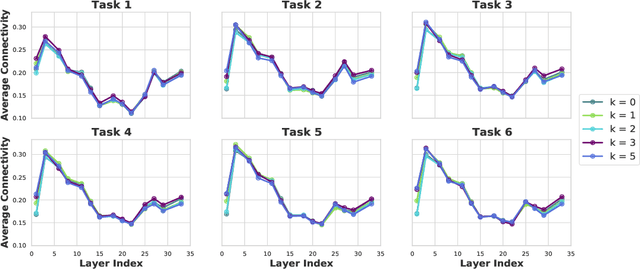
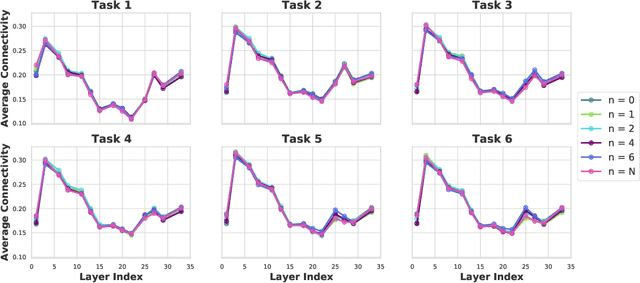
Continual learning (CL) is a setting in which an agent has to learn from an incoming stream of data sequentially. CL performance evaluates the model's ability to continually learn and solve new problems with incremental available information over time while retaining previous knowledge. Despite the numerous previous solutions to bypass the catastrophic forgetting (CF) of previously seen tasks during the learning process, most of them still suffer significant forgetting, expensive memory cost, or lack of theoretical understanding of neural networks' conduct while learning new tasks. While the issue that CL performance degrades under different training regimes has been extensively studied empirically, insufficient attention has been paid from a theoretical angle. In this paper, we establish a probabilistic framework to analyze information flow through layers in networks for task sequences and its impact on learning performance. Our objective is to optimize the information preservation between layers while learning new tasks to manage task-specific knowledge passing throughout the layers while maintaining model performance on previous tasks. In particular, we study CL performance's relationship with information flow in the network to answer the question "How can knowledge of information flow between layers be used to alleviate CF?". Our analysis provides novel insights of information adaptation within the layers during the incremental task learning process. Through our experiments, we provide empirical evidence and practically highlight the performance improvement across multiple tasks.
Size Generalization for Resource Allocation with Graph Neural Networks
Apr 29, 2022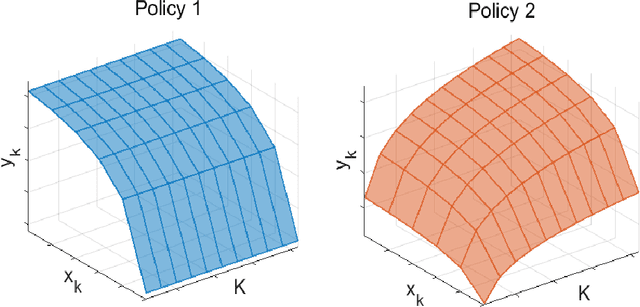
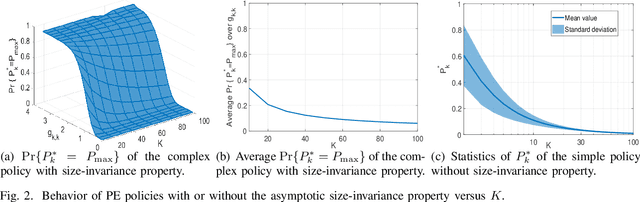
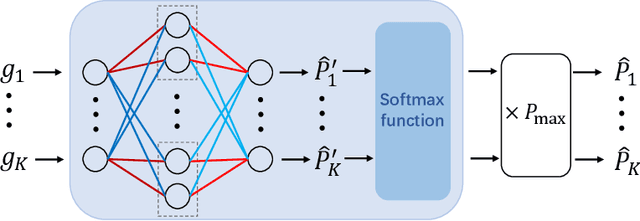
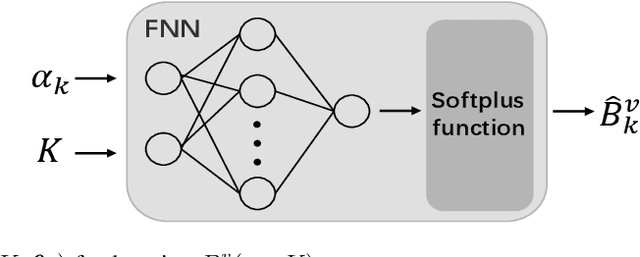
Size generalization is important for learning wireless policies, which are often with dynamic sizes, say caused by time-varying number of users. Recent works of learning to optimize resource allocation empirically demonstrate that graph neural networks (GNNs) can generalize to different problem scales. However, GNNs are not guaranteed to generalize across input sizes. In this paper, we strive to analyze the size generalization mechanism of GNNs when learning permutation equivariant (PE) policies. We find that the aggregation function and activation functions of a GNN play a key role on its size generalization ability. We take the GNN with mean aggregator, called mean-GNN, as an example to demonstrate a size generalization condition, and interpret why several GNNs in the literature of wireless communications can generalize well to problem scales. To illustrate how to design GNNs with size generalizability according to our finding, we consider power and bandwidth allocation, and suggest to select or pre-train activation function in the output layer of mean-GNN for learning the PE policies. Simulation results show that the proposed GNN can generalize well to the number of users, which validate our analysis for the size generalization condition of GNNs when learning the PE policies.
"My nose is running.""Are you also coughing?": Building A Medical Diagnosis Agent with Interpretable Inquiry Logics
Apr 29, 2022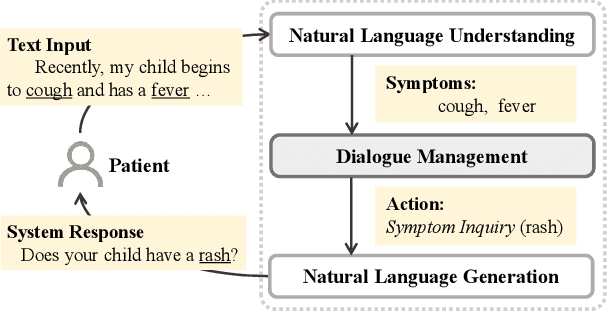
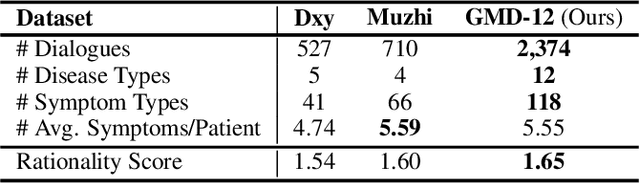
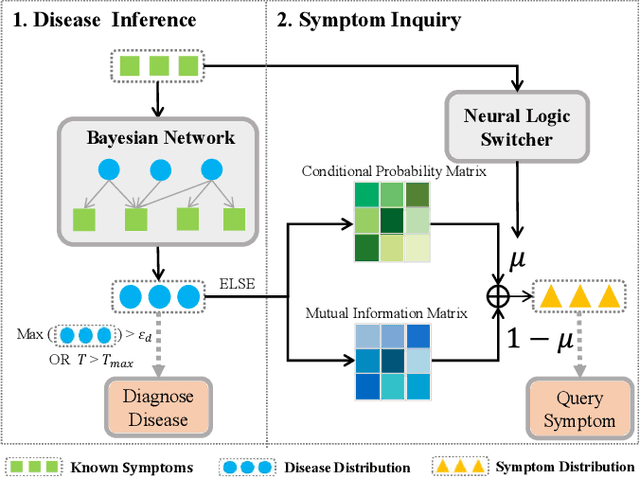
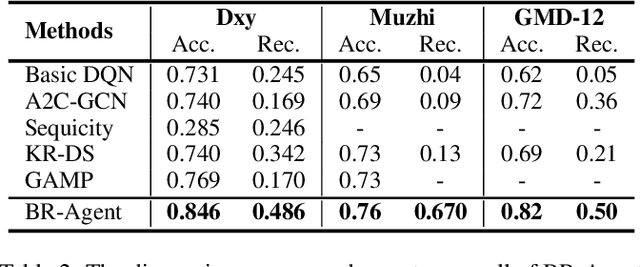
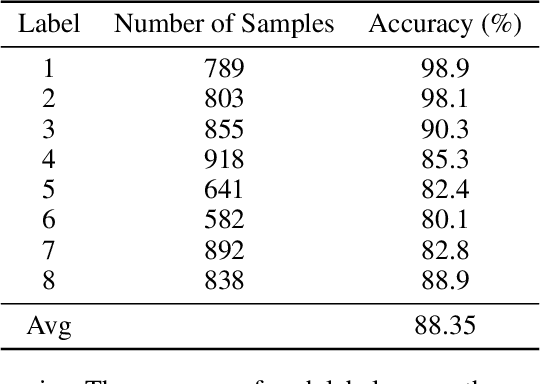
With the rise of telemedicine, the task of developing Dialogue Systems for Medical Diagnosis (DSMD) has received much attention in recent years. Different from early researches that needed to rely on extra human resources and expertise to help construct the system, recent researches focused on how to build DSMD in a purely data-driven manner. However, the previous data-driven DSMD methods largely overlooked the system interpretability, which is critical for a medical application, and they also suffered from the data sparsity issue at the same time. In this paper, we explore how to bring interpretability to data-driven DSMD. Specifically, we propose a more interpretable decision process to implement the dialogue manager of DSMD by reasonably mimicking real doctors' inquiry logics, and we devise a model with highly transparent components to conduct the inference. Moreover, we collect a new DSMD dataset, which has a much larger scale, more diverse patterns and is of higher quality than the existing ones. The experiments show that our method obtains 7.7%, 10.0%, 3.0% absolute improvement in diagnosis accuracy respectively on three datasets, demonstrating the effectiveness of its rational decision process and model design. Our codes and the GMD-12 dataset are available at https://github.com/lwgkzl/BR-Agent.
Localizing the Vehicle's Antenna: an Open Problem in 6G Network Sensing
Apr 03, 2022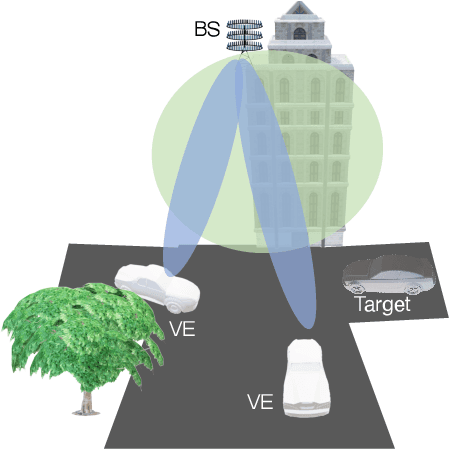
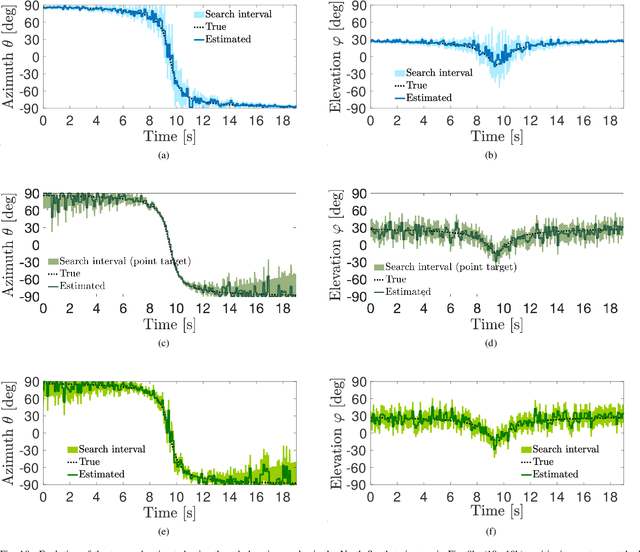
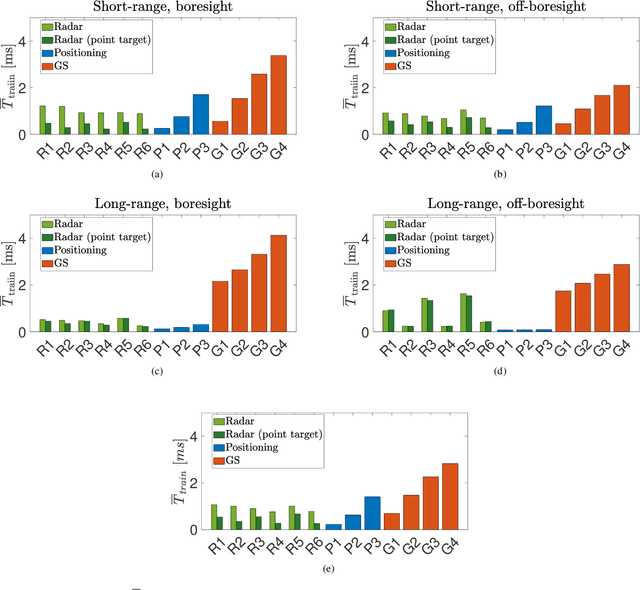
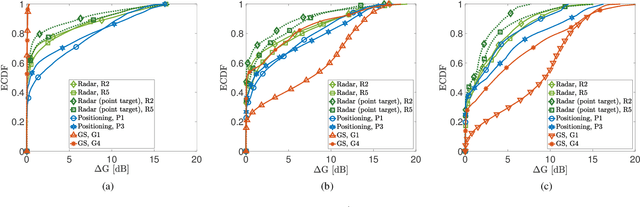
Millimeter Waves (mmW) and sub-THz frequencies are the candidate bands for the upcoming Sixth Generation (6G) of communication systems. The use of collimated beams at mmW/sub-THz to compensate for the increased path and penetration loss arises the need for a seamless Beam Management (BM), especially for high mobility scenarios such as the Vehicle-to-Infrastructure (V2I) one. Recent research advances in Integrated Sensing and Communication (ISAC) indicate that equipping the network infrastructure, e.g., the Base Station (BS), with either a stand-alone radar or sensing capabilities using optimized waveforms, represents the killer technology to facilitate the BM. However, radio sensing should accurately localize the Vehicular Equipment (VE)'s antenna, which is not guaranteed in general. Differently, employing side information from VE's onboard positioning sensors might overcome this limitation at the price of an increased control signaling between VE and BS. This paper provides a pragmatic comparison between radar-assisted and position-assisted BM for mmW V2I systems in a typical urban scenario in terms of BM training time and beamforming gain loss due to a wrong BM decision. Simulation results, supported by experimental evidence, show that the point target approximation of a traveling VE does not hold in practical V2I scenarios with radar-equipped BS. Therefore, the true antenna position has a residual uncertainty that is independent of radar's resolution and implies 50\,\% more BM training time on average. Moreover, there is not a winning technology for BM between BS-mounted radar and VE's onboard positioning systems. They provide complementary performance, depending on position, although outperforming blind BM techniques compared to conventional blind methods. Thus, we propose to optimally combine radar and positioning information in a multi-technology integrated BM solution.
AI-enabled Assessment of Cardiac Systolic and Diastolic Function from Echocardiography
Mar 21, 2022
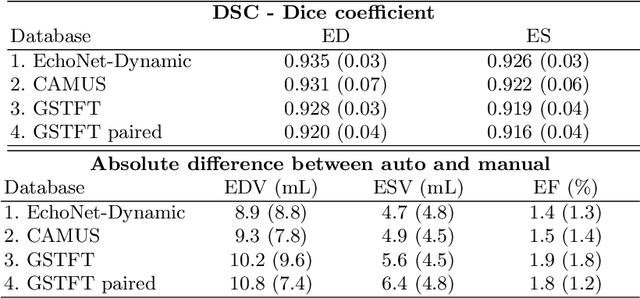
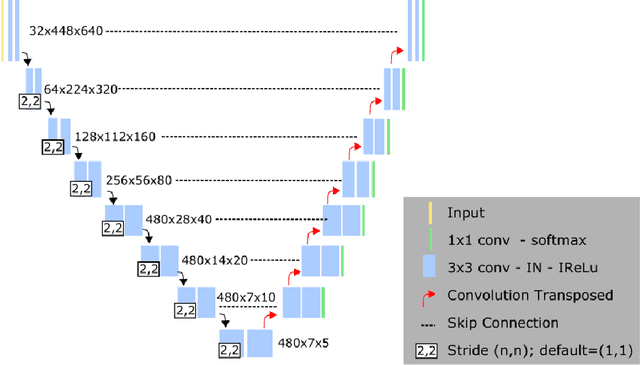

Left ventricular (LV) function is an important factor in terms of patient management, outcome, and long-term survival of patients with heart disease. The most recently published clinical guidelines for heart failure recognise that over reliance on only one measure of cardiac function (LV ejection fraction) as a diagnostic and treatment stratification biomarker is suboptimal. Recent advances in AI-based echocardiography analysis have shown excellent results on automated estimation of LV volumes and LV ejection fraction. However, from time-varying 2-D echocardiography acquisition, a richer description of cardiac function can be obtained by estimating functional biomarkers from the complete cardiac cycle. In this work we propose for the first time an AI approach for deriving advanced biomarkers of systolic and diastolic LV function from 2-D echocardiography based on segmentations of the full cardiac cycle. These biomarkers will allow clinicians to obtain a much richer picture of the heart in health and disease. The AI model is based on the 'nn-Unet' framework and was trained and tested using four different databases. Results show excellent agreement between manual and automated analysis and showcase the potential of the advanced systolic and diastolic biomarkers for patient stratification. Finally, for a subset of 50 cases, we perform a correlation analysis between clinical biomarkers derived from echocardiography and CMR and we show excellent agreement between the two modalities.
Computational behavior recognition in child and adolescent psychiatry: A statistical and machine learning analysis plan
May 11, 2022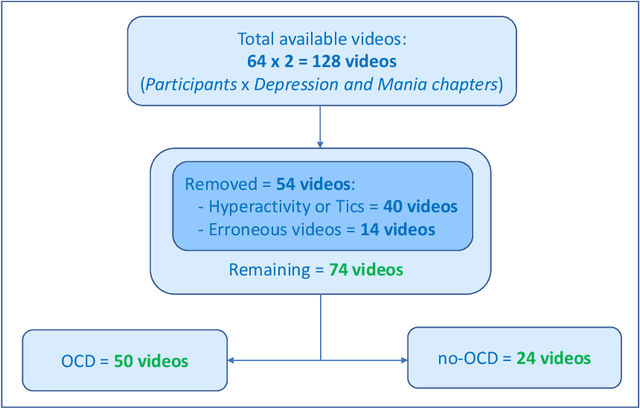
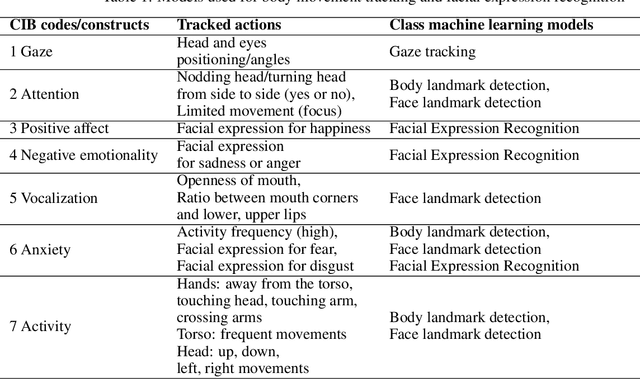
Motivation: Behavioral observations are an important resource in the study and evaluation of psychological phenomena, but it is costly, time-consuming, and susceptible to bias. Thus, we aim to automate coding of human behavior for use in psychotherapy and research with the help of artificial intelligence (AI) tools. Here, we present an analysis plan. Methods: Videos of a gold-standard semi-structured diagnostic interview of 25 youth with obsessive-compulsive disorder (OCD) and 12 youth without a psychiatric diagnosis (no-OCD) will be analyzed. Youth were between 8 and 17 years old. Features from the videos will be extracted and used to compute ratings of behavior, which will be compared to ratings of behavior produced by mental health professionals trained to use a specific behavioral coding manual. We will test the effect of OCD diagnosis on the computationally-derived behavior ratings using multivariate analysis of variance (MANOVA). Using the generated features, a binary classification model will be built and used to classify OCD/no-OCD classes. Discussion: Here, we present a pre-defined plan for how data will be pre-processed, analyzed and presented in the publication of results and their interpretation. A challenge for the proposed study is that the AI approach will attempt to derive behavioral ratings based solely on vision, whereas humans use visual, paralinguistic and linguistic cues to rate behavior. Another challenge will be using machine learning models for body and facial movement detection trained primarily on adults and not on children. If the AI tools show promising results, this pre-registered analysis plan may help reduce interpretation bias. Trial registration: ClinicalTrials.gov - H-18010607
Q-TART: Quickly Training for Adversarial Robustness and in-Transferability
Apr 14, 2022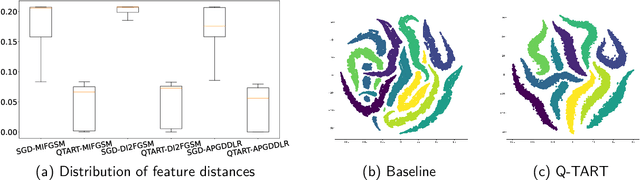
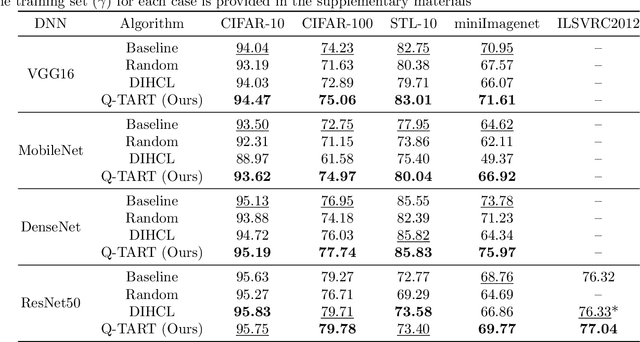
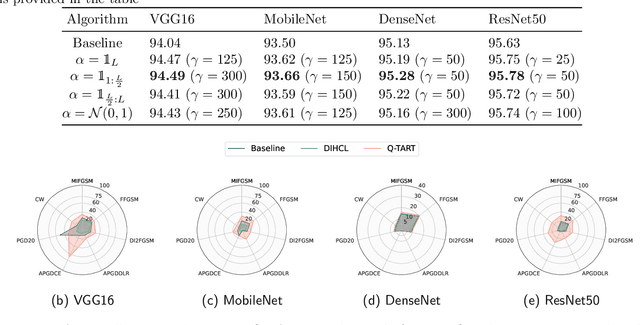
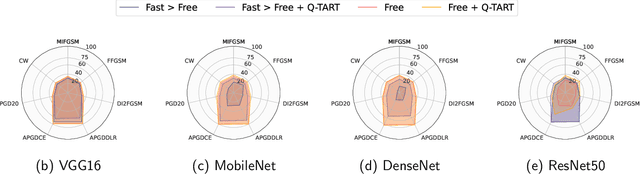
Raw deep neural network (DNN) performance is not enough; in real-world settings, computational load, training efficiency and adversarial security are just as or even more important. We propose to simultaneously tackle Performance, Efficiency, and Robustness, using our proposed algorithm Q-TART, Quickly Train for Adversarial Robustness and in-Transferability. Q-TART follows the intuition that samples highly susceptible to noise strongly affect the decision boundaries learned by DNNs, which in turn degrades their performance and adversarial susceptibility. By identifying and removing such samples, we demonstrate improved performance and adversarial robustness while using only a subset of the training data. Through our experiments we highlight Q-TART's high performance across multiple Dataset-DNN combinations, including ImageNet, and provide insights into the complementary behavior of Q-TART alongside existing adversarial training approaches to increase robustness by over 1.3% while using up to 17.9% less training time.
Dynamic Deep Convolutional Candlestick Learner
Jan 21, 2022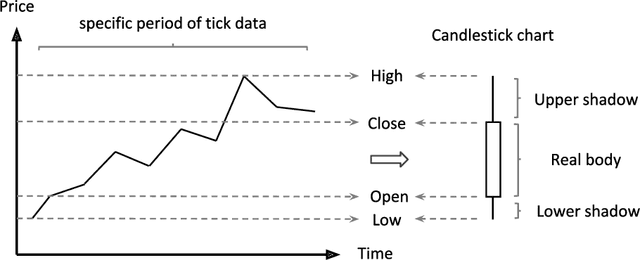
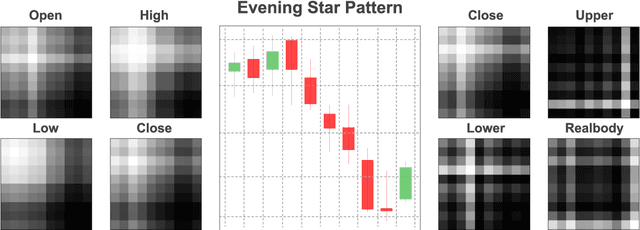
Candlestick pattern is one of the most fundamental and valuable graphical tools in financial trading that supports traders observing the current market conditions to make the proper decision. This task has a long history and, most of the time, human experts. Recently, efforts have been made to automatically classify these patterns with the deep learning models. The GAF-CNN model is a well-suited way to imitate how human traders capture the candlestick pattern by integrating spatial features visually. However, with the great potential of the GAF encoding, this classification task can be extended to a more complicated object detection level. This work presents an innovative integration of modern object detection techniques and GAF time-series encoding on candlestick pattern tasks. We make crucial modifications to the representative yet straightforward YOLO version 1 model based on our time-series encoding method and the property of such data type. Powered by the deep neural networks and the unique architectural design, the proposed model performs pretty well in candlestick classification and location recognition. The results show tremendous potential in applying modern object detection techniques on time-series tasks in a real-time manner.
Conflict-Based Search for Explainable Multi-Agent Path Finding
Feb 20, 2022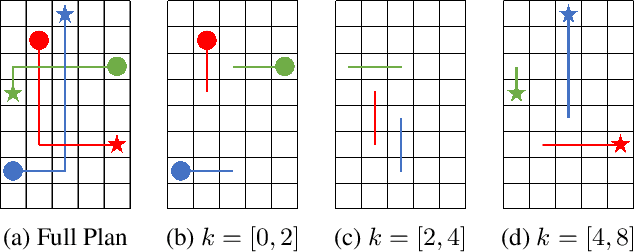
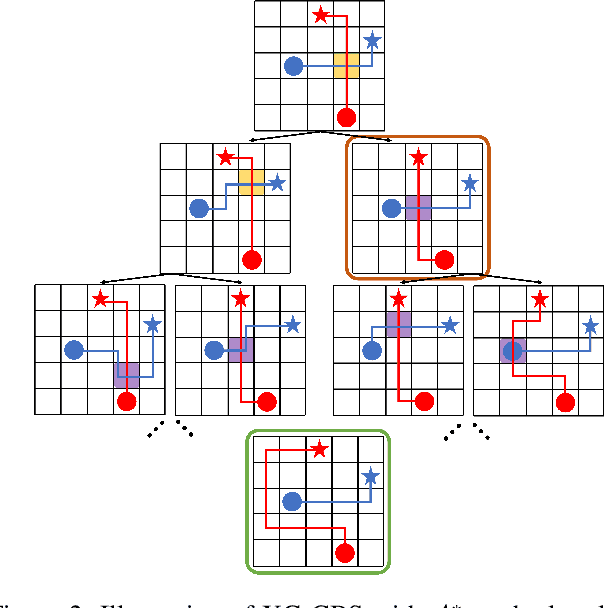
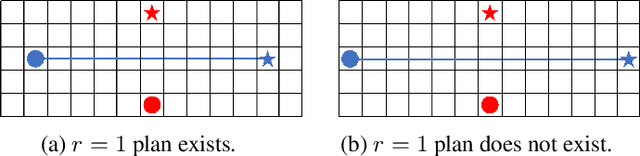
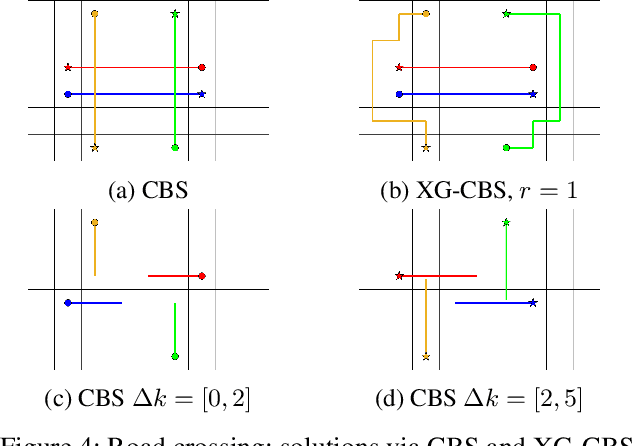
In the Multi-Agent Path Finding (MAPF) problem, the goal is to find non-colliding paths for agents in an environment, such that each agent reaches its goal from its initial location. In safety-critical applications, a human supervisor may want to verify that the plan is indeed collision-free. To this end, a recent work introduces a notion of explainability for MAPF based on a visualization of the plan as a short sequence of images representing time segments, where in each time segment the trajectories of the agents are disjoint. Then, the explainable MAPF problem asks for a set of non-colliding paths that admits a short-enough explanation. Explainable MAPF adds a new difficulty to MAPF, in that it is NP-hard with respect to the size of the environment, and not just the number of agents. Thus, traditional MAPF algorithms are not equipped to directly handle explainable-MAPF. In this work, we adapt Conflict Based Search (CBS), a well-studied algorithm for MAPF, to handle explainable MAPF. We show how to add explainability constraints on top of the standard CBS tree and its underlying A* search. We examine the usefulness of this approach and, in particular, the tradeoff between planning time and explainability.