 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAugmenters at SemEval-2023 Task 1: Enhancing CLIP in Handling Compositionality and Ambiguity for Zero-Shot Visual WSD through Prompt Augmentation and Text-To-Image Diffusion
Jul 09, 2023



This paper describes our zero-shot approaches for the Visual Word Sense Disambiguation (VWSD) Task in English. Our preliminary study shows that the simple approach of matching candidate images with the phrase using CLIP suffers from the many-to-many nature of image-text pairs. We find that the CLIP text encoder may have limited abilities in capturing the compositionality in natural language. Conversely, the descriptive focus of the phrase varies from instance to instance. We address these issues in our two systems, Augment-CLIP and Stable Diffusion Sampling (SD Sampling). Augment-CLIP augments the text prompt by generating sentences that contain the context phrase with the help of large language models (LLMs). We further explore CLIP models in other languages, as the an ambiguous word may be translated into an unambiguous one in the other language. SD Sampling uses text-to-image Stable Diffusion to generate multiple images from the given phrase, increasing the likelihood that a subset of images match the one that paired with the text.
Time-Aware Ancient Chinese Text Translation and Inference
Jul 07, 2021
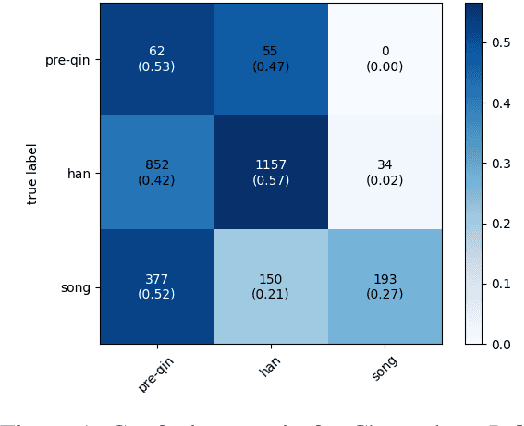
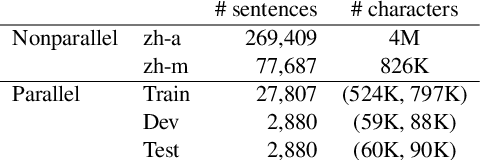
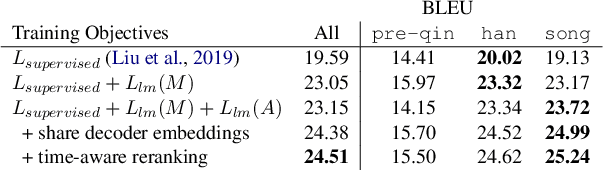
In this paper, we aim to address the challenges surrounding the translation of ancient Chinese text: (1) The linguistic gap due to the difference in eras results in translations that are poor in quality, and (2) most translations are missing the contextual information that is often very crucial to understanding the text. To this end, we improve upon past translation techniques by proposing the following: We reframe the task as a multi-label prediction task where the model predicts both the translation and its particular era. We observe that this helps to bridge the linguistic gap as chronological context is also used as auxiliary information. % As a natural step of generalization, we pivot on the modern Chinese translations to generate multilingual outputs. %We show experimentally the efficacy of our framework in producing quality translation outputs and also validate our framework on a collected task-specific parallel corpus. We validate our framework on a parallel corpus annotated with chronology information and show experimentally its efficacy in producing quality translation outputs. We release both the code and the data https://github.com/orina1123/time-aware-ancient-text-translation for future research.
Numeral Understanding in Financial Tweets for Fine-grained Crowd-based Forecasting
Sep 14, 2018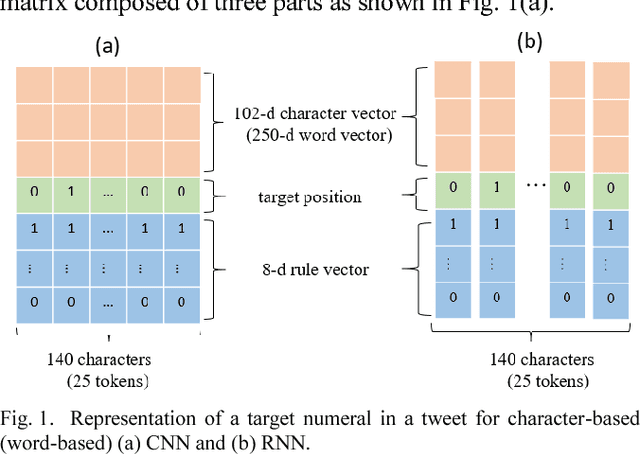
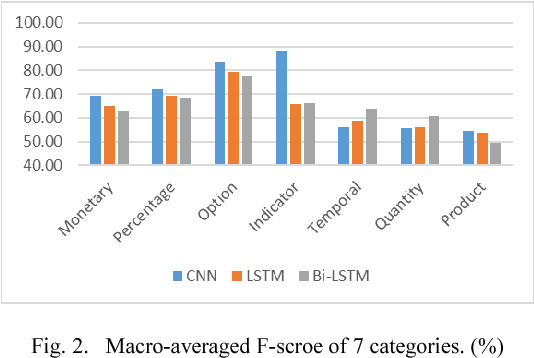
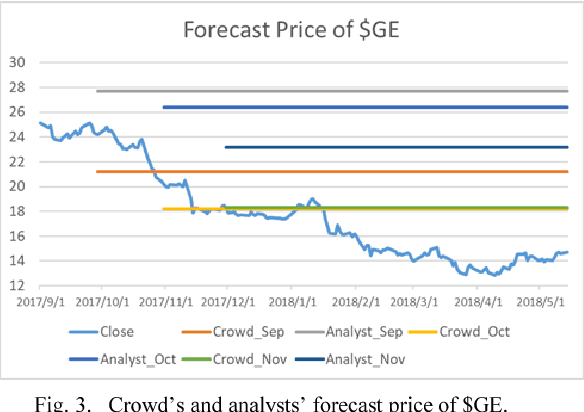
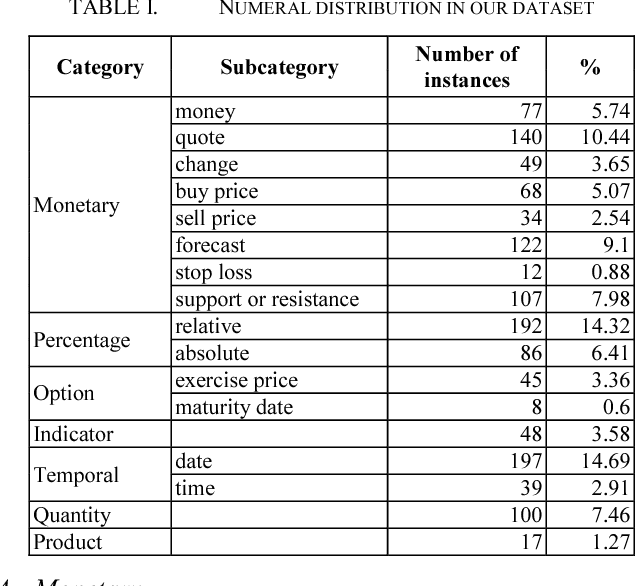
Numerals that contain much information in financial documents are crucial for financial decision making. They play different roles in financial analysis processes. This paper is aimed at understanding the meanings of numerals in financial tweets for fine-grained crowd-based forecasting. We propose a taxonomy that classifies the numerals in financial tweets into 7 categories, and further extend some of these categories into several subcategories. Neural network-based models with word and character-level encoders are proposed for 7-way classification and 17-way classification. We perform backtest to confirm the effectiveness of the numeric opinions made by the crowd. This work is the first attempt to understand numerals in financial social media data, and we provide the first comparison of fine-grained opinion of individual investors and analysts based on their forecast price. The numeral corpus used in our experiments, called FinNum 1.0 , is available for research purposes.