 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Search Strategies in Non-Serializable Environments with Applications to Software Engineering Agents
May 19, 2025Large language models (LLMs) have recently achieved remarkable results in complex multi-step tasks, such as mathematical reasoning and agentic software engineering. However, they often struggle to maintain consistent performance across multiple solution attempts. One effective approach to narrow the gap between average-case and best-case performance is guided test-time search, which explores multiple solution paths to identify the most promising one. Unfortunately, effective search techniques (e.g. MCTS) are often unsuitable for non-serializable RL environments, such as Docker containers, where intermediate environment states cannot be easily saved and restored. We investigate two complementary search strategies applicable to such environments: 1-step lookahead and trajectory selection, both guided by a learned action-value function estimator. On the SWE-bench Verified benchmark, a key testbed for agentic software engineering, we find these methods to double the average success rate of a fine-tuned Qwen-72B model, achieving 40.8%, the new state-of-the-art for open-weights models. Additionally, we show that these techniques are transferable to more advanced closed models, yielding similar improvements with GPT-4o.
Algorithm for Constrained Markov Decision Process with Linear Convergence
Jun 03, 2022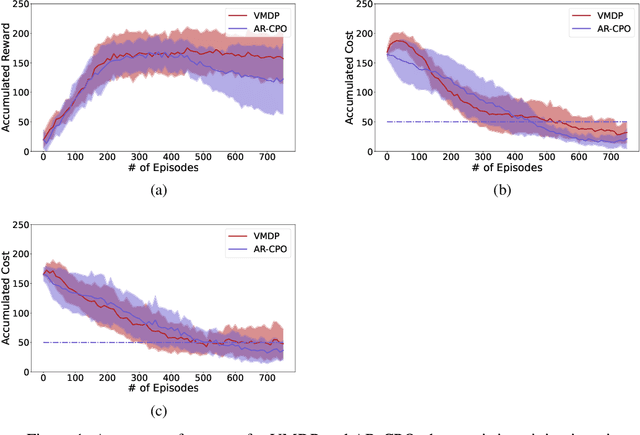

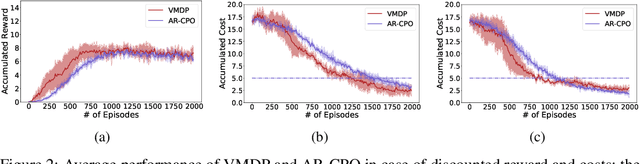
The problem of constrained Markov decision process is considered. An agent aims to maximize the expected accumulated discounted reward subject to multiple constraints on its costs (the number of constraints is relatively small). A new dual approach is proposed with the integration of two ingredients: entropy regularized policy optimizer and Vaidya's dual optimizer, both of which are critical to achieve faster convergence. The finite-time error bound of the proposed approach is provided. Despite the challenge of the nonconcave objective subject to nonconcave constraints, the proposed approach is shown to converge (with linear rate) to the global optimum. The complexity expressed in terms of the optimality gap and the constraint violation significantly improves upon the existing primal-dual approaches.