 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePenalizing Transparency? How AI Disclosure and Author Demographics Shape Human and AI Judgments About Writing
Jul 02, 2025


As AI integrates in various types of human writing, calls for transparency around AI assistance are growing. However, if transparency operates on uneven ground and certain identity groups bear a heavier cost for being honest, then the burden of openness becomes asymmetrical. This study investigates how AI disclosure statement affects perceptions of writing quality, and whether these effects vary by the author's race and gender. Through a large-scale controlled experiment, both human raters (n = 1,970) and LLM raters (n = 2,520) evaluated a single human-written news article while disclosure statements and author demographics were systematically varied. This approach reflects how both human and algorithmic decisions now influence access to opportunities (e.g., hiring, promotion) and social recognition (e.g., content recommendation algorithms). We find that both human and LLM raters consistently penalize disclosed AI use. However, only LLM raters exhibit demographic interaction effects: they favor articles attributed to women or Black authors when no disclosure is present. But these advantages disappear when AI assistance is revealed. These findings illuminate the complex relationships between AI disclosure and author identity, highlighting disparities between machine and human evaluation patterns.
Large Language Model Use Impact Locus of Control
May 16, 2025


As AI tools increasingly shape how we write, they may also quietly reshape how we perceive ourselves. This paper explores the psychological impact of co-writing with AI on people's locus of control. Through an empirical study with 462 participants, we found that employment status plays a critical role in shaping users' reliance on AI and their locus of control. Current results demonstrated that employed participants displayed higher reliance on AI and a shift toward internal control, while unemployed users tended to experience a reduction in personal agency. Through quantitative results and qualitative observations, this study opens a broader conversation about AI's role in shaping personal agency and identity.
Estimating Exposure to Information on Social Networks
Jul 13, 2022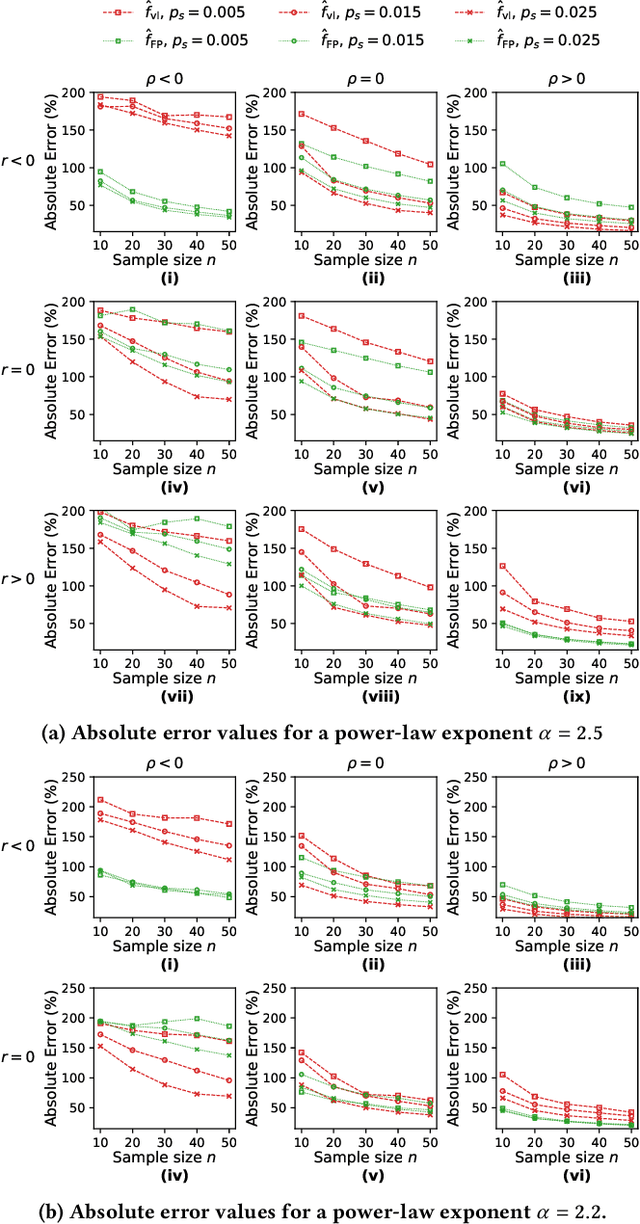
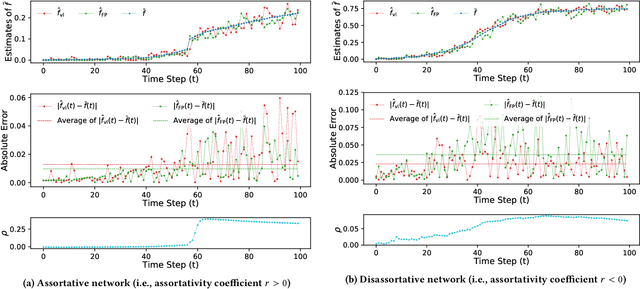
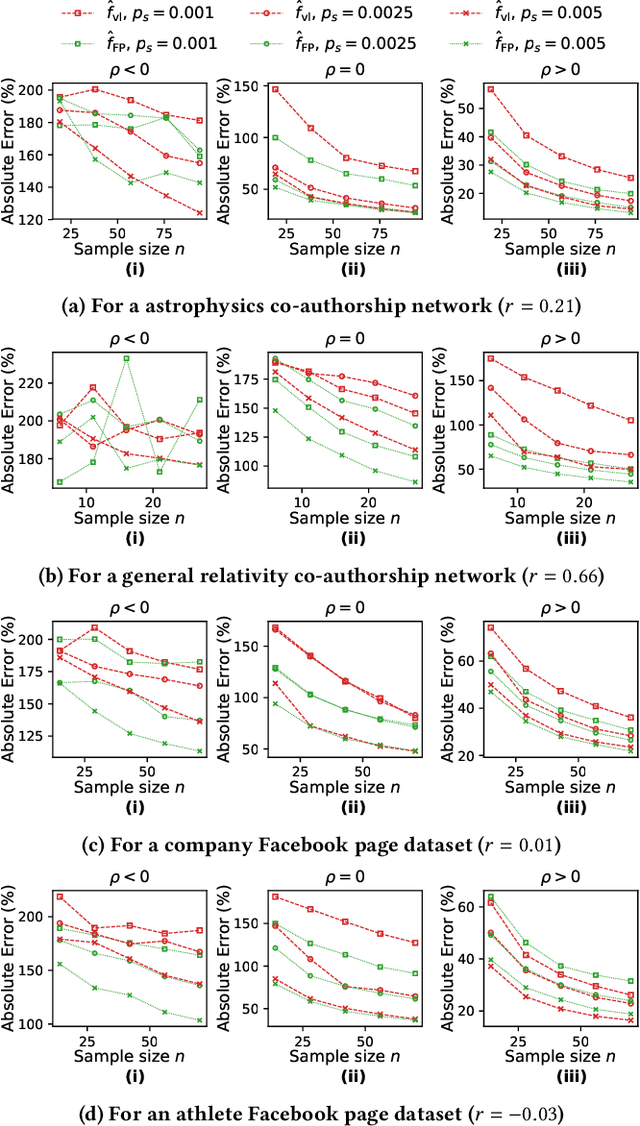
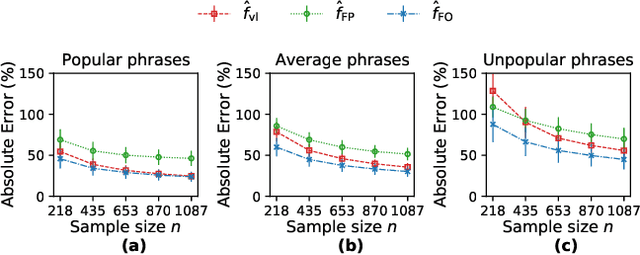
This paper considers the problem of estimating exposure to information in a social network. Given a piece of information (e.g., a URL of a news article on Facebook, a hashtag on Twitter), our aim is to find the fraction of people on the network who have been exposed to it. The exact value of exposure to a piece of information is determined by two features: the structure of the underlying social network and the set of people who shared the piece of information. Often, both features are not publicly available (i.e., access to the two features is limited only to the internal administrators of the platform) and difficult to be estimated from data. As a solution, we propose two methods to estimate the exposure to a piece of information in an unbiased manner: a vanilla method which is based on sampling the network uniformly and a method which non-uniformly samples the network motivated by the Friendship Paradox. We provide theoretical results which characterize the conditions (in terms of properties of the network and the piece of information) under which one method outperforms the other. Further, we outline extensions of the proposed methods to dynamic information cascades (where the exposure needs to be tracked in real-time). We demonstrate the practical feasibility of the proposed methods via experiments on multiple synthetic and real-world datasets.