 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
FedPseudo: Pseudo value-based Deep Learning Models for Federated Survival Analysis
Jul 12, 2022
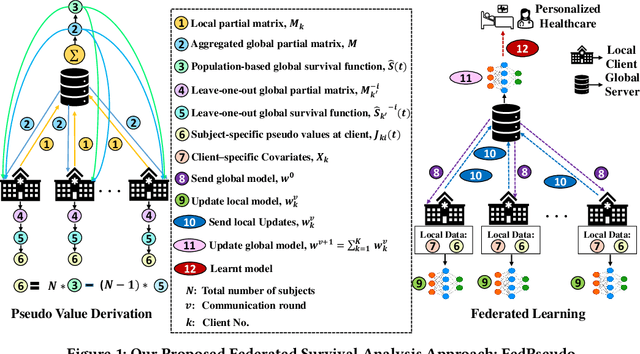
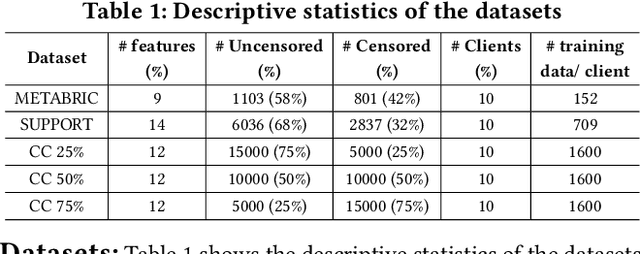
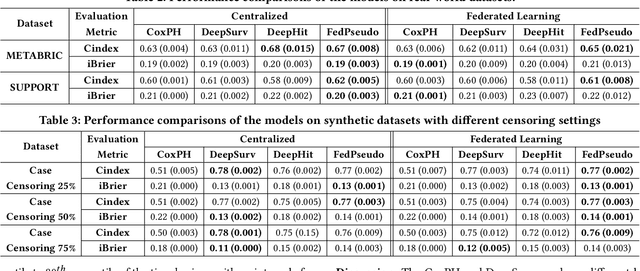
Survival analysis, time-to-event analysis, is an important problem in healthcare since it has a wide-ranging impact on patients and palliative care. Many survival analysis methods have assumed that the survival data is centrally available either from one medical center or by data sharing from multi-centers. However, the sensitivity of the patient attributes and the strict privacy laws have increasingly forbidden sharing of healthcare data. To address this challenge, the research community has looked at the solution of decentralized training and sharing of model parameters using the Federated Learning (FL) paradigm. In this paper, we study the utilization of FL for performing survival analysis on distributed healthcare datasets. Recently, the popular Cox proportional hazard (CPH) models have been adapted for FL settings; however, due to its linearity and proportional hazards assumptions, CPH models result in suboptimal performance, especially for non-linear, non-iid, and heavily censored survival datasets. To overcome the challenges of existing federated survival analysis methods, we leverage the predictive accuracy of the deep learning models and the power of pseudo values to propose a first-of-its-kind, pseudo value-based deep learning model for federated survival analysis (FSA) called FedPseudo. Furthermore, we introduce a novel approach of deriving pseudo values for survival probability in the FL settings that speeds up the computation of pseudo values. Extensive experiments on synthetic and real-world datasets show that our pseudo valued-based FL framework achieves similar performance as the best centrally trained deep survival analysis model. Moreover, our proposed FL approach obtains the best results for various censoring settings.
LiDAR-as-Camera for End-to-End Driving
Jun 30, 2022


The core task of any autonomous driving system is to transform sensory inputs into driving commands. In end-to-end driving, this is achieved via a neural network, with one or multiple cameras as the most commonly used input and low-level driving command, e.g. steering angle, as output. However, depth-sensing has been shown in simulation to make the end-to-end driving task easier. On a real car, combining depth and visual information can be challenging, due to the difficulty of obtaining good spatial and temporal alignment of the sensors. To alleviate alignment problems, Ouster LiDARs can output surround-view LiDAR-images with depth, intensity, and ambient radiation channels. These measurements originate from the same sensor, rendering them perfectly aligned in time and space. We demonstrate that such LiDAR-images are sufficient for the real-car road-following task and perform at least equally to camera-based models in the tested conditions, with the difference increasing when needing to generalize to new weather conditions. In the second direction of study, we reveal that the temporal smoothness of off-policy prediction sequences correlates equally well with actual on-policy driving ability as the commonly used mean absolute error.
Density-Based Pruning of Drone Swarm Services
Jun 09, 2022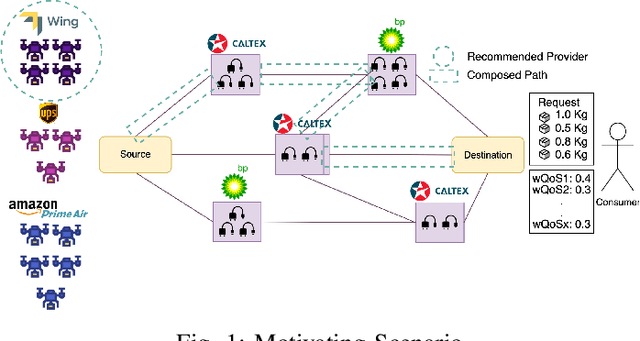
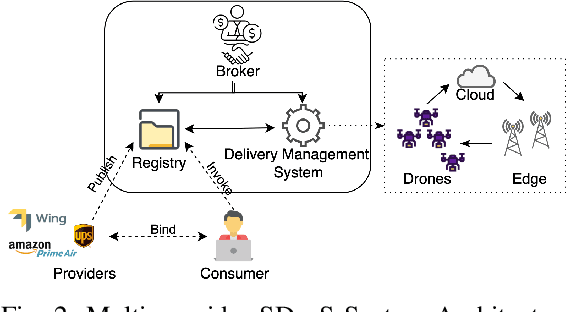
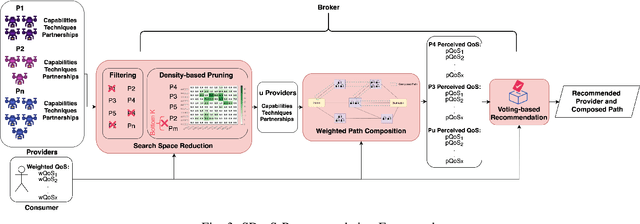
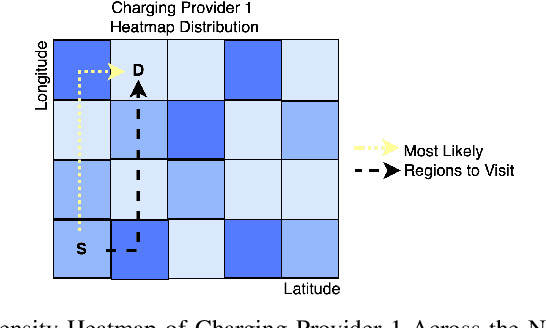
We propose a novel framework for the recommendation of swarm-based drone delivery services based on the consumers preferences. We propose a density-based pruning approach that uses the concept of partnerships with charging station providers to reduce the search space of swarm-based drone service delivery providers. A weighted service composition algorithm is proposed that considers the providers capabilities and consumers' preferences in selecting the best next service. We propose a voting-based recommendation algorithm to select the best providers. We conduct a set of experiments to evaluate the efficiency of the framework in terms of consumer satisfaction, run-time, and search space reduction cost.
LidarMutliNet: Unifying LiDAR Semantic Segmentation, 3D Object Detection, and Panoptic Segmentation in a Single Multi-task Network
Jun 23, 2022
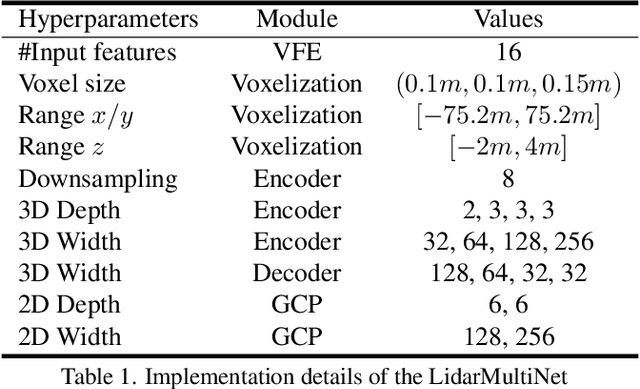
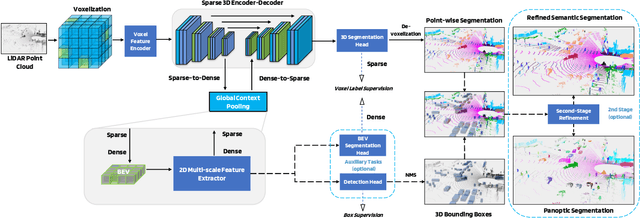
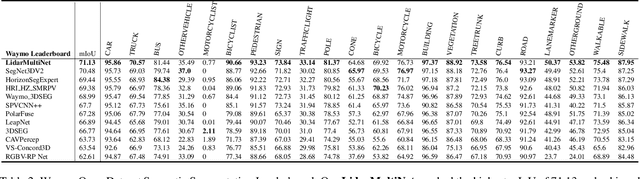
This technical report presents the 1st place winning solution for the Waymo Open Dataset 3D semantic segmentation challenge 2022. Our network, termed LidarMultiNet, unifies the major LiDAR perception tasks such as 3D semantic segmentation, object detection, and panoptic segmentation in a single framework. At the core of LidarMultiNet is a strong 3D voxel-based encoder-decoder network with a novel Global Context Pooling (GCP) module extracting global contextual features from a LiDAR frame to complement its local features. An optional second stage is proposed to refine the first-stage segmentation or generate accurate panoptic segmentation results. Our solution achieves a mIoU of 71.13 and is the best for most of the 22 classes on the Waymo 3D semantic segmentation test set, outperforming all the other 3D semantic segmentation methods on the official leaderboard. We demonstrate for the first time that major LiDAR perception tasks can be unified in a single strong network that can be trained end-to-end.
Time-domain Speech Enhancement with Generative Adversarial Learning
Mar 30, 2021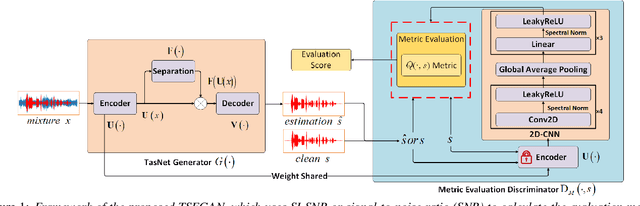
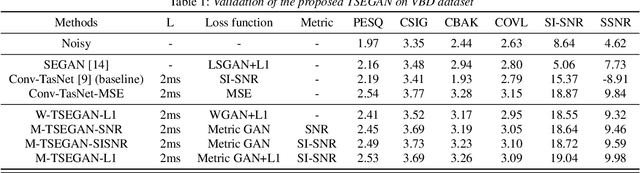
Speech enhancement aims to obtain speech signals with high intelligibility and quality from noisy speech. Recent work has demonstrated the excellent performance of time-domain deep learning methods, such as Conv-TasNet. However, these methods can be degraded by the arbitrary scales of the waveform induced by the scale-invariant signal-to-noise ratio (SI-SNR) loss. This paper proposes a new framework called Time-domain Speech Enhancement Generative Adversarial Network (TSEGAN), which is an extension of the generative adversarial network (GAN) in time-domain with metric evaluation to mitigate the scaling problem, and provide model training stability, thus achieving performance improvement. In addition, we provide a new method based on objective function mapping for the theoretical analysis of the performance of Metric GAN, and explain why it is better than the Wasserstein GAN. Experiments conducted demonstrate the effectiveness of our proposed method, and illustrate the advantage of Metric GAN.
Topology-aware Graph Neural Networks for Learning Feasible and Adaptive ac-OPF Solutions
May 16, 2022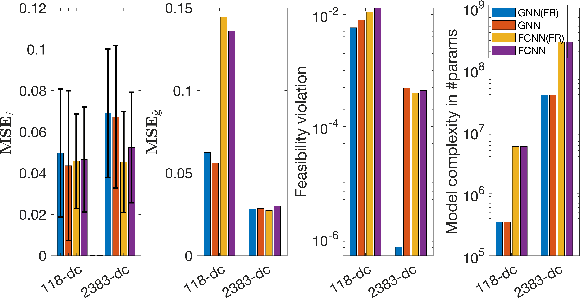
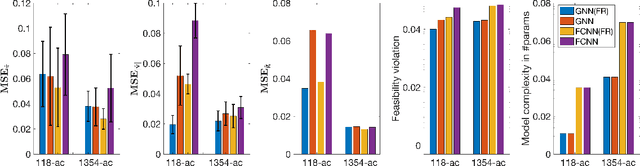
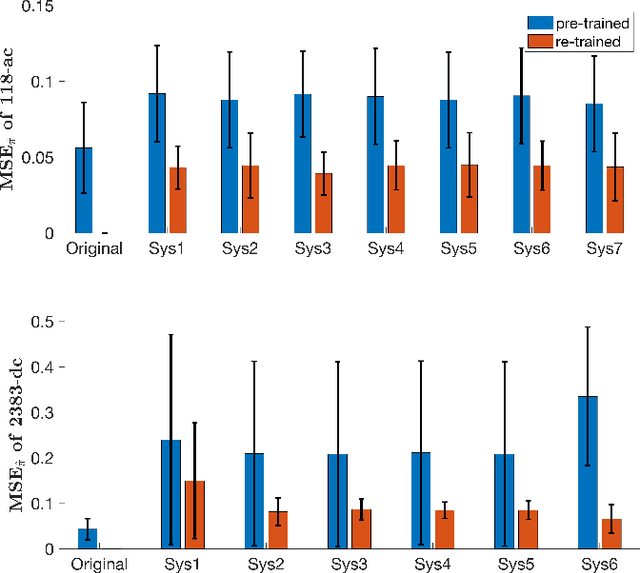
Solving the optimal power flow (OPF) problem is a fundamental task to ensure the system efficiency and reliability in real-time electricity grid operations. We develop a new topology-informed graph neural network (GNN) approach for predicting the optimal solutions of real-time ac-OPF problem. To incorporate grid topology to the NN model, the proposed GNN-for-OPF framework innovatively exploits the locality property of locational marginal prices and voltage magnitude. Furthermore, we develop a physics-aware (ac-)flow feasibility regularization approach for general OPF learning. The advantages of our proposed designs include reduced model complexity, improved generalizability and feasibility guarantees. By providing the analytical understanding on the graph subspace stability under grid topology contingency, we show the proposed GNN can quickly adapt to varying grid topology by an efficient re-training strategy. Numerical tests on various test systems of different sizes have validated the prediction accuracy, improved flow feasibility, and topology adaptivity capability of our proposed GNN-based learning framework.
Learning-Based Near-Orthogonal Superposition Code for MIMO Short Message Transmission
Jun 30, 2022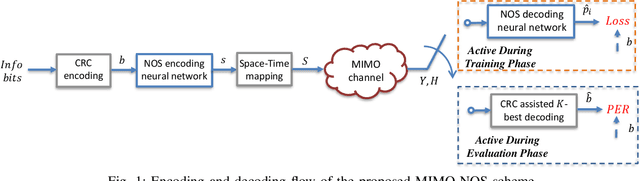
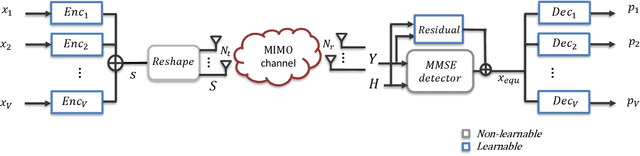
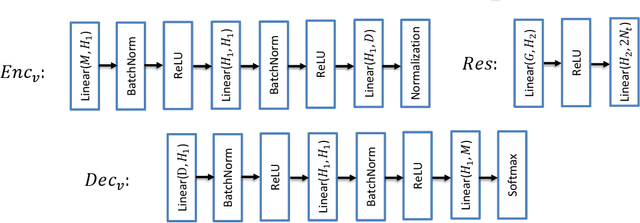
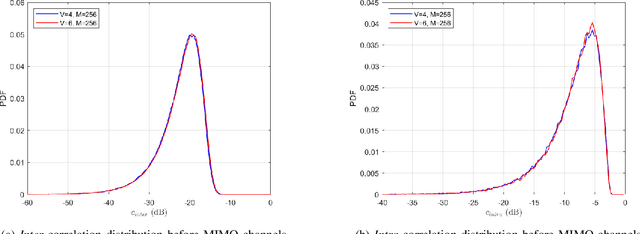
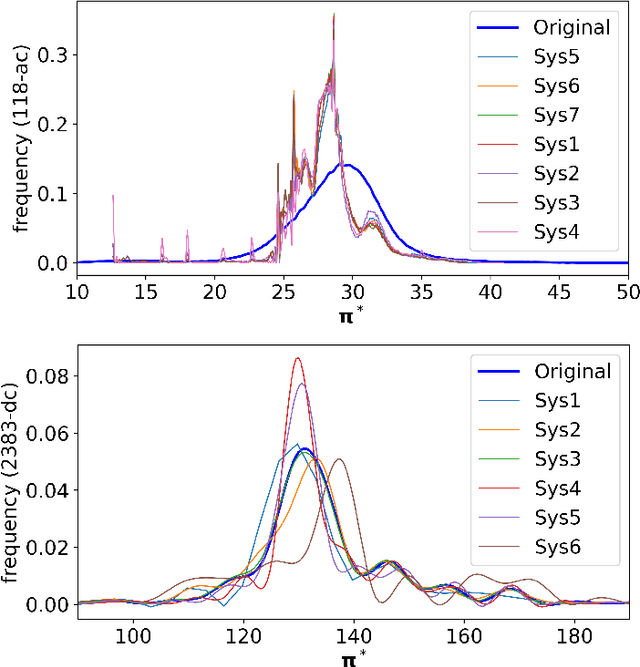
Massive machine type communication (mMTC) has attracted new coding schemes optimized for reliable short message transmission. In this paper, a novel deep learning-based near-orthogonal superposition (NOS) coding scheme is proposed to transmit short messages in multiple-input multiple-output (MIMO) channels for mMTC applications. In the proposed MIMO-NOS scheme, a neural network-based encoder is optimized via end-to-end learning with a corresponding neural network-based detector/decoder in a superposition-based auto-encoder framework including a MIMO channel. The proposed MIMO-NOS encoder spreads the information bits to multiple near-orthogonal high dimensional vectors to be combined (superimposed) into a single vector and reshaped for the space-time transmission. For the receiver, we propose a novel looped K-best tree-search algorithm with cyclic redundancy check (CRC) assistance to enhance the error correcting ability in the block-fading MIMO channel. Simulation results show the proposed MIMO-NOS scheme outperforms maximum likelihood (ML) MIMO detection combined with a polar code with CRC-assisted list decoding by 1-2 dB in various MIMO systems for short (32-64 bit) message transmission.
Learning to Increase the Power of Conditional Randomization Tests
Jul 03, 2022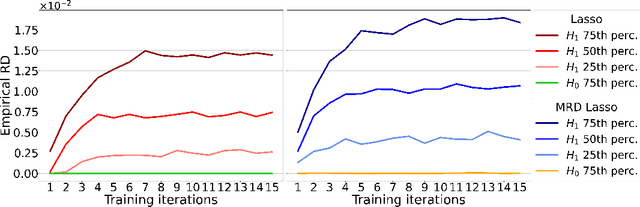
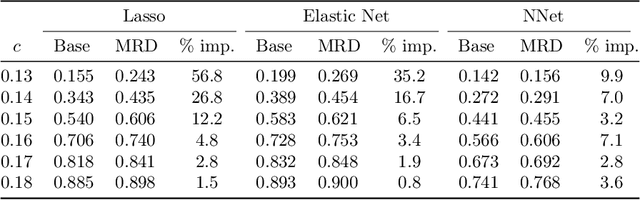
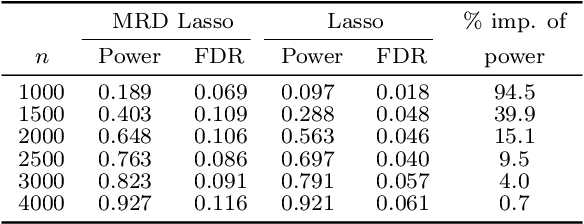
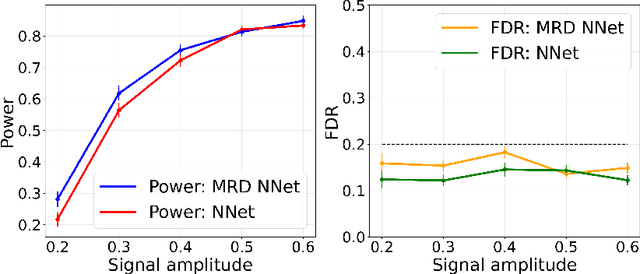
The model-X conditional randomization test is a generic framework for conditional independence testing, unlocking new possibilities to discover features that are conditionally associated with a response of interest while controlling type-I error rates. An appealing advantage of this test is that it can work with any machine learning model to design powerful test statistics. In turn, the common practice in the model-X literature is to form a test statistic using machine learning models, trained to maximize predictive accuracy with the hope to attain a test with good power. However, the ideal goal here is to drive the model (during training) to maximize the power of the test, not merely the predictive accuracy. In this paper, we bridge this gap by introducing, for the first time, novel model-fitting schemes that are designed to explicitly improve the power of model-X tests. This is done by introducing a new cost function that aims at maximizing the test statistic used to measure violations of conditional independence. Using synthetic and real data sets, we demonstrate that the combination of our proposed loss function with various base predictive models (lasso, elastic net, and deep neural networks) consistently increases the number of correct discoveries obtained, while maintaining type-I error rates under control.
Improving Road Segmentation in Challenging Domains Using Similar Place Priors
May 27, 2022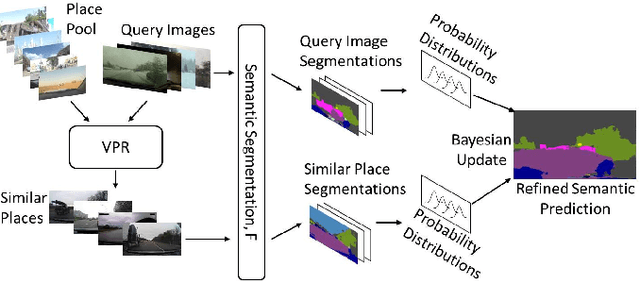
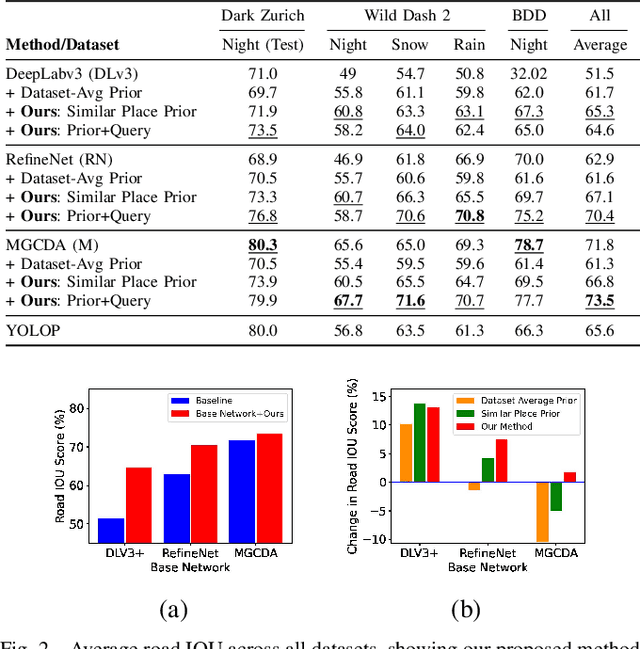
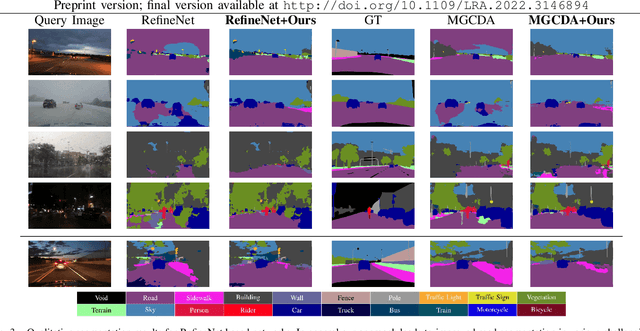
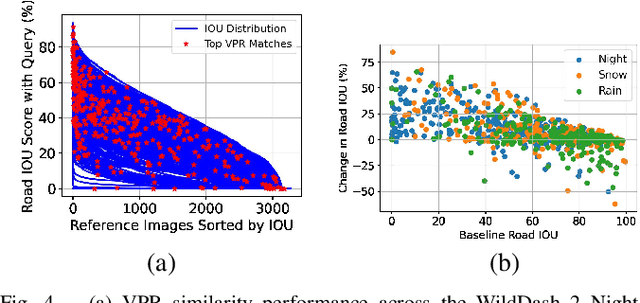
Road segmentation in challenging domains, such as night, snow or rain, is a difficult task. Most current approaches boost performance using fine-tuning, domain adaptation, style transfer, or by referencing previously acquired imagery. These approaches share one or more of three significant limitations: a reliance on large amounts of annotated training data that can be costly to obtain, both anticipation of and training data from the type of environmental conditions expected at inference time, and/or imagery captured from a previous visit to the location. In this research, we remove these restrictions by improving road segmentation based on similar places. We use Visual Place Recognition (VPR) to find similar but geographically distinct places, and fuse segmentations for query images and these similar place priors using a Bayesian approach and novel segmentation quality metric. Ablation studies show the need to re-evaluate notions of VPR utility for this task. We demonstrate the system achieving state-of-the-art road segmentation performance across multiple challenging condition scenarios including night time and snow, without requiring any prior training or previous access to the same geographical locations. Furthermore, we show that this method is network agnostic, improves multiple baseline techniques and is competitive against methods specialised for road prediction.
* Accepted into IEEE Robotics and Automation Letters (RA-L) and presented at IEEE International Conference on Robotics and Automation (ICRA 2022)
Axial and radial axonal diffusivities from single encoding strongly diffusion-weighted MRI
Jul 06, 2022
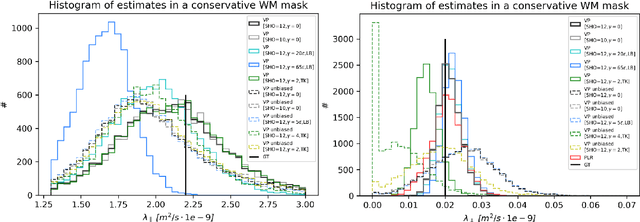
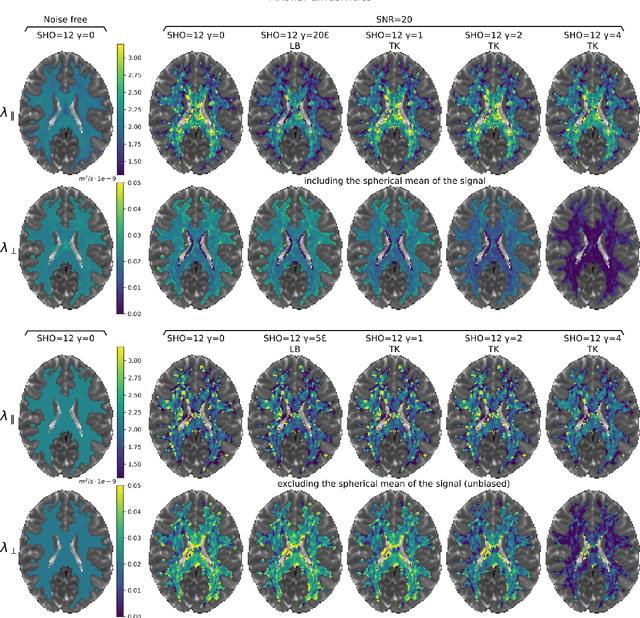
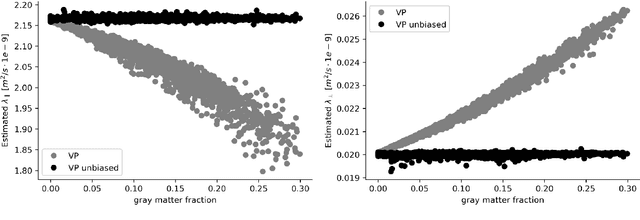
We enable the estimation of the per-axon axial diffusivity from single encoding, strongly diffusion-weighted, pulsed gradient spin echo data. Additionally, we improve the estimation of the per-axon radial diffusivity compared to estimates based on spherical averaging. The use of strong diffusion weightings in magnetic resonance imaging (MRI) allows to approximate the signal in white matter as the sum of the contributions from axons. At the same time, spherical averaging leads to a major simplification of the modeling by removing the need to explicitly account for the unknown orientation distribution of axons. However, the spherically averaged signal acquired at strong diffusion weightings is not sensitive to the axial diffusivity, which cannot therefore be estimated. After revising existing theory, we introduce a new general method for the estimation of both axonal diffusivities at strong diffusion weightings based on zonal harmonics modeling. We additionally show how this could lead to estimates that are free from partial volume bias with, for instance, gray matter. We test the method on publicly available data from the MGH Adult Diffusion Human Connectome project dataset. We report reference values of axonal diffusivities based on 34 subjects, and derive estimates of axonal radii. We address the estimation problem also from the angle of the required data preprocessing, the presence of biases related to modeling assumptions, current limitations, and future possibilities.