 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrivacy Preserving Machine Learning Workflow: from Anonymization to Personalized Differential Privacy Budgets in Federated Learning
May 04, 2026The growing development of artificial intelligence based solutions, together with privacy legislation, has driven the rise of the so-called privacy preserving machine learning architectures, such as federated learning. While federated learning enables model training on decentralized data preventing their sharing and centralization, it still faces several challenges related to data integrity and privacy. This paper presents a comprehensive privacy preserving federated learning workflow for sensitive tabular data, including anonymization and differential privacy techniques. We also introduce a formal definition for the concept of client drift, together with ways of detecting it to mitigate poisoning attacks. Then, we detail a complete methodology for assigning personalized privacy budgets for global differential privacy to the different clients participating in the network, based on a re-identification risk metric. The proposed methodology is presented and tested on an openly available dataset of medical records. Within the experimental setup we show that the approach based on personalized budgets, compared to the architecture including global differential privacy with fixed privacy budget, achieves a better model performance in terms of two error metrics.
AI4EOSC: a Federated Cloud Platform for Artificial Intelligence in Scientific Research
Dec 18, 2025

In this paper, we describe a federated compute platform dedicated to support Artificial Intelligence in scientific workloads. Putting the effort into reproducible deployments, it delivers consistent, transparent access to a federation of physically distributed e-Infrastructures. Through a comprehensive service catalogue, the platform is able to offer an integrated user experience covering the full Machine Learning lifecycle, including model development (with dedicated interactive development environments), training (with GPU resources, annotation tools, experiment tracking, and federated learning support) and deployment (covering a wide range of deployment options all along the Cloud Continuum). The platform also provides tools for traceability and reproducibility of AI models, integrates with different Artificial Intelligence model providers, datasets and storage resources, allowing users to interact with the broader Machine Learning ecosystem. Finally, it is easily customizable to lower the adoption barrier by external communities.
Metric Privacy in Federated Learning for Medical Imaging: Improving Convergence and Preventing Client Inference Attacks
Feb 03, 2025



Federated learning is a distributed learning technique that allows training a global model with the participation of different data owners without the need to share raw data. This architecture is orchestrated by a central server that aggregates the local models from the clients. This server may be trusted, but not all nodes in the network. Then, differential privacy (DP) can be used to privatize the global model by adding noise. However, this may affect convergence across the rounds of the federated architecture, depending also on the aggregation strategy employed. In this work, we aim to introduce the notion of metric-privacy to mitigate the impact of classical server side global-DP on the convergence of the aggregated model. Metric-privacy is a relaxation of DP, suitable for domains provided with a notion of distance. We apply it from the server side by computing a distance for the difference between the local models. We compare our approach with standard DP by analyzing the impact on six classical aggregation strategies. The proposed methodology is applied to an example of medical imaging and different scenarios are simulated across homogeneous and non-i.i.d clients. Finally, we introduce a novel client inference attack, where a semi-honest client tries to find whether another client participated in the training and study how it can be mitigated using DP and metric-privacy. Our evaluation shows that metric-privacy can increase the performance of the model compared to standard DP, while offering similar protection against client inference attacks.
Enhancing the Convergence of Federated Learning Aggregation Strategies with Limited Data
Jan 27, 2025



The development of deep learning techniques is a leading field applied to cases in which medical data is used, particularly in cases of image diagnosis. This type of data has privacy and legal restrictions that in many cases prevent it from being processed from central servers. However, in this area collaboration between different research centers, in order to create models as robust as possible, trained with the largest quantity and diversity of data available, is a critical point to be taken into account. In this sense, the application of privacy aware distributed architectures, such as federated learning arises. When applying this type of architecture, the server aggregates the different local models trained with the data of each data owner to build a global model. This point is critical and therefore it is fundamental to analyze different ways of aggregation according to the use case, taking into account the distribution of the clients, the characteristics of the model, etc. In this paper we propose a novel aggregation strategy and we apply it to a use case of cerebral magnetic resonance image classification. In this use case the aggregation function proposed manages to improve the convergence obtained over the rounds of the federated learning process in relation to different aggregation strategies classically implemented and applied.
Personalized Federated Learning for improving radar based precipitation nowcasting on heterogeneous areas
Aug 11, 2024The increasing generation of data in different areas of life, such as the environment, highlights the need to explore new techniques for processing and exploiting data for useful purposes. In this context, artificial intelligence techniques, especially through deep learning models, are key tools to be used on the large amount of data that can be obtained, for example, from weather radars. In many cases, the information collected by these radars is not open, or belongs to different institutions, thus needing to deal with the distributed nature of this data. In this work, the applicability of a personalized federated learning architecture, which has been called adapFL, on distributed weather radar images is addressed. To this end, given a single available radar covering 400 km in diameter, the captured images are divided in such a way that they are disjointly distributed into four different federated clients. The results obtained with adapFL are analyzed in each zone, as well as in a central area covering part of the surface of each of the previously distributed areas. The ultimate goal of this work is to study the generalization capability of this type of learning technique for its extrapolation to use cases in which a representative number of radars is available, whose data can not be centralized due to technical, legal or administrative concerns. The results of this preliminary study indicate that the performance obtained in each zone with the adapFL approach allows improving the results of the federated learning approach, the individual deep learning models and the classical Continuity Tracking Radar Echoes by Correlation approach.
Comparison of machine learning models applied on anonymized data with different techniques
May 12, 2023



Anonymization techniques based on obfuscating the quasi-identifiers by means of value generalization hierarchies are widely used to achieve preset levels of privacy. To prevent different types of attacks against database privacy it is necessary to apply several anonymization techniques beyond the classical k-anonymity or $\ell$-diversity. However, the application of these methods is directly connected to a reduction of their utility in prediction and decision making tasks. In this work we study four classical machine learning methods currently used for classification purposes in order to analyze the results as a function of the anonymization techniques applied and the parameters selected for each of them. The performance of these models is studied when varying the value of k for k-anonymity and additional tools such as $\ell$-diversity, t-closeness and $\delta$-disclosure privacy are also deployed on the well-known adult dataset.
Study of the performance and scalability of federated learning for medical imaging with intermittent clients
Jul 19, 2022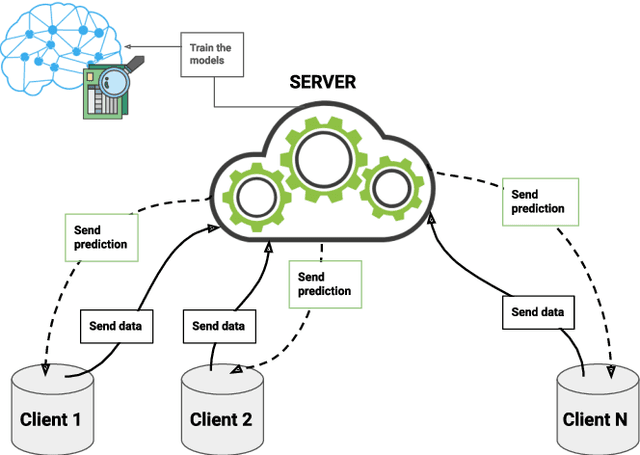
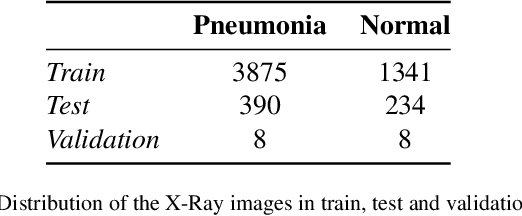
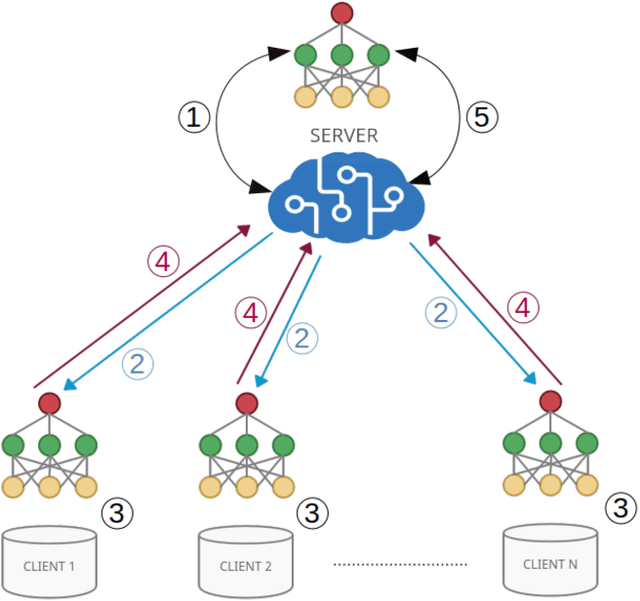
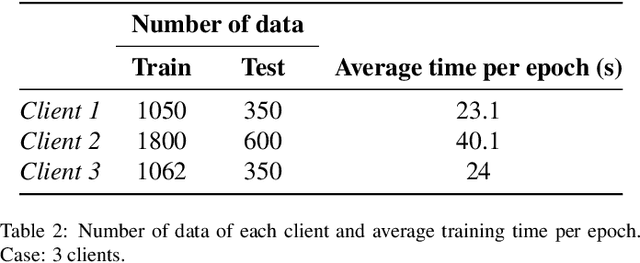
Federated learning is a data decentralization privacy-preserving technique used to perform machine or deep learning in a secure way. In this paper we present theoretical aspects about federated learning, such as the presentation of an aggregation operator, different types of federated learning, and issues to be taken into account in relation to the distribution of data from the clients, together with the exhaustive analysis of a use case where the number of clients varies. Specifically, a use case of medical image analysis is proposed, using chest X-ray images obtained from an open data repository. In addition to the advantages related to privacy, improvements in predictions (in terms of accuracy and area under the curve) and reduction of execution times will be studied with respect to the classical case (the centralized approach). Different clients will be simulated from the training data, selected in an unbalanced manner, i.e., they do not all have the same number of data. The results of considering three or ten clients are exposed and compared between them and against the centralized case. Two approaches to follow will be analyzed in the case of intermittent clients, as in a real scenario some clients may leave the training, and some new ones may enter the training. The evolution of the results for the test set in terms of accuracy, area under the curve and execution time is shown as the number of clients into which the original data is divided increases. Finally, improvements and future work in the field are proposed.