 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCredit-assigned Policy Gradient for Early Stage Retrieval in Two-stage Ranking
May 25, 2026Large-scale search, recommendation, and retrieval-augmented generation (RAG) systems typically employ a two-stage architecture: an early-stage ranker (ESR) generates a candidate set, which is subsequently re-ranked by a late-stage ranker (LSR). While there are many reinforcement learning (RL) methods for training the LSR, end-to-end training of the ESR has proven challenging. In particular, naive application of "vanilla" policy gradient (V-PG) is not scalable for candidate-set sizes relevant for practical use due to exploding variance. This issue arises because V-PG propagates the gradient to the joint probability of the candidate sets, ignoring the contribution of each specific item in the candidate set to the reward. To mitigate this issue, we propose a novel "credit-assigned" policy gradient (CA-PG), which computes gradients with respect to the probability that the target item is chosen in any candidate set, i.e. marginalizing over all candidate sets that contain it. Our theoretical analysis reveals that CA-PG significantly reduces the variance of V-PG by marginalizing over the specific composition of the candidate set, while preserving the ability to learn the correct ranking of items under a reasonably aligned LSR policy. Experiments on both synthetic and real-world data demonstrate that CA-PG improves the convergence speed and training stability for ESRs utilizing the canonical Plackett-Luce model, especially when the candidate-set size is large.
Prompt Optimization with Logged Bandit Data
Apr 03, 2025We study how to use naturally available user feedback, such as clicks, to optimize large language model (LLM) pipelines for generating personalized sentences using prompts. Naive approaches, which estimate the policy gradient in the prompt space, suffer either from variance caused by the large action space of prompts or bias caused by inaccurate reward predictions. To circumvent these challenges, we propose a novel kernel-based off-policy gradient method, which estimates the policy gradient by leveraging similarity among generated sentences, substantially reducing variance while suppressing the bias. Empirical results on our newly established suite of benchmarks demonstrate the effectiveness of the proposed approach in generating personalized descriptions for movie recommendations, particularly when the number of candidate prompts is large.
Policy Design for Two-sided Platforms with Participation Dynamics
Feb 03, 2025



In two-sided platforms (e.g., video streaming or e-commerce), viewers and providers engage in interactive dynamics, where an increased provider population results in higher viewer utility and the increase of viewer population results in higher provider utility. Despite the importance of such "population effects" on long-term platform health, recommendation policies do not generally take the participation dynamics into account. This paper thus studies the dynamics and policy design on two-sided platforms under the population effects for the first time. Our control- and game-theoretic findings warn against the use of myopic-greedy policy and shed light on the importance of provider-side considerations (i.e., effectively distributing exposure among provider groups) to improve social welfare via population growth. We also present a simple algorithm to optimize long-term objectives by considering the population effects, and demonstrate its effectiveness in synthetic and real-data experiments.
Effective Off-Policy Evaluation and Learning in Contextual Combinatorial Bandits
Aug 20, 2024



We explore off-policy evaluation and learning (OPE/L) in contextual combinatorial bandits (CCB), where a policy selects a subset in the action space. For example, it might choose a set of furniture pieces (a bed and a drawer) from available items (bed, drawer, chair, etc.) for interior design sales. This setting is widespread in fields such as recommender systems and healthcare, yet OPE/L of CCB remains unexplored in the relevant literature. Typical OPE/L methods such as regression and importance sampling can be applied to the CCB problem, however, they face significant challenges due to high bias or variance, exacerbated by the exponential growth in the number of available subsets. To address these challenges, we introduce a concept of factored action space, which allows us to decompose each subset into binary indicators. This formulation allows us to distinguish between the ''main effect'' derived from the main actions, and the ''residual effect'', originating from the supplemental actions, facilitating more effective OPE. Specifically, our estimator, called OPCB, leverages an importance sampling-based approach to unbiasedly estimate the main effect, while employing regression-based approach to deal with the residual effect with low variance. OPCB achieves substantial variance reduction compared to conventional importance sampling methods and bias reduction relative to regression methods under certain conditions, as illustrated in our theoretical analysis. Experiments demonstrate OPCB's superior performance over typical methods in both OPE and OPL.
Off-Policy Evaluation of Slate Bandit Policies via Optimizing Abstraction
Feb 03, 2024



We study off-policy evaluation (OPE) in the problem of slate contextual bandits where a policy selects multi-dimensional actions known as slates. This problem is widespread in recommender systems, search engines, marketing, to medical applications, however, the typical Inverse Propensity Scoring (IPS) estimator suffers from substantial variance due to large action spaces, making effective OPE a significant challenge. The PseudoInverse (PI) estimator has been introduced to mitigate the variance issue by assuming linearity in the reward function, but this can result in significant bias as this assumption is hard-to-verify from observed data and is often substantially violated. To address the limitations of previous estimators, we develop a novel estimator for OPE of slate bandits, called Latent IPS (LIPS), which defines importance weights in a low-dimensional slate abstraction space where we optimize slate abstractions to minimize the bias and variance of LIPS in a data-driven way. By doing so, LIPS can substantially reduce the variance of IPS without imposing restrictive assumptions on the reward function structure like linearity. Through empirical evaluation, we demonstrate that LIPS substantially outperforms existing estimators, particularly in scenarios with non-linear rewards and large slate spaces.
Towards Assessing and Benchmarking Risk-Return Tradeoff of Off-Policy Evaluation
Dec 04, 2023



Off-Policy Evaluation (OPE) aims to assess the effectiveness of counterfactual policies using only offline logged data and is often used to identify the top-k promising policies for deployment in online A/B tests. Existing evaluation metrics for OPE estimators primarily focus on the "accuracy" of OPE or that of downstream policy selection, neglecting risk-return tradeoff in the subsequent online policy deployment. To address this issue, we draw inspiration from portfolio evaluation in finance and develop a new metric, called SharpeRatio@k, which measures the risk-return tradeoff of policy portfolios formed by an OPE estimator under varying online evaluation budgets (k). We validate our metric in two example scenarios, demonstrating its ability to effectively distinguish between low-risk and high-risk estimators and to accurately identify the most efficient estimator. This efficient estimator is characterized by its capability to form the most advantageous policy portfolios, maximizing returns while minimizing risks during online deployment, a nuance that existing metrics typically overlook. To facilitate a quick, accurate, and consistent evaluation of OPE via SharpeRatio@k, we have also integrated this metric into an open-source software, SCOPE-RL. Employing SharpeRatio@k and SCOPE-RL, we conduct comprehensive benchmarking experiments on various estimators and RL tasks, focusing on their risk-return tradeoff. These experiments offer several interesting directions and suggestions for future OPE research.
SCOPE-RL: A Python Library for Offline Reinforcement Learning and Off-Policy Evaluation
Dec 04, 2023



This paper introduces SCOPE-RL, a comprehensive open-source Python software designed for offline reinforcement learning (offline RL), off-policy evaluation (OPE), and selection (OPS). Unlike most existing libraries that focus solely on either policy learning or evaluation, SCOPE-RL seamlessly integrates these two key aspects, facilitating flexible and complete implementations of both offline RL and OPE processes. SCOPE-RL put particular emphasis on its OPE modules, offering a range of OPE estimators and robust evaluation-of-OPE protocols. This approach enables more in-depth and reliable OPE compared to other packages. For instance, SCOPE-RL enhances OPE by estimating the entire reward distribution under a policy rather than its mere point-wise expected value. Additionally, SCOPE-RL provides a more thorough evaluation-of-OPE by presenting the risk-return tradeoff in OPE results, extending beyond mere accuracy evaluations in existing OPE literature. SCOPE-RL is designed with user accessibility in mind. Its user-friendly APIs, comprehensive documentation, and a variety of easy-to-follow examples assist researchers and practitioners in efficiently implementing and experimenting with various offline RL methods and OPE estimators, tailored to their specific problem contexts. The documentation of SCOPE-RL is available at https://scope-rl.readthedocs.io/en/latest/.
Off-Policy Evaluation of Ranking Policies under Diverse User Behavior
Jun 26, 2023Ranking interfaces are everywhere in online platforms. There is thus an ever growing interest in their Off-Policy Evaluation (OPE), aiming towards an accurate performance evaluation of ranking policies using logged data. A de-facto approach for OPE is Inverse Propensity Scoring (IPS), which provides an unbiased and consistent value estimate. However, it becomes extremely inaccurate in the ranking setup due to its high variance under large action spaces. To deal with this problem, previous studies assume either independent or cascade user behavior, resulting in some ranking versions of IPS. While these estimators are somewhat effective in reducing the variance, all existing estimators apply a single universal assumption to every user, causing excessive bias and variance. Therefore, this work explores a far more general formulation where user behavior is diverse and can vary depending on the user context. We show that the resulting estimator, which we call Adaptive IPS (AIPS), can be unbiased under any complex user behavior. Moreover, AIPS achieves the minimum variance among all unbiased estimators based on IPS. We further develop a procedure to identify the appropriate user behavior model to minimize the mean squared error (MSE) of AIPS in a data-driven fashion. Extensive experiments demonstrate that the empirical accuracy improvement can be significant, enabling effective OPE of ranking systems even under diverse user behavior.
Policy-Adaptive Estimator Selection for Off-Policy Evaluation
Nov 25, 2022



Off-policy evaluation (OPE) aims to accurately evaluate the performance of counterfactual policies using only offline logged data. Although many estimators have been developed, there is no single estimator that dominates the others, because the estimators' accuracy can vary greatly depending on a given OPE task such as the evaluation policy, number of actions, and noise level. Thus, the data-driven estimator selection problem is becoming increasingly important and can have a significant impact on the accuracy of OPE. However, identifying the most accurate estimator using only the logged data is quite challenging because the ground-truth estimation accuracy of estimators is generally unavailable. This paper studies this challenging problem of estimator selection for OPE for the first time. In particular, we enable an estimator selection that is adaptive to a given OPE task, by appropriately subsampling available logged data and constructing pseudo policies useful for the underlying estimator selection task. Comprehensive experiments on both synthetic and real-world company data demonstrate that the proposed procedure substantially improves the estimator selection compared to a non-adaptive heuristic.
Future-Dependent Value-Based Off-Policy Evaluation in POMDPs
Jul 26, 2022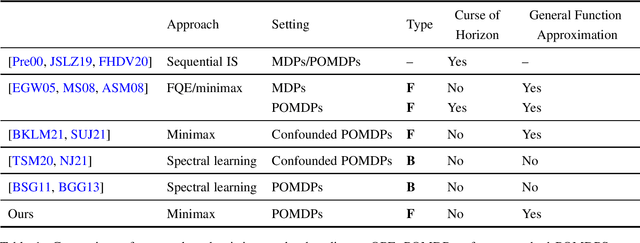
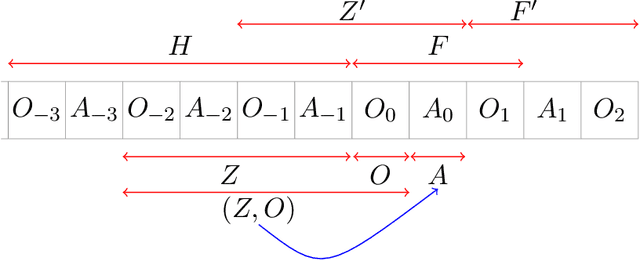
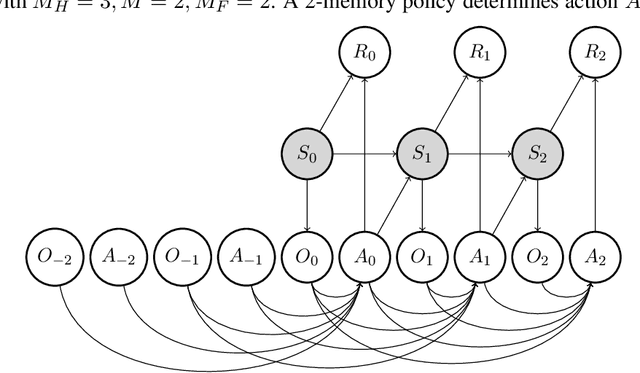
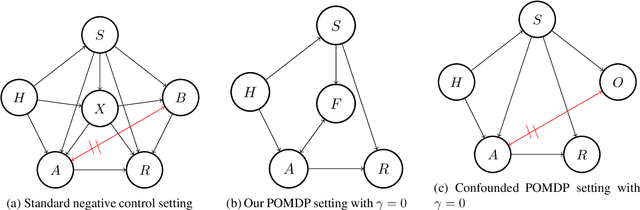
We study off-policy evaluation (OPE) for partially observable MDPs (POMDPs) with general function approximation. Existing methods such as sequential importance sampling estimators and fitted-Q evaluation suffer from the curse of horizon in POMDPs. To circumvent this problem, we develop a novel model-free OPE method by introducing future-dependent value functions that take future proxies as inputs. Future-dependent value functions play similar roles as classical value functions in fully-observable MDPs. We derive a new Bellman equation for future-dependent value functions as conditional moment equations that use history proxies as instrumental variables. We further propose a minimax learning method to learn future-dependent value functions using the new Bellman equation. We obtain the PAC result, which implies our OPE estimator is consistent as long as futures and histories contain sufficient information about latent states, and the Bellman completeness. Finally, we extend our methods to learning of dynamics and establish the connection between our approach and the well-known spectral learning methods in POMDPs.