 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FPSRS: A Fusion Approach for Paper Submission Recommendation System
May 12, 2022
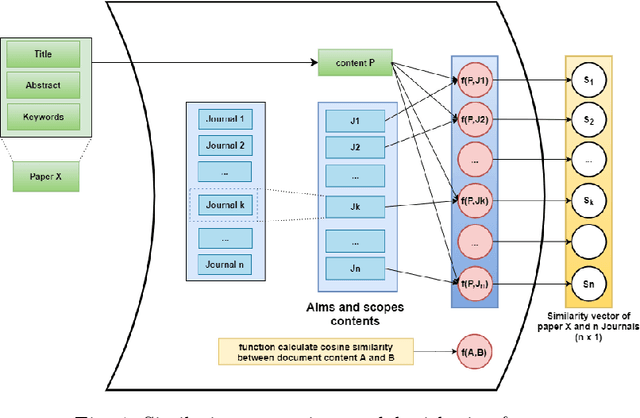
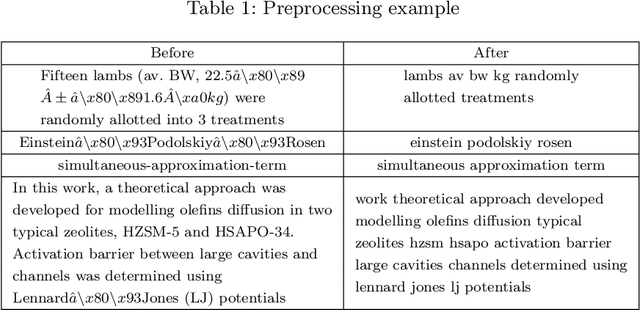

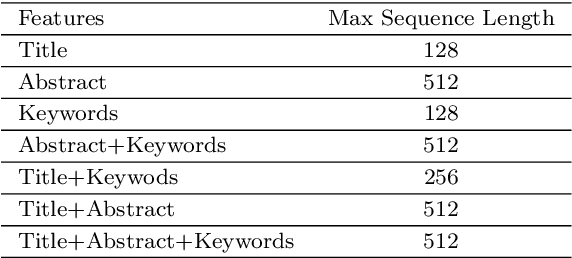
Recommender systems have been increasingly popular in entertainment and consumption and are evident in academics, especially for applications that suggest submitting scientific articles to scientists. However, because of the various acceptance rates, impact factors, and rankings in different publishers, searching for a proper venue or journal to submit a scientific work usually takes a lot of time and effort. In this paper, we aim to present two newer approaches extended from our paper [13] presented at the conference IAE/AIE 2021 by employing RNN structures besides using Conv1D. In addition, we also introduce a new method, namely DistilBertAims, using DistillBert for two cases of uppercase and lower-case words to vectorize features such as Title, Abstract, and Keywords, and then use Conv1d to perform feature extraction. Furthermore, we propose a new calculation method for similarity score for Aim & Scope with other features; this helps keep the weights of similarity score calculation continuously updated and then continue to fit more data. The experimental results show that the second approach could obtain a better performance, which is 62.46% and 12.44% higher than the best of the previous study [13] in terms of the Top 1 accuracy.
Explainable Tensorized Neural Ordinary Differential Equations forArbitrary-step Time Series Prediction
Nov 26, 2020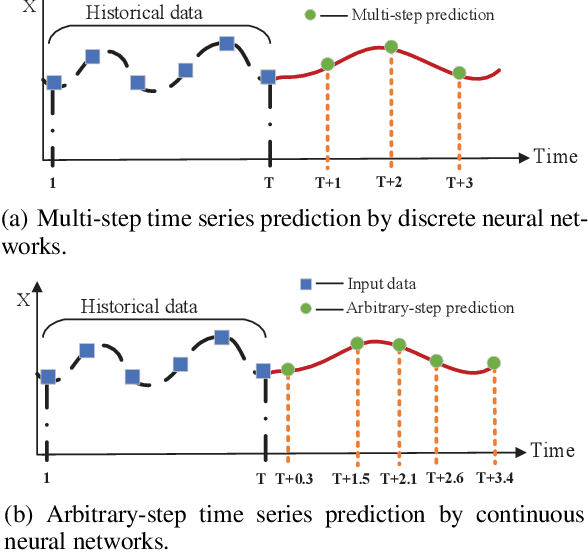
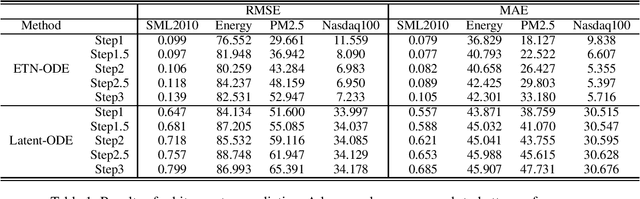
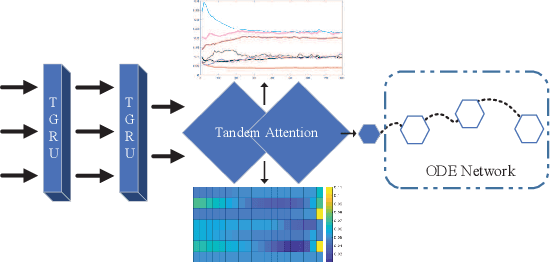
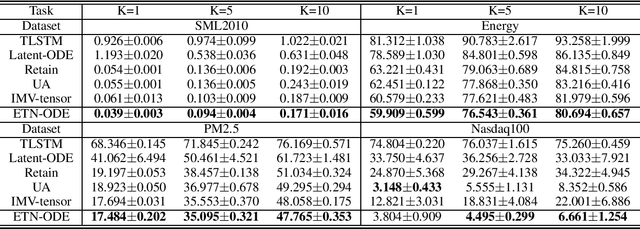
We propose a continuous neural network architecture, termed Explainable Tensorized Neural Ordinary Differential Equations (ETN-ODE), for multi-step time series prediction at arbitrary time points. Unlike the existing approaches, which mainly handle univariate time series for multi-step prediction or multivariate time series for single-step prediction, ETN-ODE could model multivariate time series for arbitrary-step prediction. In addition, it enjoys a tandem attention, w.r.t. temporal attention and variable attention, being able to provide explainable insights into the data. Specifically, ETN-ODE combines an explainable Tensorized Gated Recurrent Unit (Tensorized GRU or TGRU) with Ordinary Differential Equations (ODE). The derivative of the latent states is parameterized with a neural network. This continuous-time ODE network enables a multi-step prediction at arbitrary time points. We quantitatively and qualitatively demonstrate the effectiveness and the interpretability of ETN-ODE on five different multi-step prediction tasks and one arbitrary-step prediction task. Extensive experiments show that ETN-ODE can lead to accurate predictions at arbitrary time points while attaining best performance against the baseline methods in standard multi-step time series prediction.
Bypassing Logits Bias in Online Class-Incremental Learning with a Generative Framework
May 19, 2022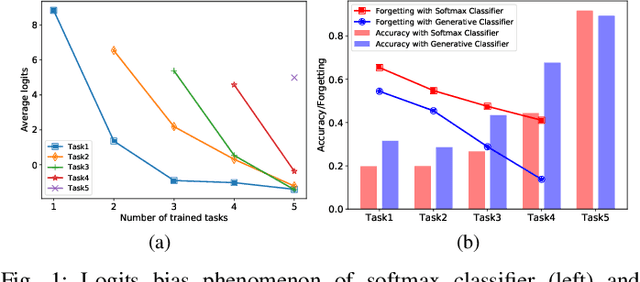
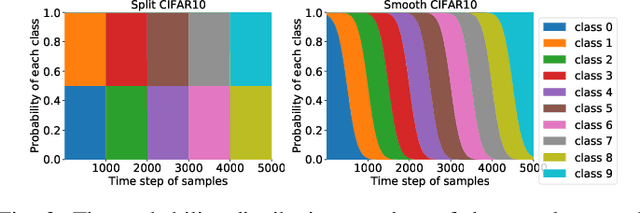
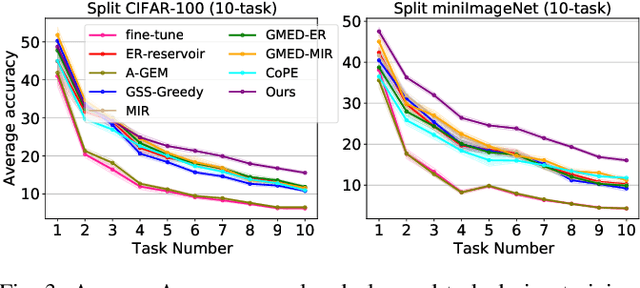
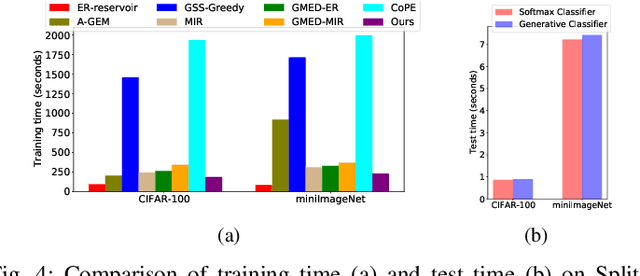
Continual learning requires the model to maintain the learned knowledge while learning from a non-i.i.d data stream continually. Due to the single-pass training setting, online continual learning is very challenging, but it is closer to the real-world scenarios where quick adaptation to new data is appealing. In this paper, we focus on online class-incremental learning setting in which new classes emerge over time. Almost all existing methods are replay-based with a softmax classifier. However, the inherent logits bias problem in the softmax classifier is a main cause of catastrophic forgetting while existing solutions are not applicable for online settings. To bypass this problem, we abandon the softmax classifier and propose a novel generative framework based on the feature space. In our framework, a generative classifier which utilizes replay memory is used for inference, and the training objective is a pair-based metric learning loss which is proven theoretically to optimize the feature space in a generative way. In order to improve the ability to learn new data, we further propose a hybrid of generative and discriminative loss to train the model. Extensive experiments on several benchmarks, including newly introduced task-free datasets, show that our method beats a series of state-of-the-art replay-based methods with discriminative classifiers, and reduces catastrophic forgetting consistently with a remarkable margin.
Accelerating Offline Reinforcement Learning Application in Real-Time Bidding and Recommendation: Potential Use of Simulation
Sep 17, 2021
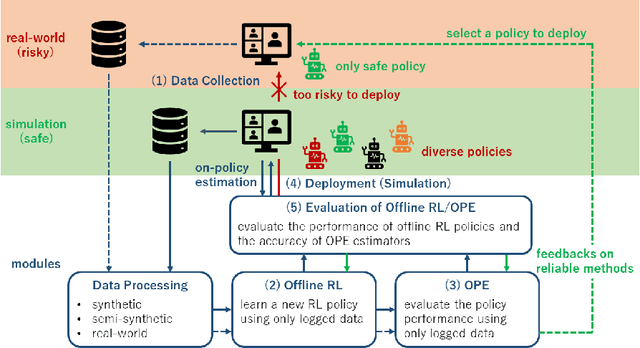
In recommender systems (RecSys) and real-time bidding (RTB) for online advertisements, we often try to optimize sequential decision making using bandit and reinforcement learning (RL) techniques. In these applications, offline reinforcement learning (offline RL) and off-policy evaluation (OPE) are beneficial because they enable safe policy optimization using only logged data without any risky online interaction. In this position paper, we explore the potential of using simulation to accelerate practical research of offline RL and OPE, particularly in RecSys and RTB. Specifically, we discuss how simulation can help us conduct empirical research of offline RL and OPE. We take a position to argue that we should effectively use simulations in the empirical research of offline RL and OPE. To refute the counterclaim that experiments using only real-world data are preferable, we first point out the underlying risks and reproducibility issue in real-world experiments. Then, we describe how these issues can be addressed by using simulations. Moreover, we show how to incorporate the benefits of both real-world and simulation-based experiments to defend our position. Finally, we also present an open challenge to further facilitate practical research of offline RL and OPE in RecSys and RTB, with respect to public simulation platforms. As a possible solution for the issue, we show our ongoing open source project and its potential use case. We believe that building and utilizing simulation-based evaluation platforms for offline RL and OPE will be of great interest and relevance for the RecSys and RTB community.
Beyond Distributional Hypothesis: Let Language Models Learn Meaning-Text Correspondence
May 08, 2022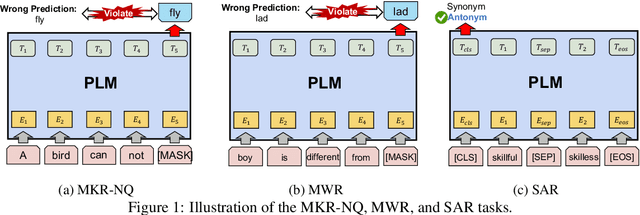
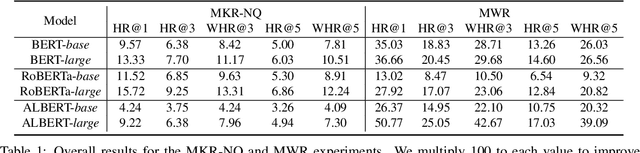
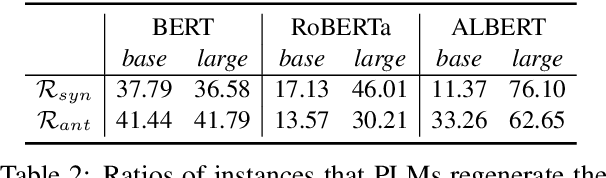
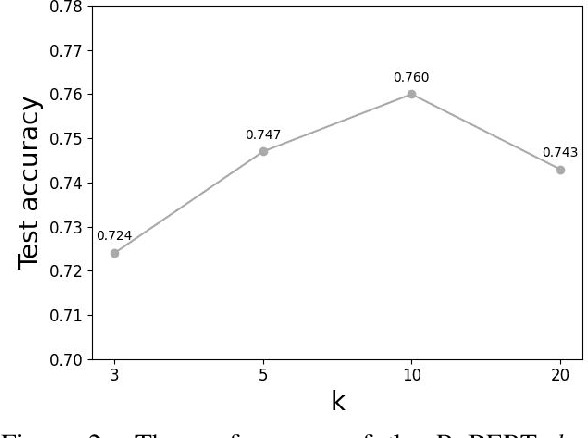
The logical negation property (LNP), which implies generating different predictions for semantically opposite inputs, is an important property that a trustworthy language model must satisfy. However, much recent evidence shows that large-size pre-trained language models (PLMs) do not satisfy this property. In this paper, we perform experiments using probing tasks to assess PLM's LNP understanding. Unlike previous studies that only examined negation expressions, we expand the boundary of the investigation to lexical semantics. Through experiments, we observe that PLMs violate the LNP frequently. To alleviate the issue, we propose a novel intermediate training task, names meaning-matching, designed to directly learn a meaning-text correspondence, instead of relying on the distributional hypothesis. Through multiple experiments, we find that the task enables PLMs to learn lexical semantic information. Also, through fine-tuning experiments on 7 GLUE tasks, we confirm that it is a safe intermediate task that guarantees a similar or better performance of downstream tasks. Finally, we observe that our proposed approach outperforms our previous counterparts despite its time and resource efficiency.
Scaling of neural-network quantum states for time evolution
Apr 21, 2021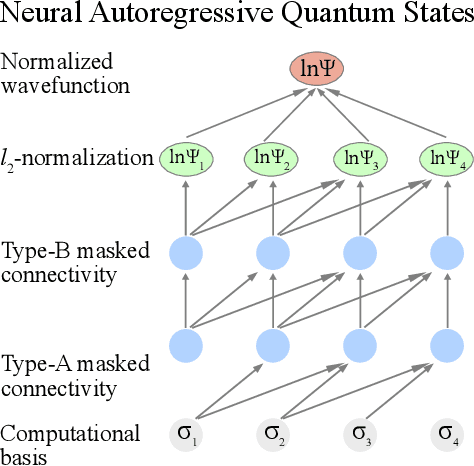
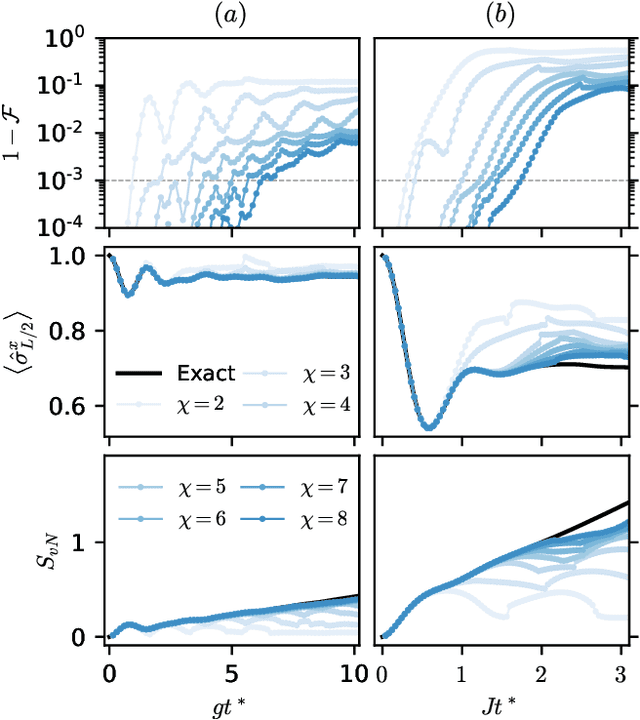
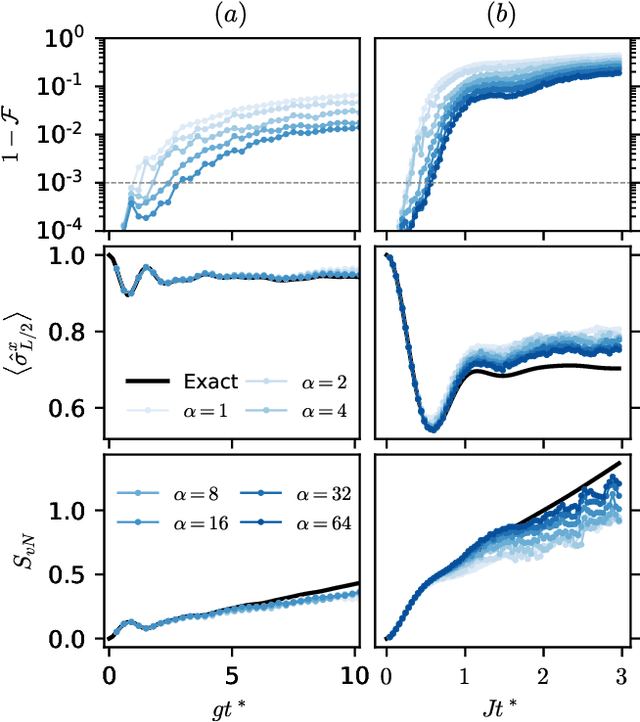
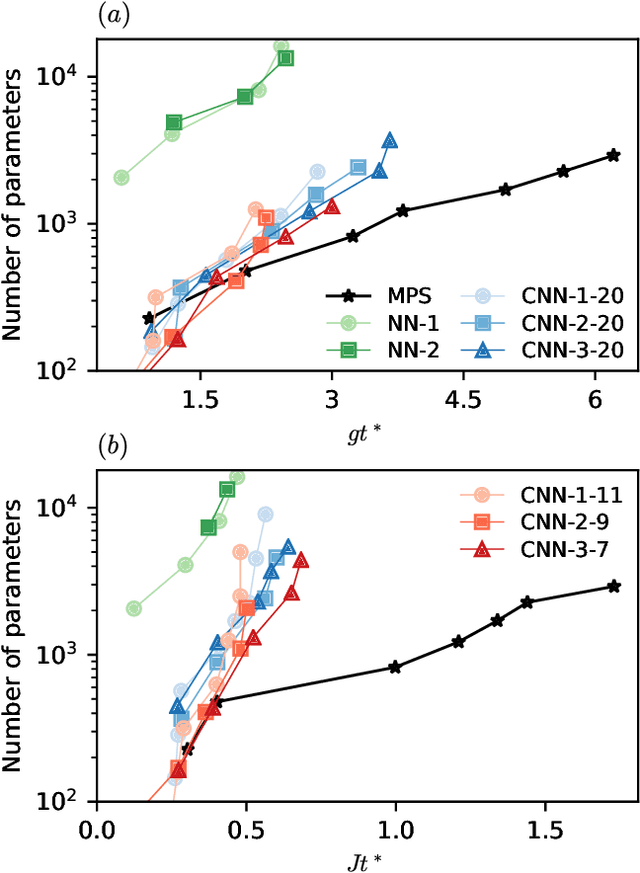
Simulating quantum many-body dynamics on classical computers is a challenging problem due to the exponential growth of the Hilbert space. Artificial neural networks have recently been introduced as a new tool to approximate quantum-many body states. We benchmark the variational power of different shallow and deep neural autoregressive quantum states to simulate global quench dynamics of a non-integrable quantum Ising chain. We find that the number of parameters required to represent the quantum state at a given accuracy increases exponentially in time. The growth rate is only slightly affected by the network architecture over a wide range of different design choices: shallow and deep networks, small and large filter sizes, dilated and normal convolutions, with and without shortcut connections.
Classifying Human Activities using Machine Learning and Deep Learning Techniques
May 19, 2022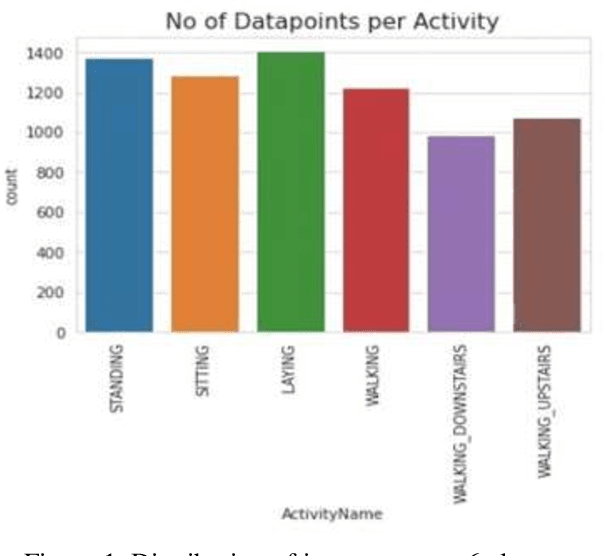

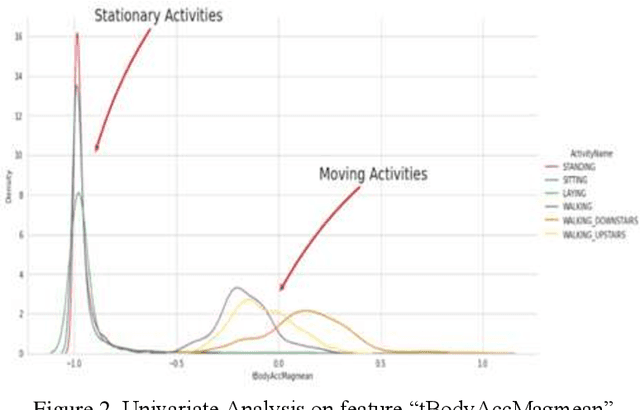

Human Activity Recognition (HAR) describes the machines ability to recognize human actions. Nowadays, most people on earth are health conscious, so people are more interested in tracking their daily activities using Smartphones or Smart Watches, which can help them manage their daily routines in a healthy way. With this objective, Kaggle has conducted a competition to classify 6 different human activities distinctly based on the inertial signals obtained from 30 volunteers smartphones. The main challenge in HAR is to overcome the difficulties of separating human activities based on the given data such that no two activities overlap. In this experimentation, first, Data visualization is done on expert generated features with the help of t distributed Stochastic Neighborhood Embedding followed by applying various Machine Learning techniques like Logistic Regression, Linear SVC, Kernel SVM, Decision trees to better classify the 6 distinct human activities. Moreover, Deep Learning techniques like Long Short-Term Memory (LSTM), Bi-Directional LSTM, Recurrent Neural Network (RNN), and Gated Recurrent Unit (GRU) are trained using raw time series data. Finally, metrics like Accuracy, Confusion matrix, precision and recall are used to evaluate the performance of the Machine Learning and Deep Learning models. Experiment results proved that the Linear Support Vector Classifier in machine learning and Gated Recurrent Unit in Deep Learning provided better accuracy for human activity recognition compared to other classifiers.
Efficient FFT Computation in IFDMA Transceivers
Mar 05, 2022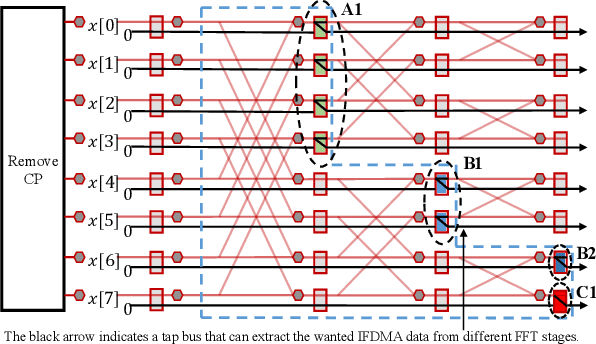
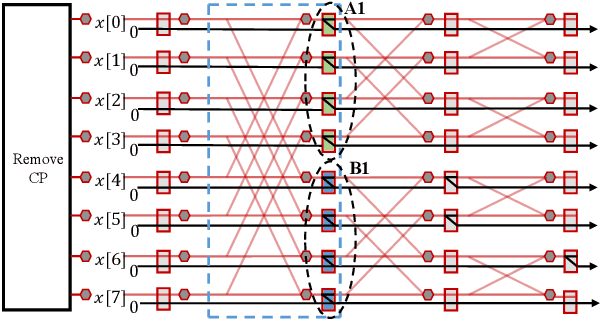
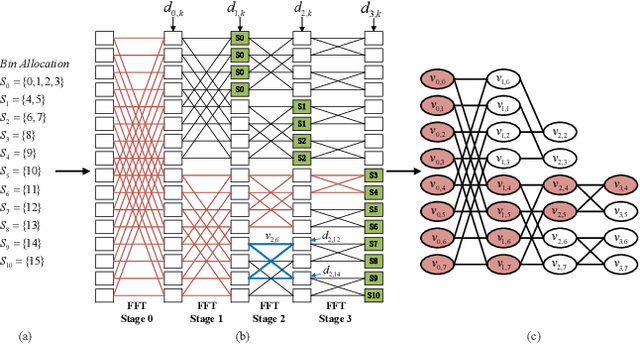

Interleaved Frequency Division Multiple Access (IFDMA) has the salient advantage of lower Peak-to-Average Power Ratio (PAPR) than its competitors like Orthogonal FDMA (OFDMA). A recent research effort put forth a new IFDMA transceiver design significantly less complex than conventional IFDMA transceivers. The new IFDMA transceiver design reduces the complexity by exploiting a certain correspondence between the IFDMA signal processing and the Cooley-Tukey IFFT/FFT algorithmic structure so that IFDMA streams can be inserted/extracted at different stages of an IFFT/FFT module according to the sizes of the streams. Although the prior work has laid down the theoretical foundation for the new IFDMA transceiver's structure, the practical realization of the transceiver on specific hardware with resource constraints has not been carefully investigated. This paper is an attempt to fill the gap. Specifically, this paper puts forth a heuristic algorithm called multi-priority scheduling (MPS) to schedule the execution of the butterfly computations in the IFDMA transceiver with the constraint of a limited number of hardware processors. The resulting FFT computation, referred to as MPS-FFT, has a much lower computation time than conventional FFT computation when applied to the IFDMA signal processing. Importantly, we derive a lower bound for the optimal IFDMA FFT computation time to benchmark MPS-FFT. Our experimental results indicate that when the number of hardware processors is a power of two: 1) MPS-FFT has near-optimal computation time; 2) MPS-FFT incurs less than 44.13\% of the computation time of the conventional pipelined FFT.
The Fast Johnson-Lindenstrauss Transform is Even Faster
Apr 04, 2022The seminal Fast Johnson-Lindenstrauss (Fast JL) transform by Ailon and Chazelle (SICOMP'09) embeds a set of $n$ points in $d$-dimensional Euclidean space into optimal $k=O(\varepsilon^{-2} \ln n)$ dimensions, while preserving all pairwise distances to within a factor $(1 \pm \varepsilon)$. The Fast JL transform supports computing the embedding of a data point in $O(d \ln d +k \ln^2 n)$ time, where the $d \ln d$ term comes from multiplication with a $d \times d$ Hadamard matrix and the $k \ln^2 n$ term comes from multiplication with a sparse $k \times d$ matrix. Despite the Fast JL transform being more than a decade old, it is one of the fastest dimensionality reduction techniques for many tradeoffs between $\varepsilon, d$ and $n$. In this work, we give a surprising new analysis of the Fast JL transform, showing that the $k \ln^2 n$ term in the embedding time can be improved to $(k \ln^2 n)/\alpha$ for an $\alpha = \Omega(\min\{\varepsilon^{-1}\ln(1/\varepsilon), \ln n\})$. The improvement follows by using an even sparser matrix. We also complement our improved analysis with a lower bound showing that our new analysis is in fact tight.
Symmetry and Uncertainty-Aware Object SLAM for 6DoF Object Pose Estimation
May 04, 2022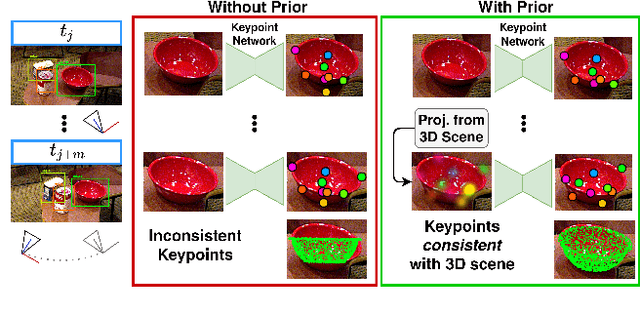
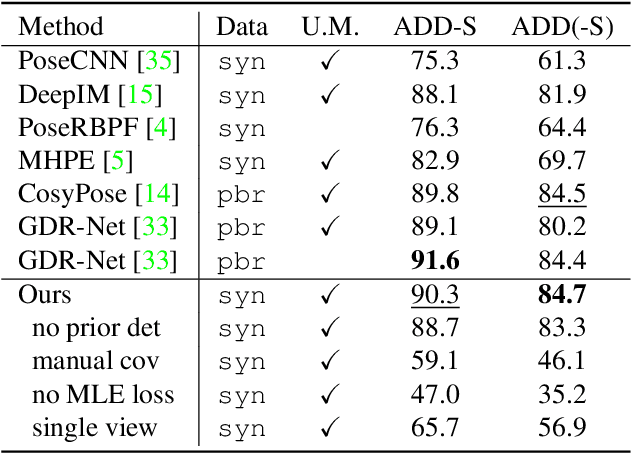
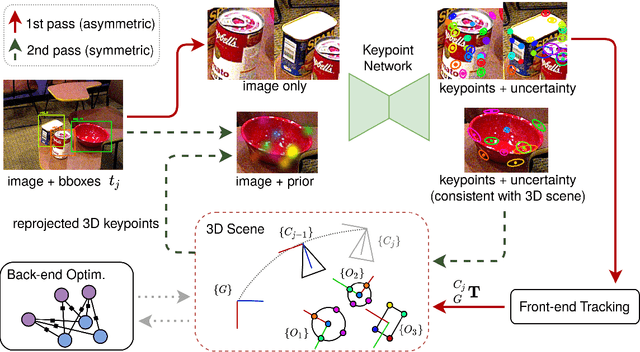
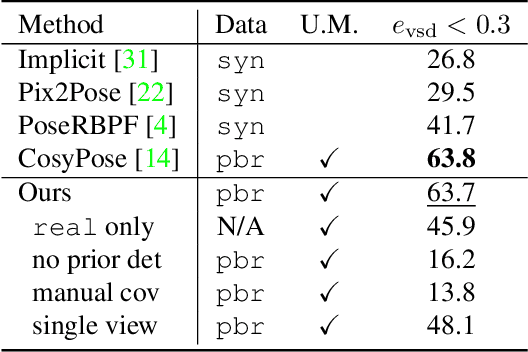
We propose a keypoint-based object-level SLAM framework that can provide globally consistent 6DoF pose estimates for symmetric and asymmetric objects alike. To the best of our knowledge, our system is among the first to utilize the camera pose information from SLAM to provide prior knowledge for tracking keypoints on symmetric objects -- ensuring that new measurements are consistent with the current 3D scene. Moreover, our semantic keypoint network is trained to predict the Gaussian covariance for the keypoints that captures the true error of the prediction, and thus is not only useful as a weight for the residuals in the system's optimization problems, but also as a means to detect harmful statistical outliers without choosing a manual threshold. Experiments show that our method provides competitive performance to the state of the art in 6DoF object pose estimation, and at a real-time speed. Our code, pre-trained models, and keypoint labels are available https://github.com/rpng/suo_slam.