 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnd-to-End Chatbot Evaluation with Adaptive Reasoning and Uncertainty Filtering
Mar 11, 2026Large language models (LLMs) combined with retrieval augmented generation have enabled the deployment of domain-specific chatbots, but these systems remain prone to generating unsupported or incorrect answers. Reliable evaluation is therefore critical, yet manual review is costly and existing frameworks often depend on curated test sets and static metrics, limiting scalability. We propose an end-to-end automatic evaluator designed to substantially reduce human effort. Our system generates Q\&A pairs directly from the underlying knowledge base, uses LLMs to judge chatbot responses against reference answers, and applies confidence-based filtering to highlight uncertain cases. Applied to a Vietnamese news dataset, the evaluator achieves high agreement with human judgments while significantly lowering review overhead. The framework is modular and language-agnostic, making it readily adaptable to diverse domains. This work introduces a practical, scalable solution for evaluating chatbots with minimal reliance on manual intervention.
FPSRS: A Fusion Approach for Paper Submission Recommendation System
May 12, 2022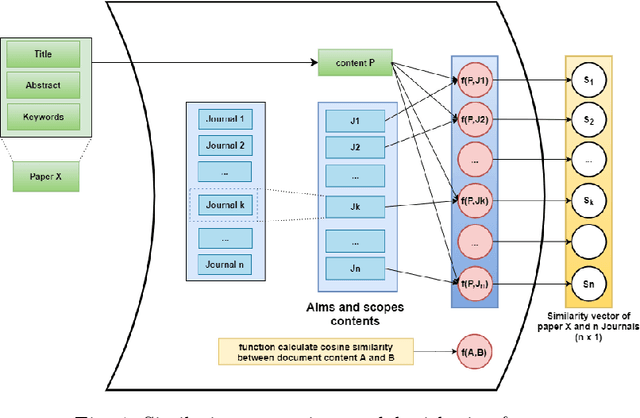
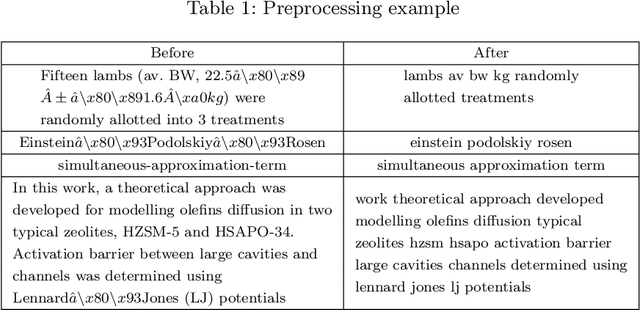

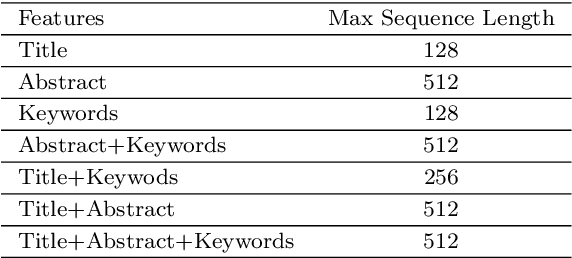
Recommender systems have been increasingly popular in entertainment and consumption and are evident in academics, especially for applications that suggest submitting scientific articles to scientists. However, because of the various acceptance rates, impact factors, and rankings in different publishers, searching for a proper venue or journal to submit a scientific work usually takes a lot of time and effort. In this paper, we aim to present two newer approaches extended from our paper [13] presented at the conference IAE/AIE 2021 by employing RNN structures besides using Conv1D. In addition, we also introduce a new method, namely DistilBertAims, using DistillBert for two cases of uppercase and lower-case words to vectorize features such as Title, Abstract, and Keywords, and then use Conv1d to perform feature extraction. Furthermore, we propose a new calculation method for similarity score for Aim & Scope with other features; this helps keep the weights of similarity score calculation continuously updated and then continue to fit more data. The experimental results show that the second approach could obtain a better performance, which is 62.46% and 12.44% higher than the best of the previous study [13] in terms of the Top 1 accuracy.