 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Towards Synthetic Multivariate Time Series Generation for Flare Forecasting
May 16, 2021
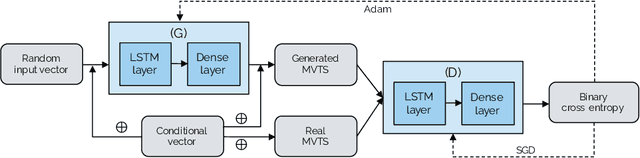
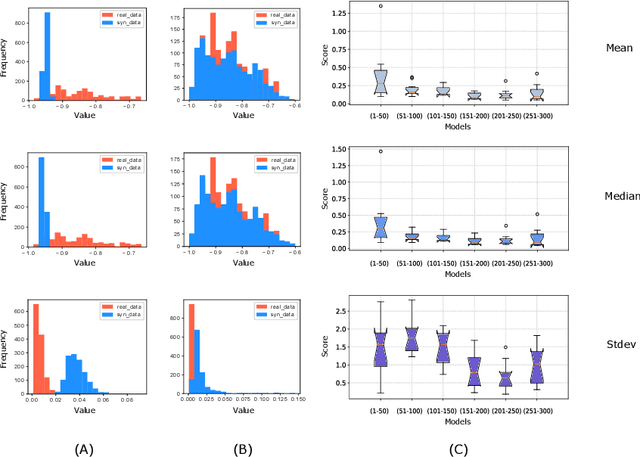
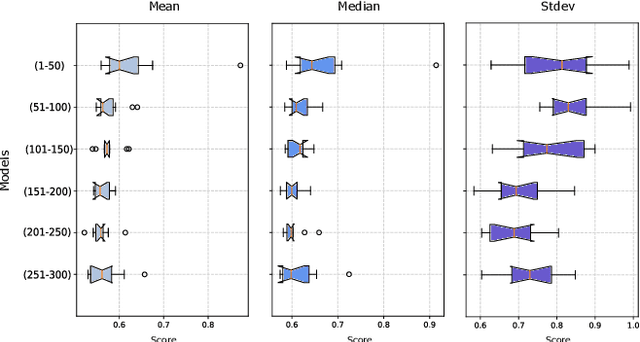
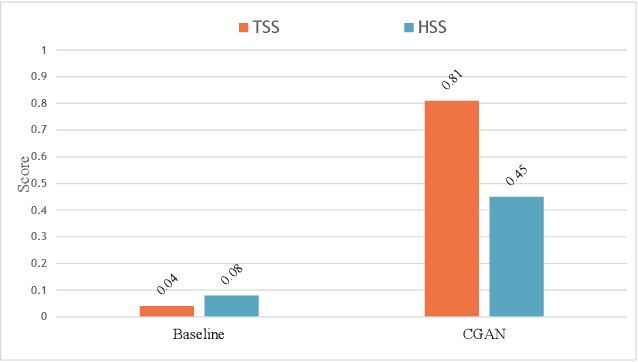
One of the limiting factors in training data-driven, rare-event prediction algorithms is the scarcity of the events of interest resulting in an extreme imbalance in the data. There have been many methods introduced in the literature for overcoming this issue; simple data manipulation through undersampling and oversampling, utilizing cost-sensitive learning algorithms, or by generating synthetic data points following the distribution of the existing data. While synthetic data generation has recently received a great deal of attention, there are real challenges involved in doing so for high-dimensional data such as multivariate time series. In this study, we explore the usefulness of the conditional generative adversarial network (CGAN) as a means to perform data-informed oversampling in order to balance a large dataset of multivariate time series. We utilize a flare forecasting benchmark dataset, named SWAN-SF, and design two verification methods to both quantitatively and qualitatively evaluate the similarity between the generated minority and the ground-truth samples. We further assess the quality of the generated samples by training a classical, supervised machine learning algorithm on synthetic data, and testing the trained model on the unseen, real data. The results show that the classifier trained on the data augmented with the synthetic multivariate time series achieves a significant improvement compared with the case where no augmentation is used. The popular flare forecasting evaluation metrics, TSS and HSS, report 20-fold and 5-fold improvements, respectively, indicating the remarkable statistical similarities, and the usefulness of CGAN-based data generation for complicated tasks such as flare forecasting.
Ordered Subgraph Aggregation Networks
Jun 22, 2022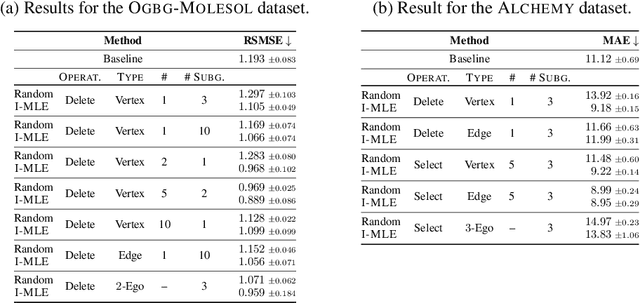
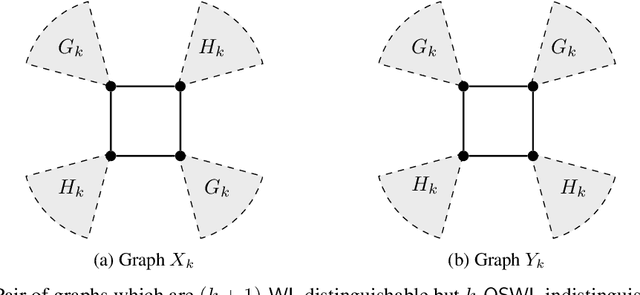
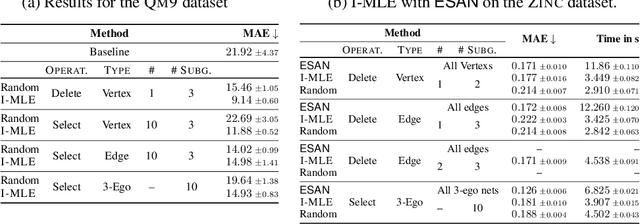

Numerous subgraph-enhanced graph neural networks (GNNs) have emerged recently, provably boosting the expressive power of standard (message-passing) GNNs. However, there is a limited understanding of how these approaches relate to each other and to the Weisfeiler--Leman hierarchy. Moreover, current approaches either use all subgraphs of a given size, sample them uniformly at random, or use hand-crafted heuristics instead of learning to select subgraphs in a data-driven manner. Here, we offer a unified way to study such architectures by introducing a theoretical framework and extending the known expressivity results of subgraph-enhanced GNNs. Concretely, we show that increasing subgraph size always increases the expressive power and develop a better understanding of their limitations by relating them to the established $k\text{-}\mathsf{WL}$ hierarchy. In addition, we explore different approaches for learning to sample subgraphs using recent methods for backpropagating through complex discrete probability distributions. Empirically, we study the predictive performance of different subgraph-enhanced GNNs, showing that our data-driven architectures increase prediction accuracy on standard benchmark datasets compared to non-data-driven subgraph-enhanced graph neural networks while reducing computation time.
A view of mini-batch SGD via generating functions: conditions of convergence, phase transitions, benefit from negative momenta
Jun 22, 2022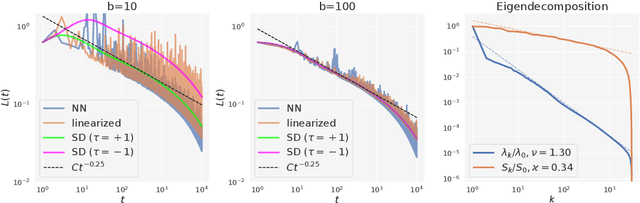
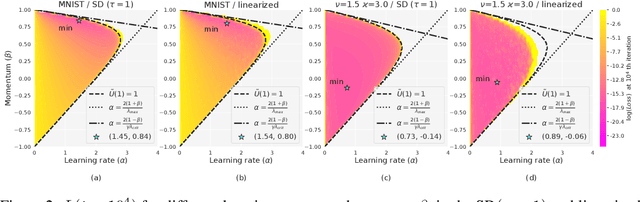
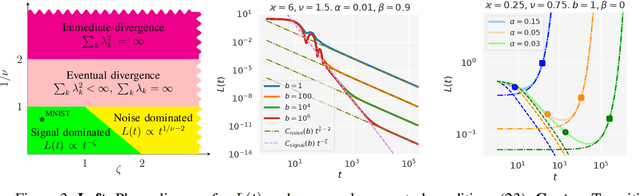
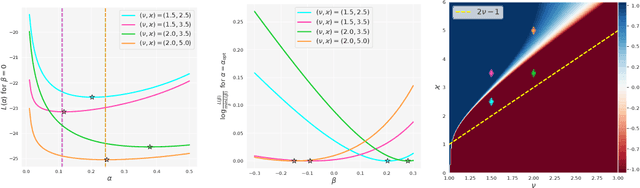
Mini-batch SGD with momentum is a fundamental algorithm for learning large predictive models. In this paper we develop a new analytic framework to analyze mini-batch SGD for linear models at different momenta and sizes of batches. Our key idea is to describe the loss value sequence in terms of its generating function, which can be written in a compact form assuming a diagonal approximation for the second moments of model weights. By analyzing this generating function, we deduce various conclusions on the convergence conditions, phase structure of the model, and optimal learning settings. As a few examples, we show that 1) the optimization trajectory can generally switch from the "signal-dominated" to the "noise-dominated" phase, at a time scale that can be predicted analytically; 2) in the "signal-dominated" (but not the "noise-dominated") phase it is favorable to choose a large effective learning rate, however its value must be limited for any finite batch size to avoid divergence; 3) optimal convergence rate can be achieved at a negative momentum. We verify our theoretical predictions by extensive experiments with MNIST and synthetic problems, and find a good quantitative agreement.
Time-correlated Window Carrier-phase Aided GNSS Positioning Using Factor Graph Optimization for Urban Positioning
Sep 02, 2021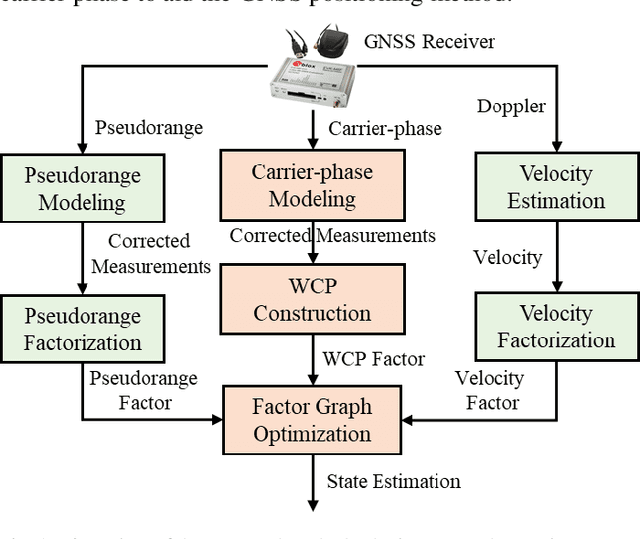
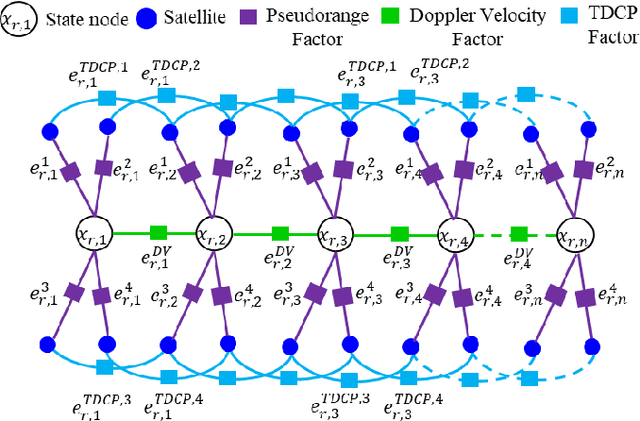
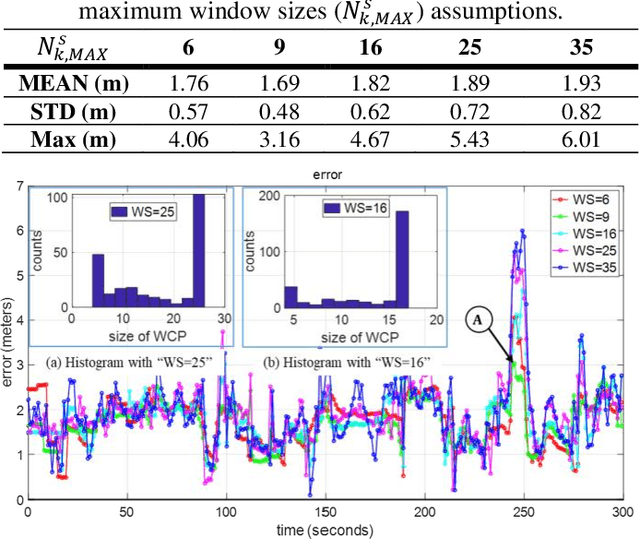
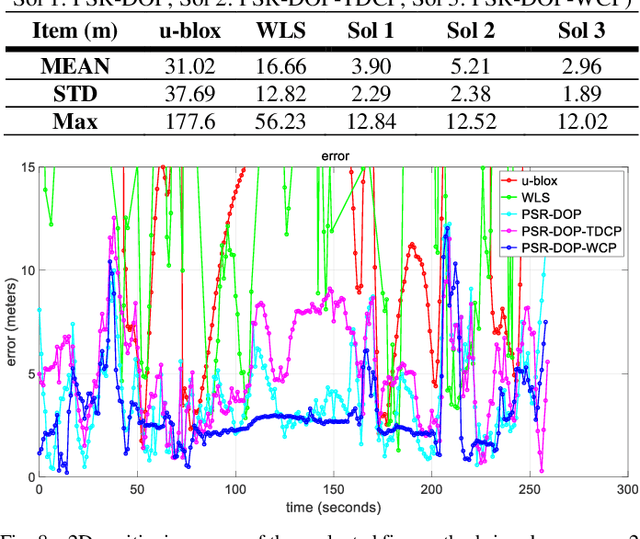
This paper proposes an improved global navigation satellite system (GNSS) positioning method that explores the time correlation between consecutive epochs of the code and carrier phase measurements which significantly increases the robustness against outlier measurements. Instead of relying on the time difference carrier phase (TDCP) which only considers two neighboring epochs using an extended Kalman filter (EKF) estimator, this paper proposed to employ the carrier-phase measurements inside a window, the so-called window carrier-phase (WCP), to constrain the states inside a factor graph. A left null space matrix is employed to eliminate the shared unknown ambiguity variables and therefore, correlated the associated states inside the WCP. Then the pseudorange, Doppler, and the constructed WCP measurements are integrated simultaneously using factor graph optimization (FGO) to estimate the state of the GNSS receiver. We evaluated the performance of the proposed method in two typical urban canyons in Hong Kong, achieving the mean positioning error of 1.76 meters and 2.96 meters, respectively, using the automobile-level GNSS receiver. Meanwhile, the effectiveness of the proposed method is further evaluated using a low-cost smartphone level GNSS receiver and similar improvement is also obtained, compared with several existing GNSS positioning methods.
Algorithm for Constrained Markov Decision Process with Linear Convergence
Jun 03, 2022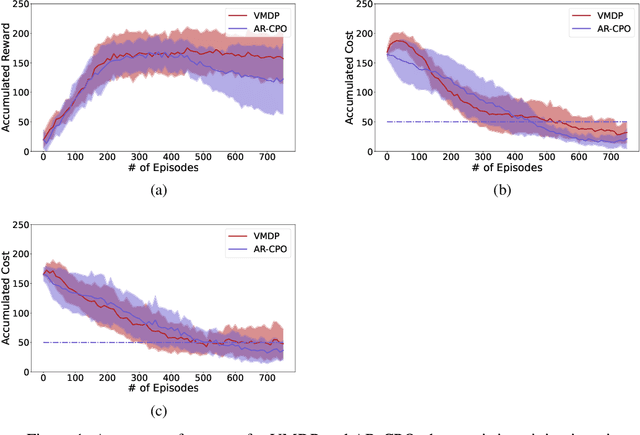

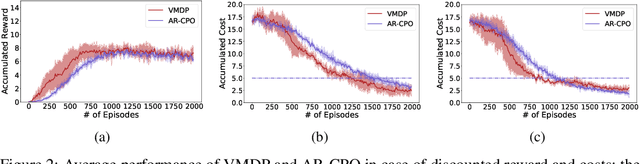
The problem of constrained Markov decision process is considered. An agent aims to maximize the expected accumulated discounted reward subject to multiple constraints on its costs (the number of constraints is relatively small). A new dual approach is proposed with the integration of two ingredients: entropy regularized policy optimizer and Vaidya's dual optimizer, both of which are critical to achieve faster convergence. The finite-time error bound of the proposed approach is provided. Despite the challenge of the nonconcave objective subject to nonconcave constraints, the proposed approach is shown to converge (with linear rate) to the global optimum. The complexity expressed in terms of the optimality gap and the constraint violation significantly improves upon the existing primal-dual approaches.
NumS: Scalable Array Programming for the Cloud
Jun 28, 2022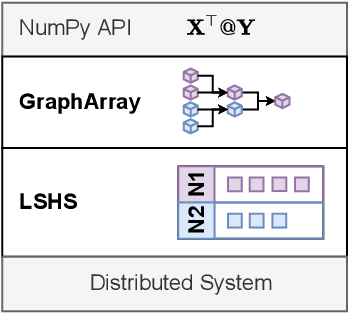

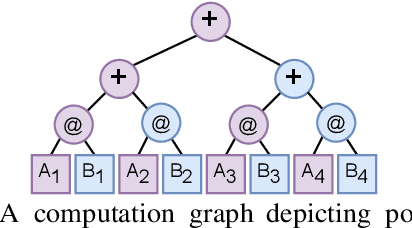
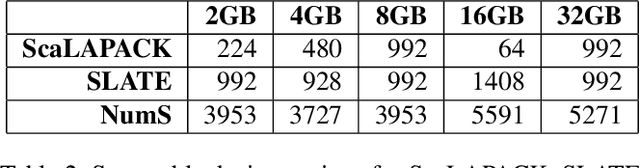
Scientists increasingly rely on Python tools to perform scalable distributed memory array operations using rich, NumPy-like expressions. However, many of these tools rely on dynamic schedulers optimized for abstract task graphs, which often encounter memory and network bandwidth-related bottlenecks due to sub-optimal data and operator placement decisions. Tools built on the message passing interface (MPI), such as ScaLAPACK and SLATE, have better scaling properties, but these solutions require specialized knowledge to use. In this work, we present NumS, an array programming library which optimizes NumPy-like expressions on task-based distributed systems. This is achieved through a novel scheduler called Load Simulated Hierarchical Scheduling (LSHS). LSHS is a local search method which optimizes operator placement by minimizing maximum memory and network load on any given node within a distributed system. Coupled with a heuristic for load balanced data layouts, our approach is capable of attaining communication lower bounds on some common numerical operations, and our empirical study shows that LSHS enhances performance on Ray by decreasing network load by a factor of 2x, requiring 4x less memory, and reducing execution time by 10x on the logistic regression problem. On terabyte-scale data, NumS achieves competitive performance to SLATE on DGEMM, up to 20x speedup over Dask on a key operation for tensor factorization, and a 2x speedup on logistic regression compared to Dask ML and Spark's MLlib.
PillarNet: High-Performance Pillar-based 3D Object Detection
May 16, 2022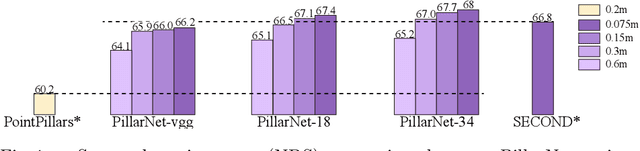
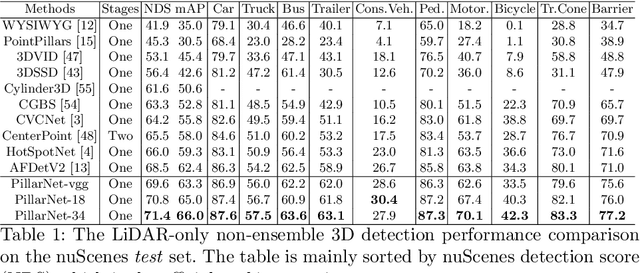
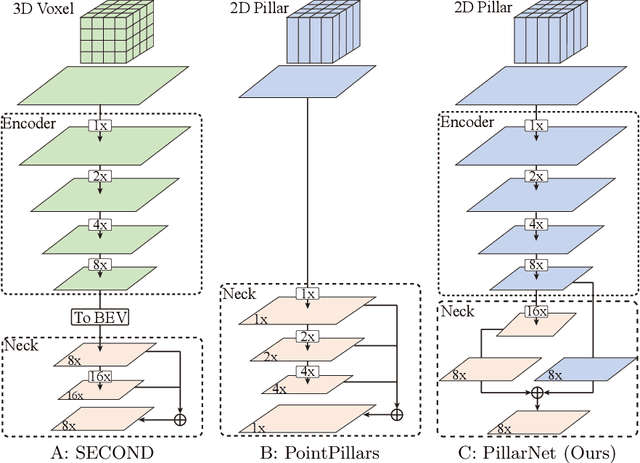

Real-time and high-performance 3D object detection is of critical importance for autonomous driving. Recent top-performing 3D object detectors mainly rely on point-based or 3D voxel-based convolutions, which are both computationally inefficient for onboard deployment. In contrast, pillar-based methods use merely 2D convolutions, which consume less computation resources, but they lag far behind their voxel-based counterparts in detection accuracy. In this paper, by examining the primary performance gap between pillar- and voxel-based detectors, we develop a real-time and high-performance pillar-based detector, dubbed PillarNet. The proposed PillarNet consists of a powerful encoder network for effective pillar feature learning, a neck network for spatial-semantic feature fusion and the commonly used detect head. Using only 2D convolutions, PillarNet is flexible to an optional pillar size and compatible with classical 2D CNN backbones, such as VGGNet and ResNet. Additionally, PillarNet benefits from an orientation-decoupled IoU regression loss along with the IoU-aware prediction branch. Extensive experimental results on the large-scale nuScenes Dataset and Waymo Open Dataset demonstrate that the proposed PillarNet performs well over the state-of-the-art 3D detectors in terms of effectiveness and efficiency.
EVReflex: Dense Time-to-Impact Prediction for Event-based Obstacle Avoidance
Sep 01, 2021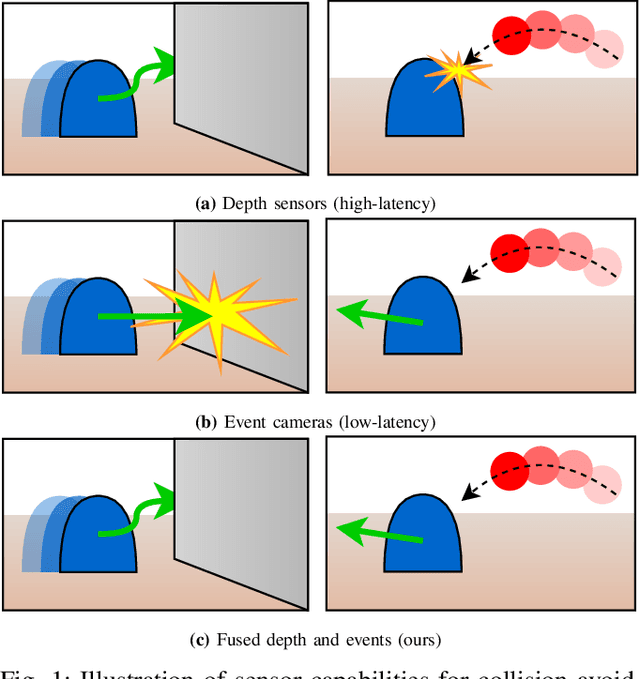
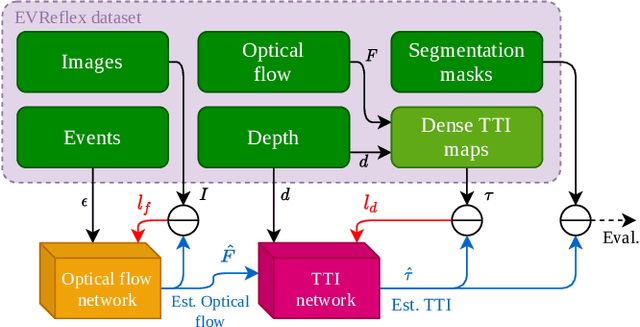
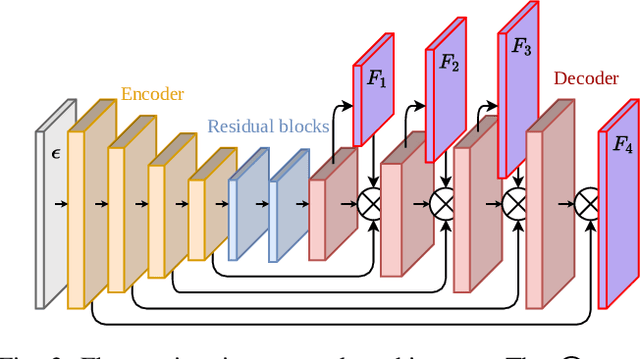
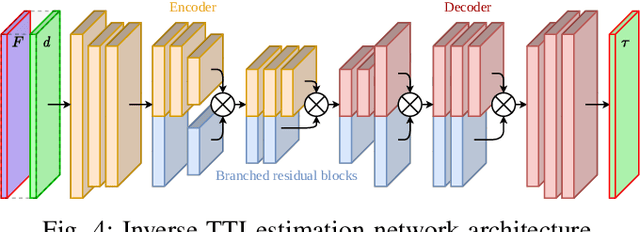
The broad scope of obstacle avoidance has led to many kinds of computer vision-based approaches. Despite its popularity, it is not a solved problem. Traditional computer vision techniques using cameras and depth sensors often focus on static scenes, or rely on priors about the obstacles. Recent developments in bio-inspired sensors present event cameras as a compelling choice for dynamic scenes. Although these sensors have many advantages over their frame-based counterparts, such as high dynamic range and temporal resolution, event-based perception has largely remained in 2D. This often leads to solutions reliant on heuristics and specific to a particular task. We show that the fusion of events and depth overcomes the failure cases of each individual modality when performing obstacle avoidance. Our proposed approach unifies event camera and lidar streams to estimate metric time-to-impact without prior knowledge of the scene geometry or obstacles. In addition, we release an extensive event-based dataset with six visual streams spanning over 700 scanned scenes.
Leveraging Dynamic Objects for Relative Localization COrrection in a Connected Autonomous Vehicle Network
May 19, 2022



High-accurate localization is crucial for the safety and reliability of autonomous driving, especially for the information fusion of collective perception that aims to further improve road safety by sharing information in a communication network of ConnectedAutonomous Vehicles (CAV). In this scenario, small localization errors can impose additional difficulty on fusing the information from different CAVs. In this paper, we propose a RANSAC-based (RANdom SAmple Consensus) method to correct the relative localization errors between two CAVs in order to ease the information fusion among the CAVs. Different from previous LiDAR-based localization algorithms that only take the static environmental information into consideration, this method also leverages the dynamic objects for localization thanks to the real-time data sharing between CAVs. Specifically, in addition to the static objects like poles, fences, and facades, the object centers of the detected dynamic vehicles are also used as keypoints for the matching of two point sets. The experiments on the synthetic dataset COMAP show that the proposed method can greatly decrease the relative localization error between two CAVs to less than 20cmas far as there are enough vehicles and poles are correctly detected by bothCAVs. Besides, our proposed method is also highly efficient in runtime and can be used in real-time scenarios of autonomous driving.
A Neural Beam Filter for Real-time Multi-channel Speech Enhancement
Feb 05, 2022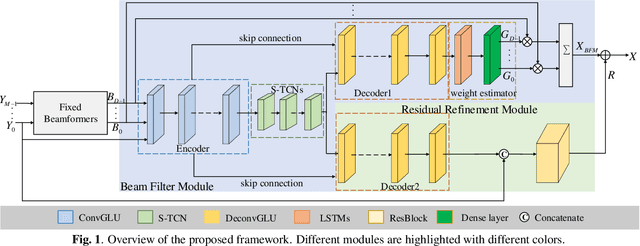
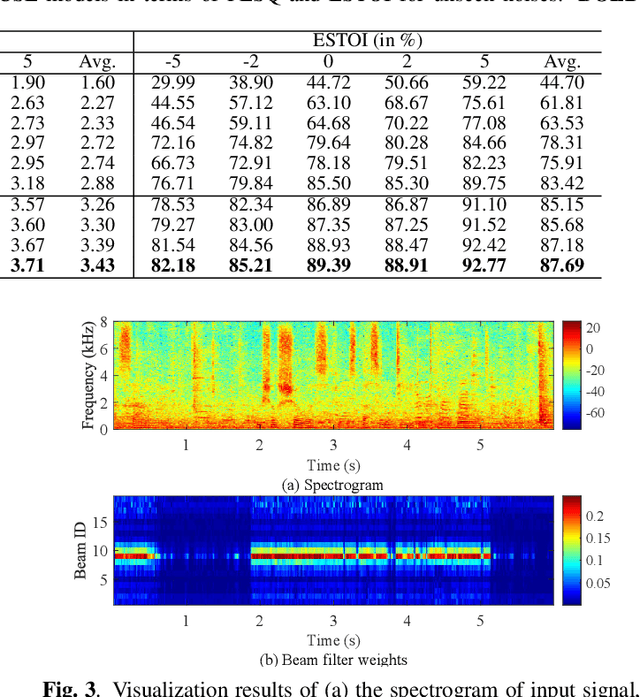
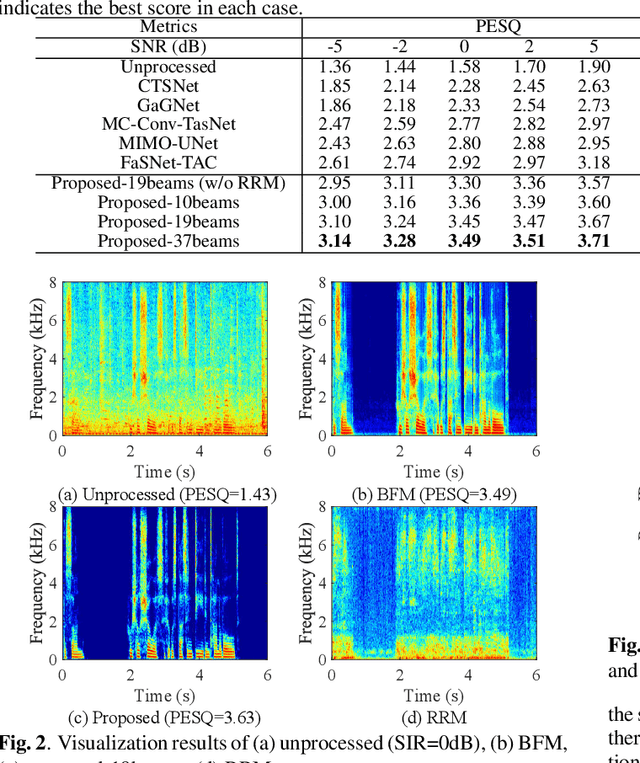
Most deep learning-based multi-channel speech enhancement methods focus on designing a set of beamforming coefficients to directly filter the low signal-to-noise ratio signals received by microphones, which hinders the performance of these approaches. To handle these problems, this paper designs a causal neural beam filter that fully exploits the spatial-spectral information in the beam domain. Specifically, multiple beams are designed to steer towards all directions using a parameterized super-directive beamformer in the first stage. After that, the neural spatial filter is learned by simultaneously modeling the spatial and spectral discriminability of the speech and the interference, so as to extract the desired speech coarsely in the second stage. Finally, to further suppress the interference components especially at low frequencies, a residual estimation module is adopted to refine the output of the second stage. Experimental results demonstrate that the proposed approach outperforms many state-of-the-art multi-channel methods on the generated multi-channel speech dataset based on the DNS-Challenge dataset.