 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Interplay Between Interpolation and Aggregation in Regression: Optimal Sample Complexity
May 28, 2026This work investigates theoretically the interplay between interpolation and aggregation in regression. We establish that the $γ$-graph dimension characterizes learnability for a broad class of natural aggregation procedures. Furthermore, we prove that an extremely simple aggregation procedure, combining three interpolating hypotheses via the median, is optimal among all these aggregation procedures, and is strictly more powerful than proper learning. Finally, we show that some hypothesis classes are learnable only by aggregating infinitely many hypotheses or by using non-interpolating aggregation rules (which may predict outside the range of their inputs), and any finite interpolating aggregation fails to achieve even trivial performance.
Agnostic Language Identification and Generation
Jan 30, 2026Recent works on language identification and generation have established tight statistical rates at which these tasks can be achieved. These works typically operate under a strong realizability assumption: that the input data is drawn from an unknown distribution necessarily supported on some language in a given collection. In this work, we relax this assumption of realizability entirely, and impose no restrictions on the distribution of the input data. We propose objectives to study both language identification and generation in this more general "agnostic" setup. Across both problems, we obtain novel interesting characterizations and nearly tight rates.
The Optimal Sample Complexity of Linear Contracts
Jan 04, 2026In this paper, we settle the problem of learning optimal linear contracts from data in the offline setting, where agent types are drawn from an unknown distribution and the principal's goal is to design a contract that maximizes her expected utility. Specifically, our analysis shows that the simple Empirical Utility Maximization (EUM) algorithm yields an $\varepsilon$-approximation of the optimal linear contract with probability at least $1-δ$, using just $O(\ln(1/δ) / \varepsilon^2)$ samples. This result improves upon previously known bounds and matches a lower bound from Duetting et al. [2025] up to constant factors, thereby proving its optimality. Our analysis uses a chaining argument, where the key insight is to leverage a simple structural property of linear contracts: their expected reward is non-decreasing. This property, which holds even though the utility function itself is non-monotone and discontinuous, enables the construction of fine-grained nets required for the chaining argument, which in turn yields the optimal sample complexity. Furthermore, our proof establishes the stronger guarantee of uniform convergence: the empirical utility of every linear contract is a $\varepsilon$-approximation of its true expectation with probability at least $1-δ$, using the same optimal $O(\ln(1/δ) / \varepsilon^2)$ sample complexity.
Uniform Mean Estimation for Heavy-Tailed Distributions via Median-of-Means
Jun 18, 2025The Median of Means (MoM) is a mean estimator that has gained popularity in the context of heavy-tailed data. In this work, we analyze its performance in the task of simultaneously estimating the mean of each function in a class $\mathcal{F}$ when the data distribution possesses only the first $p$ moments for $p \in (1,2]$. We prove a new sample complexity bound using a novel symmetrization technique that may be of independent interest. Additionally, we present applications of our result to $k$-means clustering with unbounded inputs and linear regression with general losses, improving upon existing works.
Revisiting Agnostic Boosting
Mar 12, 2025Boosting is a key method in statistical learning, allowing for converting weak learners into strong ones. While well studied in the realizable case, the statistical properties of weak-to-strong learning remains less understood in the agnostic setting, where there are no assumptions on the distribution of the labels. In this work, we propose a new agnostic boosting algorithm with substantially improved sample complexity compared to prior works under very general assumptions. Our approach is based on a reduction to the realizable case, followed by a margin-based filtering step to select high-quality hypotheses. We conjecture that the error rate achieved by our proposed method is optimal up to logarithmic factors.
Improved Margin Generalization Bounds for Voting Classifiers
Feb 23, 2025In this paper we establish a new margin-based generalization bound for voting classifiers, refining existing results and yielding tighter generalization guarantees for widely used boosting algorithms such as AdaBoost (Freund and Schapire, 1997). Furthermore, the new margin-based generalization bound enables the derivation of an optimal weak-to-strong learner: a Majority-of-3 large-margin classifiers with an expected error matching the theoretical lower bound. This result provides a more natural alternative to the Majority-of-5 algorithm by (H\o gsgaard et al. 2024) , and matches the Majority-of-3 result by (Aden-Ali et al. 2024) for the realizable prediction model.
On Agnostic PAC Learning in the Small Error Regime
Feb 13, 2025

Binary classification in the classic PAC model exhibits a curious phenomenon: Empirical Risk Minimization (ERM) learners are suboptimal in the realizable case yet optimal in the agnostic case. Roughly speaking, this owes itself to the fact that non-realizable distributions $\mathcal{D}$ are simply more difficult to learn than realizable distributions -- even when one discounts a learner's error by $\mathrm{err}(h^*_{\mathcal{D}})$, the error of the best hypothesis in $\mathcal{H}$ for $\mathcal{D}$. Thus, optimal agnostic learners are permitted to incur excess error on (easier-to-learn) distributions $\mathcal{D}$ for which $\tau = \mathrm{err}(h^*_{\mathcal{D}})$ is small. Recent work of Hanneke, Larsen, and Zhivotovskiy (FOCS `24) addresses this shortcoming by including $\tau$ itself as a parameter in the agnostic error term. In this more fine-grained model, they demonstrate tightness of the error lower bound $\tau + \Omega \left(\sqrt{\frac{\tau (d + \log(1 / \delta))}{m}} + \frac{d + \log(1 / \delta)}{m} \right)$ in a regime where $\tau > d/m$, and leave open the question of whether there may be a higher lower bound when $\tau \approx d/m$, with $d$ denoting $\mathrm{VC}(\mathcal{H})$. In this work, we resolve this question by exhibiting a learner which achieves error $c \cdot \tau + O \left(\sqrt{\frac{\tau (d + \log(1 / \delta))}{m}} + \frac{d + \log(1 / \delta)}{m} \right)$ for a constant $c \leq 2.1$, thus matching the lower bound when $\tau \approx d/m$. Further, our learner is computationally efficient and is based upon careful aggregations of ERM classifiers, making progress on two other questions of Hanneke, Larsen, and Zhivotovskiy (FOCS `24). We leave open the interesting question of whether our approach can be refined to lower the constant from 2.1 to 1, which would completely settle the complexity of agnostic learning.
Efficient Optimal PAC Learning
Feb 05, 2025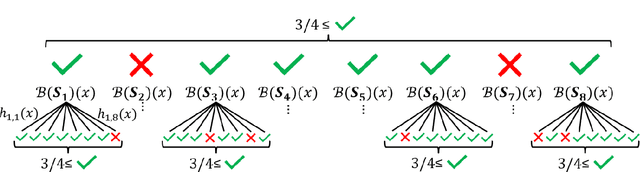
Recent advances in the binary classification setting by Hanneke [2016b] and Larsen [2023] have resulted in optimal PAC learners. These learners leverage, respectively, a clever deterministic subsampling scheme and the classic heuristic of bagging Breiman [1996]. Both optimal PAC learners use, as a subroutine, the natural algorithm of empirical risk minimization. Consequently, the computational cost of these optimal PAC learners is tied to that of the empirical risk minimizer algorithm. In this work, we seek to provide an alternative perspective on the computational cost imposed by the link to the empirical risk minimizer algorithm. To this end, we show the existence of an optimal PAC learner, which offers a different tradeoff in terms of the computational cost induced by the empirical risk minimizer.
Understanding Aggregations of Proper Learners in Multiclass Classification
Oct 30, 2024Multiclass learnability is known to exhibit a properness barrier: there are learnable classes which cannot be learned by any proper learner. Binary classification faces no such barrier for learnability, but a similar one for optimal learning, which can in general only be achieved by improper learners. Fortunately, recent advances in binary classification have demonstrated that this requirement can be satisfied using aggregations of proper learners, some of which are strikingly simple. This raises a natural question: to what extent can simple aggregations of proper learners overcome the properness barrier in multiclass classification? We give a positive answer to this question for classes which have finite Graph dimension, $d_G$. Namely, we demonstrate that the optimal binary learners of Hanneke, Larsen, and Aden-Ali et al. (appropriately generalized to the multiclass setting) achieve sample complexity $O\left(\frac{d_G + \ln(1 / \delta)}{\epsilon}\right)$. This forms a strict improvement upon the sample complexity of ERM. We complement this with a lower bound demonstrating that for certain classes of Graph dimension $d_G$, majorities of ERM learners require $\Omega \left( \frac{d_G + \ln(1 / \delta)}{\epsilon}\right)$ samples. Furthermore, we show that a single ERM requires $\Omega \left(\frac{d_G \ln(1 / \epsilon) + \ln(1 / \delta)}{\epsilon}\right)$ samples on such classes, exceeding the lower bound of Daniely et al. (2015) by a factor of $\ln(1 / \epsilon)$. For multiclass learning in full generality -- i.e., for classes of finite DS dimension but possibly infinite Graph dimension -- we give a strong refutation to these learning strategies, by exhibiting a learnable class which cannot be learned to constant error by any aggregation of a finite number of proper learners.
The Many Faces of Optimal Weak-to-Strong Learning
Aug 30, 2024Boosting is an extremely successful idea, allowing one to combine multiple low accuracy classifiers into a much more accurate voting classifier. In this work, we present a new and surprisingly simple Boosting algorithm that obtains a provably optimal sample complexity. Sample optimal Boosting algorithms have only recently been developed, and our new algorithm has the fastest runtime among all such algorithms and is the simplest to describe: Partition your training data into 5 disjoint pieces of equal size, run AdaBoost on each, and combine the resulting classifiers via a majority vote. In addition to this theoretical contribution, we also perform the first empirical comparison of the proposed sample optimal Boosting algorithms. Our pilot empirical study suggests that our new algorithm might outperform previous algorithms on large data sets.