 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedCore: Straggler-Free Federated Learning with Distributed Coresets
Jan 31, 2024



Federated learning (FL) is a machine learning paradigm that allows multiple clients to collaboratively train a shared model while keeping their data on-premise. However, the straggler issue, due to slow clients, often hinders the efficiency and scalability of FL. This paper presents FedCore, an algorithm that innovatively tackles the straggler problem via the decentralized selection of coresets, representative subsets of a dataset. Contrary to existing centralized coreset methods, FedCore creates coresets directly on each client in a distributed manner, ensuring privacy preservation in FL. FedCore translates the coreset optimization problem into a more tractable k-medoids clustering problem and operates distributedly on each client. Theoretical analysis confirms FedCore's convergence, and practical evaluations demonstrate an 8x reduction in FL training time, without compromising model accuracy. Our extensive evaluations also show that FedCore generalizes well to existing FL frameworks.
Transportation Market Rate Forecast Using Signature Transform
Jan 10, 2024



Currently, Amazon relies on third parties for transportation marketplace rate forecasts, despite the poor quality and lack of interpretability of these forecasts. While transportation marketplace rates are typically very challenging to forecast accurately, we have developed a novel signature-based statistical technique to address these challenges and built a predictive and adaptive model to forecast marketplace rates. This novel technique is based on two key properties of the signature transform. The first is its universal nonlinearity which linearizes the feature space and hence translates the forecasting problem into a linear regression analysis; the second is the signature kernel which allows for comparing computationally efficiently similarities between time series data. Combined, these properties allow for efficient feature generation and more precise identification of seasonality and regime switching in the forecasting process. Preliminary result by the model shows that this new technique leads to far superior forecast accuracy versus commercially available industry models with better interpretability, even during the period of Covid-19 and with the sudden onset of the Ukraine war.
Risk of Transfer Learning and its Applications in Finance
Nov 06, 2023



Transfer learning is an emerging and popular paradigm for utilizing existing knowledge from previous learning tasks to improve the performance of new ones. In this paper, we propose a novel concept of transfer risk and and analyze its properties to evaluate transferability of transfer learning. We apply transfer learning techniques and this concept of transfer risk to stock return prediction and portfolio optimization problems. Numerical results demonstrate a strong correlation between transfer risk and overall transfer learning performance, where transfer risk provides a computationally efficient way to identify appropriate source tasks in transfer learning, including cross-continent, cross-sector, and cross-frequency transfer for portfolio optimization.
Transfer Learning for Portfolio Optimization
Jul 25, 2023



In this work, we explore the possibility of utilizing transfer learning techniques to address the financial portfolio optimization problem. We introduce a novel concept called "transfer risk", within the optimization framework of transfer learning. A series of numerical experiments are conducted from three categories: cross-continent transfer, cross-sector transfer, and cross-frequency transfer. In particular, 1. a strong correlation between the transfer risk and the overall performance of transfer learning methods is established, underscoring the significance of transfer risk as a viable indicator of "transferability"; 2. transfer risk is shown to provide a computationally efficient way to identify appropriate source tasks in transfer learning, enhancing the efficiency and effectiveness of the transfer learning approach; 3. additionally, the numerical experiments offer valuable new insights for portfolio management across these different settings.
Feasibility of Transfer Learning: A Mathematical Framework
May 22, 2023
Transfer learning is a popular paradigm for utilizing existing knowledge from previous learning tasks to improve the performance of new ones. It has enjoyed numerous empirical successes and inspired a growing number of theoretical studies. This paper addresses the feasibility issue of transfer learning. It begins by establishing the necessary mathematical concepts and constructing a mathematical framework for transfer learning. It then identifies and formulates the three-step transfer learning procedure as an optimization problem, allowing for the resolution of the feasibility issue. Importantly, it demonstrates that under certain technical conditions, such as appropriate choice of loss functions and data sets, an optimal procedure for transfer learning exists. This study of the feasibility issue brings additional insights into various transfer learning problems. It sheds light on the impact of feature augmentation on model performance, explores potential extensions of domain adaptation, and examines the feasibility of efficient feature extractor transfer in image classification.
Feasibility and Transferability of Transfer Learning: A Mathematical Framework
Jan 27, 2023



Transfer learning is an emerging and popular paradigm for utilizing existing knowledge from previous learning tasks to improve the performance of new ones. Despite its numerous empirical successes, theoretical analysis for transfer learning is limited. In this paper we build for the first time, to the best of our knowledge, a mathematical framework for the general procedure of transfer learning. Our unique reformulation of transfer learning as an optimization problem allows for the first time, analysis of its feasibility. Additionally, we propose a novel concept of transfer risk to evaluate transferability of transfer learning. Our numerical studies using the Office-31 dataset demonstrate the potential and benefits of incorporating transfer risk in the evaluation of transfer learning performance.
Automated Quality Controlled Analysis of 2D Phase Contrast Cardiovascular Magnetic Resonance Imaging
Sep 28, 2022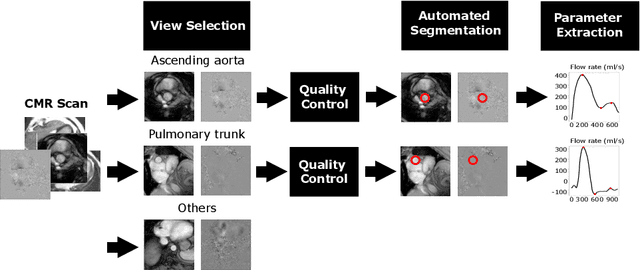
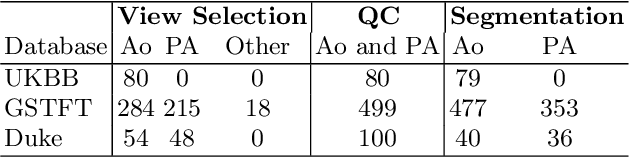
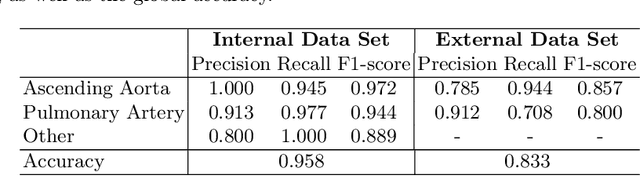
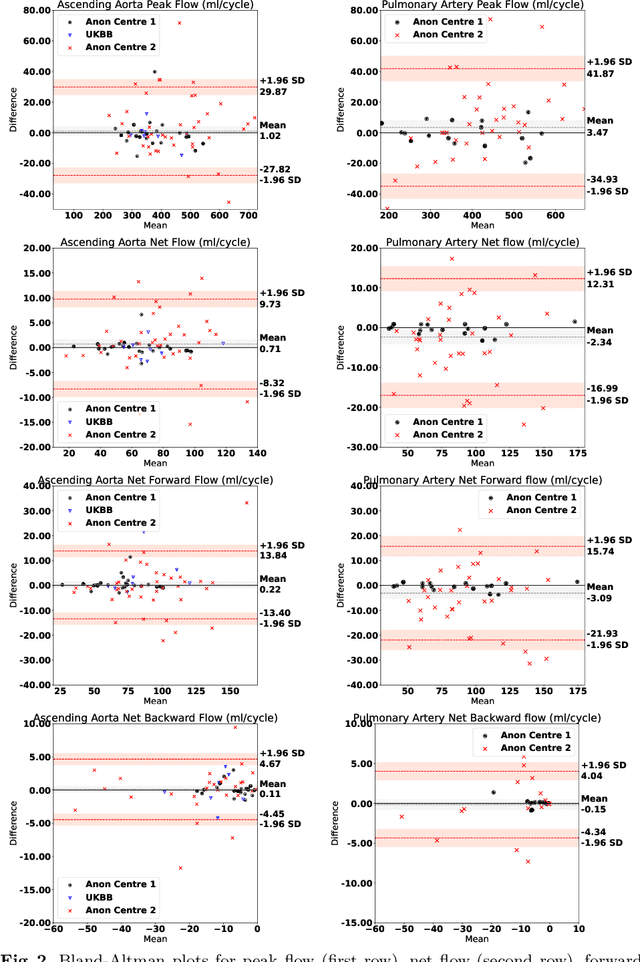
Flow analysis carried out using phase contrast cardiac magnetic resonance imaging (PC-CMR) enables the quantification of important parameters that are used in the assessment of cardiovascular function. An essential part of this analysis is the identification of the correct CMR views and quality control (QC) to detect artefacts that could affect the flow quantification. We propose a novel deep learning based framework for the fully-automated analysis of flow from full CMR scans that first carries out these view selection and QC steps using two sequential convolutional neural networks, followed by automatic aorta and pulmonary artery segmentation to enable the quantification of key flow parameters. Accuracy values of 0.958 and 0.914 were obtained for view classification and QC, respectively. For segmentation, Dice scores were $>$0.969 and the Bland-Altman plots indicated excellent agreement between manual and automatic peak flow values. In addition, we tested our pipeline on an external validation data set, with results indicating good robustness of the pipeline. This work was carried out using multivendor clinical data consisting of 986 cases, indicating the potential for the use of this pipeline in a clinical setting.
Multi-level Adaptation for Automatic Landing with Engine Failure under Turbulent Weather
Sep 09, 2022
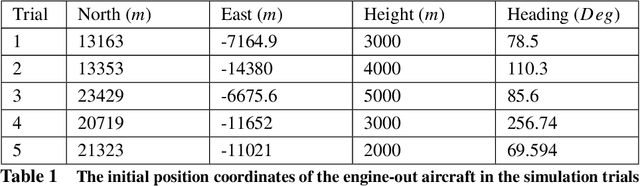
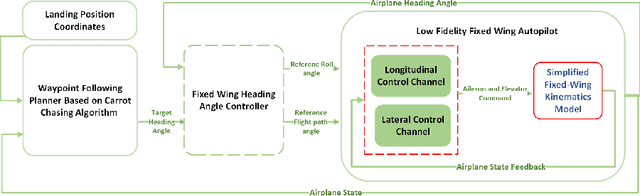
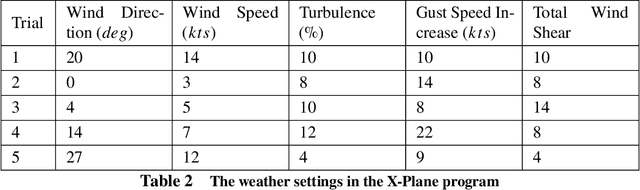
This paper addresses efficient feasibility evaluation of possible emergency landing sites, online navigation, and path following for automatic landing under engine-out failure subject to turbulent weather. The proposed Multi-level Adaptive Safety Control framework enables unmanned aerial vehicles (UAVs) under large uncertainties to perform safety maneuvers traditionally reserved for human pilots with sufficient experience. In this framework, a simplified flight model is first used for time-efficient feasibility evaluation of a set of landing sites and trajectory generation. Then, an online path following controller is employed to track the selected landing trajectory. We used a high-fidelity simulation environment for a fixed-wing aircraft to test and validate the proposed approach under various weather uncertainties. For the case of emergency landing due to engine failure under severe weather conditions, the simulation results show that the proposed automatic landing framework is robust to uncertainties and adaptable at different landing stages while being computationally inexpensive for planning and tracking tasks.
AI-enabled Assessment of Cardiac Systolic and Diastolic Function from Echocardiography
Mar 21, 2022
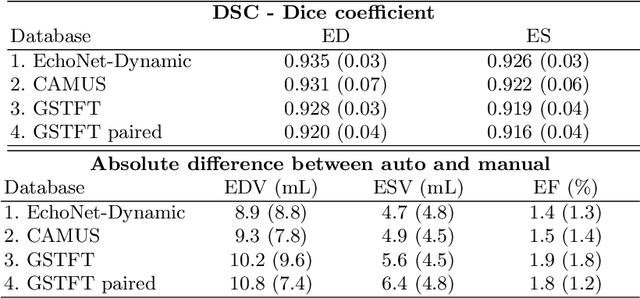
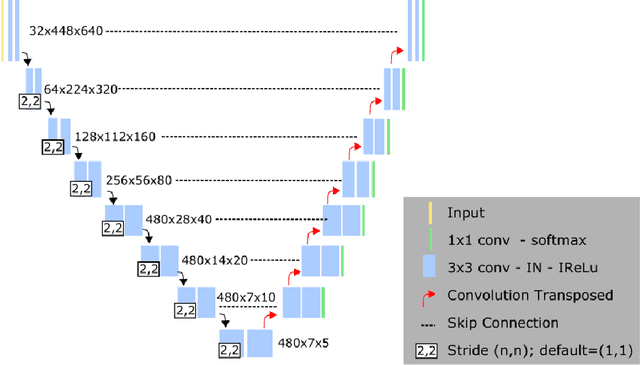

Left ventricular (LV) function is an important factor in terms of patient management, outcome, and long-term survival of patients with heart disease. The most recently published clinical guidelines for heart failure recognise that over reliance on only one measure of cardiac function (LV ejection fraction) as a diagnostic and treatment stratification biomarker is suboptimal. Recent advances in AI-based echocardiography analysis have shown excellent results on automated estimation of LV volumes and LV ejection fraction. However, from time-varying 2-D echocardiography acquisition, a richer description of cardiac function can be obtained by estimating functional biomarkers from the complete cardiac cycle. In this work we propose for the first time an AI approach for deriving advanced biomarkers of systolic and diastolic LV function from 2-D echocardiography based on segmentations of the full cardiac cycle. These biomarkers will allow clinicians to obtain a much richer picture of the heart in health and disease. The AI model is based on the 'nn-Unet' framework and was trained and tested using four different databases. Results show excellent agreement between manual and automated analysis and showcase the potential of the advanced systolic and diastolic biomarkers for patient stratification. Finally, for a subset of 50 cases, we perform a correlation analysis between clinical biomarkers derived from echocardiography and CMR and we show excellent agreement between the two modalities.
Mean-Field Multi-Agent Reinforcement Learning: A Decentralized Network Approach
Aug 05, 2021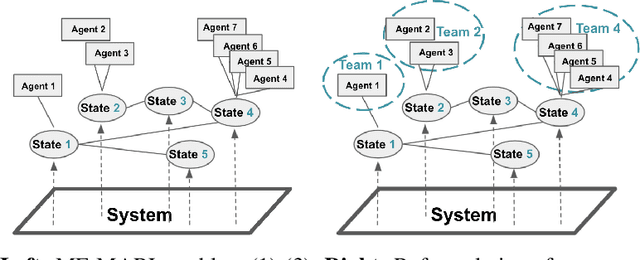
One of the challenges for multi-agent reinforcement learning (MARL) is designing efficient learning algorithms for a large system in which each agent has only limited or partial information of the entire system. In this system, it is desirable to learn policies of a decentralized type. A recent and promising paradigm to analyze such decentralized MARL is to take network structures into consideration. While exciting progress has been made to analyze decentralized MARL with the network of agents, often found in social networks and team video games, little is known theoretically for decentralized MARL with the network of states, frequently used for modeling self-driving vehicles, ride-sharing, and data and traffic routing. This paper proposes a framework called localized training and decentralized execution to study MARL with network of states, with homogeneous (a.k.a. mean-field type) agents. Localized training means that agents only need to collect local information in their neighboring states during the training phase; decentralized execution implies that, after the training stage, agents can execute the learned decentralized policies, which only requires knowledge of the agents' current states. The key idea is to utilize the homogeneity of agents and regroup them according to their states, thus the formulation of a networked Markov decision process with teams of agents, enabling the update of the Q-function in a localized fashion. In order to design an efficient and scalable reinforcement learning algorithm under such a framework, we adopt the actor-critic approach with over-parameterized neural networks, and establish the convergence and sample complexity for our algorithm, shown to be scalable with respect to the size of both agents and states.