 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
pyKT: A Python Library to Benchmark Deep Learning based Knowledge Tracing Models
Jun 23, 2022




Knowledge tracing (KT) is the task of using students' historical learning interaction data to model their knowledge mastery over time so as to make predictions on their future interaction performance. Recently, remarkable progress has been made of using various deep learning techniques to solve the KT problem. However, the success behind deep learning based knowledge tracing (DLKT) approaches is still left somewhat mysterious and proper measurement and analysis of these DLKT approaches remain a challenge. First, data preprocessing procedures in existing works are often private and/or custom, which limits experimental standardization. Furthermore, existing DLKT studies often differ in terms of the evaluation protocol and are far away real-world educational contexts. To address these problems, we introduce a comprehensive python based benchmark platform, \textsc{pyKT}, to guarantee valid comparisons across DLKT methods via thorough evaluations. The \textsc{pyKT} library consists of a standardized set of integrated data preprocessing procedures on 7 popular datasets across different domains, and 10 frequently compared DLKT model implementations for transparent experiments. Results from our fine-grained and rigorous empirical KT studies yield a set of observations and suggestions for effective DLKT, e.g., wrong evaluation setting may cause label leakage that generally leads to performance inflation; and the improvement of many DLKT approaches is minimal compared to the very first DLKT model proposed by Piech et al. \cite{piech2015deep}. We have open sourced \textsc{pyKT} and our experimental results at \url{https://pykt.org/}. We welcome contributions from other research groups and practitioners.
Time-Aware Ancient Chinese Text Translation and Inference
Jul 07, 2021
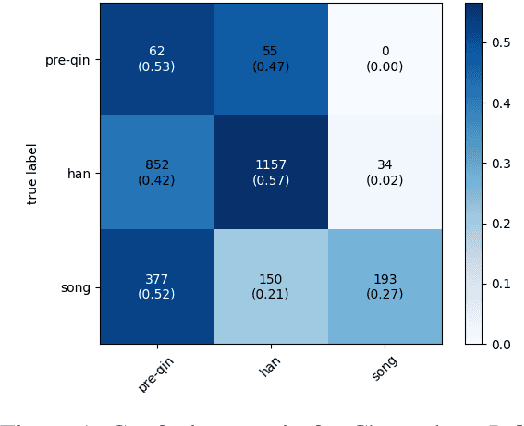
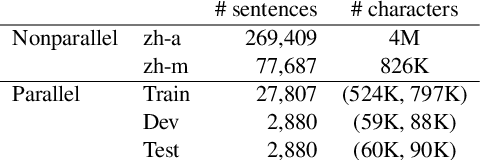
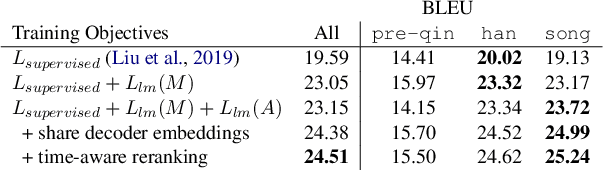
In this paper, we aim to address the challenges surrounding the translation of ancient Chinese text: (1) The linguistic gap due to the difference in eras results in translations that are poor in quality, and (2) most translations are missing the contextual information that is often very crucial to understanding the text. To this end, we improve upon past translation techniques by proposing the following: We reframe the task as a multi-label prediction task where the model predicts both the translation and its particular era. We observe that this helps to bridge the linguistic gap as chronological context is also used as auxiliary information. % As a natural step of generalization, we pivot on the modern Chinese translations to generate multilingual outputs. %We show experimentally the efficacy of our framework in producing quality translation outputs and also validate our framework on a collected task-specific parallel corpus. We validate our framework on a parallel corpus annotated with chronology information and show experimentally its efficacy in producing quality translation outputs. We release both the code and the data https://github.com/orina1123/time-aware-ancient-text-translation for future research.
Rainbow-link: Beam-Alignment-Free and Grant-Free mmW Multiple Access using True-Time-Delay Array
Aug 21, 2021
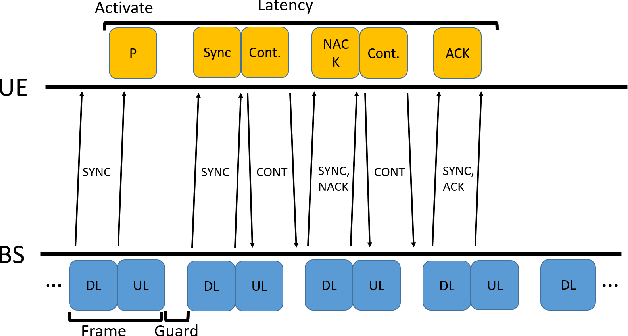
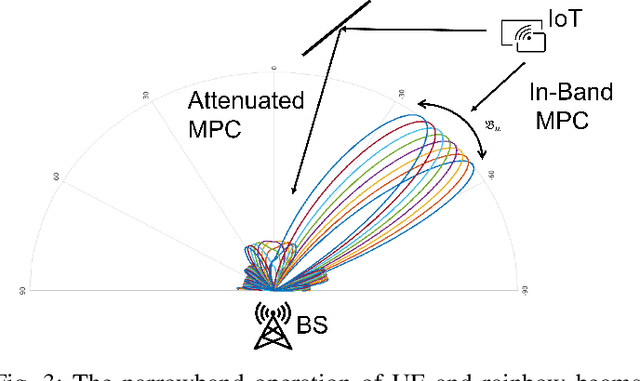
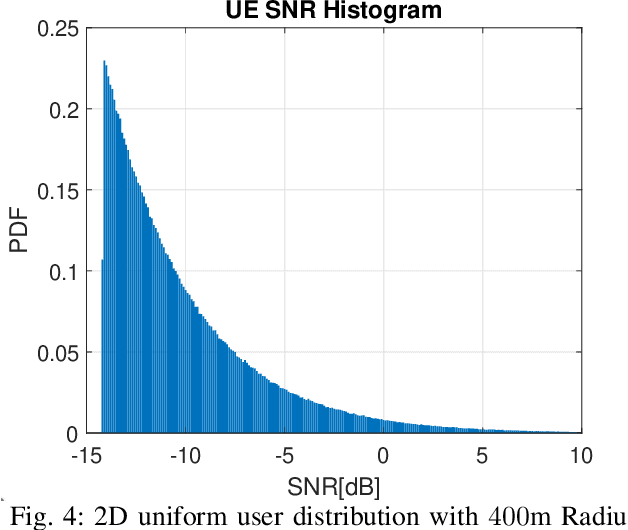
In this paper we propose a novel millimeter wave (mmW) multiple access method that exploits unique frequency dependent beamforming capabilities of True Time Delay (TTD) array architecture. The proposed protocol combines a contentionbased grant-free access and orthogonal frequency-division multiple access (OFDMA) scheme for uplink machine type communications. By exploiting abundant time-frequency resource blocks in mmW spectrum, we design a simple protocol that can achieve low collision rate and high network reliability for short packets and sporadic transmissions. We analyze the impact of various system parameters on system performance during synchronization and contention period. We exploit unique advantages of frequency dependent beamforming, referred as rainbow beam, to eliminate beam training overhead and analyze its impact on rates, latency, and coverage. The proposed system and protocol can flexibly accommodate different low latency applications with moderate rate requirements for a very large number of narrowband single antenna devices. By harnessing abundant resources in mmW spectrum and beamforming gain of TTD arrays rainbow link based system can simultaneously satisfy ultra-reliability and massive multiple access requirements.
Predicting extreme events from data using deep machine learning: when and where
Mar 31, 2022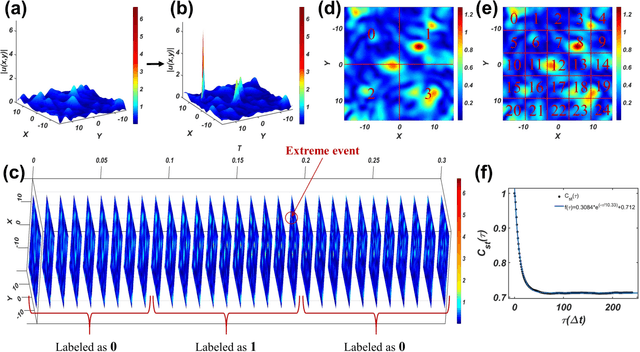
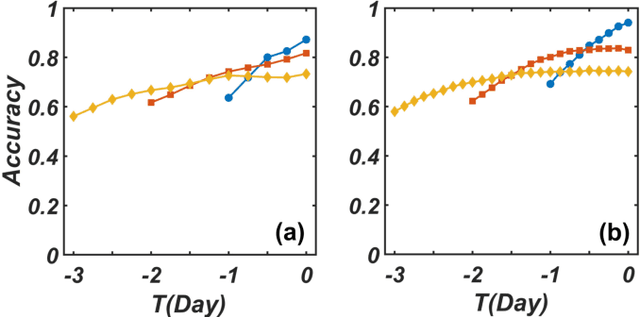
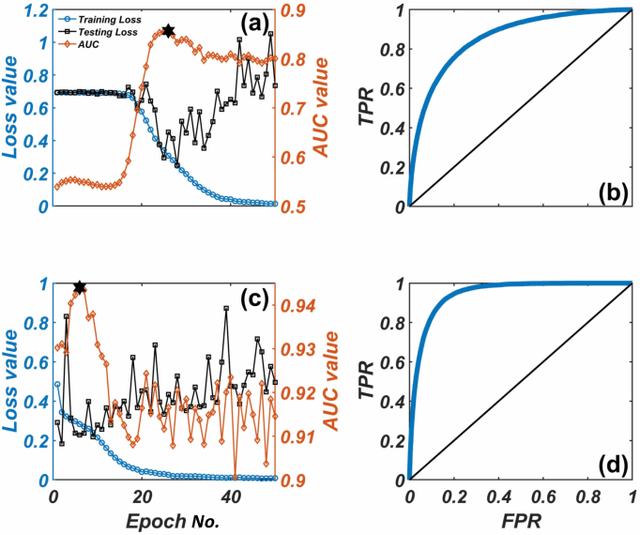
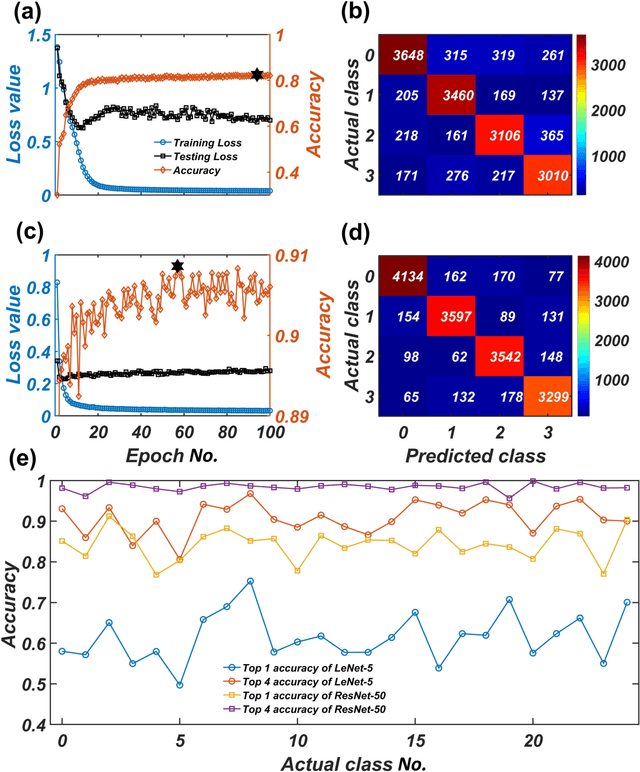
We develop a deep convolutional neural network (DCNN) based framework for model-free prediction of the occurrence of extreme events both in time ("when") and in space ("where") in nonlinear physical systems of spatial dimension two. The measurements or data are a set of two-dimensional snapshots or images. For a desired time horizon of prediction, a proper labeling scheme can be designated to enable successful training of the DCNN and subsequent prediction of extreme events in time. Given that an extreme event has been predicted to occur within the time horizon, a space-based labeling scheme can be applied to predict, within certain resolution, the location at which the event will occur. We use synthetic data from the 2D complex Ginzburg-Landau equation and empirical wind speed data of the North Atlantic ocean to demonstrate and validate our machine-learning based prediction framework. The trade-offs among the prediction horizon, spatial resolution, and accuracy are illustrated, and the detrimental effect of spatially biased occurrence of extreme event on prediction accuracy is discussed. The deep learning framework is viable for predicting extreme events in the real world.
Filtered Noise Shaping for Time Domain Room Impulse Response Estimation From Reverberant Speech
Jul 15, 2021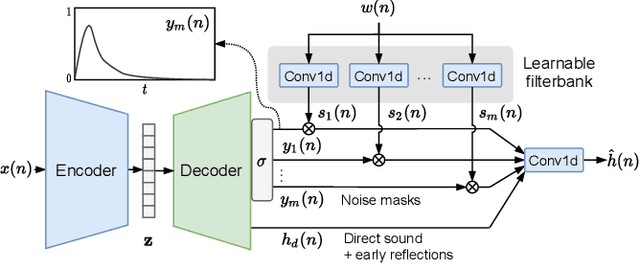
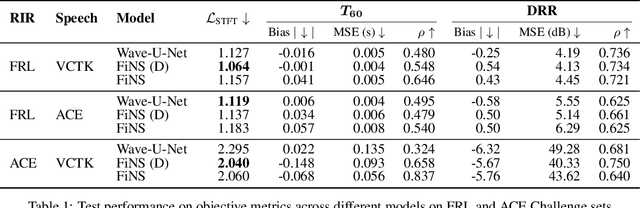
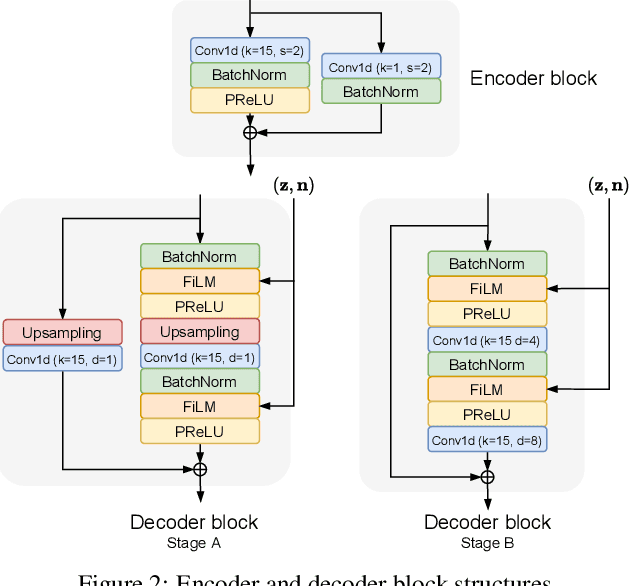
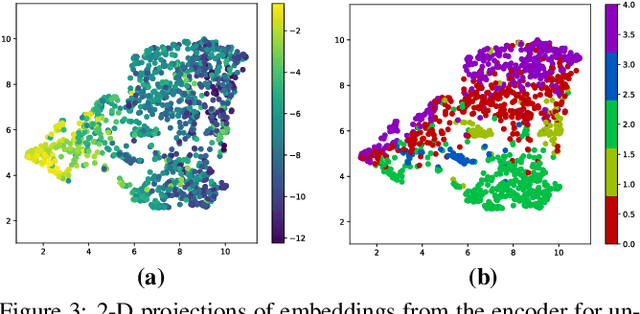
Deep learning approaches have emerged that aim to transform an audio signal so that it sounds as if it was recorded in the same room as a reference recording, with applications both in audio post-production and augmented reality. In this work, we propose FiNS, a Filtered Noise Shaping network that directly estimates the time domain room impulse response (RIR) from reverberant speech. Our domain-inspired architecture features a time domain encoder and a filtered noise shaping decoder that models the RIR as a summation of decaying filtered noise signals, along with direct sound and early reflection components. Previous methods for acoustic matching utilize either large models to transform audio to match the target room or predict parameters for algorithmic reverberators. Instead, blind estimation of the RIR enables efficient and realistic transformation with a single convolution. An evaluation demonstrates our model not only synthesizes RIRs that match parameters of the target room, such as the $T_{60}$ and DRR, but also more accurately reproduces perceptual characteristics of the target room, as shown in a listening test when compared to deep learning baselines.
Transformer Lesion Tracker
Jun 13, 2022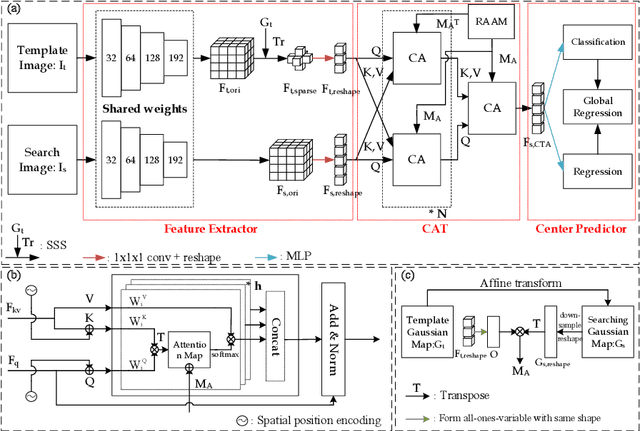
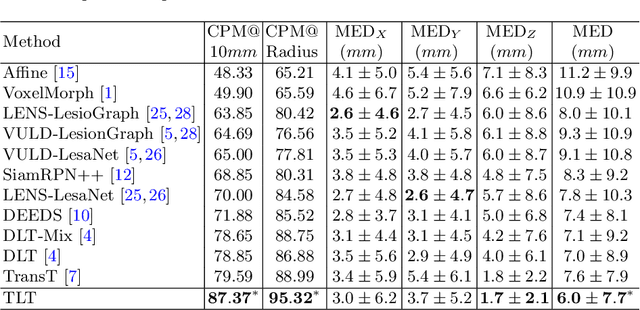
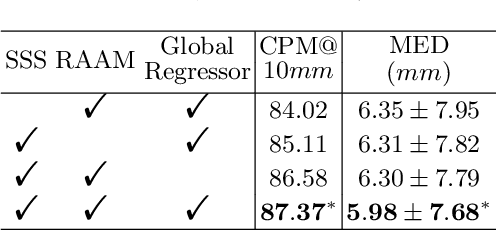

Evaluating lesion progression and treatment response via longitudinal lesion tracking plays a critical role in clinical practice. Automated approaches for this task are motivated by prohibitive labor costs and time consumption when lesion matching is done manually. Previous methods typically lack the integration of local and global information. In this work, we propose a transformer-based approach, termed Transformer Lesion Tracker (TLT). Specifically, we design a Cross Attention-based Transformer (CAT) to capture and combine both global and local information to enhance feature extraction. We also develop a Registration-based Anatomical Attention Module (RAAM) to introduce anatomical information to CAT so that it can focus on useful feature knowledge. A Sparse Selection Strategy (SSS) is presented for selecting features and reducing memory footprint in Transformer training. In addition, we use a global regression to further improve model performance. We conduct experiments on a public dataset to show the superiority of our method and find that our model performance has improved the average Euclidean center error by at least 14.3% (6mm vs. 7mm) compared with the state-of-the-art (SOTA). Code is available at https://github.com/TangWen920812/TLT.
Reconstructing Speech from Real-Time Articulatory MRI Using Neural Vocoders
Apr 23, 2021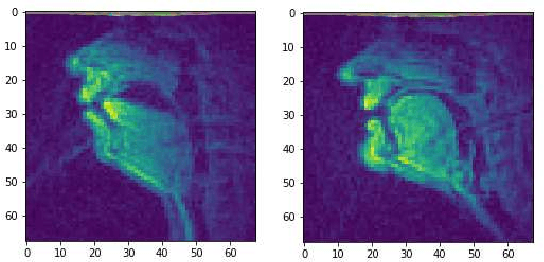
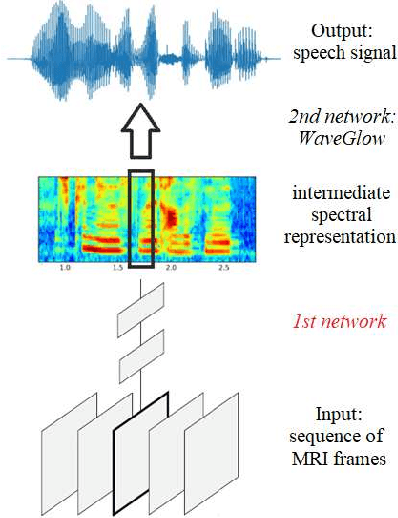
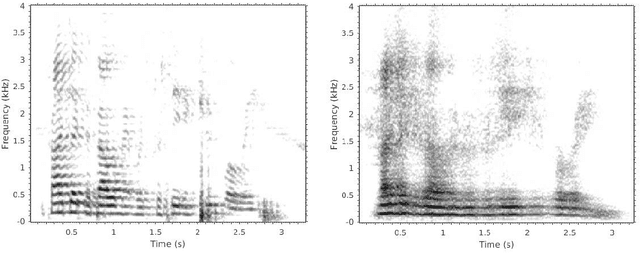

Several approaches exist for the recording of articulatory movements, such as eletromagnetic and permanent magnetic articulagraphy, ultrasound tongue imaging and surface electromyography. Although magnetic resonance imaging (MRI) is more costly than the above approaches, the recent developments in this area now allow the recording of real-time MRI videos of the articulators with an acceptable resolution. Here, we experiment with the reconstruction of the speech signal from a real-time MRI recording using deep neural networks. Instead of estimating speech directly, our networks are trained to output a spectral vector, from which we reconstruct the speech signal using the WaveGlow neural vocoder. We compare the performance of three deep neural architectures for the estimation task, combining convolutional (CNN) and recurrence-based (LSTM) neural layers. Besides the mean absolute error (MAE) of our networks, we also evaluate our models by comparing the speech signals obtained using several objective speech quality metrics like the mean cepstral distortion (MCD), Short-Time Objective Intelligibility (STOI), Perceptual Evaluation of Speech Quality (PESQ) and Signal-to-Distortion Ratio (SDR). The results indicate that our approach can successfully reconstruct the gross spectral shape, but more improvements are needed to reproduce the fine spectral details.
Cooperative Retriever and Ranker in Deep Recommenders
Jun 28, 2022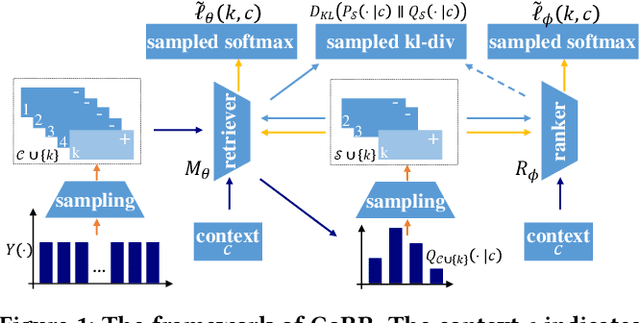

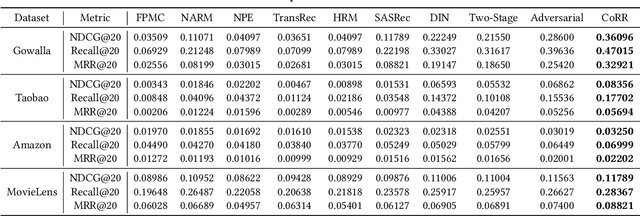
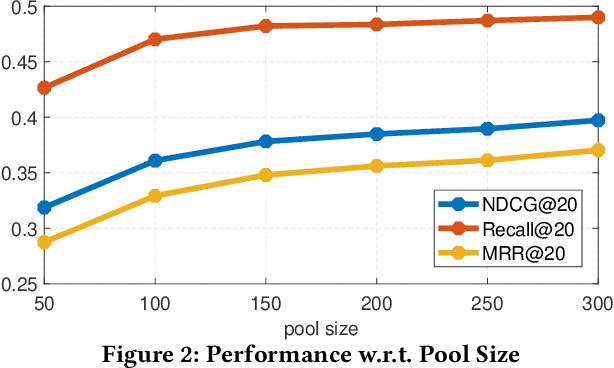
Deep recommender systems jointly leverage the retrieval and ranking operations to generate the recommendation result. The retriever targets selecting a small set of relevant candidates from the entire items with high efficiency; while the ranker, usually more precise but time-consuming, is supposed to identify the best items out of the retrieved candidates with high precision. However, the retriever and ranker are usually trained in poorly-cooperative ways, leading to limited recommendation performances when working as an entirety. In this work, we propose a novel DRS training framework CoRR(short for Cooperative Retriever and Ranker), where the retriever and ranker can be mutually reinforced. On one hand, the retriever is learned from recommendation data and the ranker via knowledge distillation; knowing that the ranker is more precise, the knowledge distillation may provide extra weak-supervision signals for the improvement of retrieval quality. On the other hand, the ranker is trained by learning to discriminate the truth positive items from hard negative candidates sampled from the retriever. With the iteration going on, the ranker may become more precise, which in return gives rise to informative training signals for the retriever; meanwhile, with the improvement of retriever, harder negative candidates can be sampled, which contributes to a higher discriminative capability of the ranker. To facilitate the effective conduct of CoRR, an asymptotic-unbiased approximation of KL divergence is introduced for the knowledge distillation over sampled items; besides, a scalable and adaptive strategy is developed to efficiently sample from the retriever. Comprehensive experimental studies are performed over four large-scale benchmark datasets, where CoRR improves the overall recommendation quality resulting from the cooperation between retriever and ranker.
Black-Box Test-Time Shape REFINEment for Single View 3D Reconstruction
Aug 23, 2021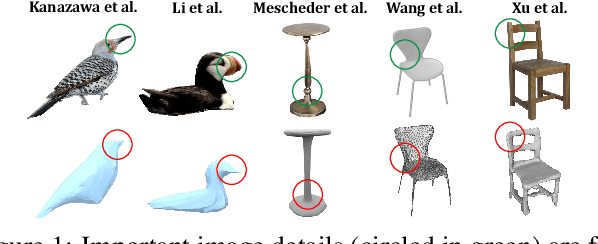
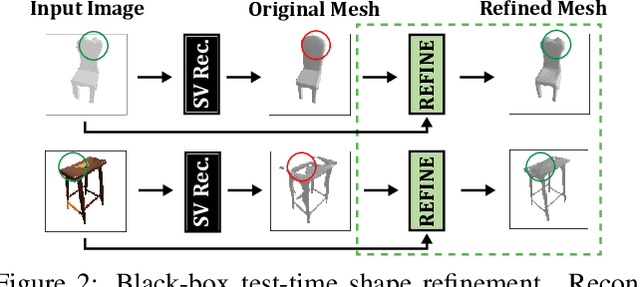
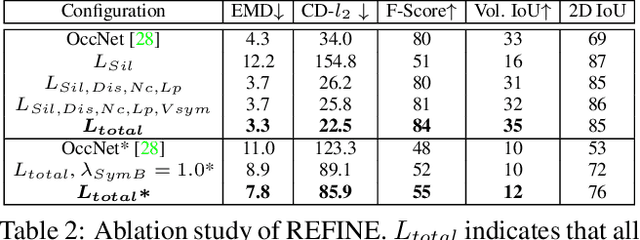
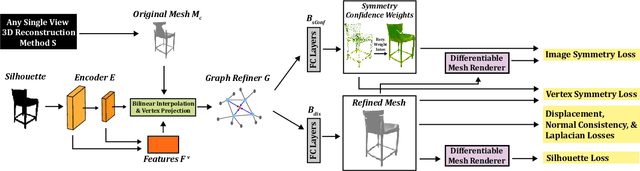
Much recent progress has been made in reconstructing the 3D shape of an object from an image of it, i.e. single view 3D reconstruction. However, it has been suggested that current methods simply adopt a "nearest-neighbor" strategy, instead of genuinely understanding the shape behind the input image. In this paper, we rigorously show that for many state of the art methods, this issue manifests as (1) inconsistencies between coarse reconstructions and input images, and (2) inability to generalize across domains. We thus propose REFINE, a postprocessing mesh refinement step that can be easily integrated into the pipeline of any black-box method in the literature. At test time, REFINE optimizes a network per mesh instance, to encourage consistency between the mesh and the given object view. This, along with a novel combination of regularizing losses, reduces the domain gap and achieves state of the art performance. We believe that this novel paradigm is an important step towards robust, accurate reconstructions, remaining relevant as new reconstruction networks are introduced.
CLAP: Learning Audio Concepts From Natural Language Supervision
Jun 09, 2022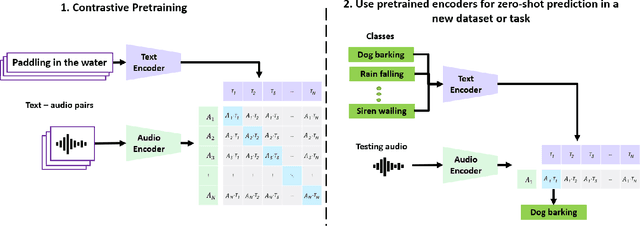
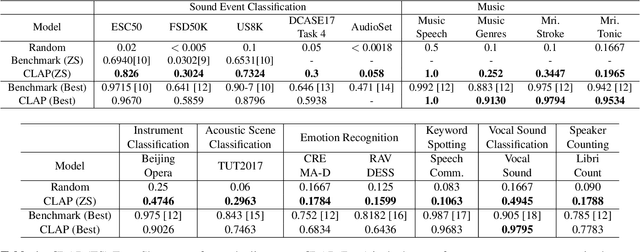
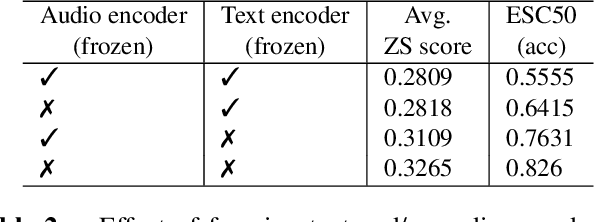
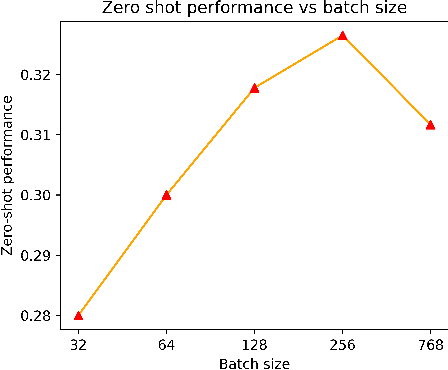
Mainstream Audio Analytics models are trained to learn under the paradigm of one class label to many recordings focusing on one task. Learning under such restricted supervision limits the flexibility of models because they require labeled audio for training and can only predict the predefined categories. Instead, we propose to learn audio concepts from natural language supervision. We call our approach Contrastive Language-Audio Pretraining (CLAP), which learns to connect language and audio by using two encoders and a contrastive learning to bring audio and text descriptions into a joint multimodal space. We trained CLAP with 128k audio and text pairs and evaluated it on 16 downstream tasks across 8 domains, such as Sound Event Classification, Music tasks, and Speech-related tasks. Although CLAP was trained with significantly less pairs than similar computer vision models, it establishes SoTA for Zero-Shot performance. Additionally, we evaluated CLAP in a supervised learning setup and achieve SoTA in 5 tasks. Hence, CLAP's Zero-Shot capability removes the need of training with class labels, enables flexible class prediction at inference time, and generalizes to multiple downstream tasks.