 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Representation of Causal Background Knowledge and its Applications in Causal Inference
Jul 10, 2022


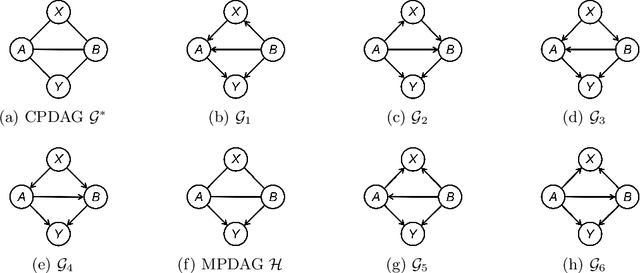

Causal background knowledge about the existence or the absence of causal edges and paths is frequently encountered in observational studies. The shared directed edges and links of a subclass of Markov equivalent DAGs refined due to background knowledge can be represented by a causal maximally partially directed acyclic graph (MPDAG). In this paper, we first provide a sound and complete graphical characterization of causal MPDAGs and give a minimal representation of a causal MPDAG. Then, we introduce a novel representation called direct causal clause (DCC) to represent all types of causal background knowledge in a unified form. Using DCCs, we study the consistency and equivalency of causal background knowledge and show that any causal background knowledge set can be equivalently decomposed into a causal MPDAG plus a minimal residual set of DCCs. Polynomial-time algorithms are also provided for checking the consistency, equivalency, and finding the decomposed MPDAG and residual DCCs. Finally, with causal background knowledge, we prove a sufficient and necessary condition to identify causal effects and surprisingly find that the identifiability of causal effects only depends on the decomposed MPDAG. We also develop a local IDA-type algorithm to estimate the possible values of an unidentifiable effect. Simulations suggest that causal background knowledge can significantly improve the identifiability of causal effects.
NeFSAC: Neurally Filtered Minimal Samples
Jul 16, 2022
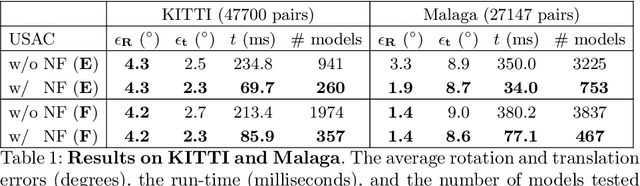

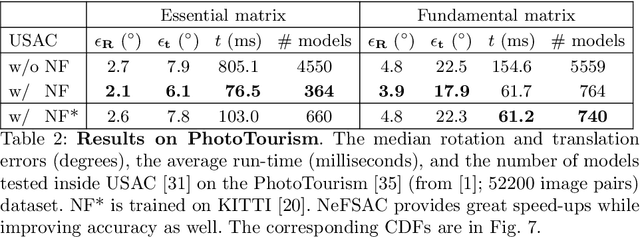
Since RANSAC, a great deal of research has been devoted to improving both its accuracy and run-time. Still, only a few methods aim at recognizing invalid minimal samples early, before the often expensive model estimation and quality calculation are done. To this end, we propose NeFSAC, an efficient algorithm for neural filtering of motion-inconsistent and poorly-conditioned minimal samples. We train NeFSAC to predict the probability of a minimal sample leading to an accurate relative pose, only based on the pixel coordinates of the image correspondences. Our neural filtering model learns typical motion patterns of samples which lead to unstable poses, and regularities in the possible motions to favour well-conditioned and likely-correct samples. The novel lightweight architecture implements the main invariants of minimal samples for pose estimation, and a novel training scheme addresses the problem of extreme class imbalance. NeFSAC can be plugged into any existing RANSAC-based pipeline. We integrate it into USAC and show that it consistently provides strong speed-ups even under extreme train-test domain gaps - for example, the model trained for the autonomous driving scenario works on PhotoTourism too. We tested NeFSAC on more than 100k image pairs from three publicly available real-world datasets and found that it leads to one order of magnitude speed-up, while often finding more accurate results than USAC alone. The source code is available at https://github.com/cavalli1234/NeFSAC.
RPLHR-CT Dataset and Transformer Baseline for Volumetric Super-Resolution from CT Scans
Jun 13, 2022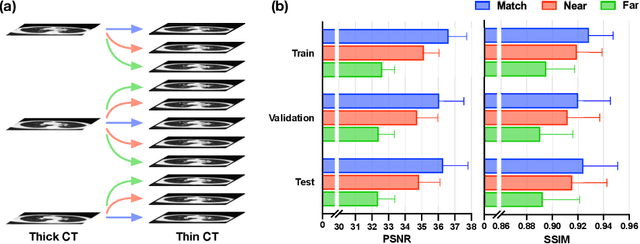
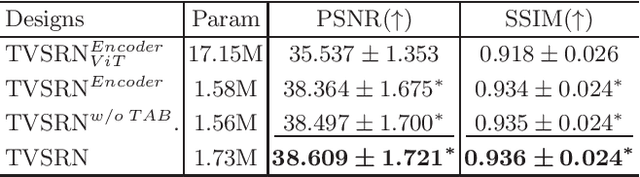
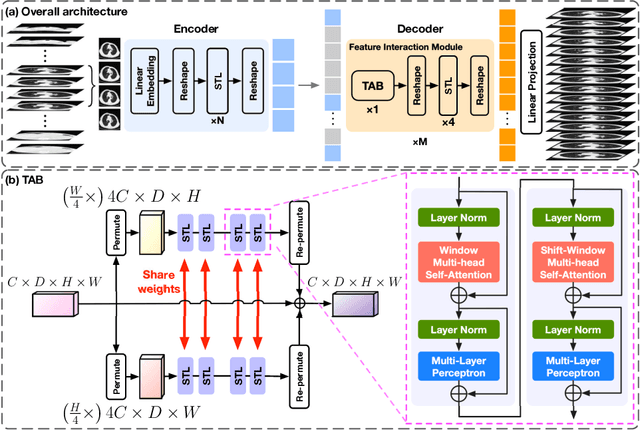
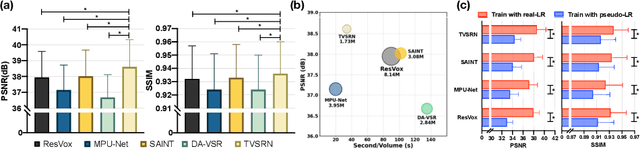
In clinical practice, anisotropic volumetric medical images with low through-plane resolution are commonly used due to short acquisition time and lower storage cost. Nevertheless, the coarse resolution may lead to difficulties in medical diagnosis by either physicians or computer-aided diagnosis algorithms. Deep learning-based volumetric super-resolution (SR) methods are feasible ways to improve resolution, with convolutional neural networks (CNN) at their core. Despite recent progress, these methods are limited by inherent properties of convolution operators, which ignore content relevance and cannot effectively model long-range dependencies. In addition, most of the existing methods use pseudo-paired volumes for training and evaluation, where pseudo low-resolution (LR) volumes are generated by a simple degradation of their high-resolution (HR) counterparts. However, the domain gap between pseudo- and real-LR volumes leads to the poor performance of these methods in practice. In this paper, we build the first public real-paired dataset RPLHR-CT as a benchmark for volumetric SR, and provide baseline results by re-implementing four state-of-the-art CNN-based methods. Considering the inherent shortcoming of CNN, we also propose a transformer volumetric super-resolution network (TVSRN) based on attention mechanisms, dispensing with convolutions entirely. This is the first research to use a pure transformer for CT volumetric SR. The experimental results show that TVSRN significantly outperforms all baselines on both PSNR and SSIM. Moreover, the TVSRN method achieves a better trade-off between the image quality, the number of parameters, and the running time. Data and code are available at https://github.com/smilenaxx/RPLHR-CT.
Hierarchical Planning with Annotated Skeleton Guidance
Jun 23, 2022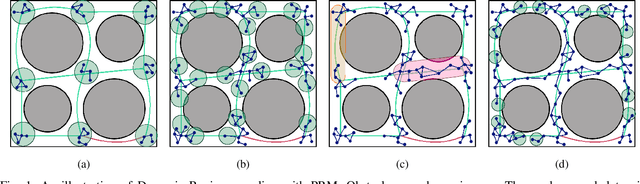
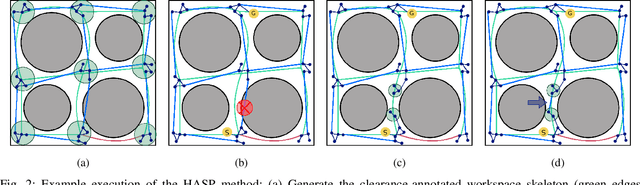
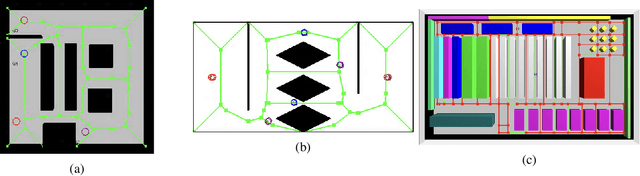
We present a hierarchical skeleton-guided motion planning algorithm to guide mobile robots. A good skeleton maps the connectivity of the subspace of c-space containing significant degrees of freedom and is able to guide the planner to find the desired solutions fast. However, sometimes the skeleton does not closely represent the free c-space, which often misleads current skeleton-guided planners. The hierarchical skeleton-guided planning strategy gradually relaxes its reliance on the workspace skeleton as C space is sampled, thereby incrementally returning a sub-optimal path, a feature that is not guaranteed in the standard skeleton-guided algorithm. Experimental comparisons to the standard skeleton-guided planners and other lazy planning strategies show significant improvement in roadmap construction run time while maintaining path quality for multi-query problems in cluttered environments.
Polytopic Planar Region Characterization of Rough Terrains for Legged Locomotion
Jul 07, 2022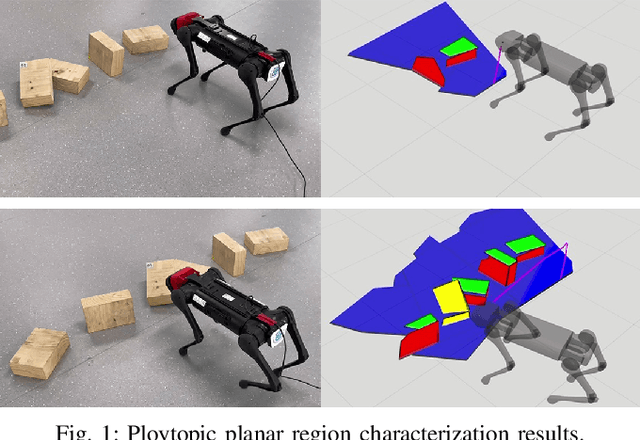
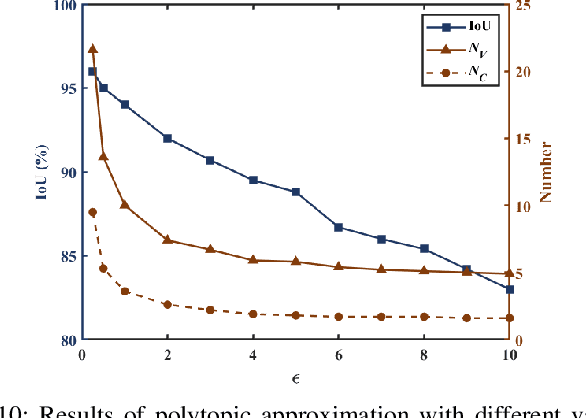
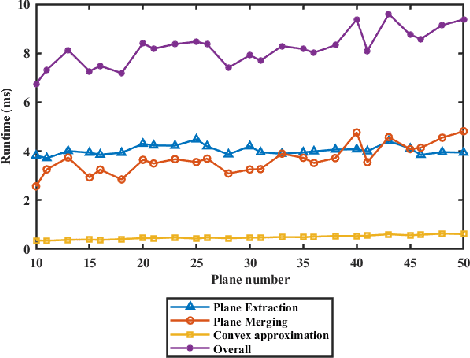
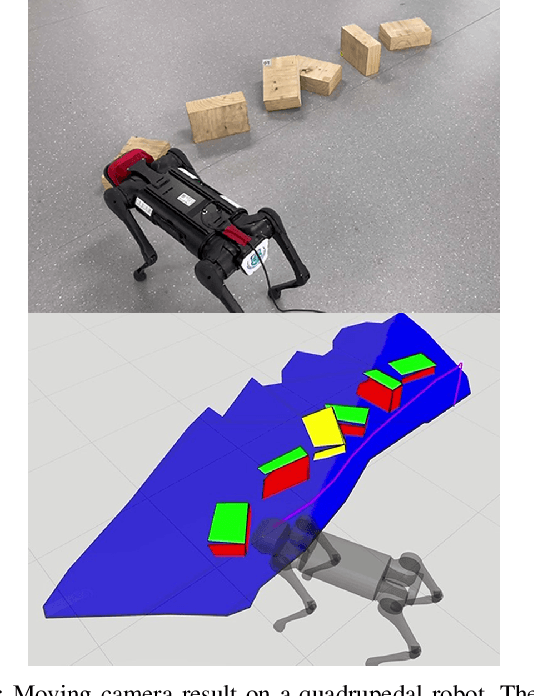
This paper studies the problem of constructing polytopic representations of planar regions from depth camera readings. This problem is of great importance for terrain mapping in complicated environment and has great potentials in legged locomotion applications. To address the polytopic planar region characterization problem, we propose a two-stage solution scheme. At the first stage, the planar regions embedded within a sequence of depth images are extracted individually first and then merged to establish a terrain map containing only planar regions in a selected frame. To simplify the representations of the planar regions that are applicable to foothold planning for legged robots, we further approximate the extracted planar regions via low-dimensional polytopes at the second stage. With the polytopic representation, the proposed approach achieves a great balance between accuracy and simplicity. Experimental validations with RGB-D cameras are conducted to demonstrate the performance of the proposed scheme. The proposed scheme successfully characterizes the planar regions via polytopes with acceptable accuracy. More importantly, the run time of the overall perception scheme is less than 10ms (i.e., > 100Hz) throughout the tests, which strongly illustrates the advantages of our approach developed in this paper.
Formalizing the Problem of Side-Effect Avoidance
Jun 23, 2022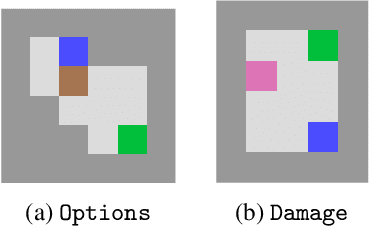
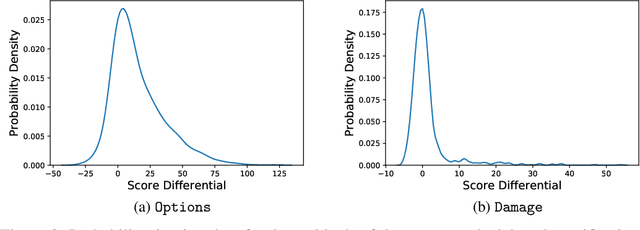
AI objectives are often hard to specify properly. Some approaches tackle this problem by regularizing the AI's side effects: Agents must weigh off "how much of a mess they make" with an imperfectly specified proxy objective. We propose a formal criterion for side effect regularization via the assistance game framework. In these games, the agent solves a partially observable Markov decision process (POMDP) representing its uncertainty about the objective function it should optimize. We consider the setting where the true objective is revealed to the agent at a later time step. We show that this POMDP is solved by trading off the proxy reward with the agent's ability to achieve a range of future tasks. We empirically demonstrate the reasonableness of our problem formalization via ground-truth evaluation in two gridworld environments.
Graph-Based Machine Learning Improves Just-in-Time Defect Prediction
Oct 11, 2021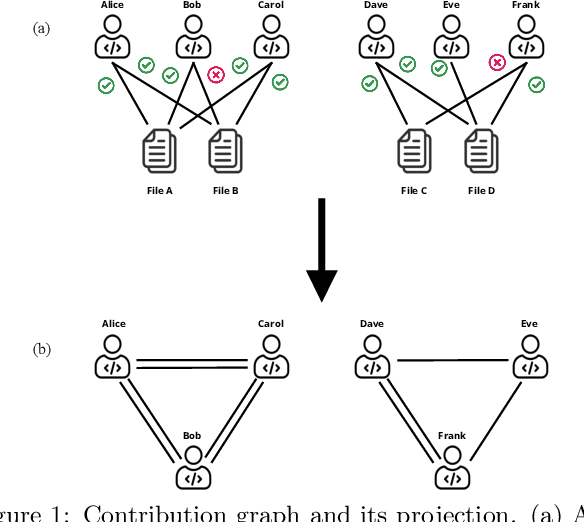
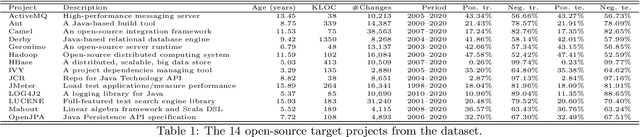
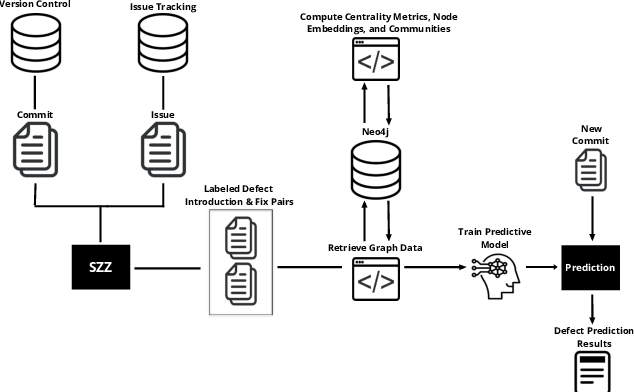

The increasing complexity of today's software requires the contribution of thousands of developers. This complex collaboration structure makes developers more likely to introduce defect-prone changes that lead to software faults. Determining when these defect-prone changes are introduced has proven challenging, and using traditional machine learning (ML) methods to make these determinations seems to have reached a plateau. In this work, we build contribution graphs consisting of developers and source files to capture the nuanced complexity of changes required to build software. By leveraging these contribution graphs, our research shows the potential of using graph-based ML to improve Just-In-Time (JIT) defect prediction. We hypothesize that features extracted from the contribution graphs may be better predictors of defect-prone changes than intrinsic features derived from software characteristics. We corroborate our hypothesis using graph-based ML for classifying edges that represent defect-prone changes. This new framing of the JIT defect prediction problem leads to remarkably better results. We test our approach on 14 open-source projects and show that our best model can predict whether or not a code change will lead to a defect with an F1 score as high as 86.25$\%$. This represents an increase of as much as 55.4$\%$ over the state-of-the-art in JIT defect prediction. We describe limitations, open challenges, and how this method can be used for operational JIT defect prediction.
People Tracking and Re-Identifying in Distributed Contexts: Extension of PoseTReID
May 20, 2022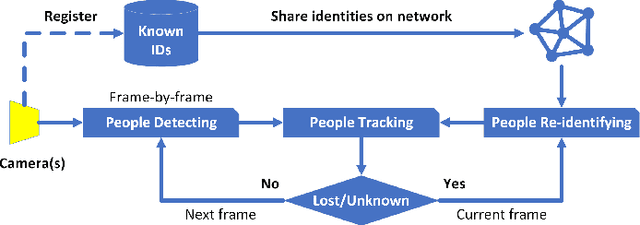



In our previous paper, we introduced PoseTReID which is a generic framework for real-time 2D multi-person tracking in distributed interaction spaces where long-term people's identities are important for other studies such as behavior analysis, etc. In this paper, we introduce a further study of PoseTReID framework in order to give a more complete comprehension of the framework. We use a well-known bounding box detector YOLO (v4) for the detection to compare to OpenPose which was used in our last paper, and we use SORT and DeepSORT to compare to centroid which was also used previously, and most importantly for the re-identification, we use a bunch of deep leaning methods such as MLFN, OSNet, and OSNet-AIN with our custom classification layer to compare to FaceNet which was also used earlier in our last paper. By evaluating on our PoseTReID datasets, even though those deep learning re-identification methods are designed for only short-term re-identification across multiple cameras or videos, it is worth showing that they give impressive results which boost the overall tracking performance of PoseTReID framework regardless the type of tracking method. At the same time, we also introduce our research-friendly and open source Python toolbox pyppbox, which is pure written in Python and contains all sub-modules which are used this study along with real-time online and offline evaluations for our PoseTReID datasets. This pyppbox is available on GitHub https://github.com/rathaumons/pyppbox .
Study of the performance and scalablity of federated learning for medical imaging with intermittent clients
Jul 18, 2022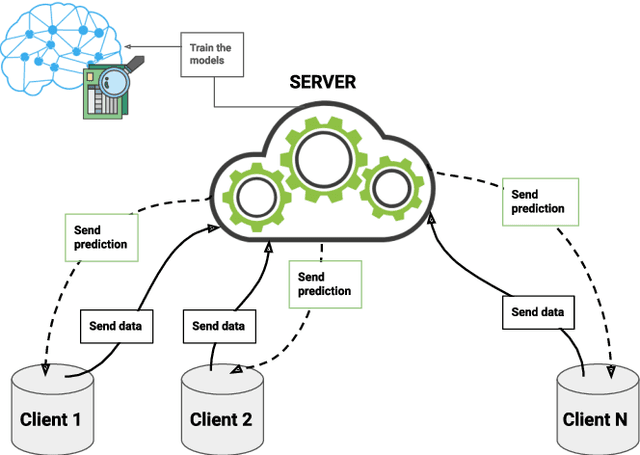
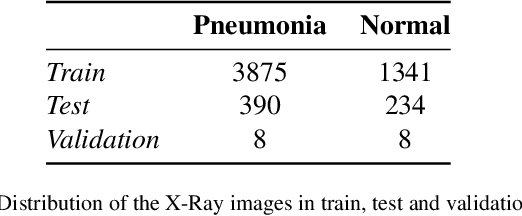
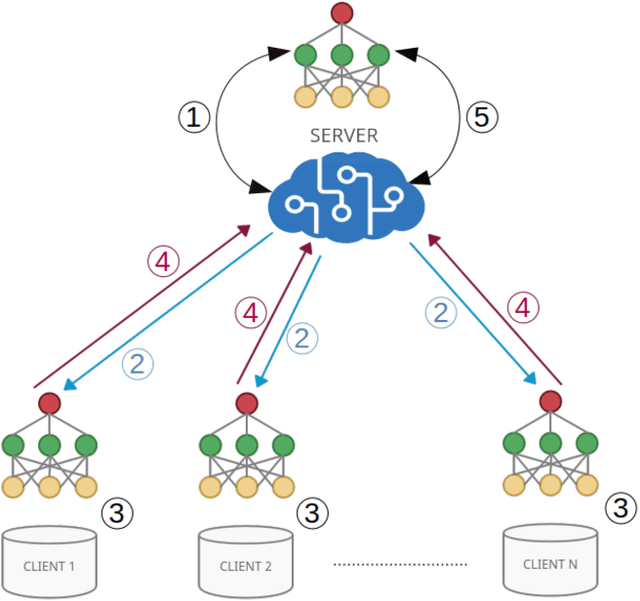
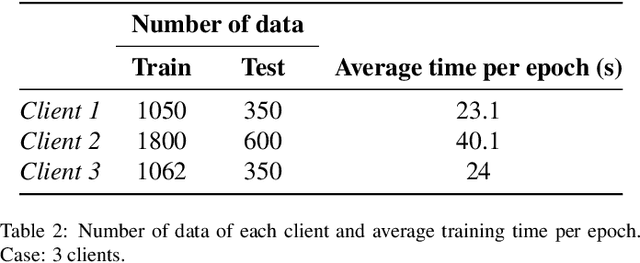
Federated learning is a data decentralization privacy-preserving technique used to perform machine or deep learning in a secure way. In this paper we present theoretical aspects about federated learning, such as the presentation of an aggregation operator, different types of federated learning, and issues to be taken into account in relation to the distribution of data from the clients, together with the exhaustive analysis of a use case where the number of clients varies. Specifically, a use case of medical image analysis is proposed, using chest X-ray images obtained from an open data repository. In addition to the advantages related to privacy, improvements in predictions (in terms of accuracy and area under the curve) and reduction of execution times will be studied with respect to the classical case (the centralized approach). Different clients will be simulated from the training data, selected in an unbalanced manner, i.e., they do not all have the same number of data. The results of considering three or ten clients are exposed and compared between them and against the centralized case. Two approaches to follow will be analyzed in the case of intermittent clients, as in a real scenario some clients may leave the training, and some new ones may enter the training. The evolution of the results for the test set in terms of accuracy, area under the curve and execution time is shown as the number of clients into which the original data is divided increases. Finally, improvements and future work in the field are proposed.
Estimating Exposure to Information on Social Networks
Jul 13, 2022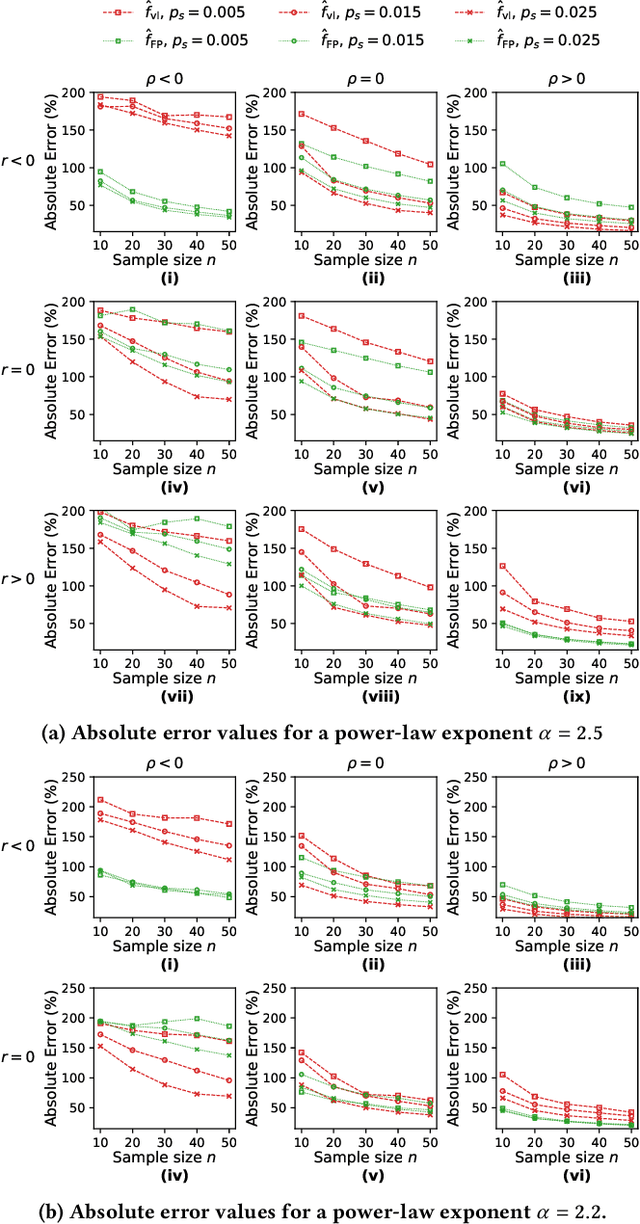
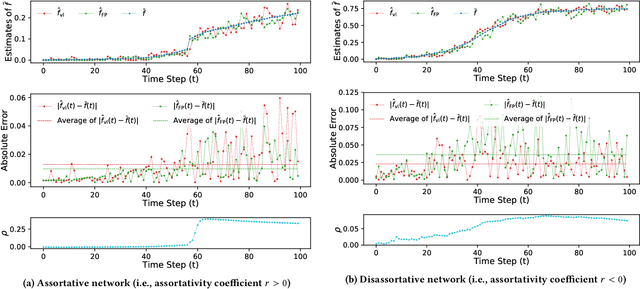
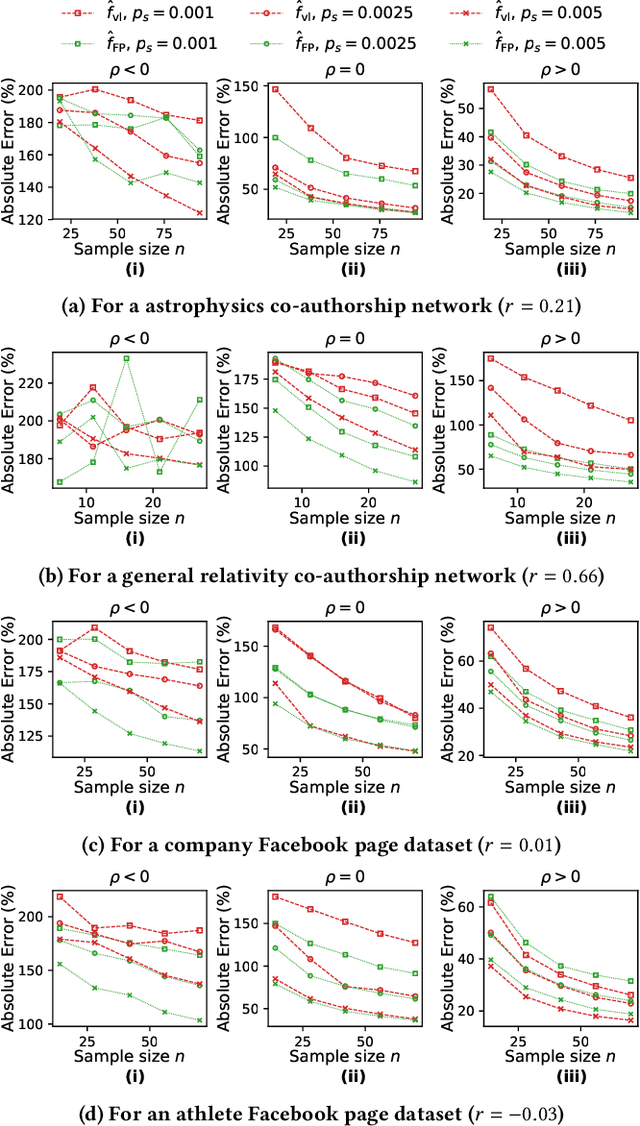
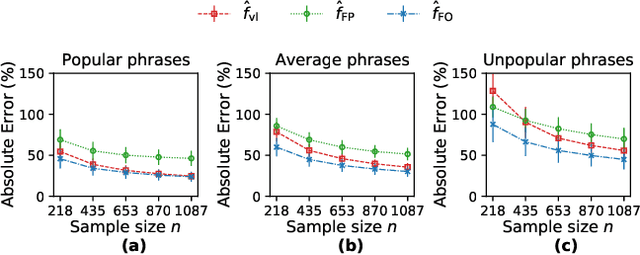
This paper considers the problem of estimating exposure to information in a social network. Given a piece of information (e.g., a URL of a news article on Facebook, a hashtag on Twitter), our aim is to find the fraction of people on the network who have been exposed to it. The exact value of exposure to a piece of information is determined by two features: the structure of the underlying social network and the set of people who shared the piece of information. Often, both features are not publicly available (i.e., access to the two features is limited only to the internal administrators of the platform) and difficult to be estimated from data. As a solution, we propose two methods to estimate the exposure to a piece of information in an unbiased manner: a vanilla method which is based on sampling the network uniformly and a method which non-uniformly samples the network motivated by the Friendship Paradox. We provide theoretical results which characterize the conditions (in terms of properties of the network and the piece of information) under which one method outperforms the other. Further, we outline extensions of the proposed methods to dynamic information cascades (where the exposure needs to be tracked in real-time). We demonstrate the practical feasibility of the proposed methods via experiments on multiple synthetic and real-world datasets.