 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpeCache: Speculative Key-Value Caching for Efficient Generation of LLMs
Mar 20, 2025



Transformer-based large language models (LLMs) have already achieved remarkable results on long-text tasks, but the limited GPU memory (VRAM) resources struggle to accommodate the linearly growing demand for key-value (KV) cache as the sequence length increases, which has become a bottleneck for the application of LLMs on long sequences. Existing KV cache compression methods include eviction, merging, or quantization of the KV cache to reduce its size. However, compression results in irreversible information forgetting, potentially affecting the accuracy of subsequent decoding. In this paper, we propose SpeCache, which takes full advantage of the large and easily expandable CPU memory to offload the complete KV cache, and dynamically fetches KV pairs back in each decoding step based on their importance measured by low-bit KV cache copy in VRAM. To avoid inference latency caused by CPU-GPU communication, SpeCache speculatively predicts the KV pairs that the next token might attend to, allowing us to prefetch them before the next decoding step which enables parallelization of prefetching and computation. Experiments on LongBench and Needle-in-a-Haystack benchmarks verify that SpeCache effectively reduces VRAM usage while avoiding information forgetting for long sequences without re-training, even with a 10x high KV cache compression ratio.
Mixture of Lookup Experts
Mar 20, 2025



Mixture-of-Experts (MoE) activates only a subset of experts during inference, allowing the model to maintain low inference FLOPs and latency even as the parameter count scales up. However, since MoE dynamically selects the experts, all the experts need to be loaded into VRAM. Their large parameter size still limits deployment, and offloading, which load experts into VRAM only when needed, significantly increase inference latency. To address this, we propose Mixture of Lookup Experts (MoLE), a new MoE architecture that is efficient in both communication and VRAM usage. In MoLE, the experts are Feed-Forward Networks (FFNs) during training, taking the output of the embedding layer as input. Before inference, these experts can be re-parameterized as lookup tables (LUTs) that retrieves expert outputs based on input ids, and offloaded to storage devices. Therefore, we do not need to perform expert computations during inference. Instead, we directly retrieve the expert's computation results based on input ids and load them into VRAM, and thus the resulting communication overhead is negligible. Experiments show that, with the same FLOPs and VRAM usage, MoLE achieves inference speeds comparable to dense models and significantly faster than MoE with experts offloading, while maintaining performance on par with MoE.
Token Compensator: Altering Inference Cost of Vision Transformer without Re-Tuning
Aug 13, 2024



Token compression expedites the training and inference of Vision Transformers (ViTs) by reducing the number of the redundant tokens, e.g., pruning inattentive tokens or merging similar tokens. However, when applied to downstream tasks, these approaches suffer from significant performance drop when the compression degrees are mismatched between training and inference stages, which limits the application of token compression on off-the-shelf trained models. In this paper, we propose a model arithmetic framework to decouple the compression degrees between the two stages. In advance, we additionally perform a fast parameter-efficient self-distillation stage on the pre-trained models to obtain a small plugin, called Token Compensator (ToCom), which describes the gap between models across different compression degrees. During inference, ToCom can be directly inserted into any downstream off-the-shelf models with any mismatched training and inference compression degrees to acquire universal performance improvements without further training. Experiments on over 20 downstream tasks demonstrate the effectiveness of our framework. On CIFAR100, fine-grained visual classification, and VTAB-1k, ToCom can yield up to a maximum improvement of 2.3%, 1.5%, and 2.0% in the average performance of DeiT-B, respectively. Code: https://github.com/JieShibo/ToCom
Memory-Space Visual Prompting for Efficient Vision-Language Fine-Tuning
May 09, 2024



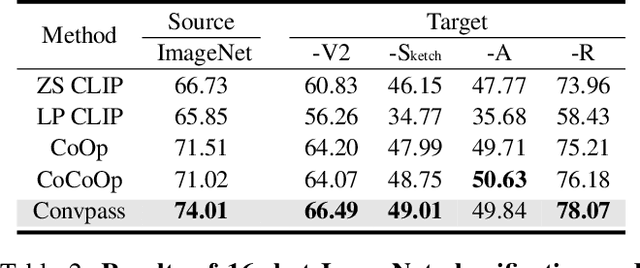
Current solutions for efficiently constructing large vision-language (VL) models follow a two-step paradigm: projecting the output of pre-trained vision encoders to the input space of pre-trained language models as visual prompts; and then transferring the models to downstream VL tasks via end-to-end parameter-efficient fine-tuning (PEFT). However, this paradigm still exhibits inefficiency since it significantly increases the input length of the language models. In this paper, in contrast to integrating visual prompts into inputs, we regard visual prompts as additional knowledge that facilitates language models in addressing tasks associated with visual information. Motivated by the finding that Feed-Forward Network (FFN) of language models acts as "key-value memory", we introduce a novel approach termed memory-space visual prompting (MemVP), wherein visual prompts are concatenated with the weights of FFN for visual knowledge injection. Experimental results across various VL tasks and language models reveal that MemVP significantly reduces the training time and inference latency of the finetuned VL models and surpasses the performance of previous PEFT methods. Code: https://github.com/JieShibo/MemVP
Revisiting the Parameter Efficiency of Adapters from the Perspective of Precision Redundancy
Jul 31, 2023



Current state-of-the-art results in computer vision depend in part on fine-tuning large pre-trained vision models. However, with the exponential growth of model sizes, the conventional full fine-tuning, which needs to store a individual network copy for each tasks, leads to increasingly huge storage and transmission overhead. Adapter-based Parameter-Efficient Tuning (PET) methods address this challenge by tuning lightweight adapters inserted into the frozen pre-trained models. In this paper, we investigate how to make adapters even more efficient, reaching a new minimum size required to store a task-specific fine-tuned network. Inspired by the observation that the parameters of adapters converge at flat local minima, we find that adapters are resistant to noise in parameter space, which means they are also resistant to low numerical precision. To train low-precision adapters, we propose a computational-efficient quantization method which minimizes the quantization error. Through extensive experiments, we find that low-precision adapters exhibit minimal performance degradation, and even 1-bit precision is sufficient for adapters. The experimental results demonstrate that 1-bit adapters outperform all other PET methods on both the VTAB-1K benchmark and few-shot FGVC tasks, while requiring the smallest storage size. Our findings show, for the first time, the significant potential of quantization techniques in PET, providing a general solution to enhance the parameter efficiency of adapter-based PET methods. Code: https://github.com/JieShibo/PETL-ViT
Detachedly Learn a Classifier for Class-Incremental Learning
Feb 23, 2023



In continual learning, model needs to continually learn a feature extractor and classifier on a sequence of tasks. This paper focuses on how to learn a classifier based on a pretrained feature extractor under continual learning setting. We present an probabilistic analysis that the failure of vanilla experience replay (ER) comes from unnecessary re-learning of previous tasks and incompetence to distinguish current task from the previous ones, which is the cause of knowledge degradation and prediction bias. To overcome these weaknesses, we propose a novel replay strategy task-aware experience replay. It rebalances the replay loss and detaches classifier weight for the old tasks from the update process, by which the previous knowledge is kept intact and the overfitting on episodic memory is alleviated. Experimental results show our method outperforms current state-of-the-art methods.
FacT: Factor-Tuning for Lightweight Adaptation on Vision Transformer
Dec 06, 2022Recent work has explored the potential to adapt a pre-trained vision transformer (ViT) by updating only a few parameters so as to improve storage efficiency, called parameter-efficient transfer learning (PETL). Current PETL methods have shown that by tuning only 0.5% of the parameters, ViT can be adapted to downstream tasks with even better performance than full fine-tuning. In this paper, we aim to further promote the efficiency of PETL to meet the extreme storage constraint in real-world applications. To this end, we propose a tensorization-decomposition framework to store the weight increments, in which the weights of each ViT are tensorized into a single 3D tensor, and their increments are then decomposed into lightweight factors. In the fine-tuning process, only the factors need to be updated and stored, termed Factor-Tuning (FacT). On VTAB-1K benchmark, our method performs on par with NOAH, the state-of-the-art PETL method, while being 5x more parameter-efficient. We also present a tiny version that only uses 8K (0.01% of ViT's parameters) trainable parameters but outperforms full fine-tuning and many other PETL methods such as VPT and BitFit. In few-shot settings, FacT also beats all PETL baselines using the fewest parameters, demonstrating its strong capability in the low-data regime.
Convolutional Bypasses Are Better Vision Transformer Adapters
Jul 18, 2022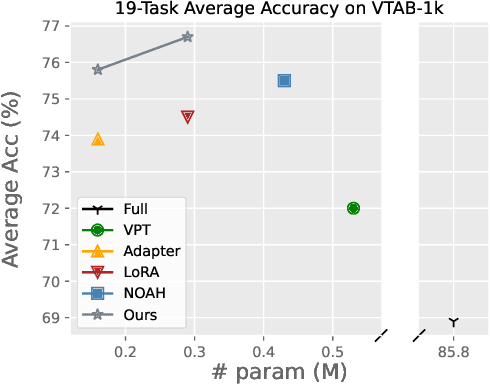
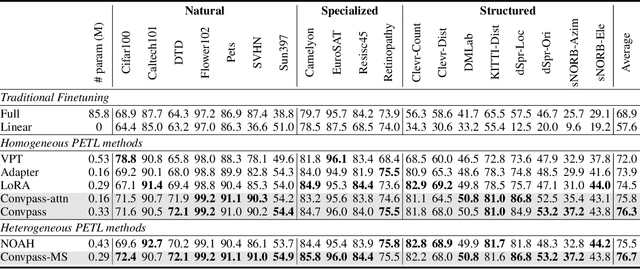
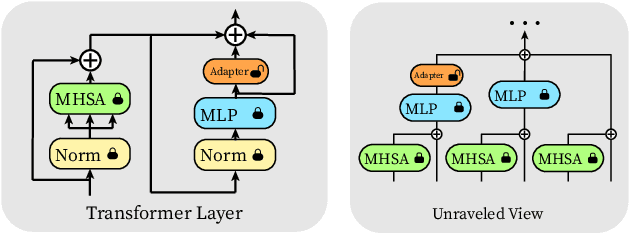
The pretrain-then-finetune paradigm has been widely adopted in computer vision. But as the size of Vision Transformer (ViT) grows exponentially, the full finetuning becomes prohibitive in view of the heavier storage overhead. Motivated by parameter-efficient transfer learning (PETL) on language transformers, recent studies attempt to insert lightweight adaptation modules (e.g., adapter layers or prompt tokens) to pretrained ViT and only finetune these modules while the pretrained weights are frozen. However, these modules were originally proposed to finetune language models. Although ported well to ViT, their design lacks prior knowledge for visual tasks. In this paper, we propose to construct Convolutional Bypasses (Convpass) in ViT as adaptation modules, introducing only a small amount (less than 0.5% of model parameters) of trainable parameters to adapt the large ViT. Different from other PETL methods, Convpass benefits from the hard-coded inductive bias of convolutional layers and thus is more suitable for visual tasks, especially in the low-data regime. Experimental results on VTAB-1k benchmark and few-shot learning datasets demonstrate that Convpass outperforms current language-oriented adaptation modules, demonstrating the necessity to tailor vision-oriented adaptation modules for vision models.
Bypassing Logits Bias in Online Class-Incremental Learning with a Generative Framework
May 19, 2022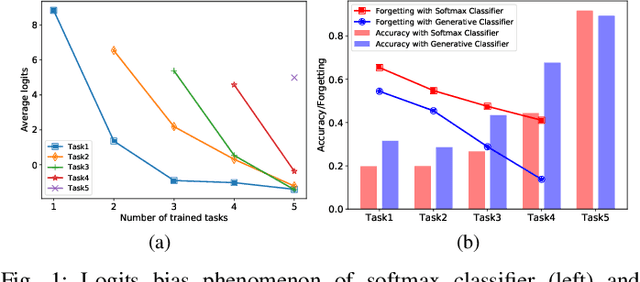
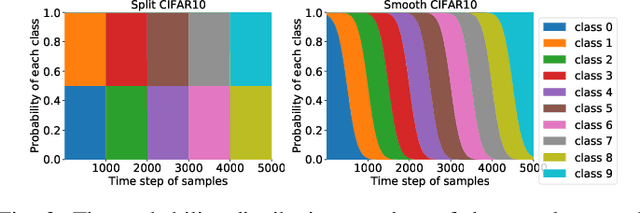
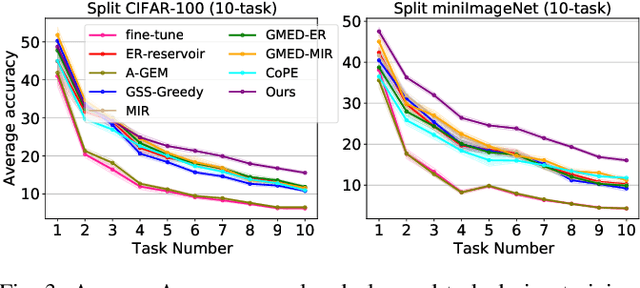
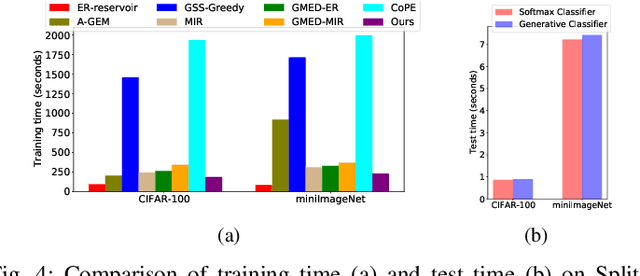
Continual learning requires the model to maintain the learned knowledge while learning from a non-i.i.d data stream continually. Due to the single-pass training setting, online continual learning is very challenging, but it is closer to the real-world scenarios where quick adaptation to new data is appealing. In this paper, we focus on online class-incremental learning setting in which new classes emerge over time. Almost all existing methods are replay-based with a softmax classifier. However, the inherent logits bias problem in the softmax classifier is a main cause of catastrophic forgetting while existing solutions are not applicable for online settings. To bypass this problem, we abandon the softmax classifier and propose a novel generative framework based on the feature space. In our framework, a generative classifier which utilizes replay memory is used for inference, and the training objective is a pair-based metric learning loss which is proven theoretically to optimize the feature space in a generative way. In order to improve the ability to learn new data, we further propose a hybrid of generative and discriminative loss to train the model. Extensive experiments on several benchmarks, including newly introduced task-free datasets, show that our method beats a series of state-of-the-art replay-based methods with discriminative classifiers, and reduces catastrophic forgetting consistently with a remarkable margin.
Alleviating Representational Shift for Continual Fine-tuning
Apr 22, 2022
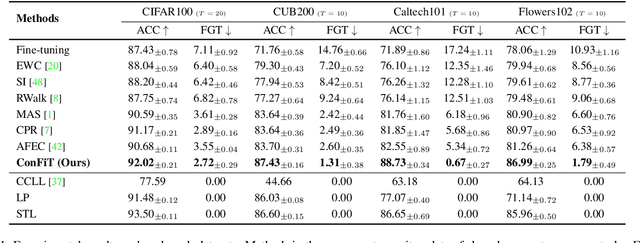
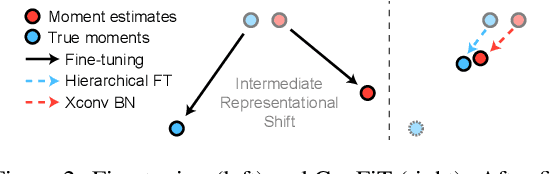
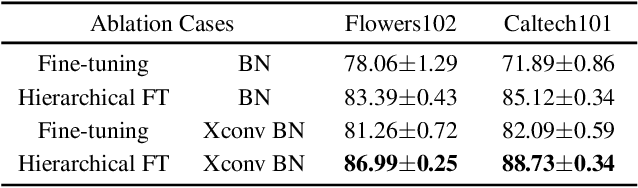
We study a practical setting of continual learning: fine-tuning on a pre-trained model continually. Previous work has found that, when training on new tasks, the features (penultimate layer representations) of previous data will change, called representational shift. Besides the shift of features, we reveal that the intermediate layers' representational shift (IRS) also matters since it disrupts batch normalization, which is another crucial cause of catastrophic forgetting. Motivated by this, we propose ConFiT, a fine-tuning method incorporating two components, cross-convolution batch normalization (Xconv BN) and hierarchical fine-tuning. Xconv BN maintains pre-convolution running means instead of post-convolution, and recovers post-convolution ones before testing, which corrects the inaccurate estimates of means under IRS. Hierarchical fine-tuning leverages a multi-stage strategy to fine-tune the pre-trained network, preventing massive changes in Conv layers and thus alleviating IRS. Experimental results on four datasets show that our method remarkably outperforms several state-of-the-art methods with lower storage overhead.