 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgefMPI: Fast Novel View Synthesis in the Wild with Layered Scene Representations
Dec 26, 2023



In this study, we propose two novel input processing paradigms for novel view synthesis (NVS) methods based on layered scene representations that significantly improve their runtime without compromising quality. Our approach identifies and mitigates the two most time-consuming aspects of traditional pipelines: building and processing the so-called plane sweep volume (PSV), which is a high-dimensional tensor of planar re-projections of the input camera views. In particular, we propose processing this tensor in parallel groups for improved compute efficiency as well as super-sampling adjacent input planes to generate denser, and hence more accurate scene representation. The proposed enhancements offer significant flexibility, allowing for a balance between performance and speed, thus making substantial steps toward real-time applications. Furthermore, they are very general in the sense that any PSV-based method can make use of them, including methods that employ multiplane images, multisphere images, and layered depth images. In a comprehensive set of experiments, we demonstrate that our proposed paradigms enable the design of an NVS method that achieves state-of-the-art on public benchmarks while being up to $50x$ faster than existing state-of-the-art methods. It also beats the current forerunner in terms of speed by over $3x$, while achieving significantly better rendering quality.
RLSAC: Reinforcement Learning enhanced Sample Consensus for End-to-End Robust Estimation
Aug 10, 2023Robust estimation is a crucial and still challenging task, which involves estimating model parameters in noisy environments. Although conventional sampling consensus-based algorithms sample several times to achieve robustness, these algorithms cannot use data features and historical information effectively. In this paper, we propose RLSAC, a novel Reinforcement Learning enhanced SAmple Consensus framework for end-to-end robust estimation. RLSAC employs a graph neural network to utilize both data and memory features to guide exploring directions for sampling the next minimum set. The feedback of downstream tasks serves as the reward for unsupervised training. Therefore, RLSAC can avoid differentiating to learn the features and the feedback of downstream tasks for end-to-end robust estimation. In addition, RLSAC integrates a state transition module that encodes both data and memory features. Our experimental results demonstrate that RLSAC can learn from features to gradually explore a better hypothesis. Through analysis, it is apparent that RLSAC can be easily transferred to other sampling consensus-based robust estimation tasks. To the best of our knowledge, RLSAC is also the first method that uses reinforcement learning to sample consensus for end-to-end robust estimation. We release our codes at https://github.com/IRMVLab/RLSAC.
AffineGlue: Joint Matching and Robust Estimation
Jul 28, 2023



We propose AffineGlue, a method for joint two-view feature matching and robust estimation that reduces the combinatorial complexity of the problem by employing single-point minimal solvers. AffineGlue selects potential matches from one-to-many correspondences to estimate minimal models. Guided matching is then used to find matches consistent with the model, suffering less from the ambiguities of one-to-one matches. Moreover, we derive a new minimal solver for homography estimation, requiring only a single affine correspondence (AC) and a gravity prior. Furthermore, we train a neural network to reject ACs that are unlikely to lead to a good model. AffineGlue is superior to the SOTA on real-world datasets, even when assuming that the gravity direction points downwards. On PhotoTourism, the AUC@10{\deg} score is improved by 6.6 points compared to the SOTA. On ScanNet, AffineGlue makes SuperPoint and SuperGlue achieve similar accuracy as the detector-free LoFTR.
Consensus-Adaptive RANSAC
Jul 26, 2023



RANSAC and its variants are widely used for robust estimation, however, they commonly follow a greedy approach to finding the highest scoring model while ignoring other model hypotheses. In contrast, Iteratively Reweighted Least Squares (IRLS) techniques gradually approach the model by iteratively updating the weight of each correspondence based on the residuals from previous iterations. Inspired by these methods, we propose a new RANSAC framework that learns to explore the parameter space by considering the residuals seen so far via a novel attention layer. The attention mechanism operates on a batch of point-to-model residuals, and updates a per-point estimation state to take into account the consensus found through a lightweight one-step transformer. This rich state then guides the minimal sampling between iterations as well as the model refinement. We evaluate the proposed approach on essential and fundamental matrix estimation on a number of indoor and outdoor datasets. It outperforms state-of-the-art estimators by a significant margin adding only a small runtime overhead. Moreover, we demonstrate good generalization properties of our trained model, indicating its effectiveness across different datasets and tasks. The proposed attention mechanism and one-step transformer provide an adaptive behavior that enhances the performance of RANSAC, making it a more effective tool for robust estimation. Code is available at https://github.com/cavalli1234/CA-RANSAC.
NeFSAC: Neurally Filtered Minimal Samples
Jul 16, 2022
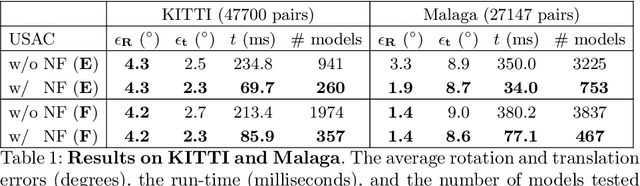

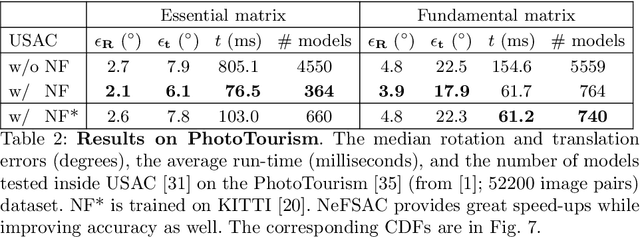
Since RANSAC, a great deal of research has been devoted to improving both its accuracy and run-time. Still, only a few methods aim at recognizing invalid minimal samples early, before the often expensive model estimation and quality calculation are done. To this end, we propose NeFSAC, an efficient algorithm for neural filtering of motion-inconsistent and poorly-conditioned minimal samples. We train NeFSAC to predict the probability of a minimal sample leading to an accurate relative pose, only based on the pixel coordinates of the image correspondences. Our neural filtering model learns typical motion patterns of samples which lead to unstable poses, and regularities in the possible motions to favour well-conditioned and likely-correct samples. The novel lightweight architecture implements the main invariants of minimal samples for pose estimation, and a novel training scheme addresses the problem of extreme class imbalance. NeFSAC can be plugged into any existing RANSAC-based pipeline. We integrate it into USAC and show that it consistently provides strong speed-ups even under extreme train-test domain gaps - for example, the model trained for the autonomous driving scenario works on PhotoTourism too. We tested NeFSAC on more than 100k image pairs from three publicly available real-world datasets and found that it leads to one order of magnitude speed-up, while often finding more accurate results than USAC alone. The source code is available at https://github.com/cavalli1234/NeFSAC.
AdaLAM: Revisiting Handcrafted Outlier Detection
Jun 07, 2020
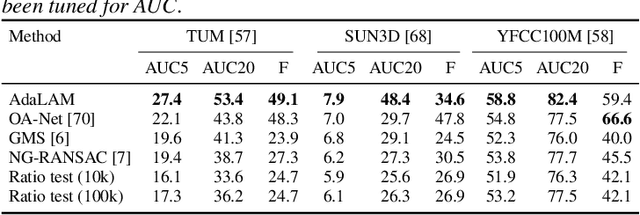

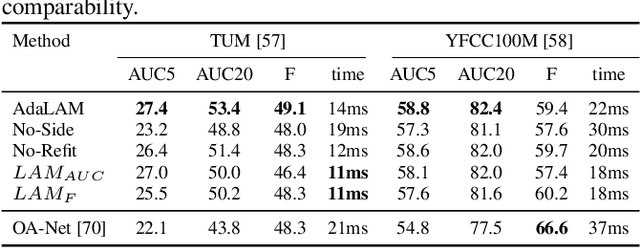
Local feature matching is a critical component of many computer vision pipelines, including among others Structure-from-Motion, SLAM, and Visual Localization. However, due to limitations in the descriptors, raw matches are often contaminated by a majority of outliers. As a result, outlier detection is a fundamental problem in computer vision, and a wide range of approaches have been proposed over the last decades. In this paper we revisit handcrafted approaches to outlier filtering. Based on best practices, we propose a hierarchical pipeline for effective outlier detection as well as integrate novel ideas which in sum lead to AdaLAM, an efficient and competitive approach to outlier rejection. AdaLAM is designed to effectively exploit modern parallel hardware, resulting in a very fast, yet very accurate, outlier filter. We validate AdaLAM on multiple large and diverse datasets, and we submit to the Image Matching Challenge (CVPR2020), obtaining competitive results with simple baseline descriptors. We show that AdaLAM is more than competitive to current state of the art, both in terms of efficiency and effectiveness.
Towards Affordance Prediction with Vision via Task Oriented Grasp Quality Metrics
Jul 10, 2019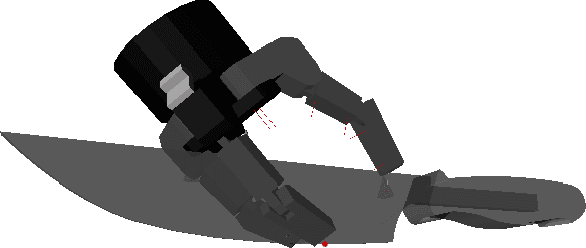
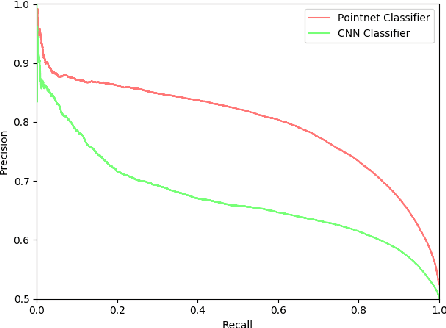
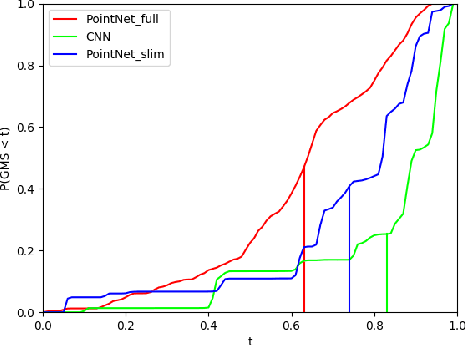
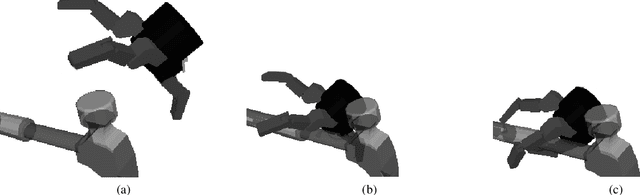
While many quality metrics exist to evaluate the quality of a grasp by itself, no clear quantification of the quality of a grasp relatively to the task the grasp is used for has been defined yet. In this paper we propose a framework to extend the concept of grasp quality metric to task-oriented grasping by defining affordance functions via basic grasp metrics for an open set of task affordances. We evaluate both the effectivity of the proposed task oriented metrics and their practical applicability by learning to infer them from vision. Indeed, we assess the validity of our novel framework both in the context of perfect information, i.e., known object model, and in the partial information context, i.e., inferring task oriented metrics from vision, underlining advantages and limitations of both situations. In the former, physical metrics of grasp hypotheses on an object are defined and computed in known object model simulation, in the latter deep models are trained to infer such properties from partial information in the form of synthesized range images.